

基于docker 容器实现伪分布式hadoop集群
如果你的配置是1核1G在这里我劝你换台服务器 尽量高于2核2g。关于docker的搭建配置再此不在赘诉。可以参考我之前的文章 Centos7.5 Docker部署.Core项目
接下来就是正式搭建hadoop环境
- 拉取镜像 https://gitee.com/sunshine223518/docker-hadoop.git
-
![]()
- 进入docker-hadoop目录 cd /root/docker-hadoop/
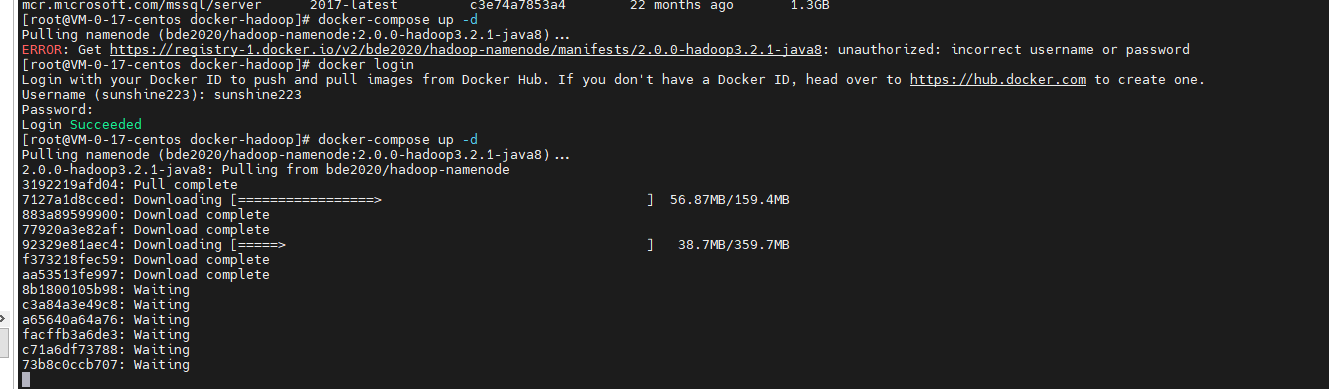
- 执行以下命令 docker-compose up -d 执行你会看到如下信息
![]()
-
到这里 Hadoop 集群已经创建完成了,如果想增加节点,可以通过修改 docker-hadoop 中的
docker-compose.yml文件来实现。例如,我们给当前集群增加两个数据节点 datanode 对
docker-compose.yml文件修改如下:datanode:
image: bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8
container_name: datanode
restart: always
volumes:
- hadoop_datanode:/hadoop/dfs/data
environment:
SERVICE_PRECONDITION: "namenode:9870"
env_file:
- ./hadoop.env
datanode2:
image: bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8
container_name: datanode2
restart: always
volumes:
- hadoop_datanode2:/hadoop/dfs/data
environment:
SERVICE_PRECONDITION: "namenode:9870"
env_file:
- ./hadoop.env
datanode3:
image: bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8
container_name: datanode3
restart: always
volumes:
- hadoop_datanode3:/hadoop/dfs/data
environment:
SERVICE_PRECONDITION: "namenode:9870"
env_file:
- ./hadoop.env - 然后重新执行
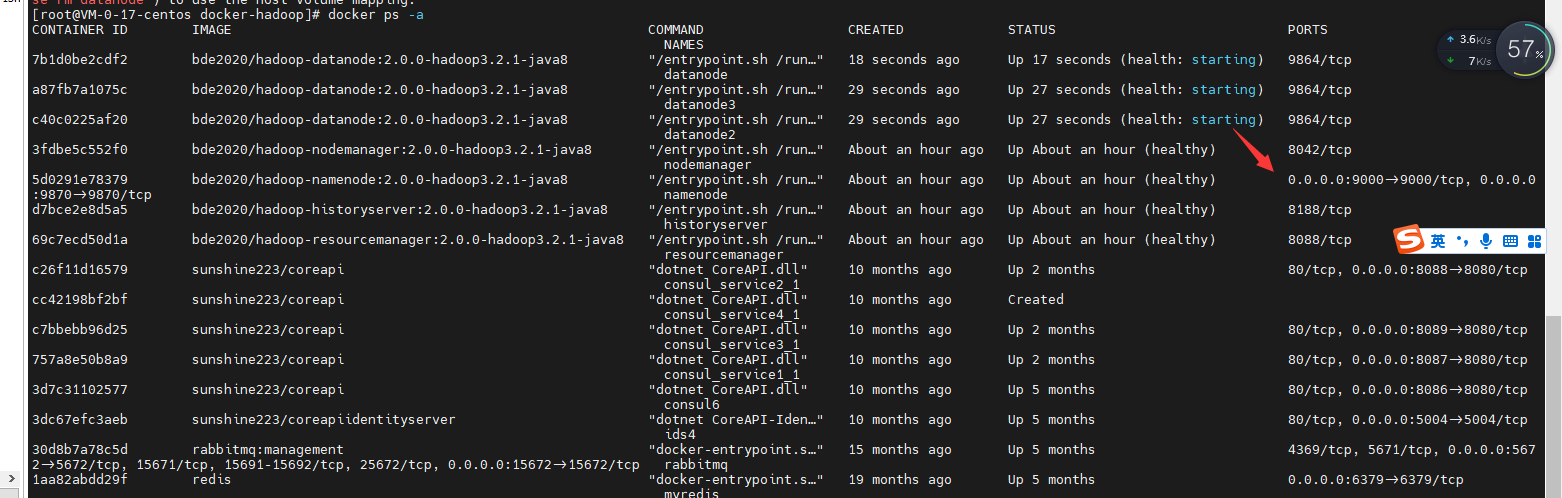
docker-compose up -d增加节点 - 最后输入 docker ps -a 进行查看是否运行成功
![]()
看到以上信息那么恭喜你,以及集群完成!可在浏览器中输入IP地址加9870端口号进行查看

测试 Hadoop 集群
测试准备
我们使用简单的词频统计 mapreduce 任务来测试 Hadoop 集群
首先下载 hadoop-mapreduce-examples jar 包。然后使用如下命令将这个 jar 包拷贝到 namenode 节点
docker cp \hadoop-mapreduce-examples-2.7.1.jar namenode:/tmp/
然后我们创建一个 input.txt 测试文件,并输入文字内容(自定义)
春华秋实,落叶纷飞
然后也将这个输入文件拷贝到 namenode 节点中
docker cp .\input.txt namenode:/tmp/
开始测试
首先使用如下命令进入到 namenode 容器中,并进入到 tmp 目录
docker exec -it namenode /bin/bash
cd tmp/
然后使用如下命令在 HDFS 中创建一个 input 目录
hdfs dfs -mkdir -p /user/root/input
将输入文件 input.txt 存储到 HDFS 中
hdfs dfs -put input.txt /user/root/input
# 查看输入文件内容
hdfs dfs -cat /user/root/input/input.txt
Tips:可以将文件通过如下命令添加到指定的 Datanode 节点中hdfs dfs -put Input.txt the-datanode-id (不是必须条件)
最后使用如下命令在 Hadoop 集群中运行 wordcount 词频统计 mapreduce 任务
hadoop jar hadoop-mapreduce-examples-2.7.1.jar wordcount input output
# 查看运行结果
hdfs dfs -cat output/part-r-00000

 浙公网安备 33010602011771号
浙公网安备 33010602011771号