Mamba与状态空间模型可视化指南
https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mamba-and-state
【原文标题:A Visual Guide to Mamba and State Space Models】
原文地址,写的真的很好很好很好,很适合了解这样一个东西到底是什么东东,这里简单对全文进行一个记录,初学难免有误,欢迎指出。最后建议看原文,这里省流(如省)以及本人搞笑版。
Transformer架构是LLMs能够成功的重要因素,先行主流模型,从开源的Mistral到闭源的ChatGPT都可以看到它的身影。
为了进一步提高LLMs,我们不断开发了新的模型架构,这些架构甚至可以超越Transformer,比如我们今天说到的Mamba,一种状态空间模型(SSM)
最原始的论文在这里:Mamba: Linear-Time Sequence Modeling with Selective State Spaces(对应项目地址:https://github.com/state-spaces/mamba)
在本文中,我们将介绍语言模型中的状态空间模型,逐一探讨,然后会说说Mamba如何有资格挑战Transformer的。
(作者的卖书广告(●'◡'●)https://github.com/handsOnLLM/Hands-On-Large-Language-Models)
Part1:Transformer的问题
说Mamba架构为何如此有趣之前,我们先来回顾一下Transformer以及说说它到底存在什么问题。
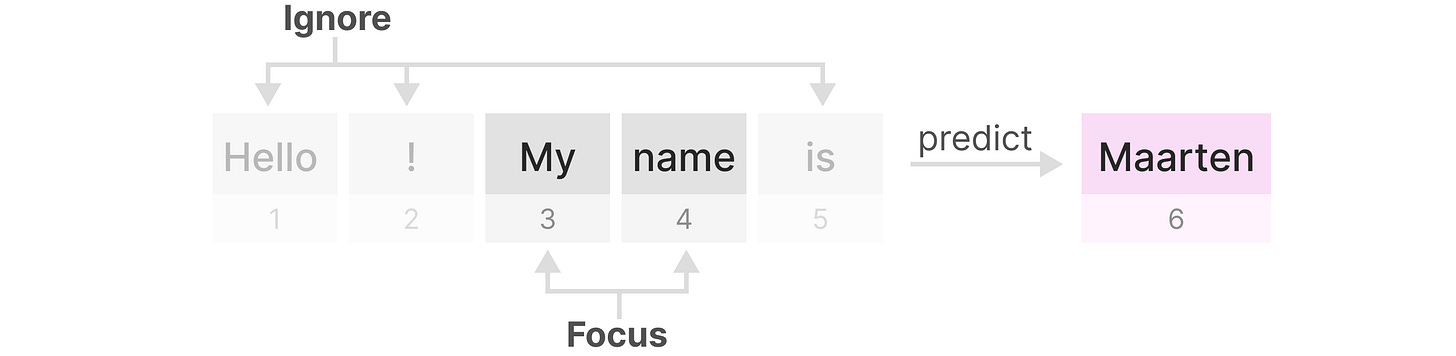
一个Transformer将任何文本输入视为由标记组成的序列(as a sequence that consists of tokens)。
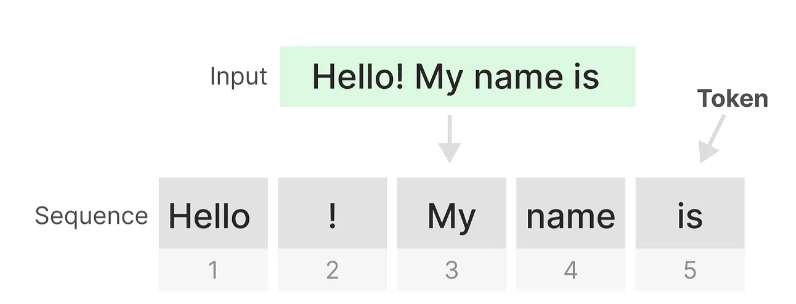
(这里token就比较像我们一个一个拆开的单词)
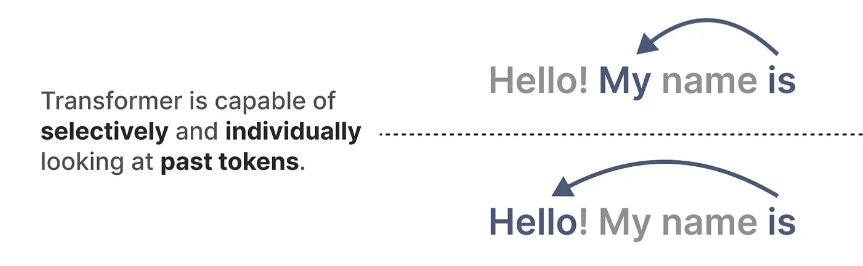
Transformer 的主要优势在于,无论它接收什么输入,它都可以回顾序列中的任何早期标记来推导其表示。(有选择地、单独地)
Transformer的核心组件:
一个Transformer主要由两个结构组成,一组用于表示文本的编码器(encoder)和一组用于生成文本的解码器(decoder),由这两个东西组成的东西可以用于多个任务,包括翻译。
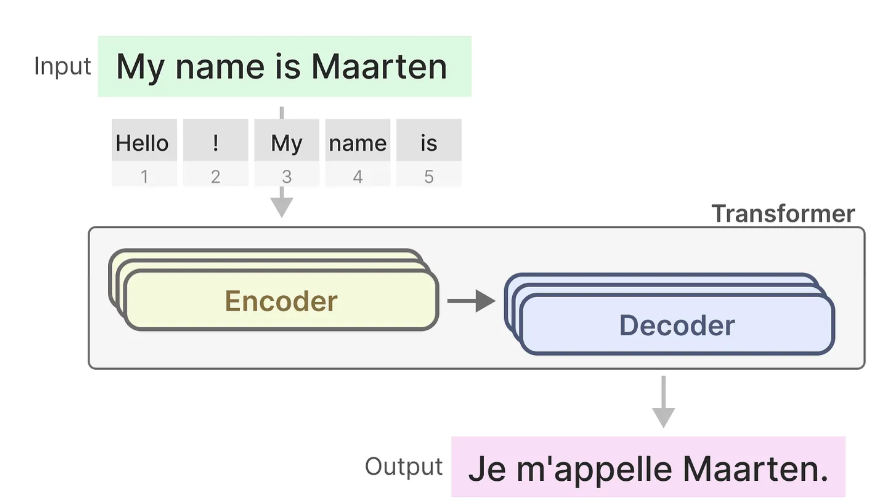
我们可以采用这种结构中的解码器来生成模型,这个基于Transformer的模型用它的解码器模块来完成一些输入文本。
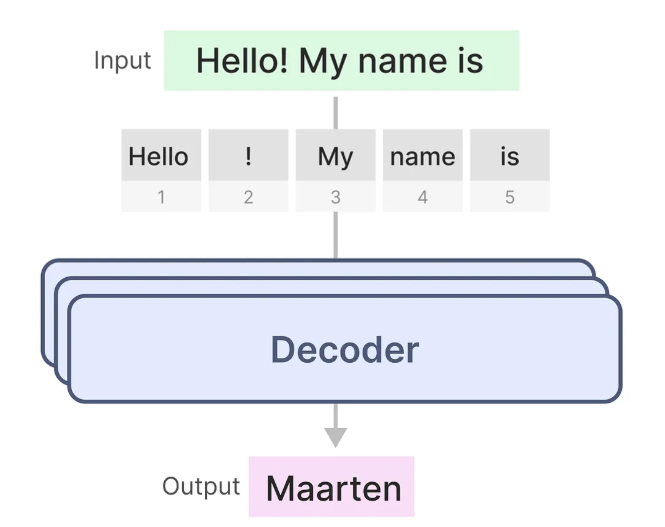
实现的工作原理:
一个单独的解码器主要由两个主要组件组成:掩码自注意力机制(masked self-attention)和前馈神经网络(feed-forward neural networ)
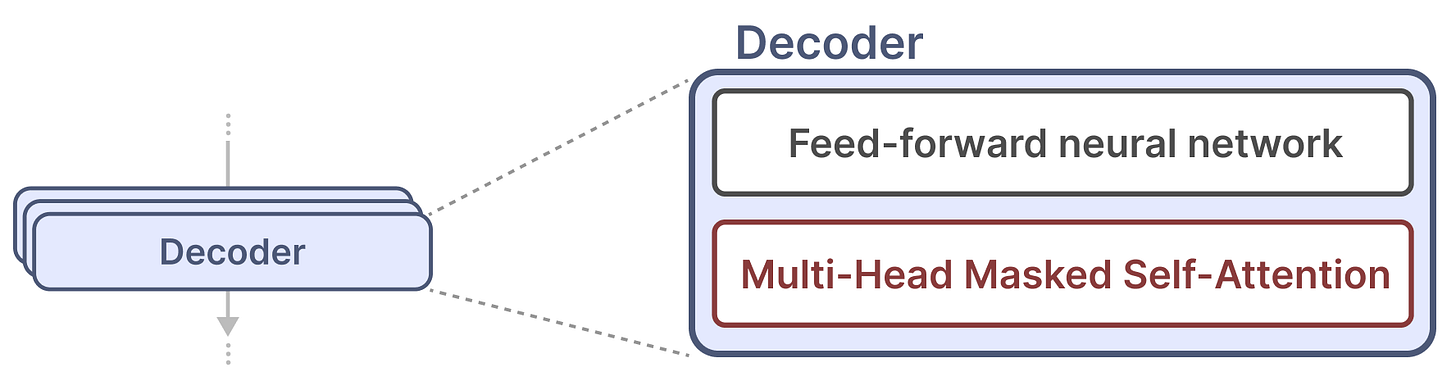
正因为有了自注意力所以让这些模型变得很出色,它允许以一种快速训练的方式查看整个序列的未压缩视图。
到底怎么实现的?首先创建一个矩阵,标记每个标记和之前每个标记的相关性,矩阵中的权重由标记对之间的相关性决定。
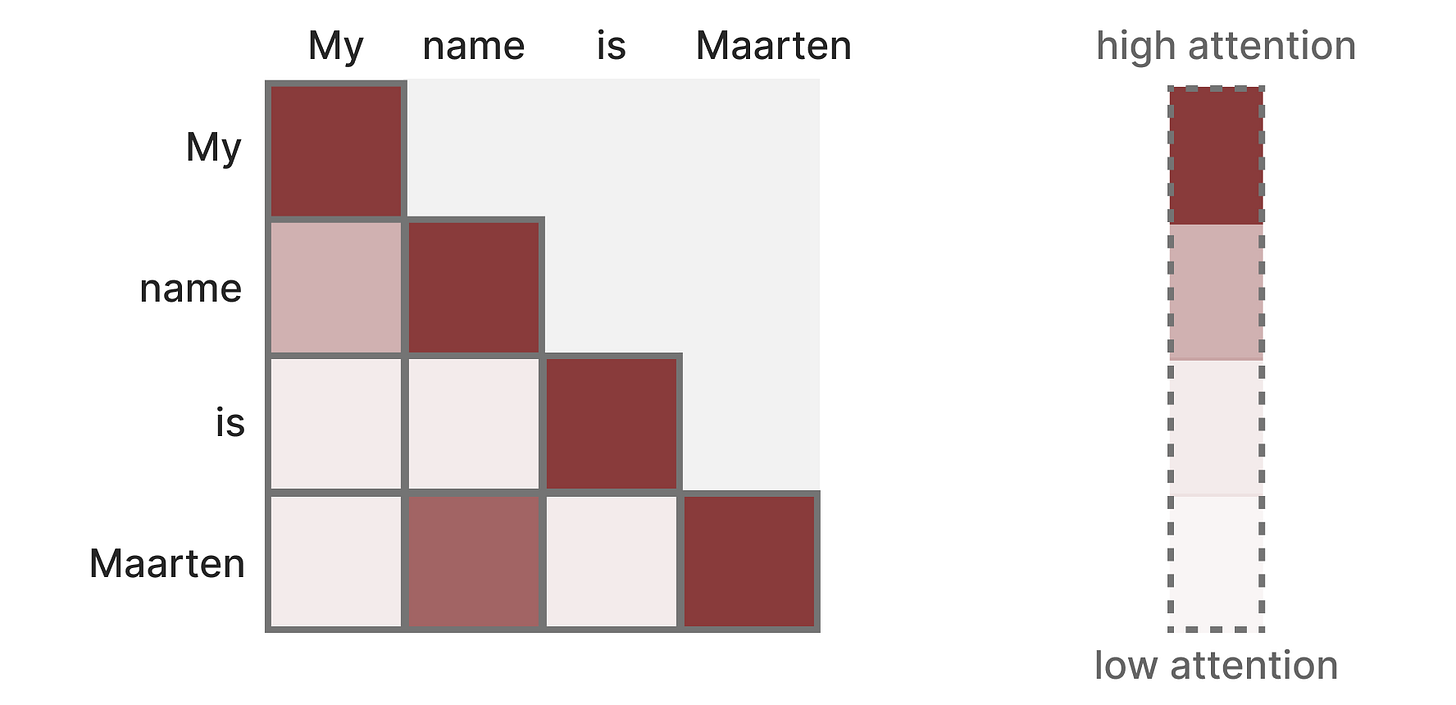
【比如上面这个图,重复的单词权重是最高的,接下来权重比较高的就是My name/ name Maarten】
在训练的过程中,这个矩阵一次性创建,在计算name和is的注意力之前,不需要先计算my和name之间的注意力。
并且这个东西支持并行化,从而极大地加快了训练速度。
推理の诅咒:
但是这样的模型机制也存在一个缺陷,假设现在我们已经生成了一些标记,现在我需要生成下一个标记,那么我们就需要重新计算整个序列的注意力。
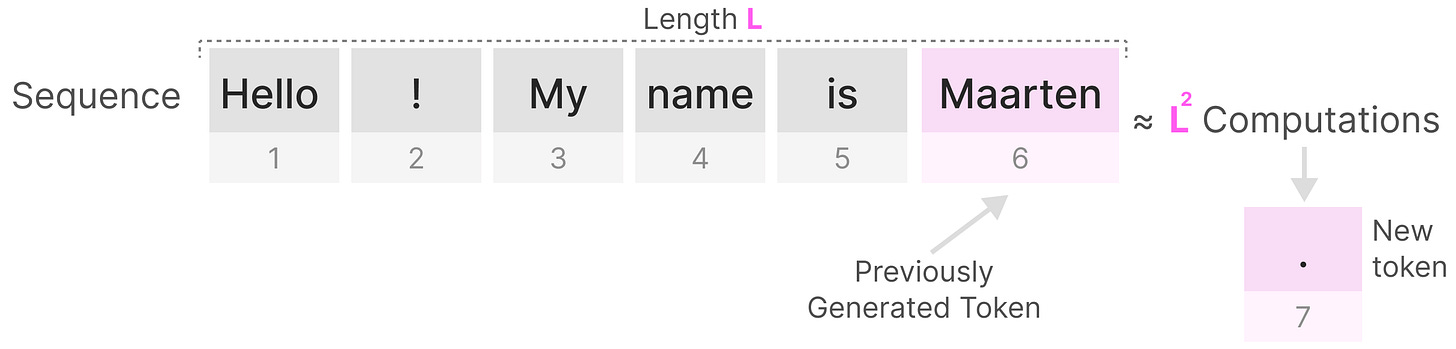
长度为L的序列重新生成新的标记大约需要L^2次计算,所以随着序列长度的增加,花销可能会变得越来越大。

【训练很快!但是,推理的过程就会变慢,规模会按照原来的平方进行增长】
所以需要重新计算整个需要是我们Transformer架构的一个主要瓶颈。
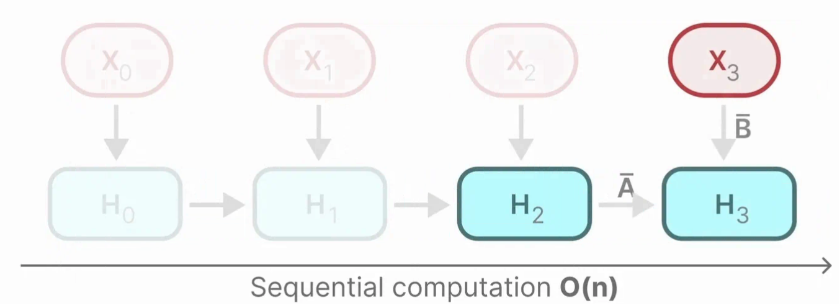
现在让我们看看传统技术,循环神经网络(RNN)是怎么解决慢速推理这个问题的。
RNNs是一种解决方案吗?
