
从 2020 年至今,已经参与过 6 次 年终活动,但今年这次是最狼狈的,发生了太多状况。
以至于,我每个节点都要盯到 0 点多,生怕又报错,这个活动会持续 20 天。
一、活动前
在活动前的周五的晚上 23 点,两个运营先后反馈充值页面在微信内显示白屏,就算只剩下一个提示,没有业务呈现。
年终活动会与充值相关,当即就引起了我们的重视。
迅速响应,当时运营以为是大范围的,因为同时收到,但事后发现是个别的人,同一个人反馈了两个运营。
根据 IP 地址,将 Nginx 请求的日志和前端监控的日志对应起来后,确认是请求脚本出错了。
查看行为轨迹的日志,发现就算点击了重新加载也没用。
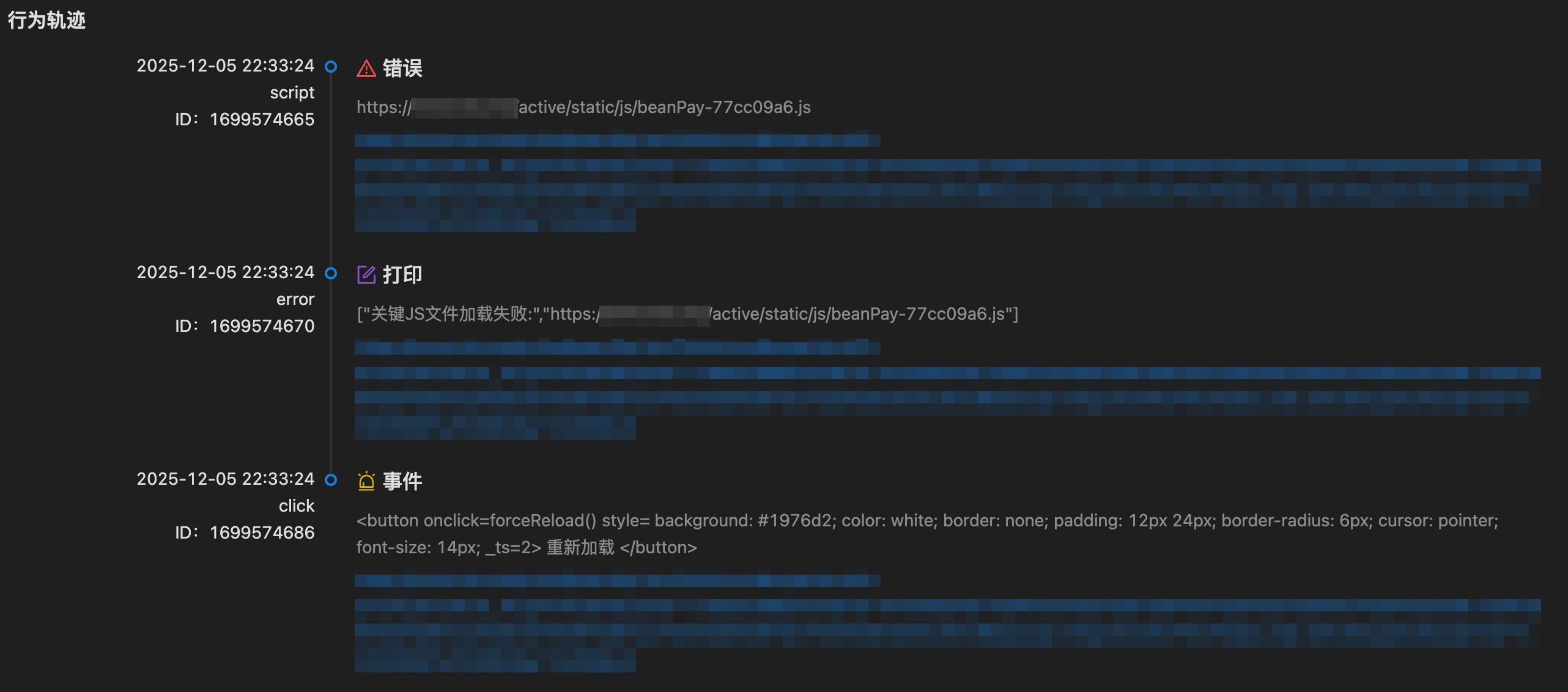
但我将地址复制到自己的浏览器中,又是能正常访问的。在 Nginx 日志中,发现此类脚本的请求响应码都是 304。
也就是说,页面请求的是缓存中的脚本。分析后,得出一个在微信环境中问题发生的步骤,但比较难复现。
- 首次访问,微信浏览器从服务器下载资源(beanPay-77cc09a6.js),并完整地记录下响应头中的 ETag 或 Last-Modified 标识符以及缓存规则(如 Cache-Control)。
- 微信清理缓存,你或系统为节省空间,在微信的“设置-通用-存储空间”中清理了缓存。这删除了资源文件本身(beanPay-77cc09a6.js 文件实体),但可能没有完全删除或重置与该URL关联的缓存元数据(特别是 ETag)。
- 再次请求,微信浏览器发起请求时,依然根据内存或数据库中保留的记录,在请求头中带上了之前缓存的 If-None-Match (对应ETag) 标识。服务器检查发现该ETag对应资源未修改,便正常返回 304 Not Modified。
- 结果,微信浏览器收到304后,试图使用本地缓存,但文件已被清理,找不到资源实体,最终导致页面加载错误(如脚本加载失败)。
我们想到的策略就算,完善刚刚白屏中的提示文案,提醒用户去更换浏览器试试。
并且在页面出错时,动态的添加脚本,并为其自动增加时间戳,期望在重新请求后,可以破坏资源缓存。
<script src="/static/js/beanPay-58a0f5a9.js?v=1766545846752"></script>
