spark集群搭建(三台虚拟机)——hadoop集群搭建(2)
!!!该系列使用三台虚拟机搭建一个完整的spark集群,集群环境如下:
virtualBox5.2、Ubuntu14.04、securecrt7.3.6_x64英文版(连接虚拟机)
jdk1.7.0、hadoop2.6.5、zookeeper3.4.5、Scala2.12.6、kafka_2.9.2-0.8.1、park1.3.1-bin-hadoop2.6
前面搭建了spark集群需要的系统环境,本文在前文基础上搭建hadoop集群
一、配置几个配置文件
hadoop的下载和配置只需在spark1上操作,然后拷贝到另外两台机器上即可,下面的配置均在spark1上进行
$ cd /usr/local/bigdata/hadoop #进入hadoop安装目录
$ cd ./etc/hadoop
1、core-site.xml
$ vim core-site.xml
添加如下,指定namenode的地址:
<configuration> <property> <name>fs.default.name</name> <value>hdfs://spark1:9000</value> </property> </configuration>
2、hdfs-site.xml
$ vim hdfs-site.xml
<configuration> <property> <name>dfs.name.dir</name> <value>/usr/local/hadoop/data/namenode</value> </property> <property> <name>dfs.data.dir</name> <value>/usr/local/hadoop/data/datanode</value> </property> <property> <name>dfs.tmp.dir</name> <value>/usr/local/hadoop/data/tmp</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> </configuration>
3、mapred-site.xml,指定hadoop运行在yarn之上
$ mv mapred-site.xml.template mapred-site.xml
$ vim mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
4、yarn-site.xml
$ vim yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>spark1</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
5、slaves
$ vim slaves
spark1 spark2 spark3
6、hadoop-env.sh
vim hadoop-env.sh
输入jdk完整路径
export JAVA_HOME=/usr/local/bigdata/jdk
二、另外两台机器
使用拷贝命令将hadoop拷贝过去
$ cd /usr/local/bigdata $ scp -r hadoop root@spark2:/usr/local/bigdata
$ scp -r hadoop root@spark3:/usr/local/bigdata
三、配置hadoop环境变量,三台机器均需要配置
export HADOOP_HOME=/usr/local/bigdata/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export HADOOP_COMMOM_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
四、启动hadoop集群
格式化namenode
$ hdfs namenode -format
$ start-dfs.sh
此时三台机器启动如下,才算成功
spark1
root@spark1:/usr/local/bigdata/hadoop/etc/hadoop# jps 4275 Jps 3859 NameNode 4120 SecondaryNameNode 3976 DataNode
spark2
root@spark2:/usr/local/bigdata/hadoop/etc/hadoop# jps 6546 DataNode 6612 Jps
spark3
root@spark3:/usr/local/bigdata/hadoop/etc/hadoop# jps
4965 DataNode
5031 Jps
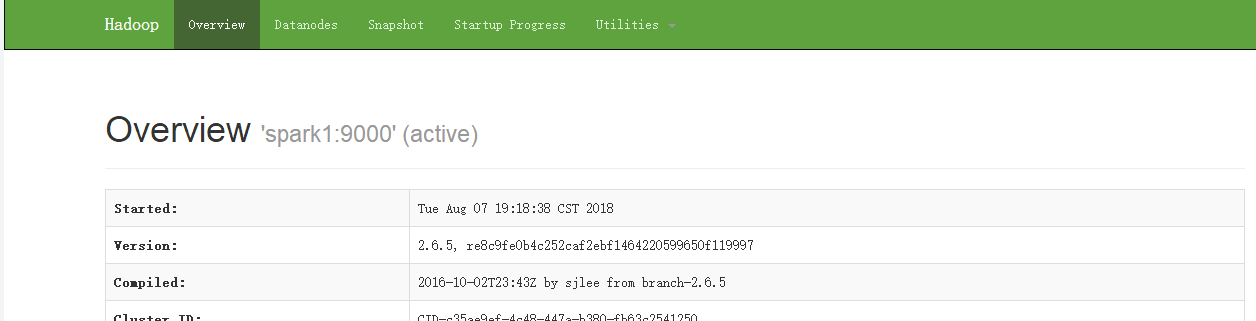
进入浏览器,访问http://spark1:50070
五、启动yarn集群
$ start-yarn.sh
此时spark1
root@spark1:/usr/local/bigdata/hadoop/etc/hadoop# jps
3859 NameNode
4803 Jps
4120 SecondaryNameNode
3976 DataNode
4443 ResourceManager
4365 NodeManager
spark2
root@spark2:/usr/local/bigdata/hadoop/etc/hadoop# jps
6546 DataNode
6947 Jps
6771 NodeManager
spark3
root@spark3:/usr/local/bigdata/hadoop/etc/hadoop# jps
5249 Jps
4965 DataNode
5096 NodeManager
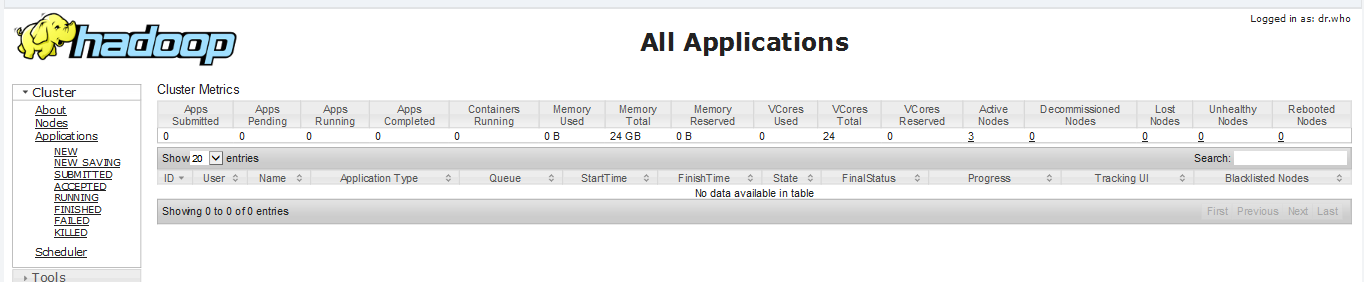
浏览器输入 spark1:8088

 浙公网安备 33010602011771号
浙公网安备 33010602011771号