RNN是一种基于序列的网络,它在每个时间步长接收两个输入,即时间步长t的输入和时间步长t-1的隐藏状态,以生成下一个隐藏状态并且预测输出。
它具有循环机制,允许信息信息从之前的一步传递到往后的一步。这里我们展开这个可视化,让他更加明确:
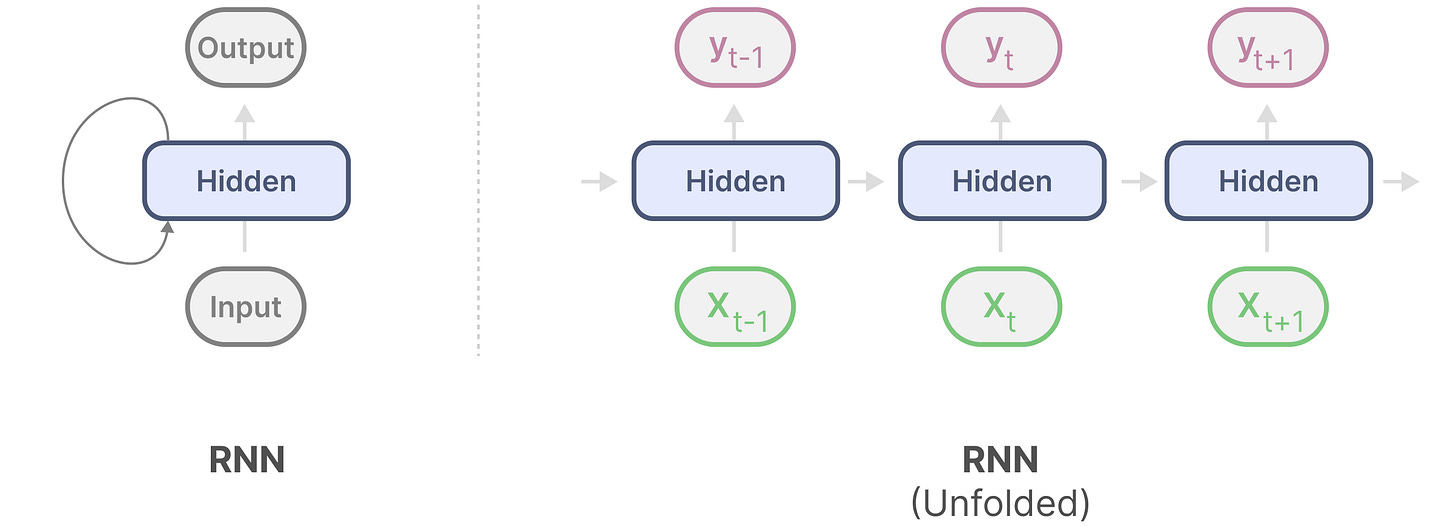
在生成输出时,RNN只会考虑先前的隐藏状态(xt-1)和当前的输入(xt),这防止重新计算了所有先前的隐藏状态(Transformer会做的事)
换句话说,RNNs可以快速推理,因为它于序列长度成线性关系,理论上它甚至可以有无限长的上下文长度。
【所以,我的感觉这种就是基于前一步的基础上往后继续发展,类似迭代的过程,而不是像我们Transformer一样一次又一次对整体进行计算。】
为了说明,我们把RNNs作用于我们之前使用的输入文本上:
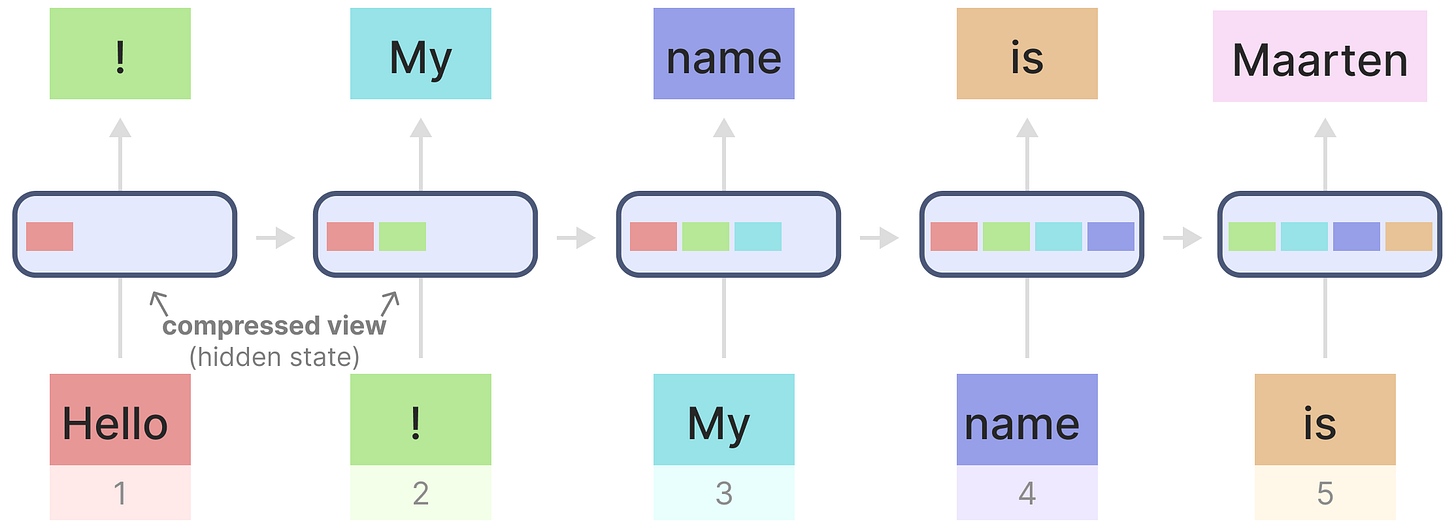
【你看,就是像这样慢慢地把我们要的东西拼接上去】
每个隐藏状态是先前所有隐藏状态的聚合,通常是一个压缩视图。
然而这里存在一个问题:
看到这里,当生成“Maarten”这个名字的时候,最后一个隐藏状态实际上已经不包含我们一开始的Hello的信息了,由于我们RNN每次只会考虑前一个的状态,所以它往往会随着时间的推移忘记前面的信息。
他的训练和推理速度都很快,但是因为会忘记所以他的准确度远不及Transformer。
取而代之,我们将关注状态空间模型(SSM)来高效地使用CNN(以及有时候也会使用卷积)
Part2:状态空间模型(SSM)
状态空间模型(SSM)类似于Transformer和RNN,处理序列信息(比如文本和信号)。这里我们将介绍SSM地基本知识以及他们与文本数据的关系。
什么是状态空间?
状态空间包含描述系统所需的最小变量集合,他是通过定义系统的可能状态以一种数学的形式表示问题的一种方法。
我们来简化一下,假设现在我们正在迷宫中导航,“状态空间”是所有可能位置(状态)的地图,每一个具体的位置点代表迷宫中的一个独特位置,具有特定的细节信息,比如你离出口还有多远。
【这里强烈建议他原文里的小视频例子,确实讲的很好】
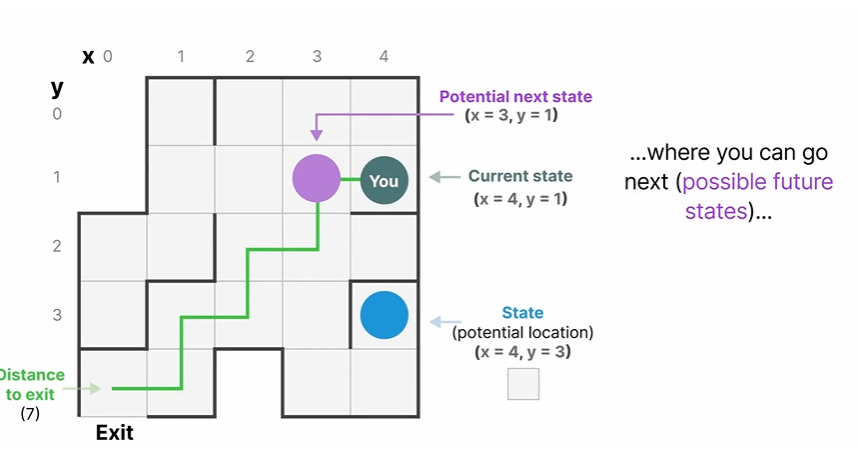
状态空间表示就是对上面这个东西的简化描述,它显示了当前的位置(也就是当前的状态)、可以前往的地方(未来的状态),以及那些变化可以带您进入下一个状态(向左或者向右)
尽管状态空间模型使用方程和矩阵来跟踪这种行为,这仅仅是一种跟踪你所在位置、你可以去哪里以及如何到达那里的方法。【也就还是对应了我们上面说的这三种状态】
描述状态的变量,在我们的例子中是X和Y坐标,以及到出口的距离,可以表示为“状态向量”。
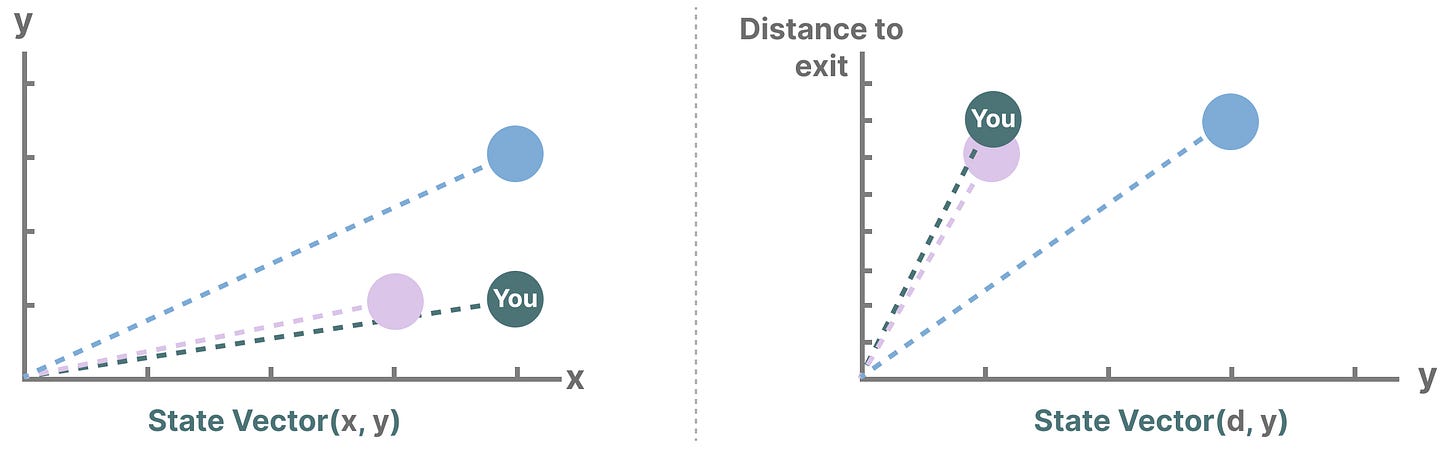
这听起来可能还是有点熟悉的,因为在语言模型中的嵌入或向量也常用来描述输入序列的状态。
比如描述我当前位置的一个向量大概也就长这个样子:
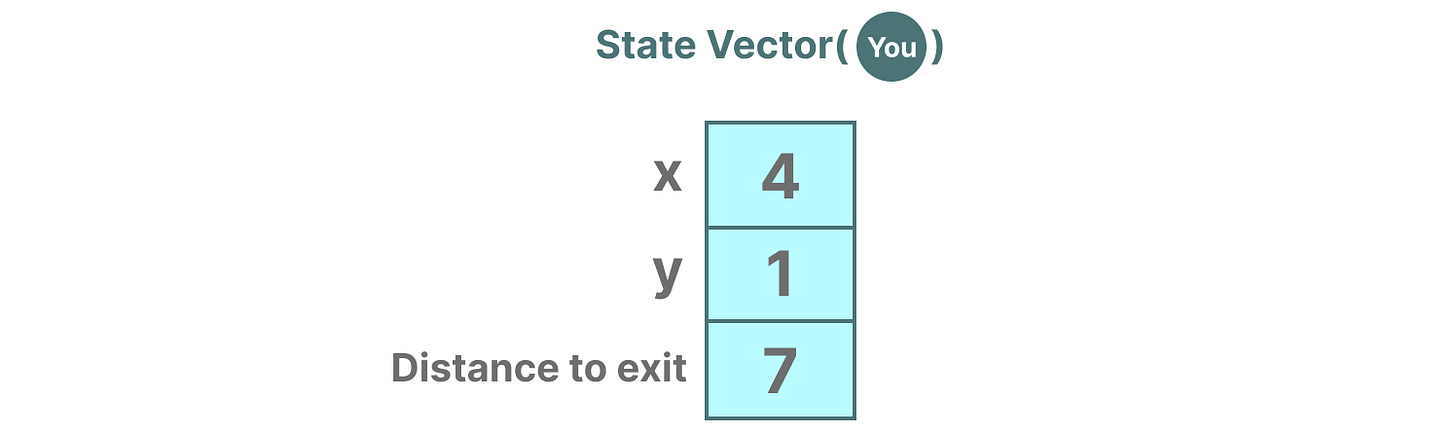
在神经网络中,系统的“状态”通常是其隐藏状态,并且在大语言模型的背景下。生成新的标记是最重要的一个方面。
什么是状态空间模型?
状态空间模型(SSMs)是用于描述这些状态并根据输入预测其下一个状态可能是什么的一种模型。
传统上,在时间t时,SSMs包含三个东西:
- 将输入序列x(t)映射——(例如对应在迷宫中向左或者向下移动)
- 将潜在状态h(t)表示——(例如,迷宫中距离出口和x/y的坐标)
- 推导出预测输出序列y(t)——(例如再向左移动一次以更快到达出口)
【这里我还是想把它和我们前面说的那个东西继续对应一下,这里本质三个东西,我理解下来是:输入的序列、潜在状态、预测结果,这个东西首先可以和我们传统的RNN进行对照的】
