

http头字段缓存详解(1)
1,浏览器缓存机制:
现在的浏览器都有缓存机制,一般使用F5刷新页面都是返回浏览器缓存的数据, 如果浏览页面发现异常时,使用Ctrl+F5组合键重新请求的页面就是没有缓存的最新页面
F5刷新:

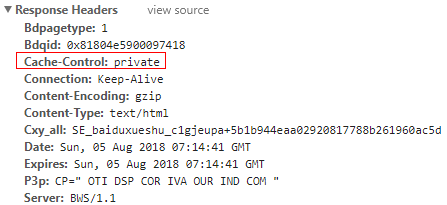
ctrl+f5刷新:
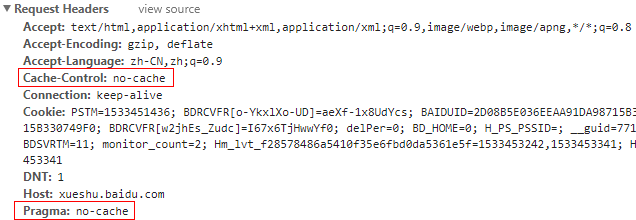
1.1,为什么使用Ctrl+F5重新请求的就是没有缓存的页面呢?
当使用Ctrl+F5组合键刷新页面时

ps:缓存方式分为浏览器和服务器缓存。
1.2,原理:
当我们在使用Ctrl+F5组合键刷新一个页面时, 会在HTTP请求头中增加一些请求项(最重要的是在请求头中增加了两个请求项Pragma:no-cache和Cache-Control:no-cache) 通过它来告诉服务器我们要获取的是最新的数据,而不是缓存数据
Cache-Control / Pragma 这个HTTP Head字段用于指定所有缓存机制在整个请求/响应链中必须服从的指令。
1.3,Cache-Control字段有一些可选值,如下所示:
Public :所有内容都将被缓存,在响应头中设置 Private :内容只缓存到私有服务器中,在响应头中设置 no-cache :所有内容都不会被缓存,在请求头和响应头中设置
另一种说法:不是不缓存而是使用缓存需要验证(可以通过请求头If-None-Match和响应头ETag,来对缓存的有效性进行验证。)
(ps:应该是可选择的配合验证,而不是必须配套使用)
no-store :所有内容都不会被缓存到缓存或Internet临时文件中,在响应头中设置 must-revalidation/proxy-revalidation :如果缓存的内容失效,请求必须发送到服务器/代理以进行重新验证,在请求头中设置 max-age=xxx :缓存的内容将在xxx秒后失效,这个选项只在HTTP1.1中可用,和Last-Modified一起使用时优先级较高,在响应头中设置
1.4,HTTP其他缓存头字段:
Expires :
它通常的使用格式是Expires:Fri ,24 Dec 2027 04:24:07 GMT,后面跟的是日期和时间,
超过这个时间后,缓存的内容将失效,浏览器在发出请求之前会先检查这个页面的这个字段,查看页面是否已经过期,过期了就重新向服务器发起请求;
Last-Modified / If-Modified:
它一般用于表示一个服务器上的资源最后的修改时间,资源可以是静态或动态的内容,
通过这个最后修改时间可以判断当前请求的资源是否是最新的。
一般服务端在响应头中返回一个Last-Modified字段,告诉浏览器这个页面的最后修改时间,
浏览器再次请求时会在请求头中增加一个If-Modified字段,询问当前缓存的页面是否是最新的,
如果是最新的就返回304状态码,告诉浏览器是最新的,服务器也不会传输新的数据
(ps:也就是服务器省略了具体内容的传输,只需返回一个标识状态码)
补充:304状态码
304(未修改) 自从上次请求后,请求的网页未修改过。服务器返回此响应时,不会返回网页内容。
Etag/If-None-Match:
(ps:一般用于当Cache-Control:no-cache时,用于验证缓存有效性)
