redis缓存数据库
redis服务
NoSql(not only sql)主要分为:
- 临时性键值存储 memcache、redis
- 永久性键值存储 roma、redis
- 面向文档的数据库 MongoDB、couchdb、elasticksearch、redisjson
- 面向列的数据库 cassandra、hbase
redis特性:
- 速度快: 10w qps,基于内存,C语言实现,单线程
- 持久化
- 支持多种数据结构
- 支持多种编程语言
- 支持lua脚本,发布订阅、事务、pipeline等
- 代码精简,单线程开发容易,不依赖外部库
- 主从复制
- 支持高可用、分布式
单线程工作模式:
- 6.0版本以前是单线程,之后支持多线程
- 纯内存存储
- 非阻塞型io
- 避免线程切换的竞争资源消耗
注意: 性能优化事项
- 一次执行一条命令
- 拒绝长(慢)命令: keys、flushall、show lua script、mutil/exec、operate gib value(collection)
- 其他线程:fysnc file descriptor、cloes file descriptor
redis对比memcached:
- 支持数据的持久化: 可以将内存中的数据保持在磁盘中,重启redis服务或者服务器之后可以从备份文件中恢复数据到内存继续使用
- 支持更多的数据类型: 支持string(字符串)、hash(哈希数据)、list(列表)、set(集合)、zet(有序集合)
- 支持数据的备份: 可以实现类似于数据的master-slave模式的数据备份,另外也支持使用 快照+AOF
- 支持更大的value数据: memcache单个ke:value最大只支持1MB,而redis最大支持512MB
- Redis是单线程,而memcache是多线程,所以单机情况下没有memcache并发高,但redis支持分布式集群以实现更高的并发,单Redis实例可以实现数万并发
- 支持集群横向扩展: 基于redis cluster的横向扩展,可以实现分布式集群,大幅提升性能和数据安全性。
- 都是基于C语言开发
redis 典型应用场景及其流程:
- Session 共享:常见于web集群中的Tomcat或者PHP中多web服务器session共享
- 缓存:数据查询、电商网站商品信息、新闻内容
- 计数器:访问排行榜、商品浏览数等和次数相关的数值统计场景
- 微博/微信社交场合:共同好友,粉丝数,关注,点赞评论等
- 消息队列:ELK的日志缓存、部分业务的订阅发布系统
- 地理位置: 基于GEO(地理信息定位),实现摇一摇,附近的人,外卖等功能
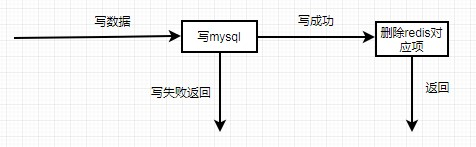
数据更新操作流程:
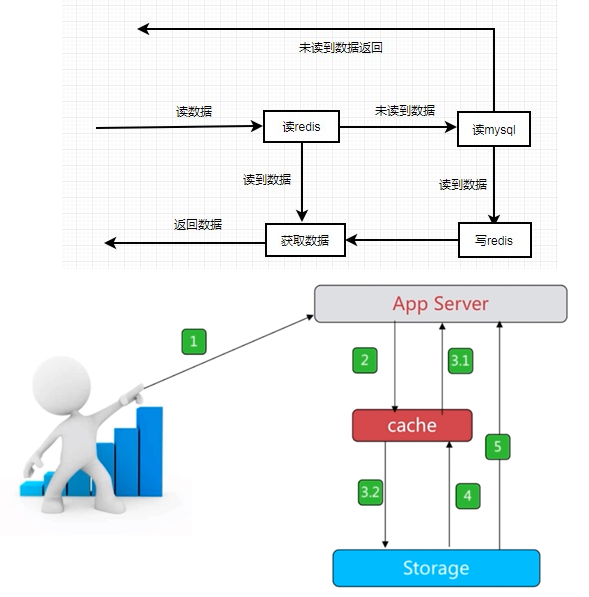
数据读操作流程:
做消息队列:
redis程序
- redis-server:用于启动Redis的工具。
- redis-benchmark:用于检测Redis在本机的运行效率。
- redis-check-aof:修复AOF持久化文件
- redis-check-rdb:修复RDB持久化文件
- redis-cli: Redis 命令行工具
- redis-setinel: redis- -server文件的软链接
redis-server命令:
redis-server -h
./redis-server [/path/to/redis.conf] [options]
./redis-server - (read config from stdin)
./redis-server (run the server with default conf)
./redis-server /etc/redis/6379.conf
./redis-server --port 7777
./redis-server --port 7777 --replicaof 127.0.0.1 8888
./redis-server /etc/myredis.conf --loglevel verbose
./redis-server /etc/sentinel.conf --sentinel
redis-benchmark命令:
redis- -benchmark [option] [option value]. 常用选项如下所示。
-h 指定服务器主机名。
-p 指定服务器端口。
-s 指定服务器socket。
-c 指定并发连接数。
-n 指定请求数。
-d 以字节(B) 的形式指定SET/GET值的数据大小。
-k 1=keep alive 0=reconnect。
-r SET/GET/INCR 使用随机key, SADD使用随机值。
-P 通过管道传输 请求。
-q 强制退出redis. 仅显示query/sec值。
--csv 以CSV格式输出。
-I 生成循环,永久执行测试。
-t 仅运行以逗号分隔的测试命令列表。