然而他不是使用离散序列作为输入(比如单一的向左移动一次),而是接收一个连续序列并预测输出序列。【这里我倾向于一组动作包含了向左向右这些的】

SSMs 假设动态系统,如 3D 空间中移动的物体,可以通过两个方程从其在时间 t 的状态进行预测。
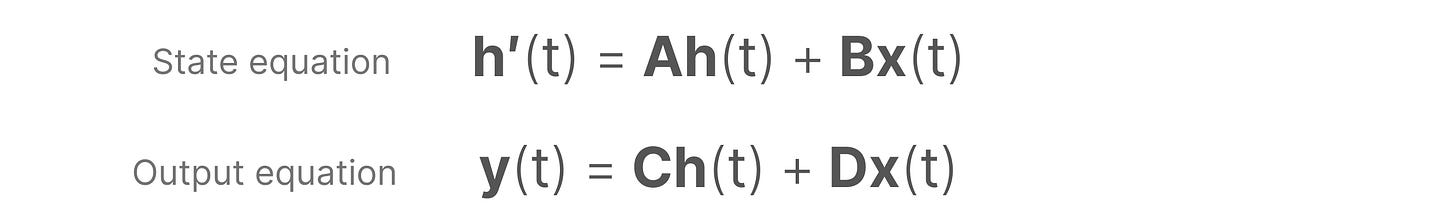
通过解这些方程,假设我们可以揭示基于观察数据(输入序列和先前状态)预测系统状态的统计原理。
其目标是找到这种状态表示 h(t),以便我们可以从输入序列到输出序列。
【简单说把上面两个缝合一下就是我们的目标】
【划重点,这里很重要了】

这两个方程是状态空间模型的核心。
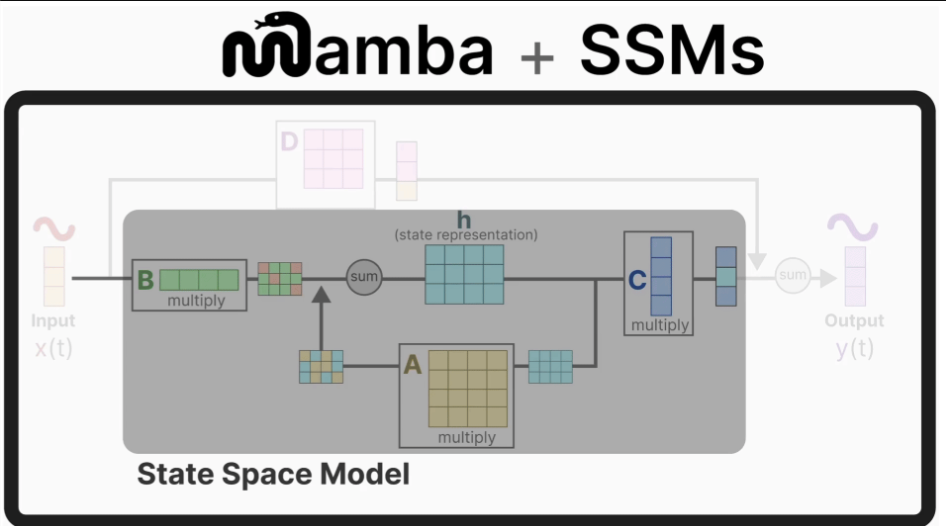
状态方程描述了如何根据输入影响输出的变换(就是这里我当前输入的B,他会影响我当前状态下的A,说的有点绕,看图就懂了)
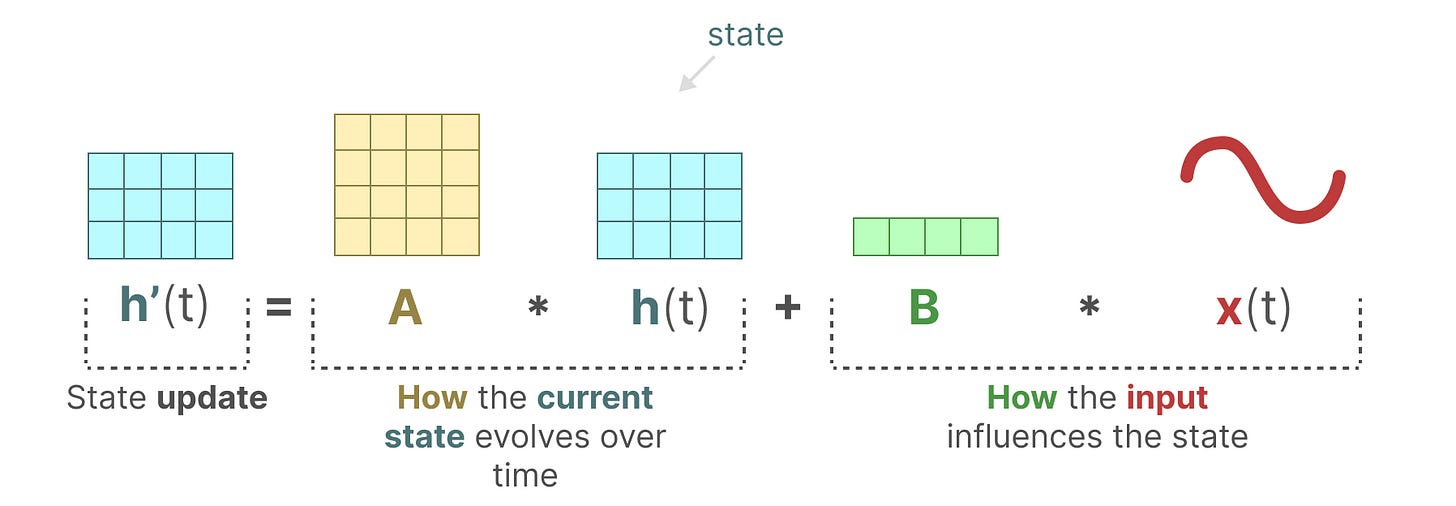
【状态更新=当前状态随时间如何演变+输入如何影响状态】
如我们所见,h(t)指的是在任意给定时间 t 的潜在状态表示,而 x(t)指的是某些输入。
输出方程描述了状态是如何通过矩阵 C 转换为输出,以及输入是如何通过矩阵 D 影响输出的。
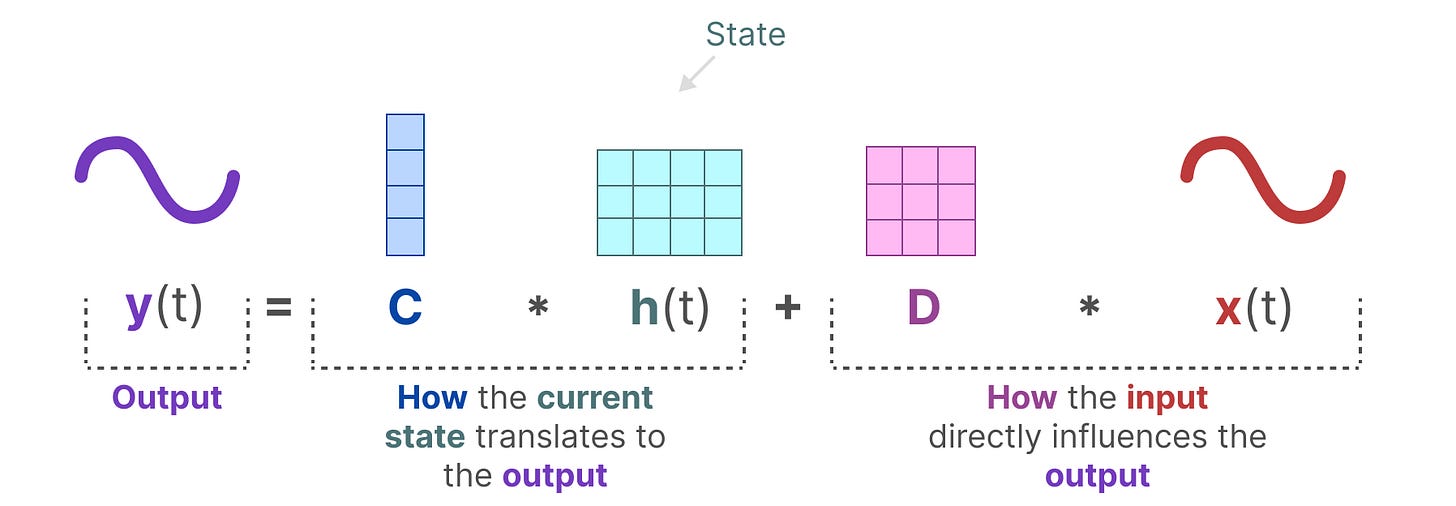
【输出=当前状态如何转化为输出+输入如何直接影响输出】
【注意:矩阵 A、B、C 和 D 也通常被称为参数,因为它们是可以学习的。】
可视化这两个方程,我们就得到了这样的结构:
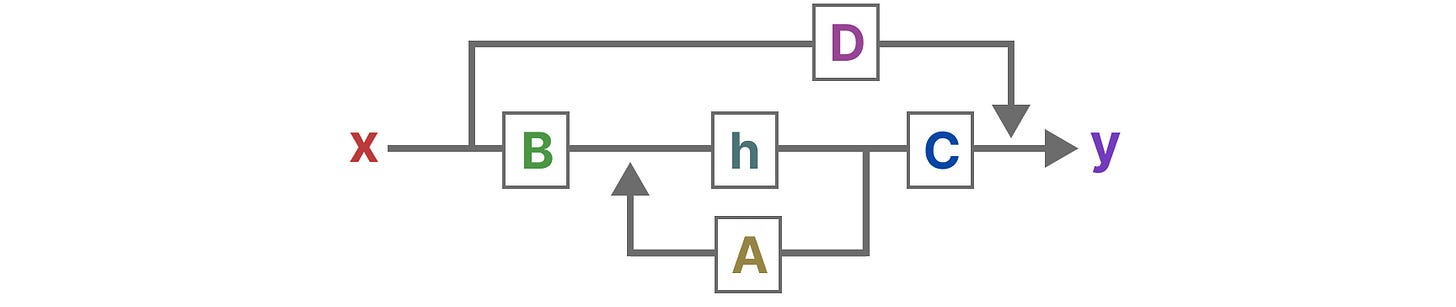
【眼熟吧,这个和我们一开始放的那个是可以对应上的(●ˇ∀ˇ●)】
让我们一步一步的介绍这种通用技术,以了解这些矩阵是如何影响学习过程的:
1、假设我们有一些输入信号x(t),这个信号首先被矩阵B乘以,
该矩阵描述了输入如何影响系统。

更新后的状态(类似于神经网络的隐藏状态)是一个潜在空间,其中包含着环境的核心"知识"。
2、我们用矩阵 A 乘,它描述了所有内部状态如何连接,因为它们代表了系统的基础动态特性。
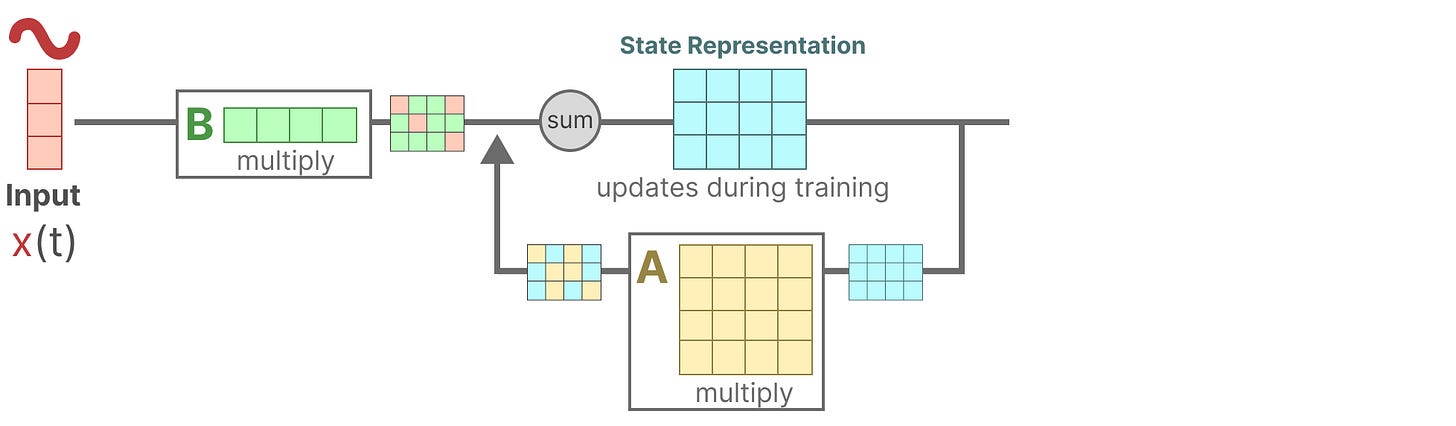
你可能已经注意到了,在创建状态表示之前会应用矩阵 A,并在状态表示更新后更新矩阵 A。
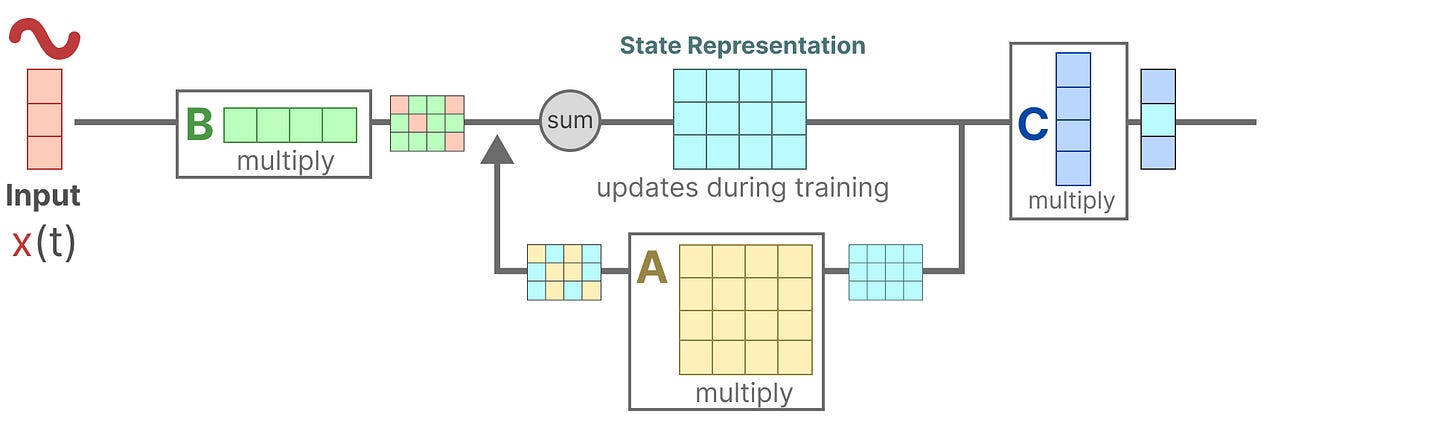
3、然后,我们使用矩阵 C 来描述状态如何转换为输出。
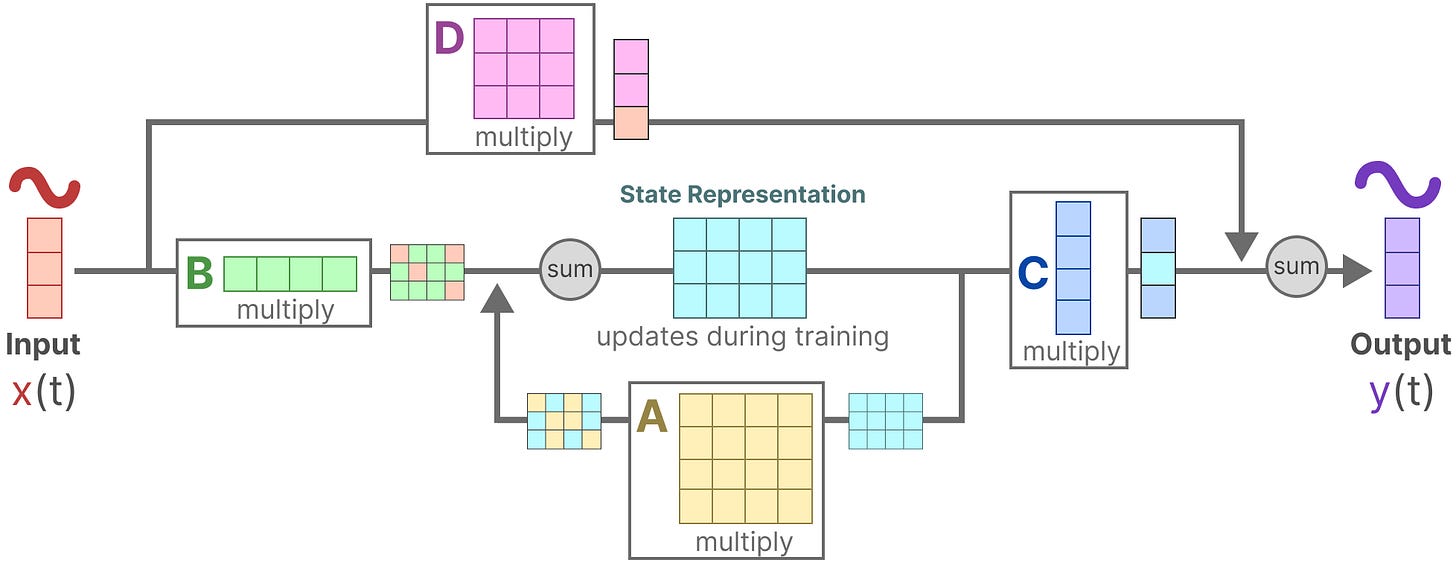
4、最后,我们可以利用矩阵 D 从输入直接提供信号到输出。这通常也被称为跳跃连接。
(这里建议跟着原视频过一遍就很熟悉了)
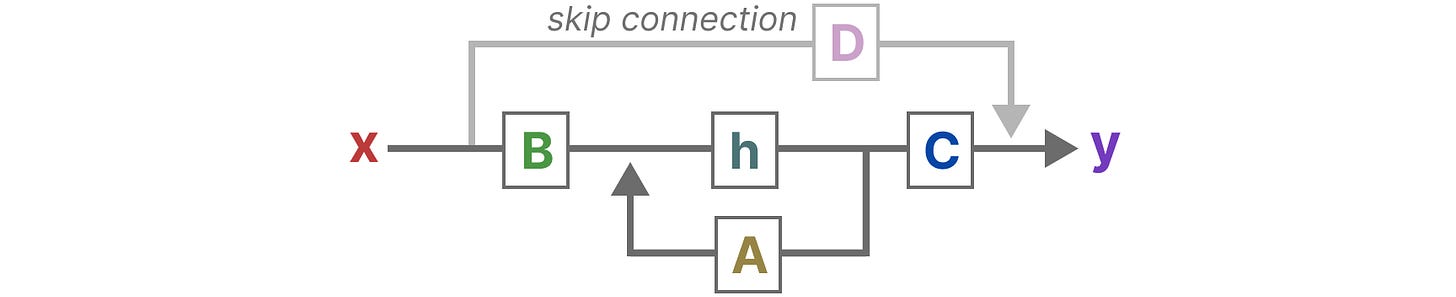
我们可以更新原始方程(并添加一些漂亮的颜色),以表示每个矩阵的作用,就像我们之前做的那样。
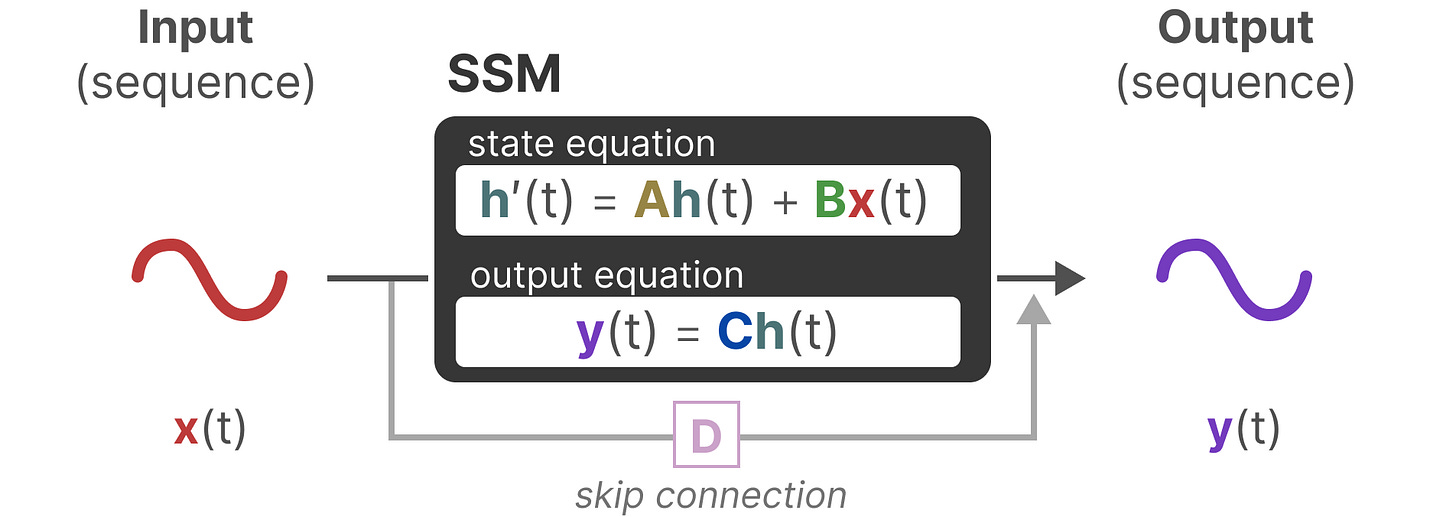
这两个方程式共同旨在从观测数据中预测系统的状态。由于输入预期是连续的,SSM 的主要表示形式是连续时间表示。
从连续信号到离散信号
简而言之就是为了解决我的输入信号是离散的,所以我希望我们的模型离散化。
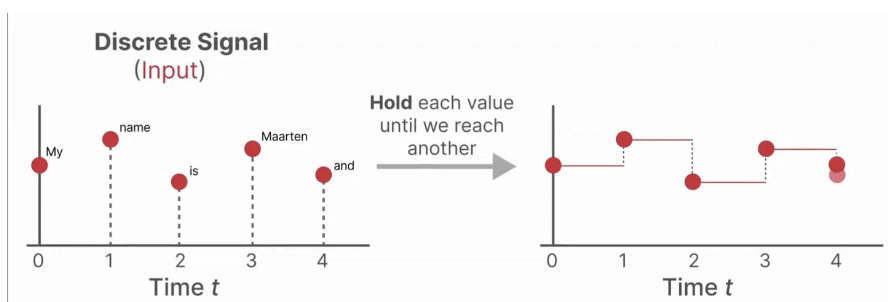
为此我们将利用零阶保持技术(Zero-order hold technique),它的工作原理如下:
- 首先,每次我们接收到一个离散信号时,我们保持其值,直到我们接收到一个新的离散信号。
- 这个过程创建了一个连续信号,SSM 可以使用:
- 我们保持值的时长由一个新的可学习参数表示,称为步长 ∆,它代表输入的分辨率。
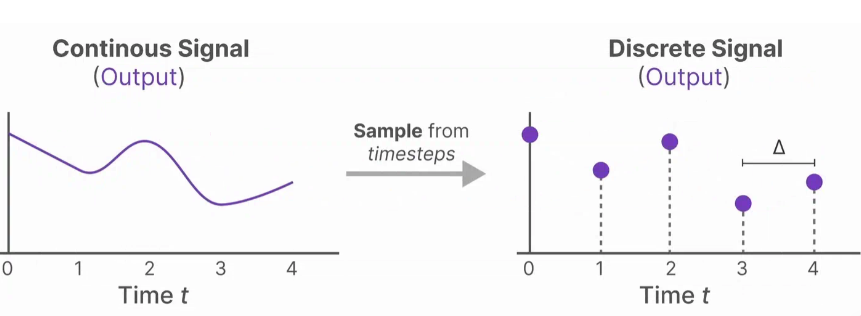
- 这些采样值就是我们的离散输出!