Etag与Last-Modified有类似的功能,它的作用是让服务端给每个页面分配一个唯一 的编号,然后通过这个编号来区分当前这个页面是否是最新的,
这种方式更加灵活,但是后端如果有多台Web服务器时不太好处理,因为每个Web服务器都要记住网站的所有资源,否则浏览器返回这个编号就没有意义了。
疑问:哪些是浏览器主动控制的,哪些是服务器主动控制的。
PS:总结:
为什么响应头可能几种参数同时存在: Cache-Control:max-age=315360000 ETag:"96a3-558a6b1f51e40" Expires:Tue, 20 Jun 2028 06:17:28 GMT Last-Modified:Fri, 08 Sep 2017 05:17:37 GMT 个人理解是: 1,是存在优先级 2,是浏览器兼容问题 即真正起作用的只是其中某个某几个参数。
2,详解Cache-Control和ETag(请求头If-None-Match、响应头ETag)
请求头中和响应头中的Cache-Control的区别:
请求头里的Cache-Control是no-cache,是浏览器通知服务器:本地没有缓存数据 响应头中的 Cache-Control:max-age=259200 是通知浏览器:259200 秒之内别来烦我,自己从缓冲区中刷新
如果响应头中有 Cache-Control=no-cache 那么浏览器是不会缓存的
不过即使有缓存,也不一定被浏览器使用。因为浏览器还有其他设置
同时并不是与缓存相关的头都会被浏览器接受,协议只是建议,并不一个定非要执行
请求头里的no-cache表示浏览器不想读缓存,并不是说没有缓存。
一般在浏览器按ctrl+F5强制刷新时,请求头里就有这个no-cache,也就是跳过强缓存和协商缓存阶段,直接请求服务器。
(如果直接按F5的话,请求头是max-age=0,只跳过强缓存,但进行协商缓存)
关注请求头If-None-Match、响应头ETag、响应头Cache-Control
当今绝大多数的浏览器,都支持这三个Http头。
我们所要做的就是,确保每个服务器响应都提供正确的 HTTP 头指令,以指导浏览器何时可以缓存响应以及可以缓存多久。
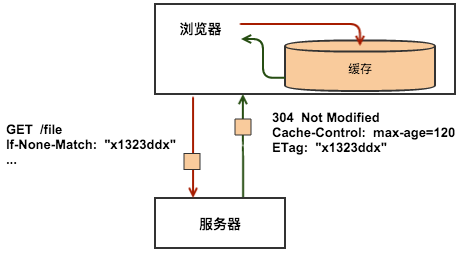
缓存在哪儿?

上图中有三个角色,浏览器、Web代理和服务器,如图所示Http缓存存在于浏览器和Web代理中。
当然在服务器内部,也存在着各种缓存,但这已经不是本文要讨论的Http缓存了。
所谓的Http缓存控制,就是一种约定,通过设置不同的响应头Cache-Control来控制浏览器和Web代理对缓存的使用策略,
通过设置请求头If-None-Match和响应头ETag,来对缓存的有效性进行验证。
响应头ETag
ETag全称Entity Tag,用来标识一个资源。
在具体的实现中,ETag可以是资源的hash值,也可以是一个内部维护的版本号。
但不管怎样,ETag应该能反映出资源内容的变化,这是Http缓存可以正常工作的基础。

如上例中所展示的,服务器在返回响应时,通常会在Http头中包含一些关于响应的元数据信息,
其中,ETag就是其中一个,本例中返回了值为x1323ddx的ETag。
当资源/file的内容发生变化时,服务器应当返回不同的ETag。
请求头If-None-Match
对于同一个资源,比如上一例中的/file,在进行了一次请求之后,浏览器就已经有了/file的一个版本的内容,和这个版本的ETag,