-Idle模式 仅打开N个idle连接并等待。
例:
#发送100个并发连接与100000个请求测试性能
redis-benchmark -h 127.0.0.1 -p 6379 -c 100 -n 100000
#测试存取大小为100B的数据包的性能
redis-benchmark -h 1127.0.0.1 -p 6379 -q -d 100
#测试本机上Redis服务在进行set与lpush操作时的性能
redis-benchmark -t set, lpush -n 00000 -q
redis-check-aof命令
用于修复aof文件错误,aof文件错误时,redis是不能正常启动的
redis-check-aof --fix AOF文件
redis-check-rdb命令
用于修复rdb文件错误,rdb文件错误时,redis是不能正常启动的
redis-check-aof --fix RDB文件
redis-cli命令:
redis-cli [选项] [命令]
选项:
-h 主机 连接主机
-p 6379 端口
-s socket文件 socket连接
-a 密码
-c 集群模式中自动重定向槽位
get 键 直接查看变量
info 直接查看info信息
config
shutdown
--cluster 命令 集群相关命令
命令:
info [信息段] 查看数据库信息
信息段:
Server 为服务端配置
Clients 为客户端信息
Memory 为内存相关信息
Persistence 持续保持
Stats 数据库状态
Replication 主从复制
CPU
Cluster 集群相关
Keyspace 数据库存的总数据量,也就是键值对
set key value [expiration EX 秒|PX 毫秒] [NX|XX] 存入数据,建 值即可,后面可省略
说明:
EX为键值对有效期时间,秒为单位
PX为键值对有效期时间,毫秒为单位
NX为键不存在时,才进行操作
XX为键已经存在时,才进行操作
get key 查看数据,键
del key 删除键
config get/set 键/参数 值 临时动态查看/修改数据或配置参数
config get s* 支持迷糊查询键
config set requirepass 123456 临时修改密码
save 保存
slowlog len 慢查询记录数量
slowlog get 慢查询记录查看
slowlog reset 清空慢查询日志
dbsize 数据总数
flushall 删除所有库所有key
flushdb 强制清空当前库的所有key
select num 选择几号数据库,相当于mysql的use database
注意: 集群中不支持多个库,只能使用0库
keys * 用通配符列出库中所有key,但会引起cpu高负荷,大数据时引起宕机,禁用
shutdown 保存所有数据后关闭服务
ttl key 查看数据的有效期
说明:
-1为永久有效
-2为过期
type key 查看key的数据属性
cluster 命令 执行集群相关的命令
集群命令:
info
cluster_size 集群数(有槽位才算集群)
nodes 显示当前节点与其他节点关系
meet ip port 认识集群其他节点
addslots 槽位 手动加槽位(只能一个一个加)
create 创建集群
check
fix 集群数据迁移时的错误修复
reshard 重新分配槽位
repbalance 自动平均集群槽位
add-node 添加新节点
del-node 删除节点
call
set-timeout
import 导入数据到集群
info命令输出信息:
server: 一般 Redis 服务器信息,包含以下域
| redis_version | Redis 服务器版本 |
| redis_git_sha1 | Git SHA1 |
| redis_git_dirty | Git dirty flag |
| os | Redis 服务器的宿主操作系统 |
| arch_bits | 架构(32 或 64 位) |
| multiplexing_api | Redis所使用的事件处理机制,默认epoll |
| gcc_version | 编译 Redis 时所使用的 GCC 版本 |
| process_id | 服务器进程的 PID |
| run_id | Redis服务器的随机标识符(用于Sentinel和集群) |
| tcp_port | TCP/IP 监听端口 |
| uptime_in_seconds | 自Redis服务器启动以来,经过的秒数 |
| uptime_in_days | 自Redis服务器启动以来,经过的天数 |
| hz | redis内部调度(进行关闭timeout的客户端,删除过期key等等)频率,程序规定serverCron每秒运行10次 |
| configured_hz | |
| lru_clock | 自增的时钟,用于LRU管理,该时钟100ms(hz=10,因此每1000ms/10=100ms执行一次定时任务)更新一次 |