- 从数学上讲,我们可以如下应用零阶保持:
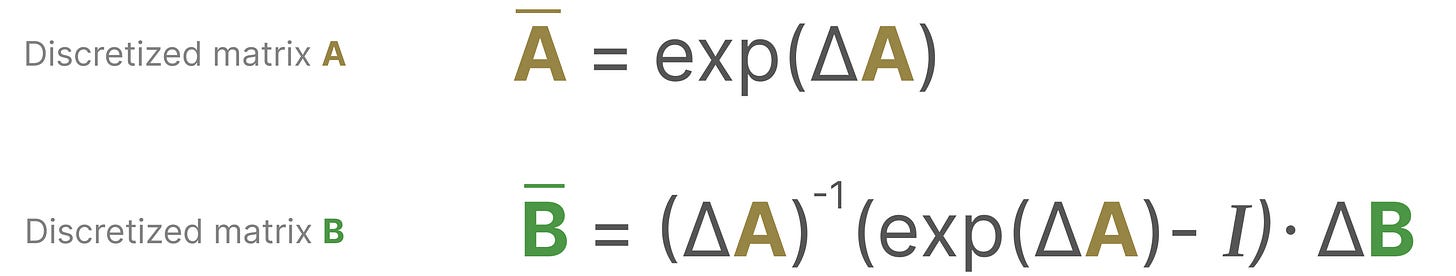
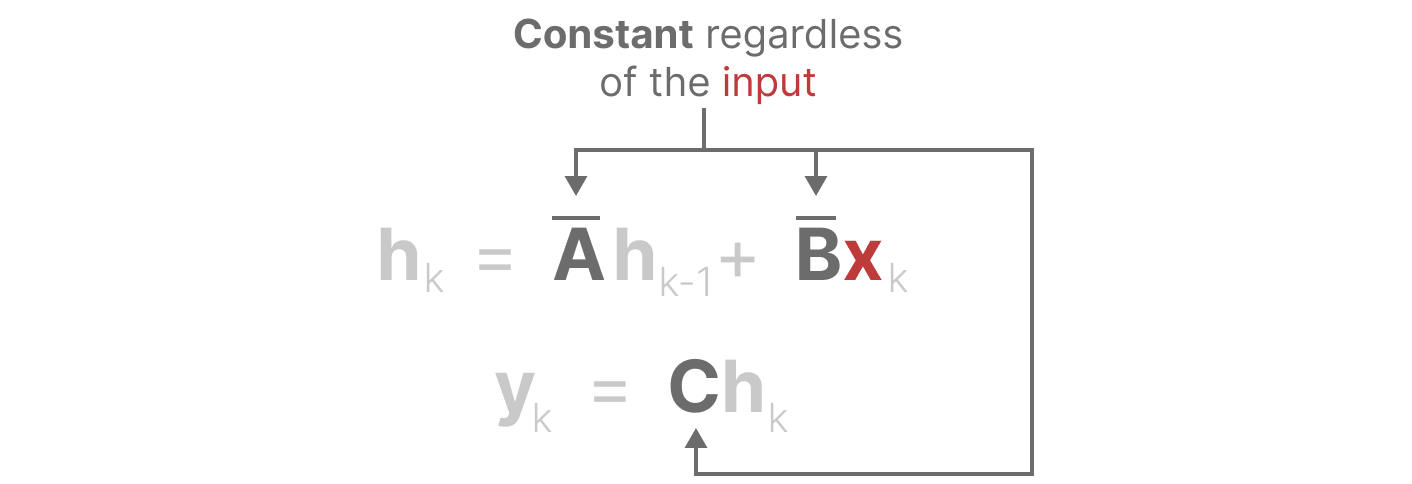
- 他们共同使我们能够从连续的 SSM 过渡到由以下公式表示的离散 SSM:现在是一个序列到序列的映射,即 xₖ → yₖ:
- 这里,矩阵 A 和 B 现在代表模型的离散化参数。
- 我们使用 k 来表示离散化的时间步长,以便在提及连续与离散状态空间模型时更加清晰。
【注意:在训练过程中,我们仍然保存矩阵 A 的连续形式,而不是离散化版本。在训练过程中,连续表示会被离散化。(其实这里有点没有理解到这个关于离散化的解释,先存个疑问放一个我自己的理解:我们无论连续的数据还是离散的数据,对于计算机而言最终的展现形式都是离散的,连续只是众多的离散罢了,所以在计算的过程中还是离散的(?但感觉也不太对,存疑))】
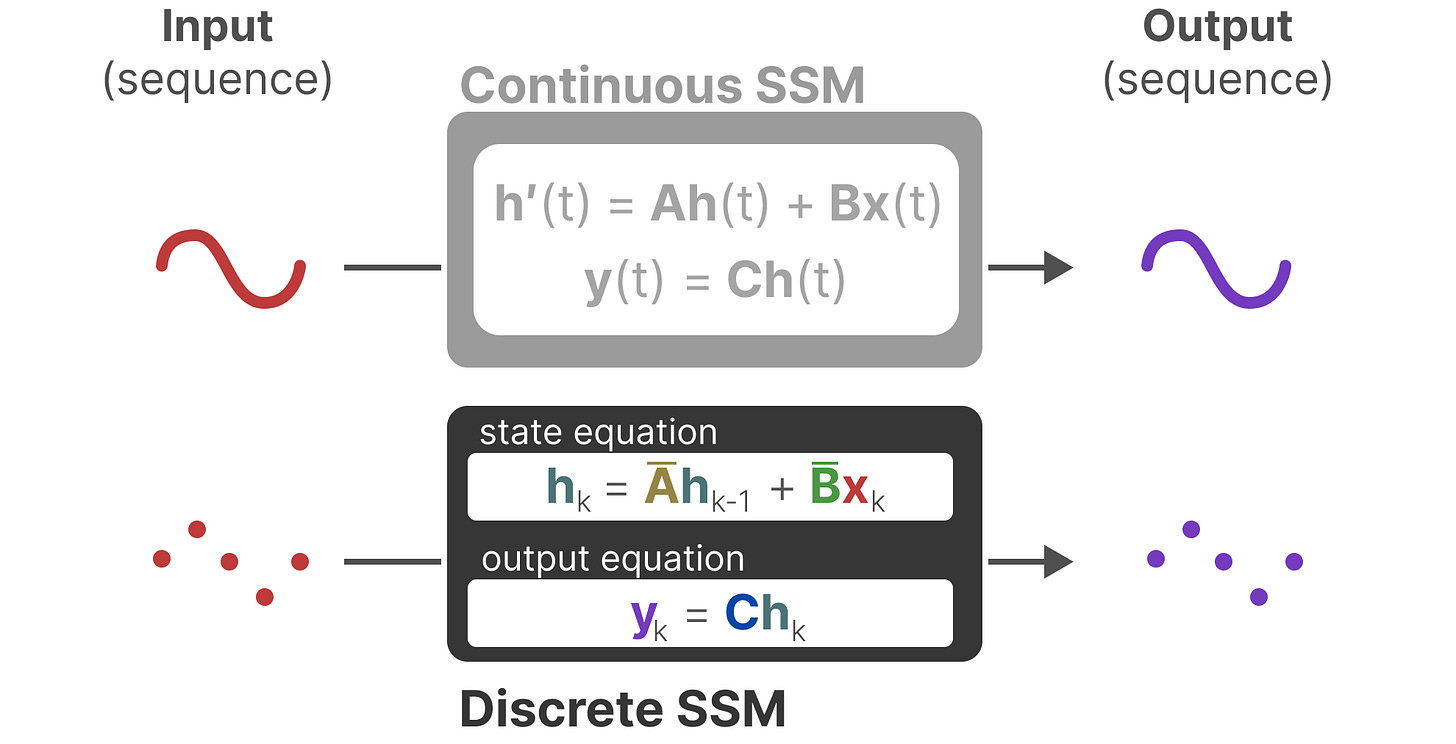
现在我们已经有了离散表示的公式,让我们来探讨如何实际计算模型。
循环表示(快速推理):
我们的离散化状态空间模型允许我们在特定的时间步长中而不是连续信号中表示问题,正如我们之前在RNNs中看到的那样,一种循环的方法在这里非常有用。
如果我们考虑离散的时间步长而不是连续信号,我们可以用时间步长来重新描述这个问题:【就是说之前的连续公式替换成我们上面这里推到出来的离散的公式】
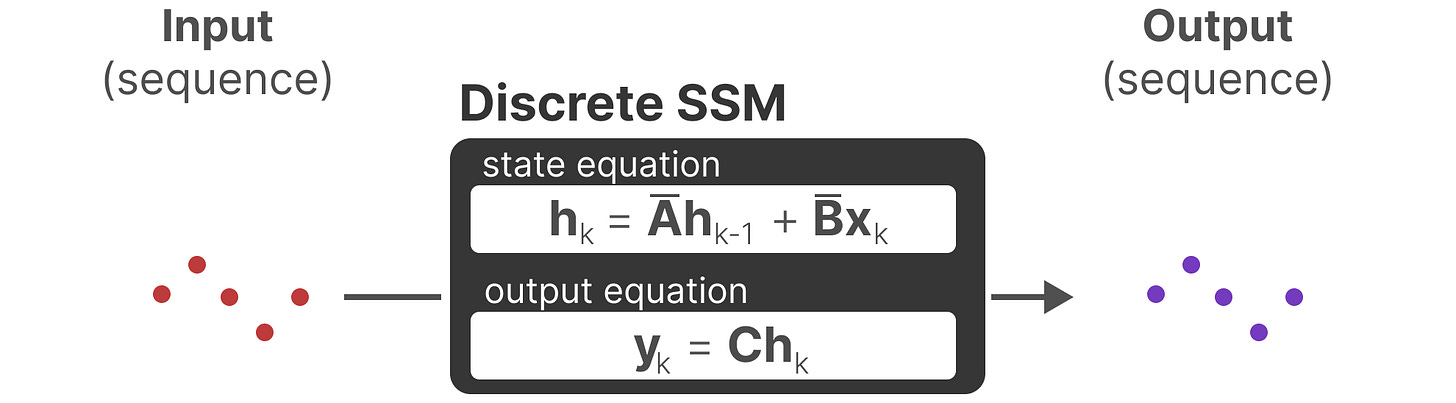
【这里简单地推导模式和前面其实差不多,就是当前状态的输入对之前状态的输出的】
在每一个时间步长,我们计算当前输入(Bxk)对先前状态(Ahk-1)的影响,然后计算预测输出(Chk)。
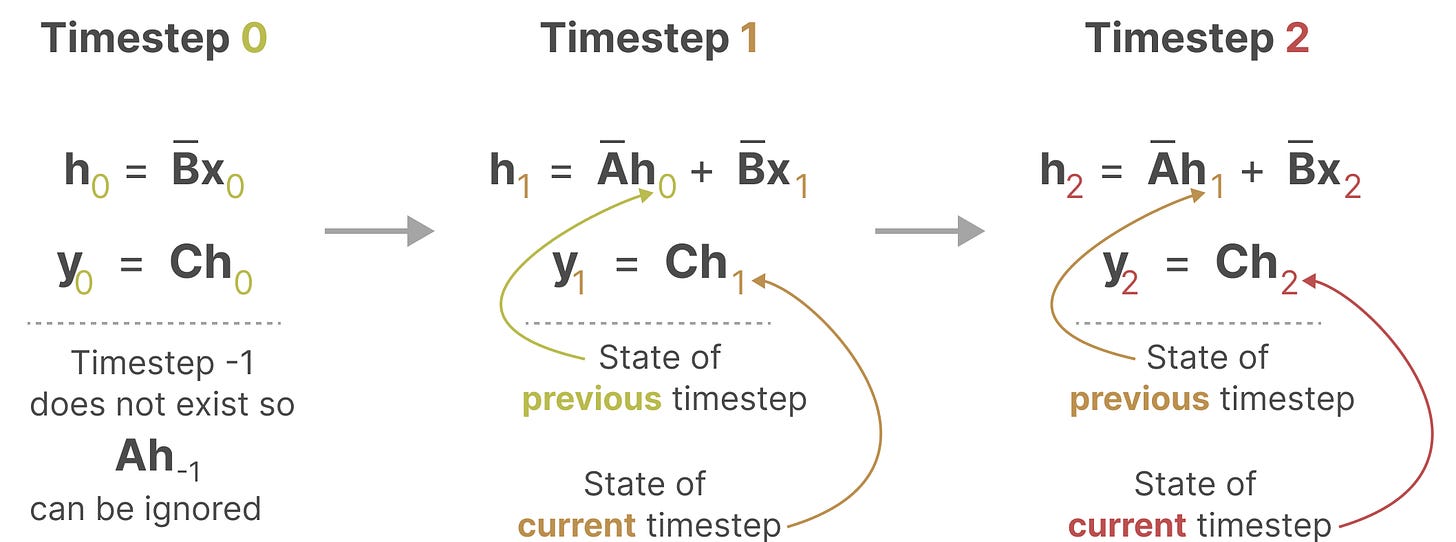
我们可以像之前处理RNN一样来处理它【你对比,你细品这个】
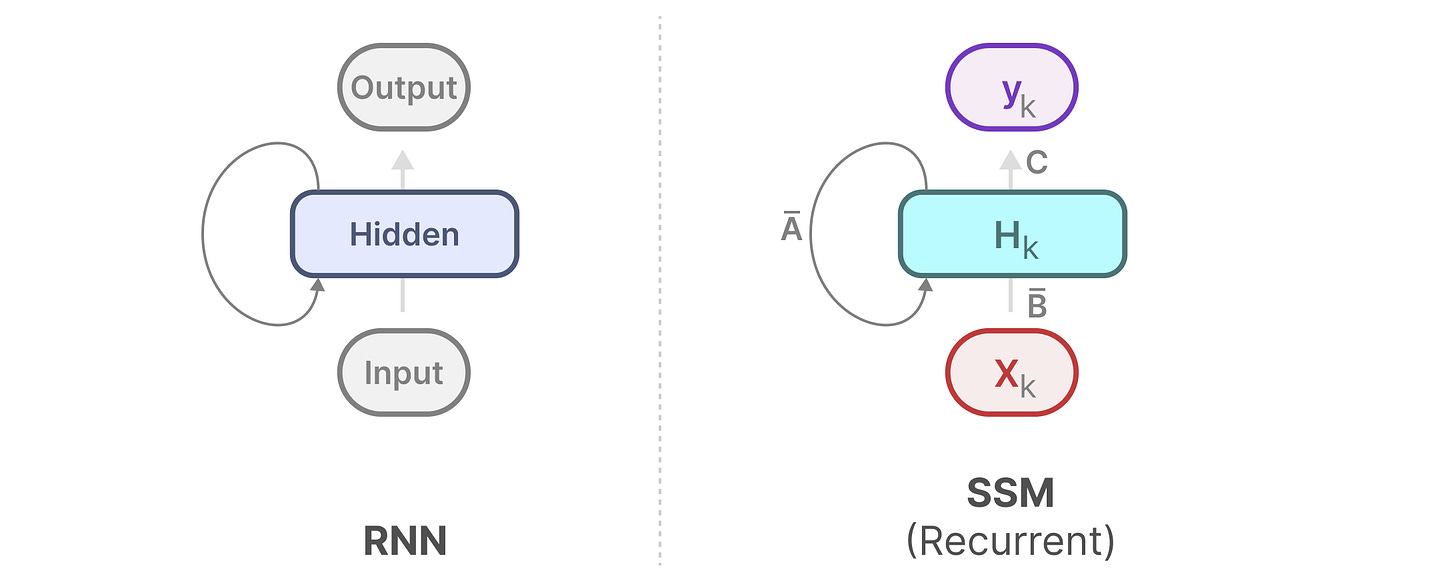
我们可以将其展开:
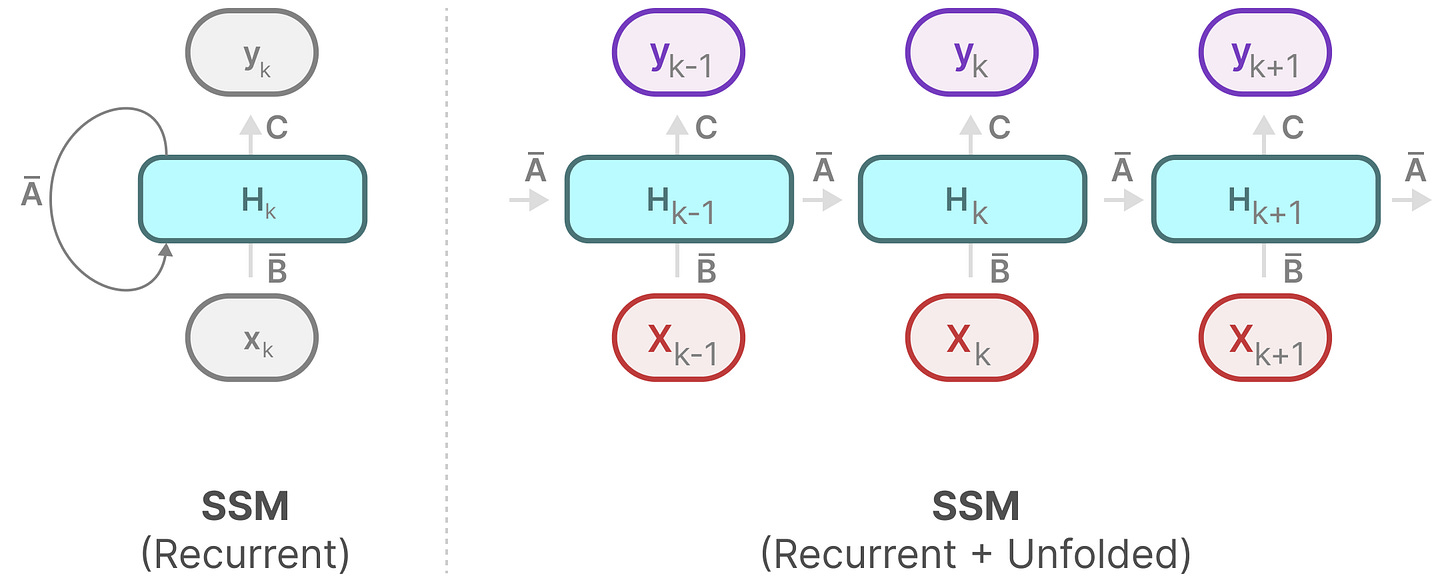
注意我们如何使用RNN的底层方法来展示这种离散化版本。
卷积表示(便于训练):
另一种我们可以用于 SSMs(状态空间模型)的表示是卷积。记得在经典图像识别任务中,我们应用过滤器(核)来提取聚合特征:
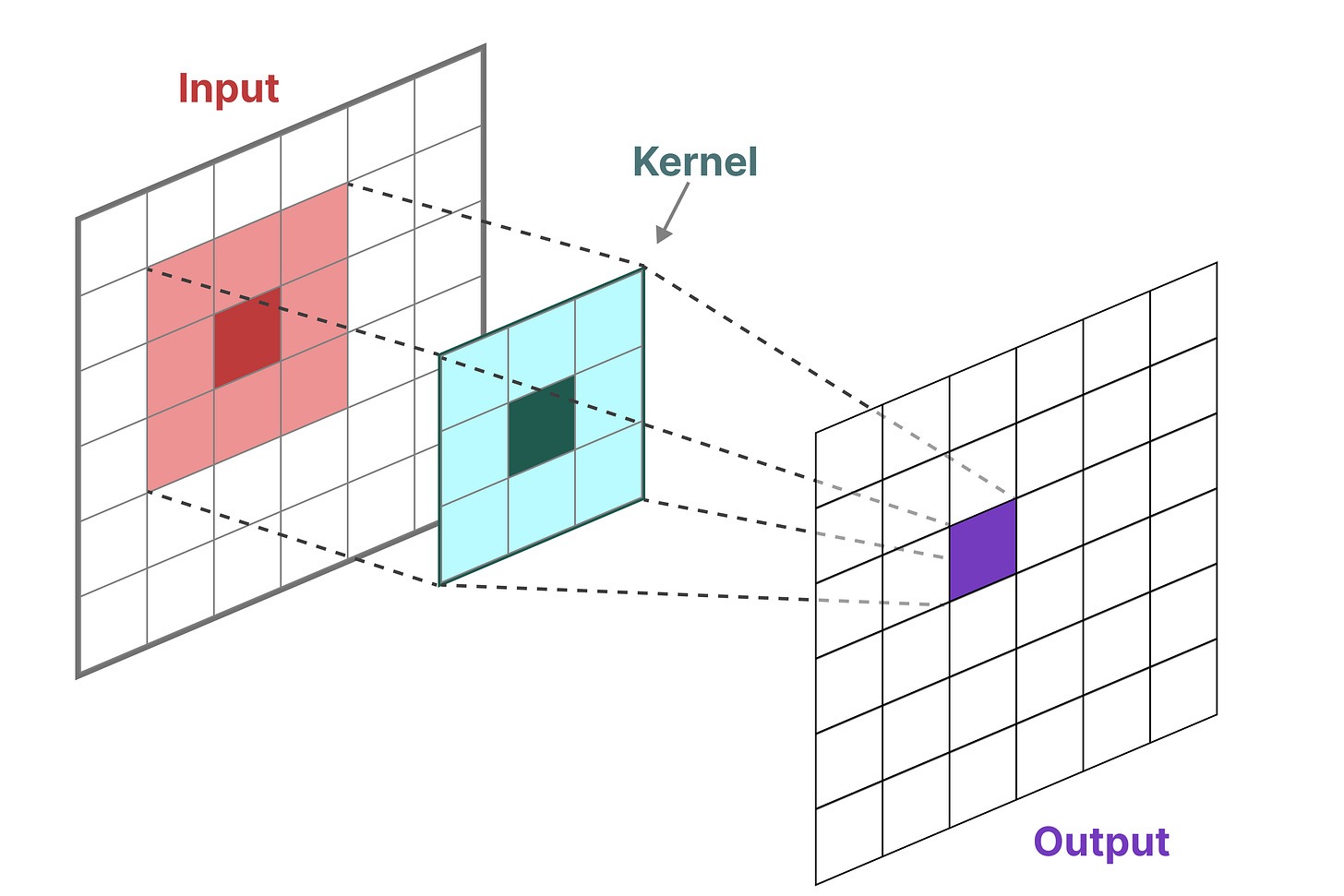
这里因为我们处理的不是图像而是文字,所以这里我们看到一个一维的视角:
【当然,本人目前的研究方向上还是要去看这个二位的,原理一样的】