当下次用户再需要这个资源,浏览器再次向服务器请求的时候,可以利用请求头If-None-Match来告诉服务器自己已经有个ETag为x1323ddx的/file,
这样,如果服务器上的/file没有变化,也就是说服务器上的/file的ETag也是x1323ddx的话,服务器就不会再返回/file的内容,
而是返回一个304的响应,告诉浏览器该资源没有变化,缓存有效。
响应头Cache-Control
每个资源都可以通过Http头Cache-Control来定义自己的缓存策略,
Cache-Control控制谁在什么条件下可以缓存响应以及可以缓存多久。
最快的请求是不必与服务器进行通信的请求:
通过响应的本地副本,我们可以避免所有的网络延迟以及数据传输的数据成本。
为此,HTTP 规范允许服务器返回一系列不同的 Cache-Control 指令,控制浏览器或者其他中继缓存如何缓存某个响应以及缓存多长时间。
Cache-Control 头在 HTTP/1.1 规范中定义,取代了之前用来定义响应缓存策略的头(例如 Expires)。
当前的所有浏览器都支持 Cache-Control,因此,使用它就够了。
Cache-Control中设置的常用指令
max-age 该指令指定从当前请求开始,允许获取的响应被重用的最长时间(单位为秒。
例如:Cache-Control:max-age=60表示响应可以再缓存和重用 60 秒。
需要注意的是,在max-age指定的时间之内,浏览器不会向服务器发送任何请求,包括验证缓存是否有效的请求,
也就是说,如果在这段时间之内,服务器上的资源发生了变化,那么浏览器将不能得到通知,而使用老版本的资源。
所以在设置缓存时间的长度时,需要慎重。 public和private 如果设置了public,表示该响应可以再浏览器或者任何中继的Web代理中缓存,public是默认值,
即Cache-Control:max-age=60等同于Cache-Control:public, max-age=60。 在服务器设置了private比如Cache-Control:private, max-age=60的情况下,
表示只有用户的浏览器可以缓存private响应,不允许任何中继Web代理对其进行缓存
例如,用户浏览器可以缓存包含用户私人信息的 HTML 网页,但是 CDN 不能缓存。
no-cache 如果服务器在响应中设置了no-cache即Cache-Control:no-cache,
那么浏览器在使用缓存的资源之前,必须先与服务器确认返回的响应是否被更改,如果资源未被更改,可以避免下载。
这个验证之前的响应是否被修改,就是通过上面介绍的请求头If-None-match和响应头ETag来实现的。 需要注意的是,no-cache这个名字有一点误导。
设置了no-cache之后,并不是说浏览器就不再缓存数据,只是浏览器在使用缓存数据时,需要先确认一下数据是否还跟服务器保持一致。
如果设置了no-cache,而ETag的实现没有反应出资源的变化,那就会导致浏览器的缓存数据一直得不到更新的情况。 no-store 如果服务器在响应中设置了no-store即Cache-Control:no-store,
那么浏览器和任何中继的Web代理,都不会存储这次相应的数据。
当下次请求该资源时,浏览器只能重新请求服务器,重新从服务器读取资源。
怎样决定一个资源的Cache-Control策略呢?