| executable | 执行文件,服务程序在哪 |
| config_file | 配置文件路径 |
clients: 已连接客户端信息,包含以下域
| connected_clients | 已连接客户端的数量(不包括通过从属服务器连接的客户端) |
| client_longest_output_list | 当前连接的客户端当中,最长的输出列表 |
| client_longest_input_buf | 当前连接的客户端当中,最大输入缓存 |
| blocked_clients | 正在等待阻塞命令(BLPOP、BRPOP、BRPOPLPUSH)的客户端的数量 |
memory: 内存信息,包含以下域
| used_memory | 由Redis分配器分配的内存总量,不包含内存碎片,也就是实际使用的内存,以字节(byte)为单位。 |
| used_memory_human | 以人类可读的格式返回Redis分配的内存总量 |
| used_memory_rss | 从操作系统的角度,返回Redis已分配的内存总量(俗称常驻集大小)。这个值和top、ps等命令的输出一致。包含内存碎片,整个进程的内存,包含了上面的实际内存;如果rss过大导致内部碎片大,内存资源浪费,和fork的耗时和cow内存都会增大 |
| used_memory_rss_human | |
| used_memory_peak | Redis的内存消耗峰值(以字节为单位) |
| used_memory_peak_human | 以人类可读的格式返回Redis的内存消耗峰值 |
| used_memory_peak_perc | (used_memory/used_memory_peak)*100%,内存使用峰值占用总内存的百分比 |
| used_memory_overhead | Redis为了维护数据集的内部机制所需的内存开销,包括所有客户端输出缓冲区、查询缓冲区、AOF重写缓冲区和主从复制的backlog |
| used_memory_startup | Redis服务器启动时消耗的内存 |
| used_memory_dataset | used_memory - used_memory_overhead |
| used_memory_dataset_perc | 100%*(used_memory_dataset/(used_memory—used_memory_startup)),当前数据集占用启动后内存的百分比 |
| allocator_allocated | 分配器分配的内存 |
| allocator_active | 分配器活跃的内存 |
| allocator_resident | 分配器常驻的内存 |
| total_system_memory | 整个系统内存 |
| total_system_memory_human | |
| used_memory_lua | Lua引擎所使用的内存大小(以字节为单位) |
| used_memory_lua_human | |
| mem_fragmentation_ratio | used_memory_rss和used_memory之间的比率,used_memory_rss/ used_memory |
| maxmemory | Redis实例的最大内存配置 |
| maxmemory_human | |
| maxmemory_policy | 当达到maxmemory时的淘汰策略 |
| allocator_frag_ratio | 分配器的碎片率 |
| allocator_frag_bytes | 分配器的碎片大小(以字节为单位) |
| allocator_rss_ratio | 分配器常驻内存比例 |
| allocator_rss_bytes | 分配器的常驻内存大小(以字节为单位) |
| rss_overhead_ratio | 常驻内存开销比例 |
| rss_overhead_bytes | 常驻内存开销大小(以字节为单位) |
| mem_fragmentation_ratio | 内存碎片率,used_memory_rss和used_memory之间的比率 |
| mem_fragmentation_bytes | 内存碎片的大小(以字节为单位) |
| mem_not_counted_for_evict | 被驱逐的大小 |
| mem_replication_backlog | repl_backlog |
| mem_clients_slaves | clients_slaves |
| mem_clients_normal | clients_normal |
| mem_aof_buffer | aof的写缓冲大小 |
| mem_allocator | 在编译时指定的,Redis所使用的内存分配器。可以是libc 、jemalloc或者tcmalloc |
注意:
- 在理想情况下,used_memory_rss的值应该只比 used_memory稍微高一点儿。当rss>used,且两者的值相差较大时,表示存在(内部或外部的)内存碎片。内存碎片的比率可以通过mem_fragmentation_ratio 的值看出当 used > rss 时,表示Redis的部分内存被操作系统换出到交换空间了,在这种情况下,操作可能会产生明显的延迟
- 当Redis释放内存时,分配器可能会,也可能不会,将内存返还给操作系统
- 如果Redis释放了内存,却没有将内存返还给操作系统,那么used_memory的值可能和操作系统显示的 Redis 内存占用并不一致
- 查看used_memory_peak的值可以验证这种情况是否发生
- active_defrag_running 表示有没有活动的defrag任务正在运行,1表示有活动的defrag任务正在运行(defrag:表示内存碎片整理)
- lazyfree_pending_objects 等待释放的对象数(由于使用ASYNC选项调用UNLINK或FLUSHDB和FLUSHALL)
注意2:
- 内存碎片过大时可进行碎片整理,当mem_fragmentation_ratio<1时用swap多,mem_fragmentation_ratio>1.5时碎片较多
- 手动整理:redis-cli memory purge
手动整理内存碎片,但会阻塞主进程,且是粗暴的清理脏页来达到回收内存
- 自动整理: redis-cli CONFIG SET activedefrag yes
自动内存整理,进行数据整合(复制、转移),也会阻塞主进程
persistence: RDB 和 AOF 的相关信息
| loading | 服务器是否正在载入持久化文件 |
| rdb_changes_since_last_save | 离最近一次成功生成rdb文件,写入命令的个数,即有多少个写入命令没有持久化 |
| rdb_bgsave_in_progress | 0为没有RDB备份,1为正在 |
| rdb_last_save_time | 离最近一次成功创建rdb文件的时间戳。当前时间戳 - rdb_last_save_time=多少秒未成功生成rdb文件 |
| rdb_last_bgsave_status | 最近一次rdb持久化是否成功 |
| rdb_last_bgsave_time_sec | 最近一次成功生成rdb文件耗时秒数 |
| rdb_current_bgsave_time_sec | 如果服务器正在创建rdb文件,那么这个域记录的就是当前的创建操作已经耗费的秒数 |
| rdb_last_cow_size | RDB过程中父进程与子进程相比执行了多少修改(包括读缓冲区,写缓冲区,数据修改等) |
| aof_enabled | 是否开启了aof |
| aof_rewrite_in_progress | 标识aof的rewrite操作是否在进行中 |
| aof_rewrite_scheduled | rewrite任务计划,当客户端发送bgrewriteaof指令,如果当前rewrite子进程正在执行,那么将客户端请求的bgrewriteaof变为计划任务,待aof子进程结束后执行rewrite |
| aof_last_rewrite_time_sec | 最近一次aof rewrite耗费的时长 |
| aof_current_rewrite_time_sec | 如果rewrite操作正在进行,则记录所使用的时间,单位秒 |
| aof_last_bgrewrite_status | 上次bgrewriteaof操作的状态 |
| aof_last_write_status | 上次aof写入状态 |
| aof_last_cow_size | AOF过程中父进程与子进程相比执行了多少修改(包括读缓冲区,写缓冲区,数据修改等) |
stats: 一般统计信息
| total_connections_received | 接收到的总连接数,可以写脚本看新创建连接个数,如果新创建连接过多,过度地创建和销毁连接对性能有影响,说明短连接严重或连接池使用有问题,需调研代码的连接设置 |
| total_commands_processed | redis处理的命令数 |
| instantaneous_ops_per_sec | redis当前的qps,redis内部较实时的每秒执行的命令数 |
| total_net_input_bytes | redis网络总入口流量字节数 |
| total_net_output_bytes | redis网络总出口流量字节数 |
| instantaneous_input_kbps | redis网络入口当前kps |
| instantaneous_output_kbps | redis网络出口当前kps |
| rejected_connections | 拒绝的连接个数,redis连接个数达到maxclients限制,拒绝新连接的个数 |
| sync_full | 主从完全同步成功次数 |
| sync_partial_ok | 主从部分同步成功次数 |
| sync_partial_err | 主从部分同步失败次数 |