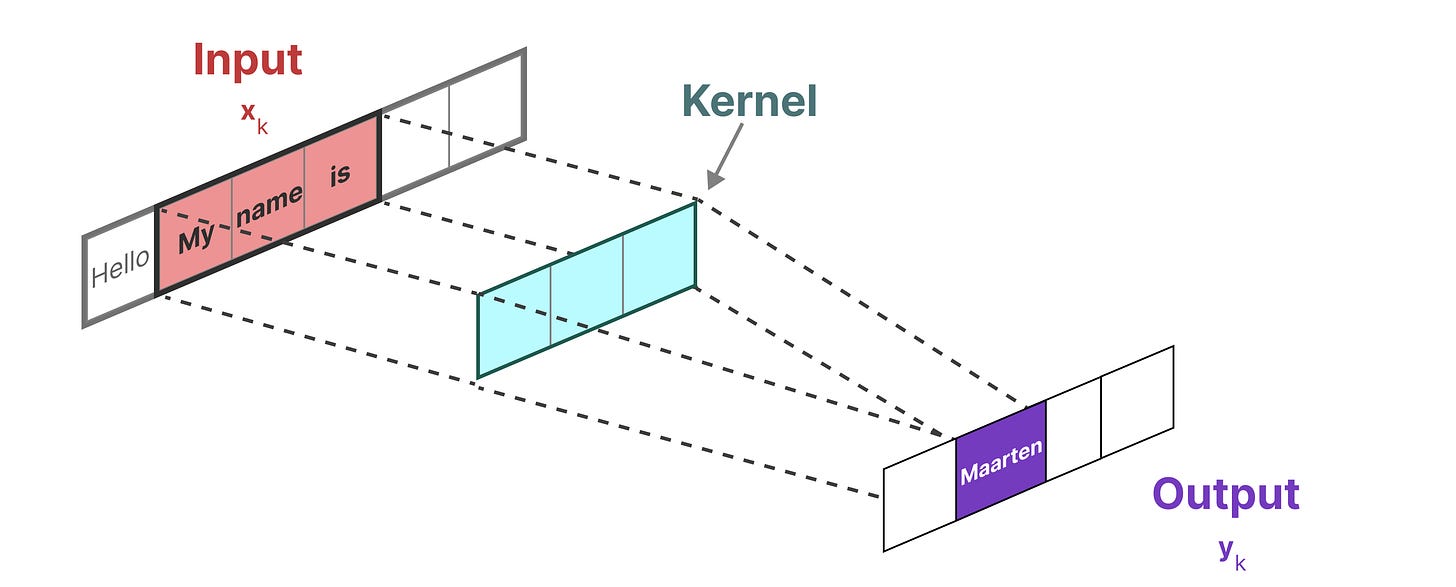
【截取了原文关于这个时间段的文字描述:】
【这样也就大概懂了这个卷积运算到底怎么算的】
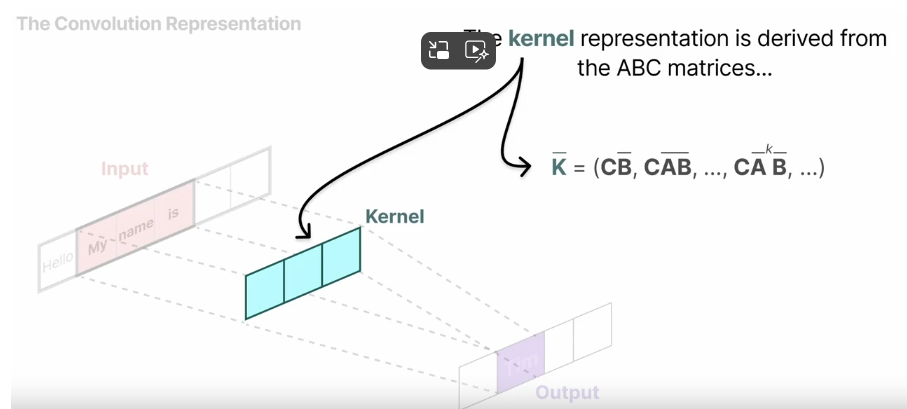
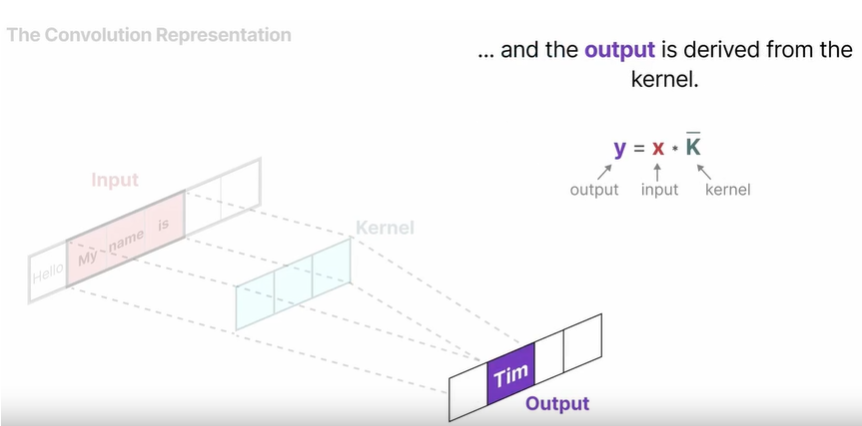
我们用于表示这个“滤波器”的内核(kernel)来自于SSM的公式推导:(就上面这个)
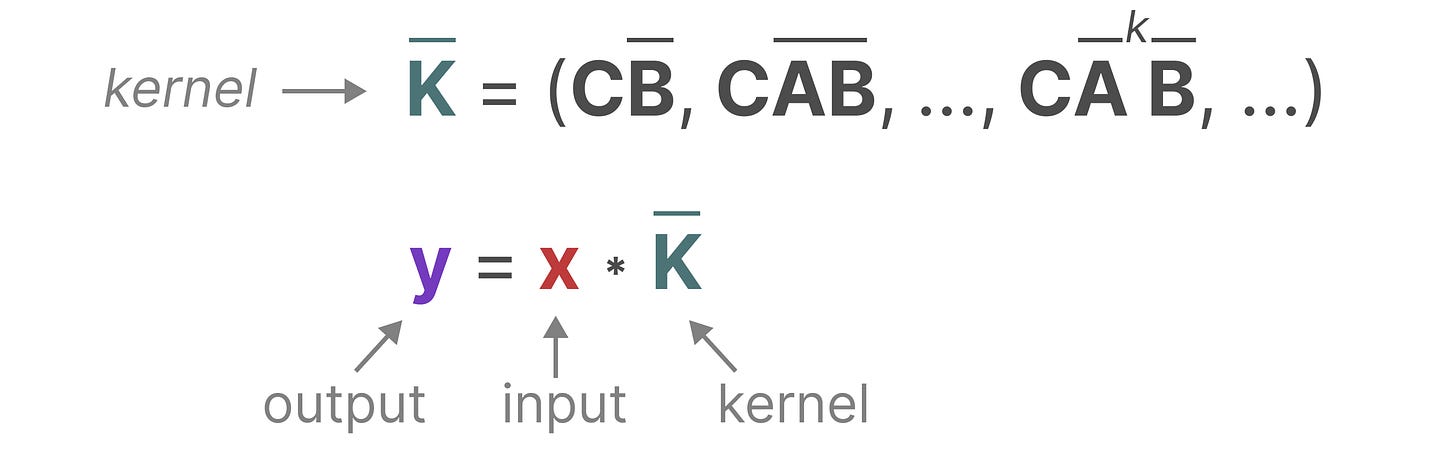
【这里关于原文的数学推导部分,不过多展开了,想明白这个运算怎么回事的请看原文喵(。>︿<)_θ】
将状态空间模型(SSM)表示为卷积的好处之一是它可以像卷积神经网络(CNNs)一样并行训练。然而,由于固定核大小,它们的推理速度不如循环神经网络(RNNs)快且无界。
三种表示方法:(小结)
对比我们前面说的这三种表示方法,连续的、循环的和卷积的,各有不同的优缺点:
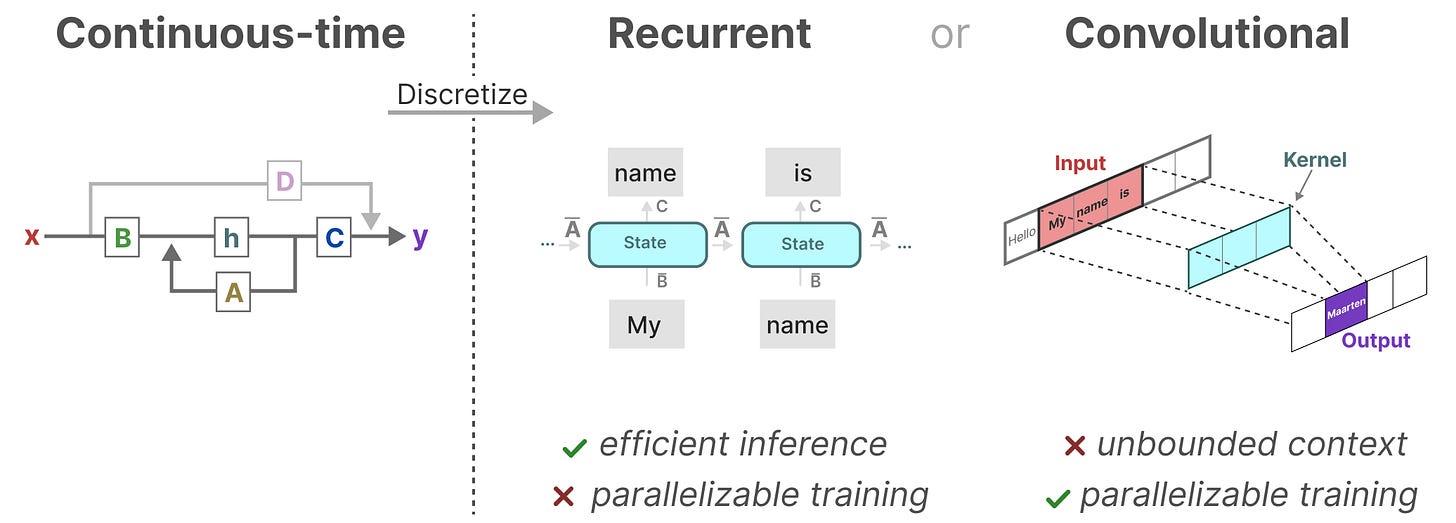
有趣的是,我们现在有了循环 SSM 的高效推理和卷积 SSM 的可并行训练。
使用这些表示,我们可以使用一个巧妙的技巧,即根据任务选择表示。在训练期间,我们使用可以并行化的卷积表示,而在推理期间,我们使用高效的循环表示:
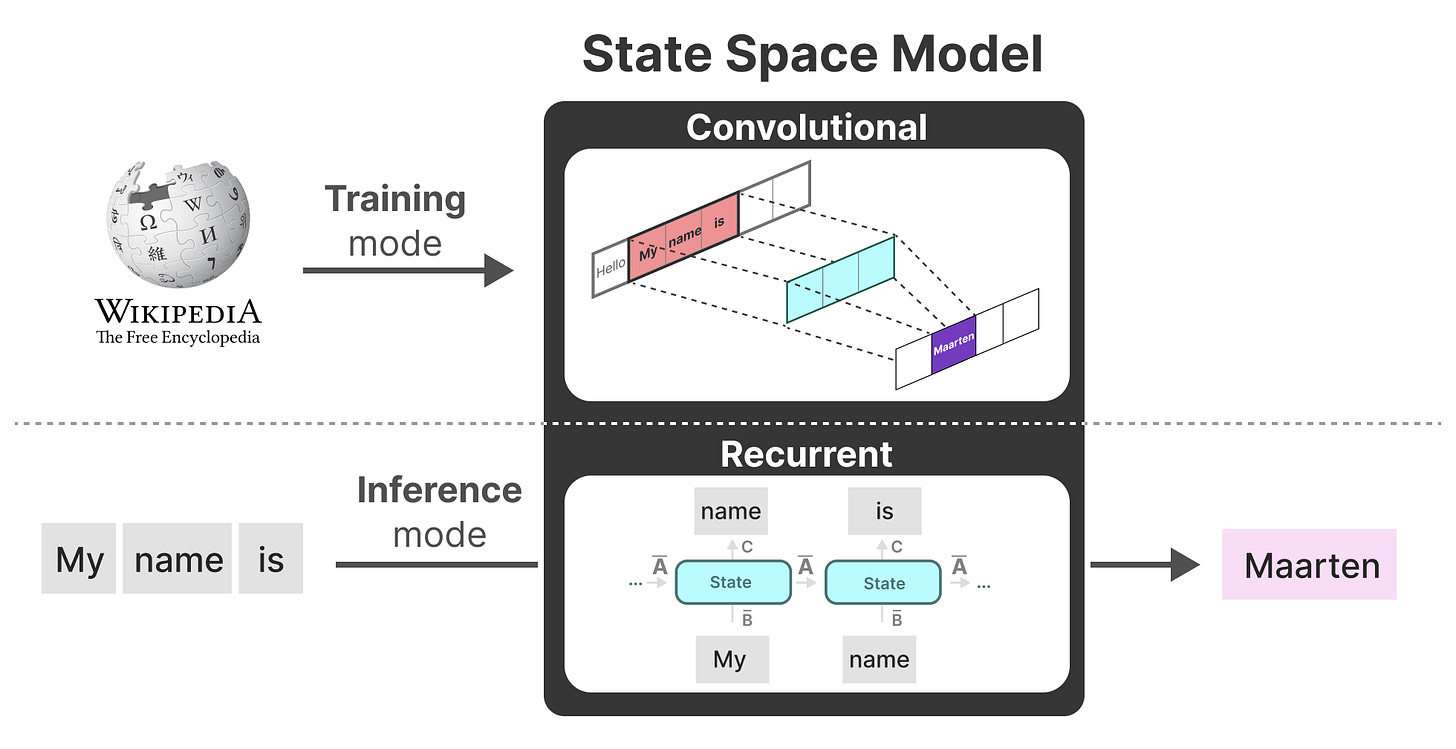
【毕竟没说只让用一种方法,各有自己的优点】
该模型被称为线性状态空间层(LSSL)
这些表示具有一个重要的属性,即线性时不变性(LTI)。LTI 表示 SSM 的参数 A、B 和 C 在所有时间步长中都是固定的。这意味着矩阵 A、B 和 C 对于 SSM 生成的每个标记都是相同的。
换句话说,无论你给出什么序列给 SSM,A、B 和 C 的值都保持不变。我们有一个静态的表示,它不具备内容感知能力。
在我们探讨 Mamba 如何解决这个问题之前,让我们先探讨拼图中的最后一部分,即矩阵 A。
矩阵A的重要性
【到这里我们也一起来回忆一下最开始的矩阵A,他用来进行对预测结果进行递归的一个二次推导】
可以说,SSM 公式的最重要方面之一是矩阵 A。正如我们之前在递归表示中看到的那样,它捕捉了先前状态的信息来构建新状态。
本质上,矩阵 A 产生隐藏状态:
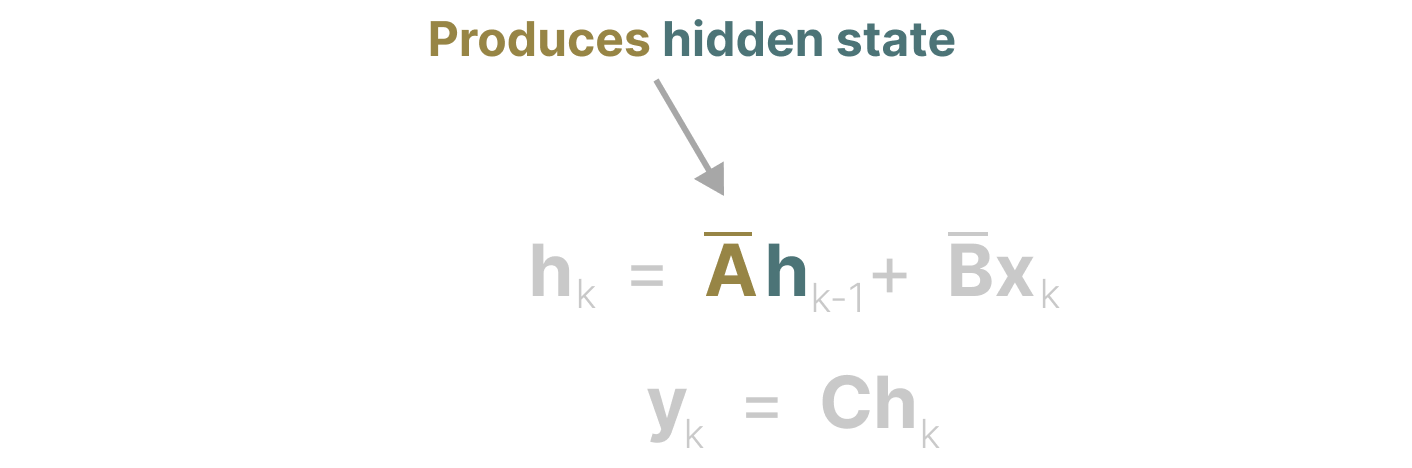
创建矩阵 A 可能就是记住少量之前的标记和捕捉到目前为止我们所看到的每个标记之间的区别。特别是在循环表示的上下文中,因为它只回顾之前的状态。