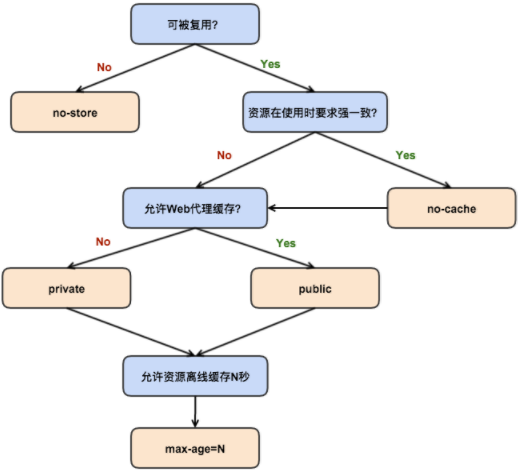
3,HTTP缓存机制[译文]
通过重用已获取的资源,可大幅提高web站点和应用的性能。
由于web缓存减少了延迟和网络流量,因此缩短了展示一个资源所需的时间。
通过使用HTTP缓存机制,web站点可实现更快更灵活的响应。
缓存的目的:
1,减轻服务器压力(服务器不用每次为所有客户端提供服务了),
2,提高访问效率(因为缓存离客户端最近,可直接提供资源副本,也可节省很多传输时间)。
所有不同类型的缓存,大致可以归为两类:
私有缓存 和 共享缓存。
1,共享缓存中存储的资源副本是供所有用户使用的(比如不同浏览器,不同机器),
2,私有缓存是仅提供给单个用户的专有缓存(不同用户保留不同私有缓存副本)。
本文仅讨论浏览器缓存和代理缓存,但就目前来讲,还有很多其他类型的缓存,
比如:网关缓存、CDN、反向代理缓存、负载均衡
(负载均衡是部署在服务器端的,为多个web服务器提供更可靠、更高性能以及更易进行规模化扩展的方案)。
浏览器(私有)缓存
私有缓存是单个用户的专有缓存, 一般来讲,在你的浏览器设置中就可以看到“缓存”的选项。 浏览器缓存保留了用户通过HTTP下载的所有文档资源,前进/后退、保存、查看源代码等操作都可以使用到此缓存,而不用再重新访问服务器。 同样的,有了缓存,我们还可以实现脱机浏览文档和资源。
代理(共享)缓存
共享缓存中存放的访问结果是提供给多个用户使用的。
比如:ISP或你的公司可能会组建一个本地网络的代理,该代理(服务器)会缓存不同用户访问外网时请求的公共资源,
这些公共资源被缓存后,下次其他用户也访问同一资源时,就会重用此已被缓存的资源(就不用再向源站获取了),从而减少了网络浏览和延迟。
缓存操作的目标
HTTP缓存通常只缓存GET请求(其他请求一般不缓存),缓存的主键由请求方法和目标URI(通常只用到URI,因为一般仅缓存GET请求)组成。
通常的缓存条目有:
成功的查询请求的结果数据:状态码为200的GET响应(结果中可能包含资源数据如:HTML文档、图片或文件等)
永久性跳转:状态码为301(Moved Permanently)的响应
返回出错,文档不存在:状态码为404(Not Found)的响应
不完整的结果数据:状态码为206(Partial Content)的响应(通过Range头发起的请求所返回的结果,Range用于只获取文档某一部分)
其他非GET请求的结果(如果这些结果比较适合作为缓存的话)
缓存控制
Cache-control头部
HTTP/1.1中,Cache-Control头用于指定缓存机制中的不同指令,它是可用在请求报文及响应报文中的通用头部。 通过该头部提供的不同指令,你可以定义一个自己的缓存策略。
禁止缓存 方式
如下头部定义,在该方式下,缓存不会保存任何的客户端请求和服务器响应。
每次客户端的请求都会发送到源服务器,并且每次源服务器返回的数据都会全部下载到客户端。 Cache-Control: no-store Cache-Control: no-cache, no-store, must-revalidate
强制确认缓存 方式
如下头部定义,此方式下,每次有请求发出时,缓存会将此请求发到服务器(译者注:该请求应该会带有与本地缓存相关的验证字段),
服务器端会验证请求中所描述的缓存是否过期,若未过期(译者注:实际就是返回304),则缓存才使用本地缓存副本。
Cache-Control: no-cache
私有和公共缓存
"public" 指令表示该响应可以被任何中间人(译者注:比如中间代理、CDN等)缓存。 若指定了"public",则一些通常不被中间人缓存的页面
(比如 带有HTTP验证信息(帐号密码)的页面 或 某些特定影响状态码的页面),将会被其缓存。 而 "private" 则表示该响应是专用于某单个用户的,中间人不能缓存此响应,该响应只能应用于浏览器私有缓存中。 Cache-Control: private Cache-Control: public