| expired_keys | 运行以来过期的key的数量 |
| expired_stale_perc | 过期的比率 |
| expired_time_cap_reached_count | 过期计数 |
| evicted_keys | 运行以来清除(超过了maxmemory后)的key的数量 |
| keyspace_hits | 命中次数 |
| keyspace_misses | 未命中次数 |
| pubsub_channels | 当前消息队列使用中的频道数量 |
| pubsub_patterns | 当前消息队列使用的模式的数量 |
| latest_fork_usec | 最近一次fork操作阻塞redis进程的耗时数,单位微秒 |
| migrate_cached_sockets | 是否已经缓存了到该地址的连接 |
| slave_expires_tracked_keys | 从实例到期key数量 |
| active_defrag_hits | 主动碎片整理命中次数 |
| active_defrag_misses | 主动碎片整理未命中次数 |
| active_defrag_key_hits | 主动碎片整理key命中次数 |
| active_defrag_key_misses | 主动碎片整理key未命中次数 |
| master_host | MasterIP |
| master_port | |
| master_link_status | Master的连接状态(up/down) |
| master_last_io_seconds_ago | 最近一次主从交互之后的秒数 |
| master_sync_in_progress | 表示从服务器是否一直在与主服务器进行同步 |
| slave_repl_offset | 从服务器复制偏移量 |
| slave_priority | 从服务器的优先级 |
| slave_read_only | 从服务是否只读 |
replication: 主/从复制信息
| role | 实例的角色,是master or slave |
| connected_slaves | 连接的slave实例个数 |
| master_replid | 主实例启动随机字符串 |
| master_replid2 | 主实例启动随机字符串2 |
| master_repl_offset | 主从同步偏移量,此值如果和上面的slave_repl_offset相同说明主从一致没延迟,与master_replid可被用来标识主实例复制流中的位置 |
| second_repl_offset | 主从同步偏移量2,此值如果和上面的offset相同说明主从一致没延迟 |
| repl_backlog_active | 复制积压缓冲区是否开启 |
| repl_backlog_size | 主从复制时的缓冲区大小(repl_back_buffer),单位字节 |
| repl_backlog_first_byte_offset | 复制缓冲区里偏移量的大小 |
| repl_backlog_histlen | 此值等于master_repl_offset - repl_backlog_first_byte_offset,该值不会超过repl_backlog_size的大小 |
cpu: CPU 计算量统计信息
| used_cpu_sys | 将所有redis主进程在核心态所占用的CPU时求和累计起来 |
| used_cpu_user | 将所有redis主进程在用户态所占用的CPU时求和累计起来 |
| used_cpu_sys_children | 将后台进程在核心态所占用的CPU时求和累计起来 |
| used_cpu_user_children | 将后台进程在用户态所占用的CPU时求和累计起来 |
cluster: Redis 集群信息
开启集群后才会显示
| cluster_enabled | 实例是否启用集群模式 |
keyspace: 数据库相关的统计信息
使用了几个库,就显示几个库,默认有16个库
| db0 | db0的key的数量,以及带有生存期的key的数,平均存活时间 |
配置文件解读: redis.conf
bind 127.0.0.1 监听地址,空格隔开监听多个
protected-mode yes 3.2版本以后,没有bind和密码,允许本地访问,不允许远程访问
port 6379 监听端口
tcp-backlog 511 三次握手的时候server端收到client ack确认号之后的队列值,避免最大并发的时候出现拒绝访问,采取队列排队连接
timeout 0 连接超时时间,默认0,永不超时
tcp-keepalive 300 tcp会话保持时间
daemonize no 守护进程方式运行,默认为no,关闭
supervised no 和操作系统相关参数,可以设置通过upstart和systemd管理Redis守护进程,centos 7以后都使用systemd