在实际页面访问中,还会访问到已经删除了的脚本文件,那么就算加时间戳也无济于事。
但是通常提示和加载优化后,绝大部分的用户还是能正确将页面加载出来。
二、活动中
1)数据库连接报错
活动开始后的一天凌晨,1点半后,年终活动和充值页面打不开了,一直加载中。
插个背景,由于历史原因,我们很多活动的接口是用 Node 编写的,而 Node 接口内部还会调用服务端的接口,
在凌晨 3 点 20 的时候,就有监控组的客服同事打我电话,我马上起来排查,第一感觉就是非代码问题。
排查 1 个小时候后,果然在 Node 日志中发现了错误,重启了服务器后,故障恢复。
Error [SequelizeDatabaseError]: read ECONNRESET
year_end_list Error [SequelizeDatabaseError]: read ECONNRESET
凌晨没有联系到运维,就给他留言了,早上回复了,说是内存水位线过高导致数据库重启。
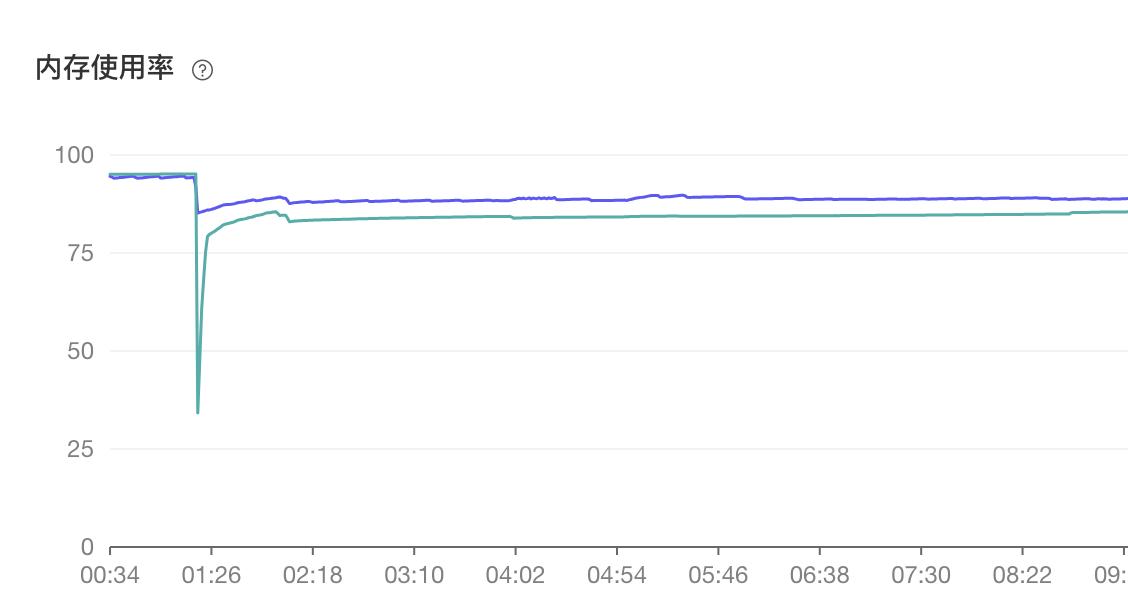
服务端其实也影响了,但是因为会自动重连,没有大范围报错。
而我们使用的 sequelize3.30 没有重连机制,所以数据库在异常重启后,就断连了。
2026 年的一个重点就是升级 sequelize.js,现在的版本实在太旧,最新版本已经到 6 了。
而造成数据库重启的原因是服务端的 pod 数量增加,占用的数据库连接也增加,pod 连接数据库的默认连接也翻倍。
高峰期相当于日常的 4 倍,持续增高,慢慢将数据库内存磨光,出现了内存水位线过高导致的 OOM 报错。
在大活动之前,服务端升级了资源,结果出现了意外。
其实他们升级的太晚了,在活动开始前一天才升级,如果是我,绝对要提前一周观察升级后的变化。
在知道原因后,我在白天写了份重连的逻辑,就是加个定时器定时的去执行语句,当出错时,重新连接。
不过在测试环境没有模拟出那个报错,所以无法验证,后面就想到直接监控错误日志。
一旦有这个错误,就自动重启服务器,也可以重新连接数据库,并且要将错误加到飞书告警中,让我们第一时间知道。
2)接口大量挂起
3 天后的周五,晚上有个两个活动的赛段结点,结束后就有大量的请求刷新去看结果。
结果持续 5 分钟,接口无响应,五分钟内有 5000 多次请求,涉及 268 个 IP,第 6 分钟自动恢复。