过期机制
过期机制中,最重要的指令是 "max-age=<seconds>",表示资源能够被缓存(保持新鲜)的最大时间。 与 Expires指令不同,该指令的值是相对于请求的那个时间之后的秒数。 对于那些不会变动的文档资源,你可以直接将其设置为永久缓存,比如像图片、CSS文件、JS文件这些静态资源。 Cache-Control: max-age=31536000
验证确认
当使用了 "must-revalidate" 指令,那就意味着缓存在考虑使用一个陈旧的资源时,必须先验证它的状态,并且,已过期的缓存将不被使用。 Cache-Control: must-revalidate
Pragma 头部
Pragma 是HTTP/1.0规范中的头部,它已经不是可靠的用于过期控制的头部了,
尽管它的行为和 Cache-Control: no-cache 一致(未设置Cache-Control头部的情况下)。
Pragma 现仅用于兼容 HTTP/1.0 客户端。
新鲜度
理论上来讲,当一个资源被缓存存储后,该资源应该可以被永久存储在缓存中。
由于缓存只有有限的空间用于存储资源副本,所以缓存会定期地将一些副本删除,这个过程叫做 缓存驱逐。
另一方面,当服务器上面的资源进行了更新,那么缓存中的对应资源也应该被更新,
由于HTTP是C/S模式的协议,服务器更新一个资源时,不可能直接通知客户端及其缓存,
所以双方必须为该资源约定一个过期时间,在该过期时间之前,该资源(缓存副本)就是 新鲜的,
当过了过期时间后,该资源(缓存副本)则变为 陈旧的。
驱逐算法用于将陈旧的资源(缓存副本)替换为新鲜的,注意,一个陈旧的资源(缓存副本)是不会直接被清除或忽略的,
当客户端发起一个请求时,缓存检索到已有一个对应的陈旧资源(缓存副本),则缓存会先将此请求附加一个If-None-Match头,
然后发给目标服务器,以此来检查该资源副本是否是依然还是算新鲜的,
若服务器返回了 304 (Not Modified)(该响应不会有带有实体信息),则表示此资源副本是新鲜的,这样一来,可以节省一些带宽。
(译者注:若服务器通过 If-None-Match 或 If-Modified-Since判断后发现已过期,那么会带有该资源的实体内容返回)
新鲜度的生命周期是通过若干头部值来计算的,如果设置了 "Cache-control: max-age=N" 头部,那么新鲜度的生命期则等于 N。
经常情况下,可能未设置此头部,则会检查 Expires 头部是否存在,
若 Expires 头部存在,则新鲜度生命期 等于 该头部的值 减去 Date 头部的值。
若两种头部都未设置,则会查找 Last-Modified 头部,
若存在,则新鲜度生命期 等于 Date 头部值 减去 Last-modified 头部值 再除以 10。
资源版本化
缓存使用越频繁(译者注:跟命中率有关了),那么网站的响应速度和效率就越高,为此,在最佳实践中,我们推荐尽可能地将过期时间设置得长一些,
但这会导致我们很难去更新那些不常变动的资源。
比如我们经常会遇到这样的需求:
很多页面都引用了一些JS和CSS文件,当这些文件的内容变动时,我们希望能尽快地让其在缓存中更新。
web开发者们研究出一个方案,Steve Sounders称它为 revving[1]。
其原理是,将那些经常更新的文件的文件名通过一种特别的方式来命名,
即文件名中加入版本号,这样一来,每一次文件内容改变,文件名也被一起改变,就相当于新建了另一个不同的资源,
那我们就可以将该资源设置为永久不过期了(通常设置为1年以上)。
但为了引用这个改动后的资源,所以链接到此资源的链接地址都需要改变(译者注:其文件名改变后,相对应的URI也改变,所以链接到此资源的地址也应该改变),
这也是该方案的缺点:
带来了额外的复杂性,通常web开发者会使用一些工具来自动应对此缺点(译者注:如webpack),
当不常变动的资源改变时,这些资源的文件名URI也随之改变,而引用这些资源的另外的经常变动的资源,也将随之改变(引用地址改变),