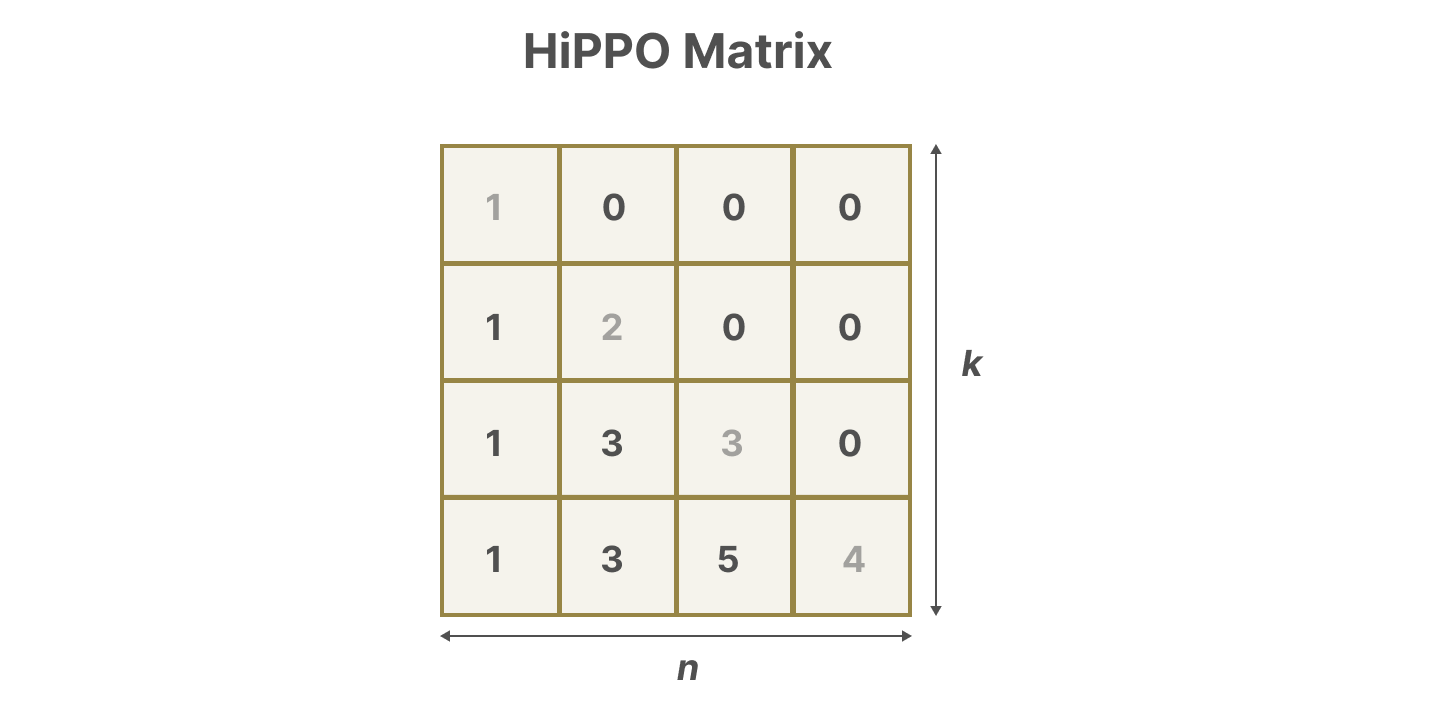
我们如何创建矩阵 A,使其保留大量内存(上下文大小)?
高阶多项式投影算子。(High-order Polynomial Projection Operators)
HiPPO 试图将其迄今为止看到的所有输入信号压缩成一个系数向量。
它使用矩阵 A 构建一个状态表示,能够很好地捕捉最近的标记并衰减较旧的标记。其公式可以表示如下:【划重点,A的核心表达形式这样的】
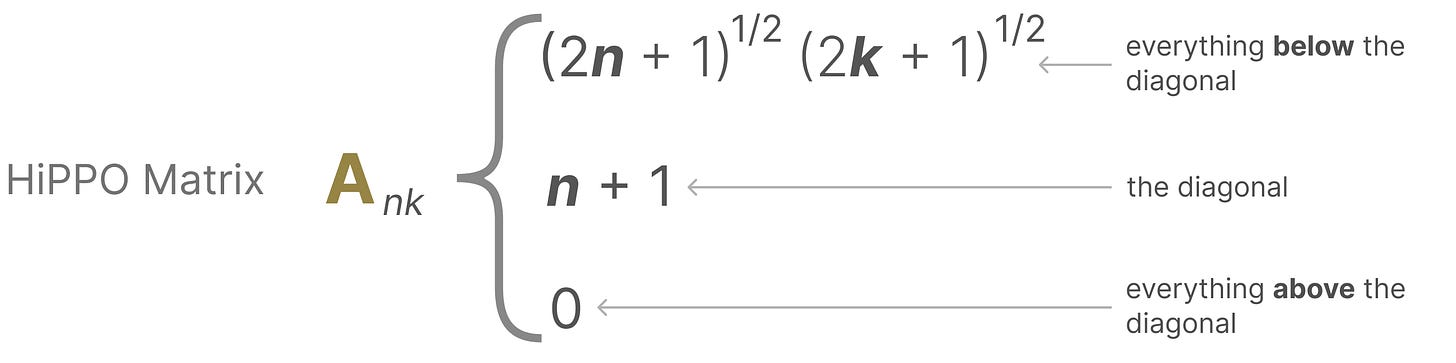
假设我们有一个方阵 A,这将给我们:【但上面这个原文里少了个符号】
使用 HiPPO 构建矩阵 A 比将其初始化为随机矩阵要好得多。因此,与旧信号(初始标记)相比,它更准确地重建了新信号(最近标记)。
HiPPO 矩阵的背后目的是为了产生一个隐藏状态来记住其历史状态。
(数学原理就跳过了,也没有特别详细)
HiPPO 随后被应用于我们之前看到的循环和卷积表示,以处理长距离依赖。结果是结构化状态空间序列(S4),一类可以高效处理长序列的 SSM。
它由三部分组成:
- State Space Models (状态空间模型)
- HiPPO for handling long-range dependencies(HiPPO 用于处理长距离依赖)
- Discretization for creating recurrent and convolution representations(用于创建循环和卷积表示的离散化)
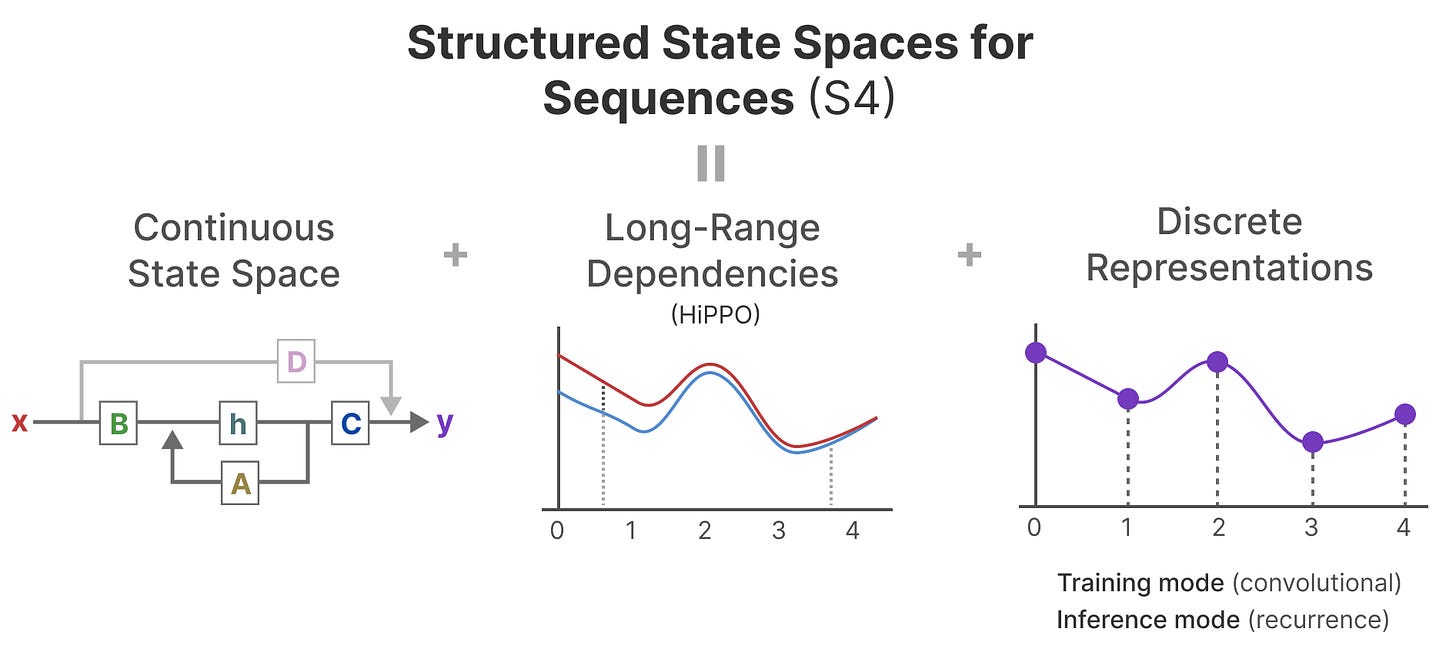
这类 SSM 根据你选择的表示(循环或卷积)具有多个优点。它还可以处理长文本序列,并通过构建在 HiPPO 矩阵之上来有效地存储内存。
Part3:Mamba——选择性状态空间
我们最终涵盖了理解mamba独特之处所需要的所有基础知识。状态空间模型可以用来模拟文本序列,但任有一系列我们想要避免的缺点。
在本节中,我们将要介绍mamba的两个主要贡献:
1、selective scan algorithm(选择性扫描算法),允许模型过滤(不)相关信息
2、hardware-aware algorithm(硬件感知算法),通过并行扫描、内核融合和重新计算,能够高效存储(中间)结果
它们共同构成了选择性的 SSM 或 S6 模型,可以像自注意力机制一样用于创建 Mamba 模块。
【其实这里提到的两个主要贡献也就是我们Mamba比较大的一个创新点】
在探讨两个主要贡献之前,让我们先探讨为什么它们是必要的。
他们试图解决什么问题?