查看 Node 的监控发现,并发量也不是很大,QPS 最多 38 左右,服务器的 CPU、内存等指标都不高。
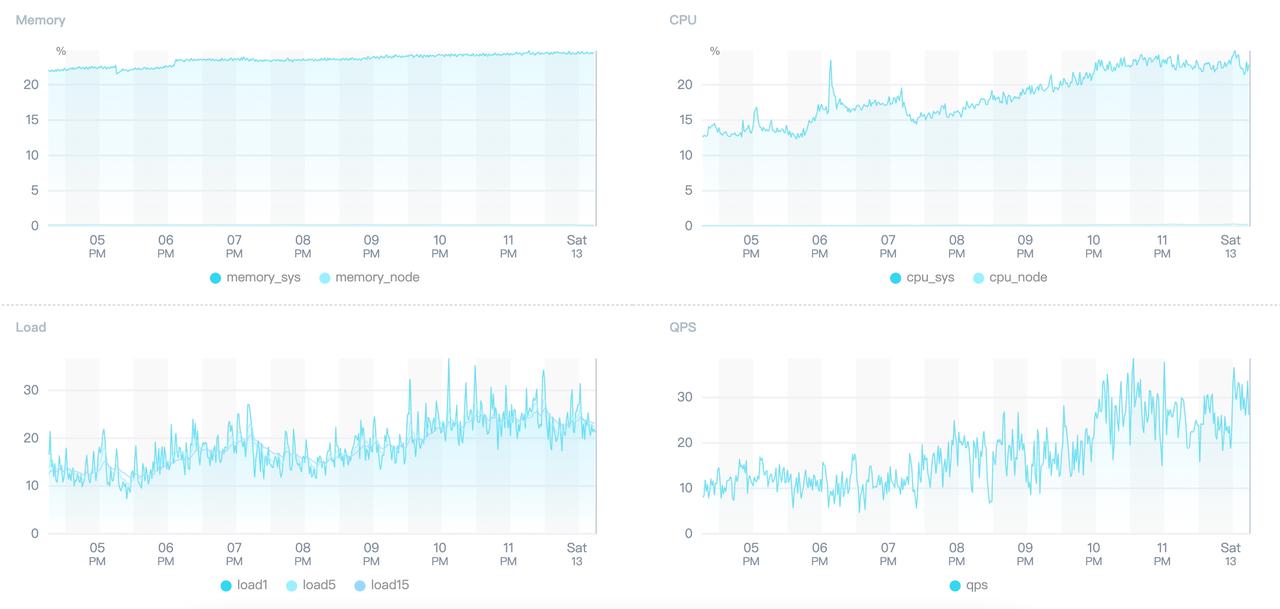
马上联系运维,结果又没联系到,我第一反应,可能还是服务端的内部接口出问题了。
周六早上运费回消息,开始排查,那一天没出门,一直在推运维、测试、服务端的人排查和修改加校验。
下午让测试组对活动的接口进行压测,之前是对活动页面压测,没有发现问题。
对接口压测后,马上暴露了问题,出现了大量 499 请求,服务端的两个内部接口也超时严重。
原来是个订阅同步的功能将 CPU 拉高,影响了服务的调用,于是将该功能拆分,单独运行。
与此同时,我们也对活动接口做了一轮优化,内部有个单查询的 SQL 语句改成了批量查询。
SELECT * FROM `app_user` WHERE `id` = ?; SELECT * FROM `app_user` WHERE `id` IN (?, ?);
接口慢响应比例从万分之 8 降低至万分之 2,并且关闭了预请求。
原来会在页面呈现的 30 秒后,自动去拉取页面内的其他 Tab 栏内的接口,初衷是个体验优化。
但实际上线后,就发现并不是很需要预请求,在某个阶段的活动结束后,用户并不会再去切换 Tab 栏浏览。
所以大部分的请求都浪费掉了,而且结点时请求过多,有可能出现性能问题。
故而关闭了此优化,关闭后每日的接口数量从最高 3.7W 稳定在 4K 浮动。
3)页面数据异常
4 天后又到了一个赛段的结束,蹲到 0 点,没有发现异常。结果早上上班,运营上报说某个用户的数据变成了 0。
排查后发现,是服务端内部的一个接口,少了个参数,也就是说漏需求了。
我没发现,服务端没发现,测试也没发现,然后上线后,运营发现了。
服务端的人没有仔细阅读需求文档,开发全依赖我写的一个技术文档,我就变成了瓶颈。
这里面有些历史原图,一般是服务端出接口文档,前端协商修改,我们这边是反着来的。
我的文档一旦出错,就会连着出错。而测试其实少了一个用例场景,这次发生后也进行了补充。
本次问题妥妥的就是个人祸,后续需要大家对需求有更仔细的理解。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号