pidfile /var/run/redis_6379.pid pid文件路径
loglevel notice 日志级别
logfile /var/log/redis/redis.log 日志文件路径
databases 16 设置db库的数量,默认16个,一般用第一个
always-show-logo yes 启动服务时,是有显示log
save 900 1 900秒内有1个键数据发生更改就自动RDB备份
save 300 10 300秒变10次就触发
save 60 10000
stop-writes-on-bgsave-error yes 快照出错时是否禁止redis写入操作,如果磁盘空间满了,会引起redis不可访问,生产环境可改为no,尽最大可能保证redis是可访问的
rdbcompression yes 持久化到RDB文件时,是否压缩,"yes"为压缩,"no"则反之
rdbchecksum yes 是否开启RC64校验,默认是开启
dbfilename dump.rdb rdb快照文件名
dir /var/lib/redis rdb快照文件保存路径
replica-serve-stale-data yes 当从库同步主库时失去连接或者复制正在进行被断开,从机库有两种运行方式:
1、设置为yes(默认设置),从库会继续响应客户端的读请求。
2、设置为no,除去指定的命令之外的任何请求都会返回一个错误"SYNC with master in progress"
replica-read-only yes 是否设置从库只读
repl-diskless-sync no 是否使用socket方式复制数据(无盘同步),新slave连接时候需要做数据的全量同步,redis-server就要从内存dump出新的RDB文件,然后从master传到slave,有两种方式把RDB文件传输给客户端:
1、基于硬盘(disk-backed):master创建一个新进程dump RDB,RDB完成之后由父进程(即主进程)传给slaves
2、基于socket(diskless):master创建一个新进程直接dump RDB到slave的socket,不经过主进程,不经过硬盘
基于硬盘的话,RDB文件创建后,一旦创建完毕,可以同时服务更多的slave,但是基于socket的话,新slave连接、到master之后得逐个同步数据
在磁盘较慢并且网络较快的时候,可以用diskless(yes),否则使用磁盘(no)
repl-diskless-sync-delay 5 复制的延迟时间,0为关闭,在延迟时间内连接的新客户端,会一起通过disk方式同步数据,但是一旦复制开始还没有结束之前,master节点不会再接收新slave的复制请求,直到下一次同步开始
repl-ping-slave-period 10 slave根据master指定的时间进行周期性的PING监测
repl-timeout 60 复制连接的超时时间,需要大于repl-ping-slave-period,否则会经常报超时
repl-disable-tcp-nodelay no 在socket模式下是否在slave套接字发送sync之后禁用TCP_NODELAY
repl-backlog-size 512mb 主从复制缓冲区内存大小,只有在slave连接之后才分配内存
repl-backlog-ttl 3600 多次时间master没有slave连接,就清空backlog缓冲区
replica-priority 100 当master不可用,Sentinel会根据slave的优先级选举一个master,最低的优先级的slave,当选master,而配置成0,永远不会被选举
requirepass foobared 设置连接密码
rename-command 重命名一些高危命令
rename-command keys "linux" keys命令改名为linux
rename-command flushall "" 禁用flushall命令
maxclients 10000 Redis最大连接客户端
maxmemory 最大内存,单位为bytes字节,8G内存的计算方式8(G)=8*1024M*1024K*1024b,或者8589934592字节,4592到K,9934到M,8589到G,需要注意的是slave的输出缓冲区是不计算在maxmemory内
appendonly no 是否开启AOF日志记录,默认redis使用的是rdb方式持久化,这种方式在许多应用中已经足够用了,但是redis如果中途宕机,会导致可能有几分钟的数据丢失(取决于dumpd数据的间隔时间),根据save来策略进行持久化,Append Only File是另一种持久化方式,可以提供更好的持久化特性,Redis会把每次写入的数据在接收后都写入appendonly.aof文件,每次启动时Redis都会先把这个文件的数据读入内存里,先忽略RDB文件
appendfilename "appendonly.aof" AOF文件名
appendfsync everysec aof策略配置,no为关闭,由操作系统来负责数据同步到磁盘(一般30s一次)