状态空间模型,甚至 S4(结构化状态空间模型),在语言建模和生成中某些至关重要的任务上表现不佳,即会关注或忽略特定输入。
我们可以用两个合成任务来说明这一点,即选择性复制(selective copying)和归纳头(induction heads)。
在选择性复制任务中,SSM(状态空间模型)的目标是复制输入的部分并按顺序输出:

然而,(循环/卷积)SSM 在这个任务上表现不佳,因为它具有线性时不变性。正如我们之前所看到的,矩阵 A、B 和 C 对于 SSM 生成的每个标记都是相同的。
因此,由于固定的 A、B 和 C 矩阵,SSM 无法进行内容感知推理,因为它将每个标记同等对待。这成了一问题,因为我们希望 SSM 推理输入(prompt)。
SSM 在归纳头部任务上表现不佳,该任务的目的是在输入中重现的模式:
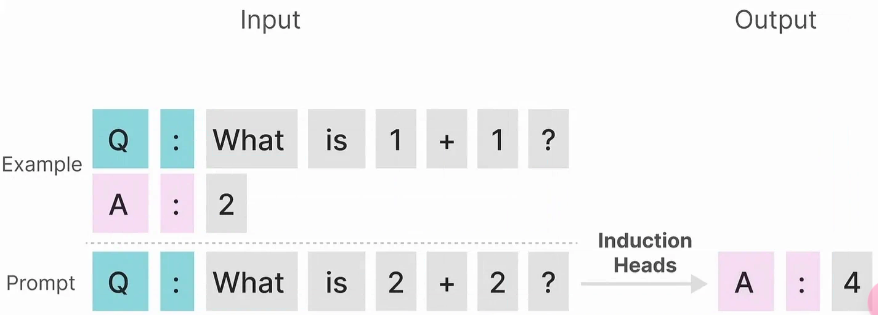
在上述示例中,我们实际上在进行一次性的提示,试图“教导”模型在每次“Q:”之后提供“A:”的响应。然而,由于状态空间模型是时间不变的,它无法选择从其历史中回忆哪些先前标记。
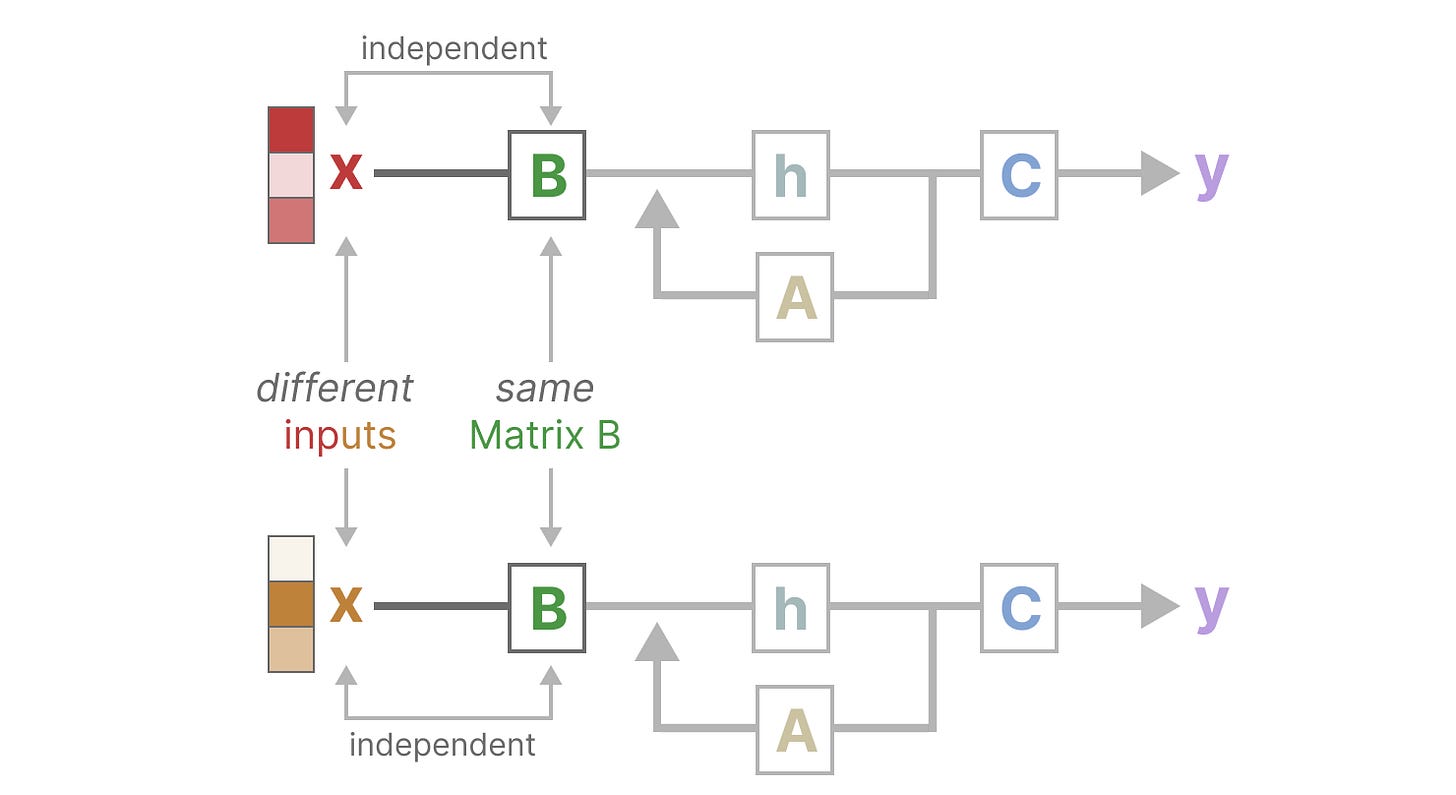
让我们通过关注矩阵 B 来阐述这一点。无论输入 x 是什么,矩阵 B 都保持完全相同,因此与 x 无关:
同样,A 和 C 也无论输入如何都保持不变。这证明了我们迄今为止所看到的 SSMs 的静态特性:
 【你看嘛,这标记没有区别的,那我怎么区分?那我问你ε=( o`ω′)ノ】
【你看嘛,这标记没有区别的,那我怎么区分?那我问你ε=( o`ω′)ノ】
与这些任务相比,Transformer 由于可以根据输入序列动态地改变其注意力,因此相对容易。它们可以选择性地“查看”或“关注”序列的不同部分。
这些任务上状态空间模型(SSM)的糟糕性能说明了时间不变 SSM 的潜在问题,矩阵 A、B 和 C 的静态性质导致了内容感知问题。
选择性保留信息(Selectively Retain Information)
SSM 的循环表示创建了一个非常高效的小状态,因为它压缩了整个历史。然而,与不通过注意力矩阵压缩历史(Transformer 模型)相比,它要弱得多。
Mamba 旨在兼得两者之优,存在这样小的一个状态空间,能够做到和Transformer 的状态空间一样高效。
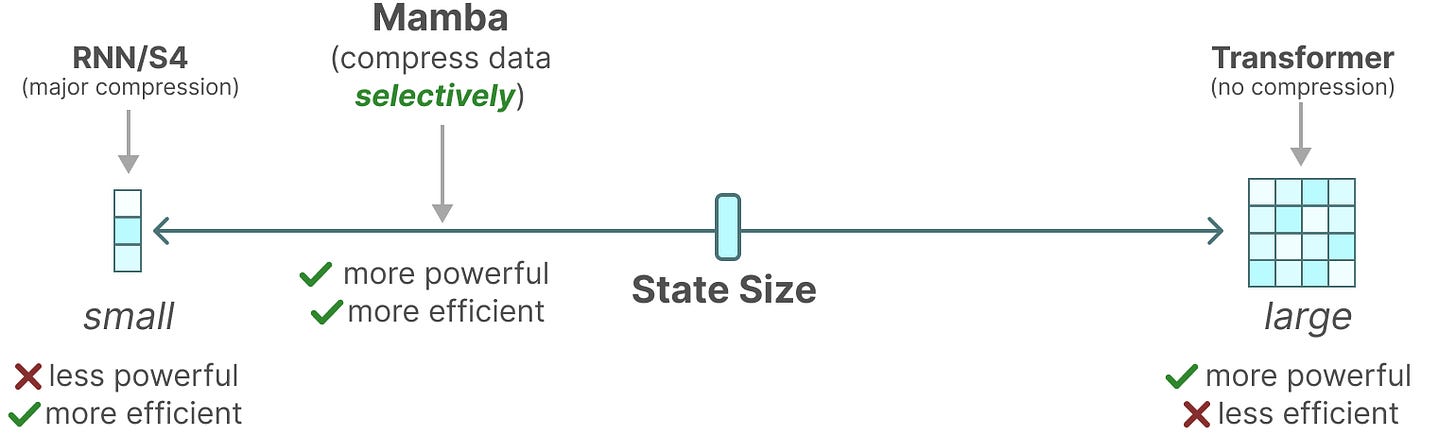
如上所述,它是通过选择性地将数据压缩到状态中实现的。当你有一个输入句子时,通常有一些信息,如停用词,它们并没有太多意义。
【两者兼顾!(●ˇ∀ˇ●)】
为了选择性地压缩信息,我们需要参数依赖于输入。为此,让我们首先在训练过程中探索 SSM 中输入和输出的维度:
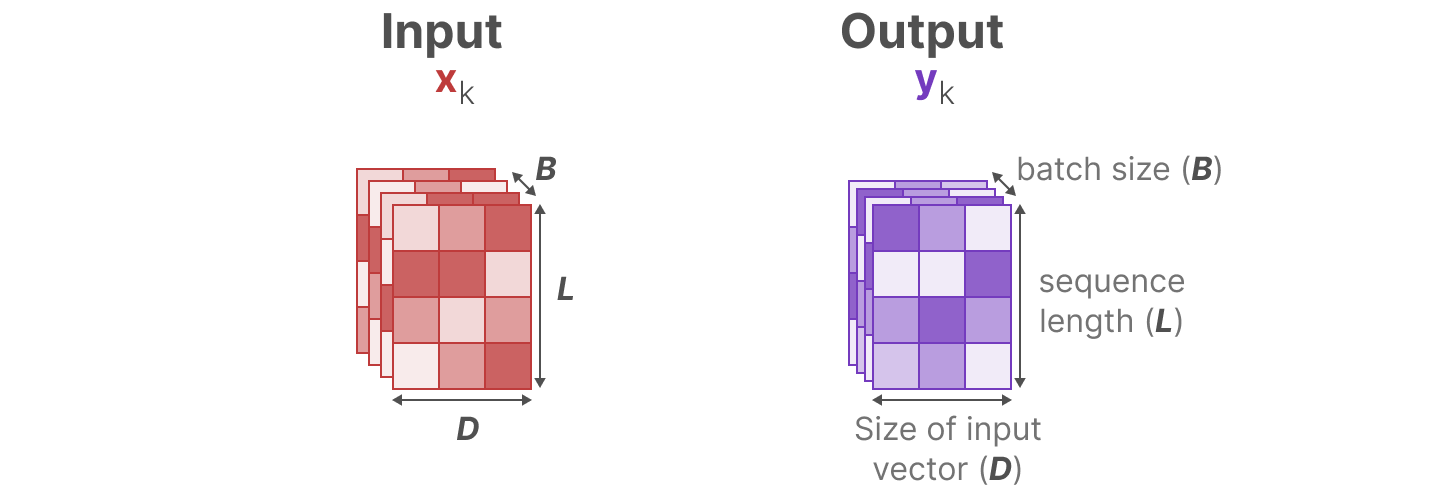
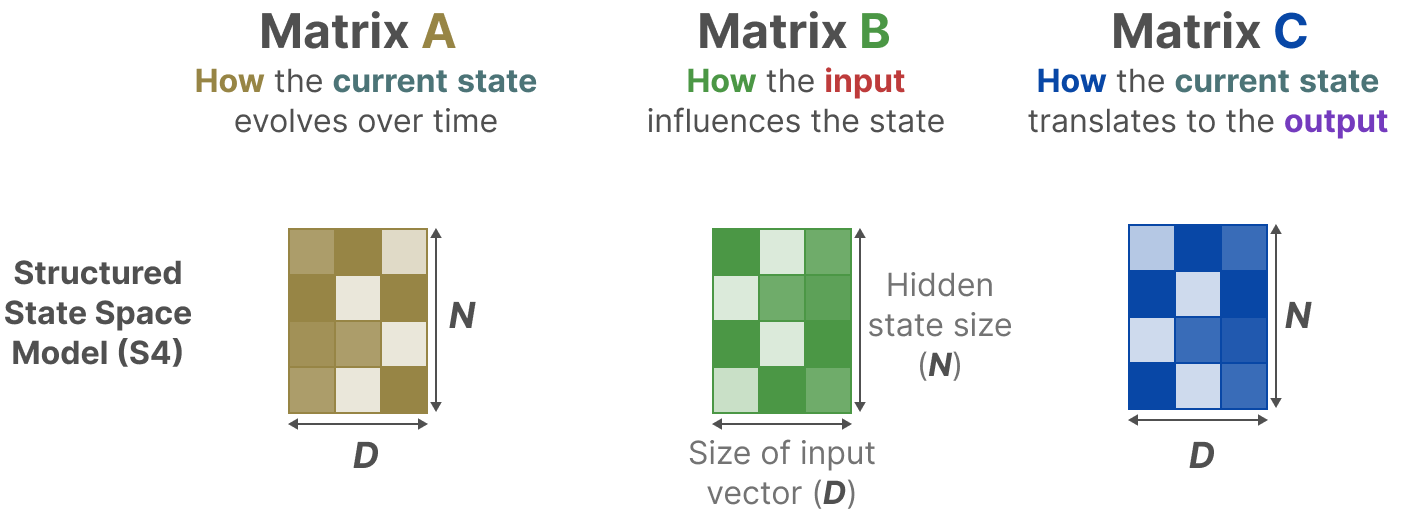
在结构化状态空间模型(S4)中,矩阵 A、B 和 C 与输入无关,因为它们的维度 N 和 D 是静态的,不会改变。
相反,Mamba 通过结合输入的序列长度和批量大小,使矩阵 B 和 C,甚至步长∆都依赖于输入:
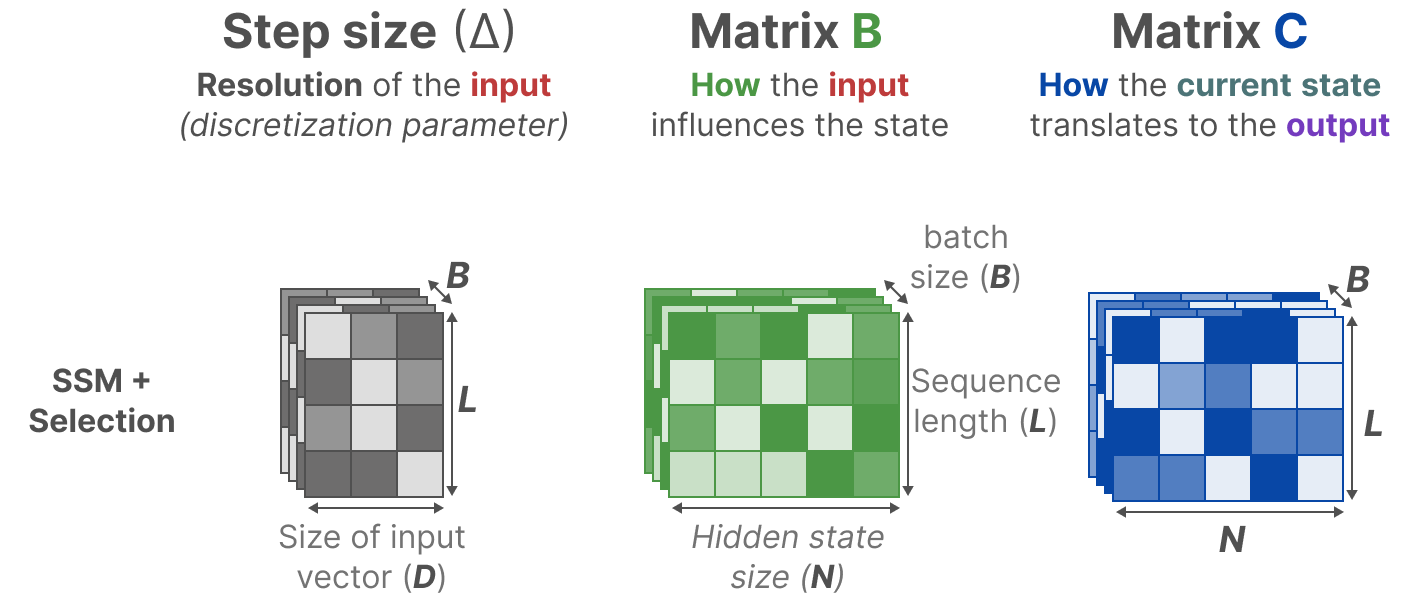
这意味着对于每个输入标记,我们现在都有不同的 B 和 C 矩阵,这解决了内容感知的问题!