当客户端请求常变动的资源时,它里面引用的不常变动的资源,由于加入了版本号,所以其新的版本也被下载。
这种方案有一个好处:
可以解决2个资源过期时间不一致导致不一同被更新的问题。
这在当网站的CSS或JS资源拥有共同的依赖时显得尤为重要,
比如他们引用了同一个HTML元素,导致他们互相依赖。
(译者注:举例,比如当前缓存了两个JS文件A,B,A里面是比较早期的功能,A先过期,B是晚于A开发的功能,且依赖于A,B后过期,
假如这期间服务器端A和B都做了改变,加了新的功能,那么当A过期时拿到了最新版的A,而B还未过期,则使用的是旧版的B,这样页面运行时,可能导致严重错误)。
添加在资源名称上面的版本号并非必须是像1.1.3这样的常用版本定义方式,甚至可以仅仅是一个连续递增的数字,
只要版本号不冲突,它可以是任意的,比如hash值或日期时间。
缓存的验证确认
当用户点击刷新(重新加载)按钮时,就会触发一个再次验证确认,当用户正常访问某网站/资源时,浏览器会检查该请求对应的缓存内容,
若之前缓存的响应内容中,包含了 "Cache-control: must-revalidate" 头部,那么也会触发一个再次验证确认。
另外一个引发再次验证确认的因素是:用户可以在浏览器的 Advanced->Cache 设置选项面板中设置 强制每次加载页面时都进行验证确认。 当一个缓存副本已经到了过期时间,那么就会先到服务器验证确认此缓存的新鲜度,或者直接从服务器获取该资源最新的内容。
验证确认操作仅仅在服务器的响应信息中提供了 强验证器 或 弱验证器 才会发生。
ETag头部
响应报文中的 ETag 头是一个对 用户代理透明 的值,被用来作为强验证器,
意思就是说,像浏览器这样的用户代理程序并不知道其值代表的含义。
若在服务器的响应报文中含有 ETag 头部,
则后续客户端发起同一请求时,会附加一个 If-None-Match 头部(其值为之前Etag的值)用于让服务器验证该请求对应的缓存是否新鲜。 响应报文中的 Last-Modified 头用来作为弱验证器,之所以作为“弱”,是因为它最多只能精确到秒,
若服务器的响应报文中存在 Last-Modified 头部,那么客户端发起一个 If-Modified-Since 请求来验证缓存是否新鲜。 当发起了一个验证请求,服务器可以忽略此验证请求并返回一个正常的 200 OK 响应报文,
或者也可以返回 304 Not Modified(带有一个空的实体)来告知浏览器:
你可以使用当前缓存副本,后者(304)的响应报文中也可以附加一些头部,用来更新当前缓存副本中缓存的头部信息。
可变响应 - Vary头部
响应报文中的 Vary 头部用于 决定如何匹配后续请求的头部,从而决定是否采用某缓存副本,而不是从服务器获得一个新的副本。
当发起一个请求时,缓存命中了一个副本(之前缓存的响应报文信息),
而这个副本中含有 Vary 头部,那么缓存需要检查 Vary 头部中所列出的头部字段,
若在当前请求中的这些头部字段值 与 缓存副本中响应的头部字段值匹配,
那么可以使用此缓存副本,否则需要不能使用此副本(重新请求服务器)。
有了这个头部,就可以动态地提供内容了,
举个例子,
当我们使用 Vary: User-Agent 头部时,缓存服务器就需要去查看新发起的请求的 User-Agent 头部是否匹配,
然后再决定是否采用缓存。如果你需要为手机端用户展示不同的内容,
此举可以防止将电脑端的缓存错误地提供给了手机端的用户,
并且还可以帮助Google这些搜索引擎发现并抓取手机端版本的页面,以及告诉搜索引擎这不是 Cloaking 作弊。 Vary: User-Agent 由于 User-Agent 头部在移动端和电脑端中的值都是不同的,所以缓存就不会错误地将移动端内容提供给电脑端用户了,反之亦然。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号