always为每次写入都执行fsync,保证数据同步到磁盘
everysec为每秒执行一次fsync,可能会导致丢失这1s数据
no-appendfsync-on-rewrite no 在rewrite期间,是否把新记录的追加到buffer区,主要考虑磁盘IO和请求阻塞时间
默认为no,表示"不暂缓",新的aof记录仍然会被立即同步,Linux的默认fsync策略是30秒,也就是新数据写入buffer,写入旧aof和临时aof都进行
如果为yes可能丢失30秒数据,但由于yes性能较好而且会避免出现阻塞因此比较推荐,也就是新数据直接写入临时aof文件,全部写入临时aof
auto-aof-rewrite-percentage 100 当Aof日志增长超过指定百分比例时重写AOF(文件有64m时触发,按100%增长,128m时再次触发,重写后可能是100m,再次100%增长到200m时,再次触发重写...),设置为0表示不自动重写Aof日志,重写是为了使aof体积保持最小,但是还可以确保保存最完整的数据
auto-aof-rewrite-min-size 64mb 触发aof rewrite的最小文件大小
aof-load-truncated yes 是否加载由于其他原因导致的末尾异常的AOF文件(主进程被kill/断电等)
aof-use-rdb-preamble no 4.0新增RDB-AOF混合持久化格式,aof文件数据记录格式
在开启之后,AOF重写产生的文件将同时包含RDB格式的内容和AOF格式的内容,其中RDB格式的内容用于记录已有的数据,而AOF格式的内存则用于记录最近发生了变化的数据,这样Redis就可以同时兼有RDB持久化和AOF持久化的优点(既能够快速地生成重写文件,也能够在出现问题时,快速地载入数据)
新版本redis 5.0.3以后,默认开启了,aof文件变小,但导致不能编辑此文件,因为是二进制数据,所以如果需要能够手动修改次文件,次配置在新版本中要关闭
lua-time-limit 5000 lua脚本的最大执行时间,单位为毫秒
cluster-enabled yes 是否开启集群模式,默认是单机模式
cluster-config-file nodes-6379.conf 由node节点自动生成的集群配置文件
cluster-node-timeout 15000 集群中node节点连接超时时间
cluster-replica-validity-factor 10 在执行故障转移的时候可能有些节点和master断开一段时间数据比较旧,这些节点就不适用于选举为master,超过这个时间的就不会被进行故障转移
cluster-migration-barrier 1 集群迁移屏障,一个主节点拥有的至少正常工作的从节点,即如果主节点的slave节点故障后会将多余的从节点分配到当前主节点成为其新的从节点。
cluster-require-full-coverage no 集群请求槽位全部覆盖,如果一个主库宕机且没有备库就会出现集群槽位不全,那么yes情况下redis集群槽位验证不全就不再对外提供服务,而no则可以继续使用但是会出现查询数据查不到的情况(因为有数据丢失)
slowlog-log-slower-than 10000 以微秒为单位的慢日志记录,为负数会禁用慢日志,为0会记录每个命令操作
slowlog-max-len 128 滚动记录内存中的慢查询记录数量,128条
#redis高级设置
activedefrag yes #内存碎片整理总开关,开启后才有可能执行碎片整理
active-defrag-ignore-bytes 100mb #内存碎片的字节数达到此阀值(默认100MB)时,允许整理
active-defrag-threshold-lower 10 #内存碎片空间占操作系统分配给 Redis 的总空间比例达到此阀值(默认10%)时,允许整理
active-defrag-threshold-upper 100 #内存碎片空间占操作系统分配给Redis的总空间比例达到此阀值(默认100%)时,则尽最大努力整理
active-defrag-cycle-min 5 #清理内存碎片占用 CPU 时间的比例不低于此阀值(默认5%),保证清理能正常开展
active-defrag-cycle-max 75 #清理内存碎片占用CPU 时间的比例不高于此阀值(默认75%),一旦超过则停止清理
active-defrag-max-scan-fields 1000 #碎片整理扫描set/hash/zset/list时,仅当set/hash/zset/list的长度小于此阀值时,才会将此key加入碎片整理
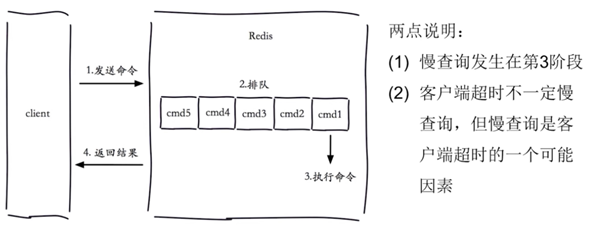
redis慢查询:
原理:
- 客户端向redis发起请求,到达服务端后进入等待执行队列,先进先出,一个一个执行,执行命令的时间是redis慢查询的关注点

 浙公网安备 33010602011771号
浙公网安备 33010602011771号