【注意:矩阵 A 保持不变,因为我们希望状态本身保持静态,但影响状态的方式(通过 B 和 C)是动态的。】
它们共同选择在隐藏状态中保留什么以及忽略什么,因为它们现在依赖于输入。
步长∆越小,就越会忽略特定的单词,而更多地使用先前的上下文;而步长∆越大,则更多地关注输入单词而不是上下文:
扫描操作(The Scan Operation,可并行)
由于这些矩阵现在是动态的,因此不能使用卷积表示来计算,因为卷积表示假设有一个固定的核。我们只能使用循环表示,从而失去卷积提供的并行化优势。
为了实现并行化,让我们探索如何通过循环来计算输出:
每个状态是前一个状态的和(乘以 A)加上当前输入(乘以 B)。这被称为扫描操作,可以用 for 循环轻松计算。
并行化似乎是不可能的,因为每个状态只有在有了前一个状态的情况下才能计算。然而,Mamba 通过并行扫描算法使得这一点成为可能。
【我们可以并行!!!/(ㄒoㄒ)/~~,这种并行其实很抽象,这里建议再看看其他的】
它假设我们执行操作的顺序通过关联属性无关紧要。因此,我们可以分部分计算序列,并迭代地组合它们:
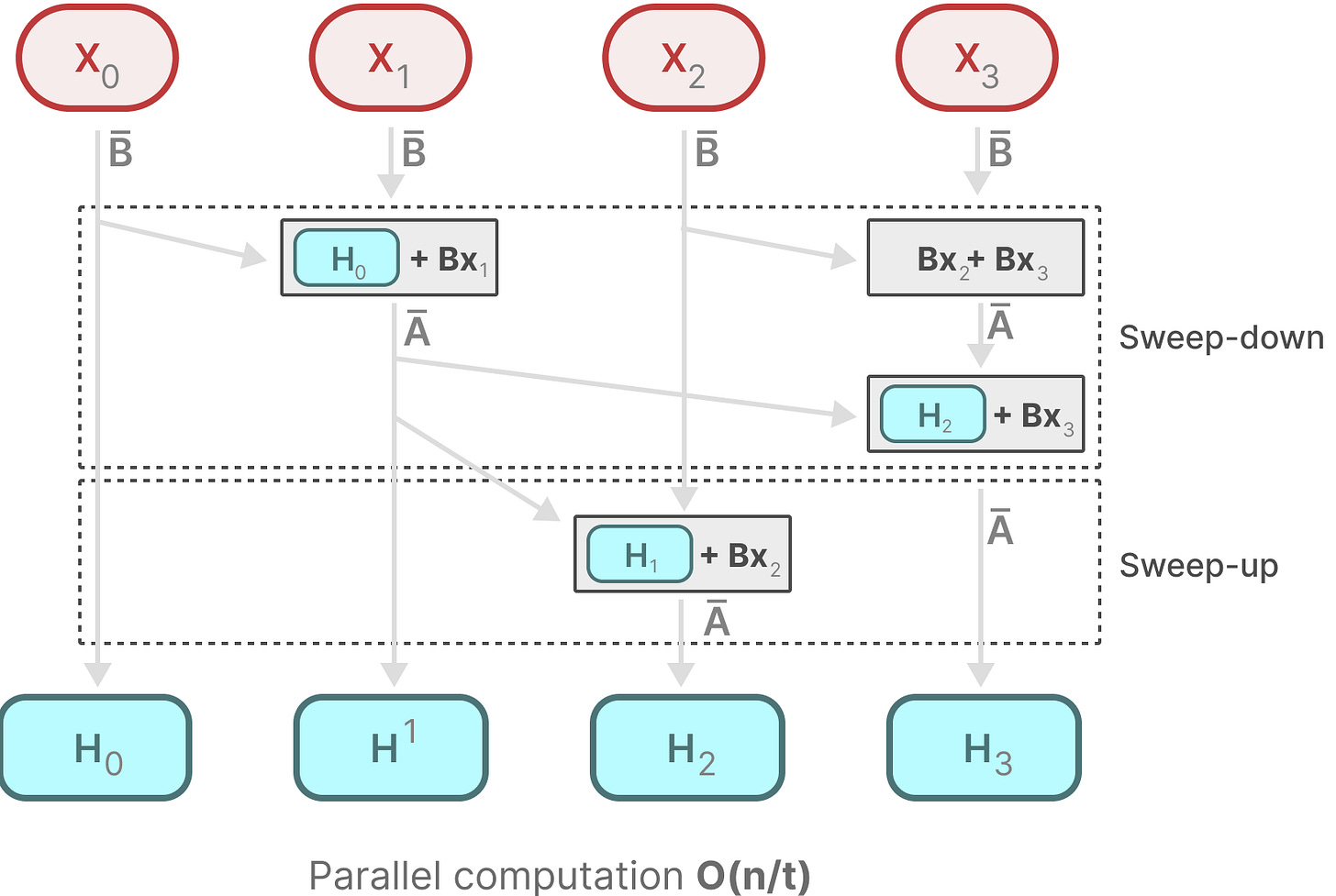
动态矩阵 B 和 C 以及并行扫描算法共同构成了选择性扫描算法,以表示使用循环表示的动态和快速特性。
硬件感知算法
【这里我就当无情的翻译搬运工了,总之它优化了硬件层的东西】
近年来 GPU 的一个缺点是它们在小型但高效的 SRAM 和大型但略低效的 DRAM 之间有限的传输(I/O)速度。频繁地在 SRAM 和 DRAM 之间复制信息成为瓶颈。

Mamba,就像 Flash Attention 一样,试图限制我们从 DRAM 到 SRAM 以及相反方向需要进行的次数。它是通过内核融合来实现的,这使得模型能够防止写入中间结果,并持续进行计算,直到完成。
我们可以通过可视化 Mamba 的基本架构来查看 DRAM 和 SRAM 分配的具体实例:
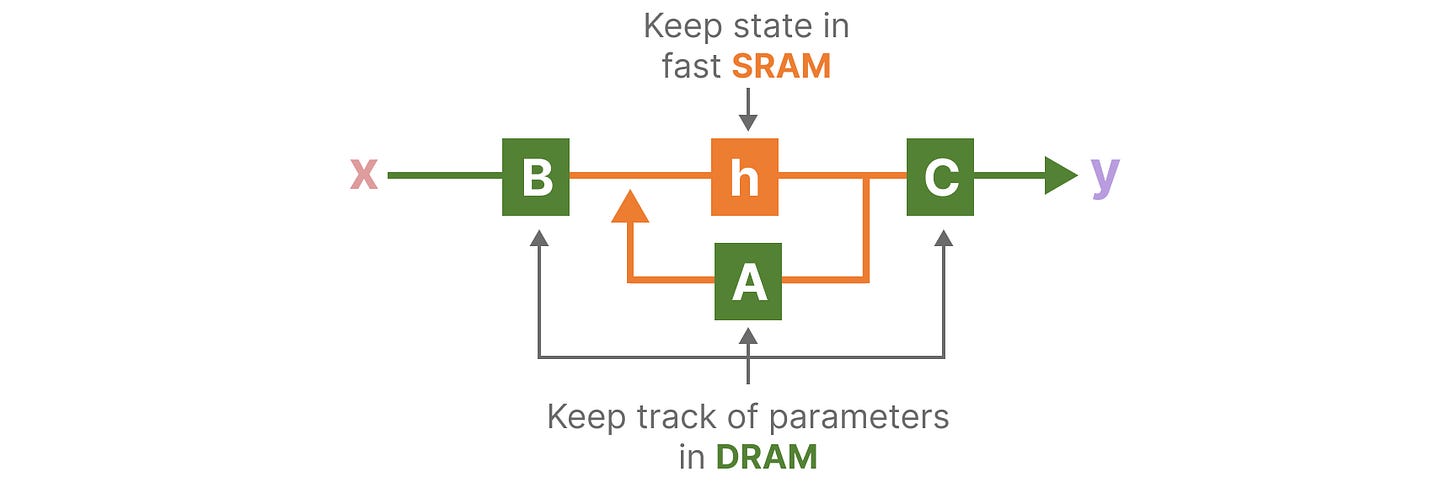
这里,以下内容融合为一个核:
- Discretization step with step size ∆(步长为∆的离散化步骤)
- Selective scan algorithm (选择性扫描算法)
- Multiplication with C (与 C 的乘法)
硬件感知算法的最后一步是重新计算。
中间状态并未保存,但对于反向传播计算梯度是必要的。相反,作者们在反向传播过程中重新计算这些中间状态。
虽然这看起来可能不太高效,但与从相对较慢的 DRAM 中读取所有这些中间状态相比,成本要低得多。
我们现在已经涵盖了其架构的所有组件,以下是从其文章中摘取的图像来展示:
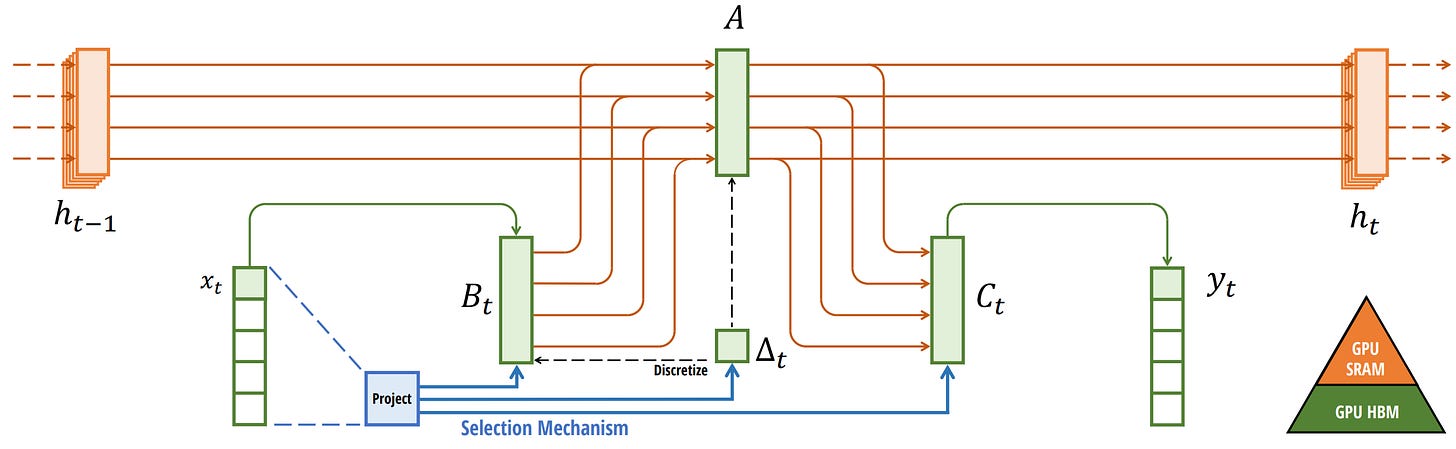
这种架构通常被称为选择性 SSM 或 S6 模型,因为它本质上是一个使用选择性扫描算法计算的 S4 模型。
Mamba模块:
到目前为止,我们探索过的选择性 SSM 可以像在解码器模块中表示自注意力一样,作为一个模块实现。
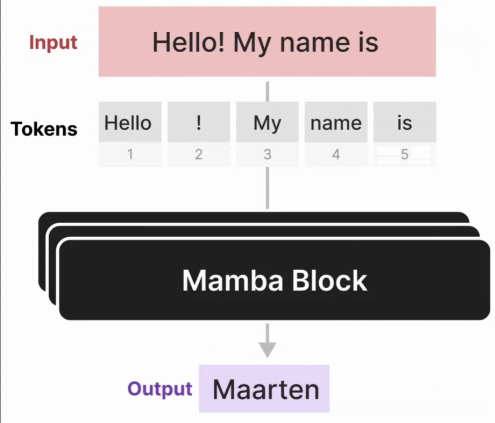
类似于解码器,我们可以堆叠多个 Mamba 模块,并将它们的输出作为下一个 Mamba 模块的输入:
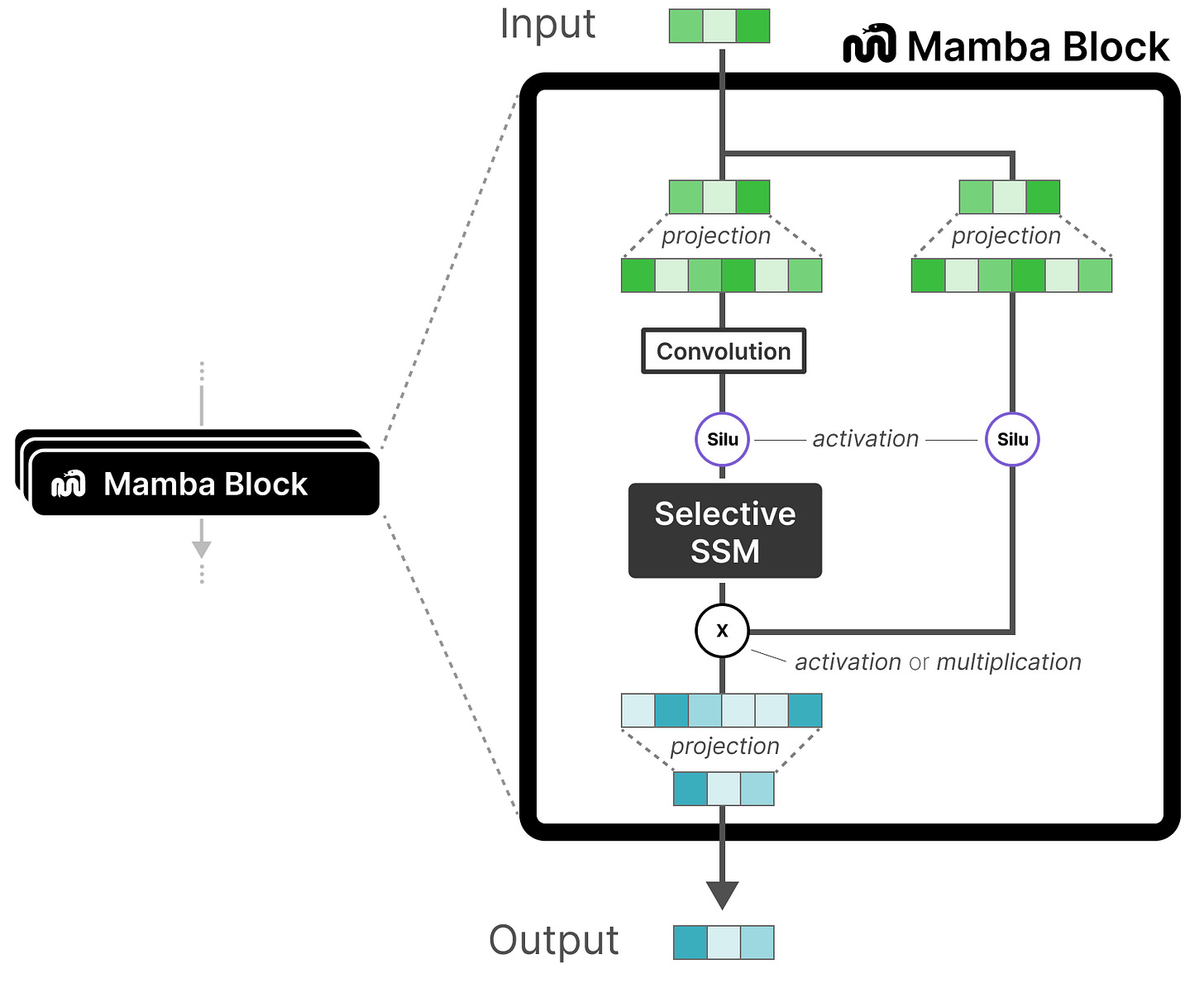
它从线性投影开始,以扩展输入嵌入。然后,在应用选择性 SSM 之前进行卷积,以防止独立标记计算。
【注意看到这里选择性状态空间模型Selective SSM】
选择性状态空间模型具有以下特性:
- 通过离散化创建的循环状态空间模型
- 在矩阵 A 上使用 HiPPO 初始化以捕捉长距离依赖关系
- 选择性扫描算法以选择性压缩信息
- 针对硬件的算法以加速计算
我们可以更详细地探讨这个架构,在查看代码实现时,并探索一个端到端的示例将如何呈现:
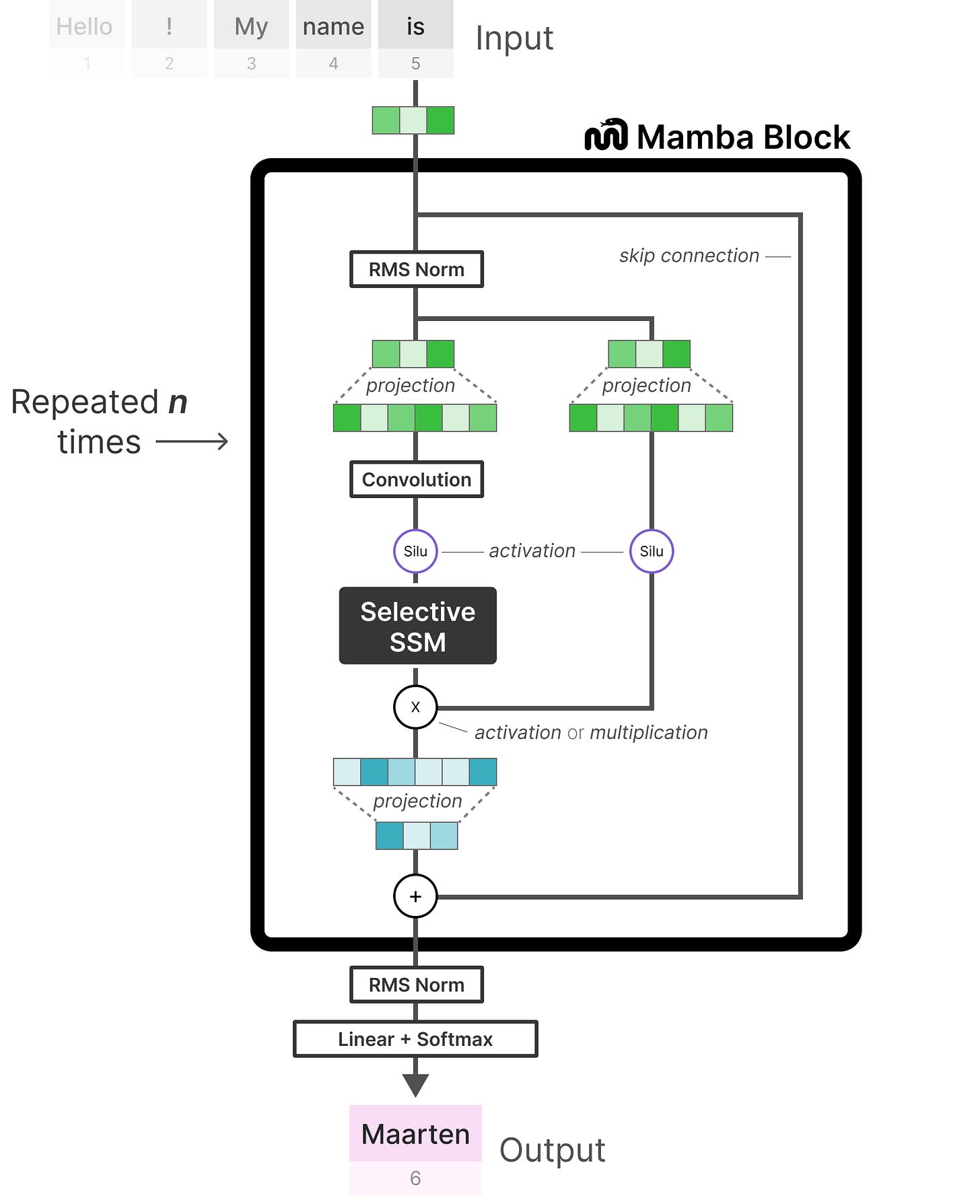
【这里就只是把我们上面的整个block模块可视化了,不要怕,用的时候我们也是直接针对整个模型进行运算操作调整的】
注意一些变化,如包含归一化层和 softmax 用于选择输出标记。
当我们把所有东西放在一起时,我们得到了快速推理和训练,甚至是无界的上下文。使用这种架构,作者发现它的性能与相同规模的 Transformer 模型相匹配,有时甚至超过!
结论(Conclusion)
这标志着我们在状态空间模型和令人难以置信的 Mamba 架构中的旅程结束。希望这篇帖子能让你更好地理解状态空间模型,尤其是 Mamba 的潜力。谁知道这会不会取代 Transformer,但至少现在,看到如此不同的架构得到应有的关注是令人兴奋的!
【买书广告*2加致谢名单】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号