spark集群搭建(三台虚拟机)——spark集群搭建(5)
!!!该系列使用三台虚拟机搭建一个完整的spark集群,集群环境如下:
virtualBox5.2、Ubuntu14.04、securecrt7.3.6_x64英文版(连接虚拟机)
jdk1.7.0、hadoop2.6.5、zookeeper3.4.5、Scala2.12.6、kafka_2.9.2-0.8.1、spark1.3.1-bin-hadoop2.6
本文在前面基础上搭建spark
一、spark1
下面操作在spark1上:
1、spark(spark1.3.1-bin-hadoop2.6)下载解压重命名
2、配置环境变量
export SPARK_HOME=/usr/local/bigdata/spark
export PATH=$PATH:$SPARK_HOME/bin
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
修改配置文件
1、spark-env.sh
$ cd ./spark/conf #进入spark的conf目录下 $ mv spark-env.sh.template spark-env.sh $ vim spark-env.sh
添加如下配置
export JAVA_HOME=/usr/local/bigdata/jdk
export SCALA_HOME=/usr/local/bigdata/scala
export SPARK_MASTER_IP=192.168.43.XXX
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/usr/local/bigdata/hadoop/etc/hadoop
2、slaves
$ mv slaves.template slaves $ vim slaves
添加三台主机名
spark1
spark2
spark3
二、spark2和spark3
1、拷贝spark到另外两台机器上
root@spark1:/usr/local/bigdata# scp -r spark root@spark2://usr/local/bigdata/ root@spark1:/usr/local/bigdata# scp -r spark root@spark3://usr/local/bigdata/
2、同理配置spark2和spark3的环境变量,或者直接把环境变量文件拷贝过去
三、启动spark
进入spark的sbin目录下,执行:
$ ./start-all.sh
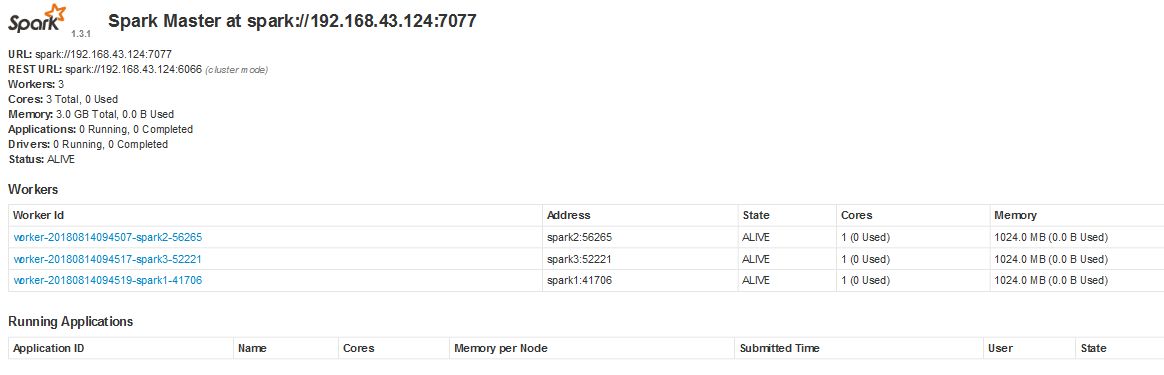
此时查看jps,spark1上有Master
root@spark1:/usr/local/bigdata/spark/sbin# jps 3489 Worker 2972 NodeManager 2643 SecondaryNameNode 3541 Jps 2358 NameNode 3330 Master 2847 ResourceManager 2482 DataNode
spark2
root@spark2:/usr/local/bigdata# jps 2838 Jps 2579 NodeManager 2786 Worker 2486 DataNode
spark3
root@spark3:/usr/local/bigdata# jps 3988 Jps 3731 NodeManager 3936 Worker 3637 DataNode
浏览器输入http://spark1:8080/
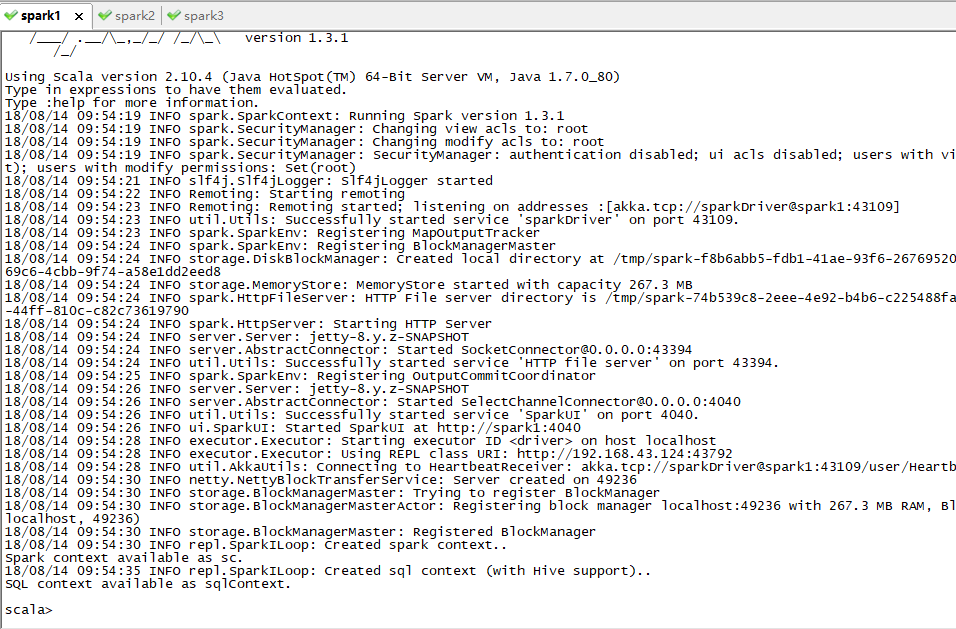
$ spark-shell #进入shell

 浙公网安备 33010602011771号
浙公网安备 33010602011771号