
50系显卡配置运行sovits4.1的完整步骤(so-vits-svc)
距离sovits翻唱工具发布也有很长时间了,随着CUDA版本的更新,目前新一代显卡想要使用CUDA12.8版本运行这个项目,还是有一些兼容性问题需要处理
项目github地址:https://github.com/svc-develop-team/so-vits-svc
一、事前准备:CUDA
1,检查显卡支持的CUDA版本
输入命令:nvidia-smi
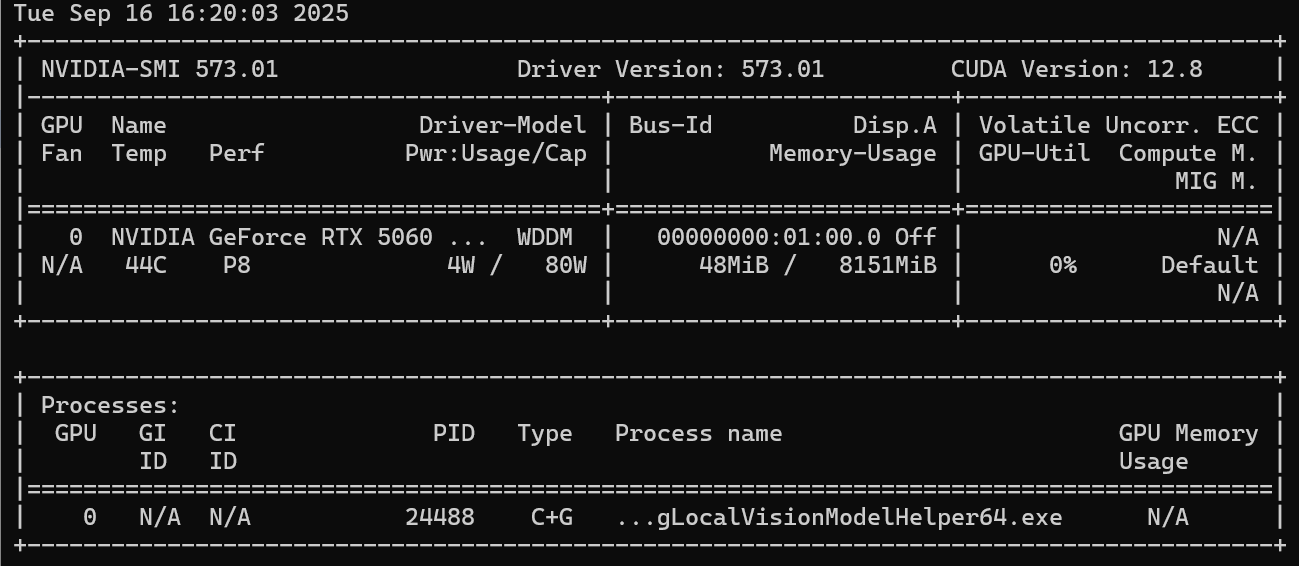
2,去英伟达官网,下载并安装右上角对应的CUDA版本
安装完成后输入:nvcc -V,如图显示就说明安装好了

二、安装相关依赖
1,安装miniconda,创建一个python3.10的虚拟环境
conda create -n 环境名 python=3.10
然后激活相应的环境:conda activate 环境名
2,降级pip版本到24.0
直接输入:pip install pip==24.0
这个指令在conda里面应该是不得行的,不过问题不大,conda会给你提示正确的指令
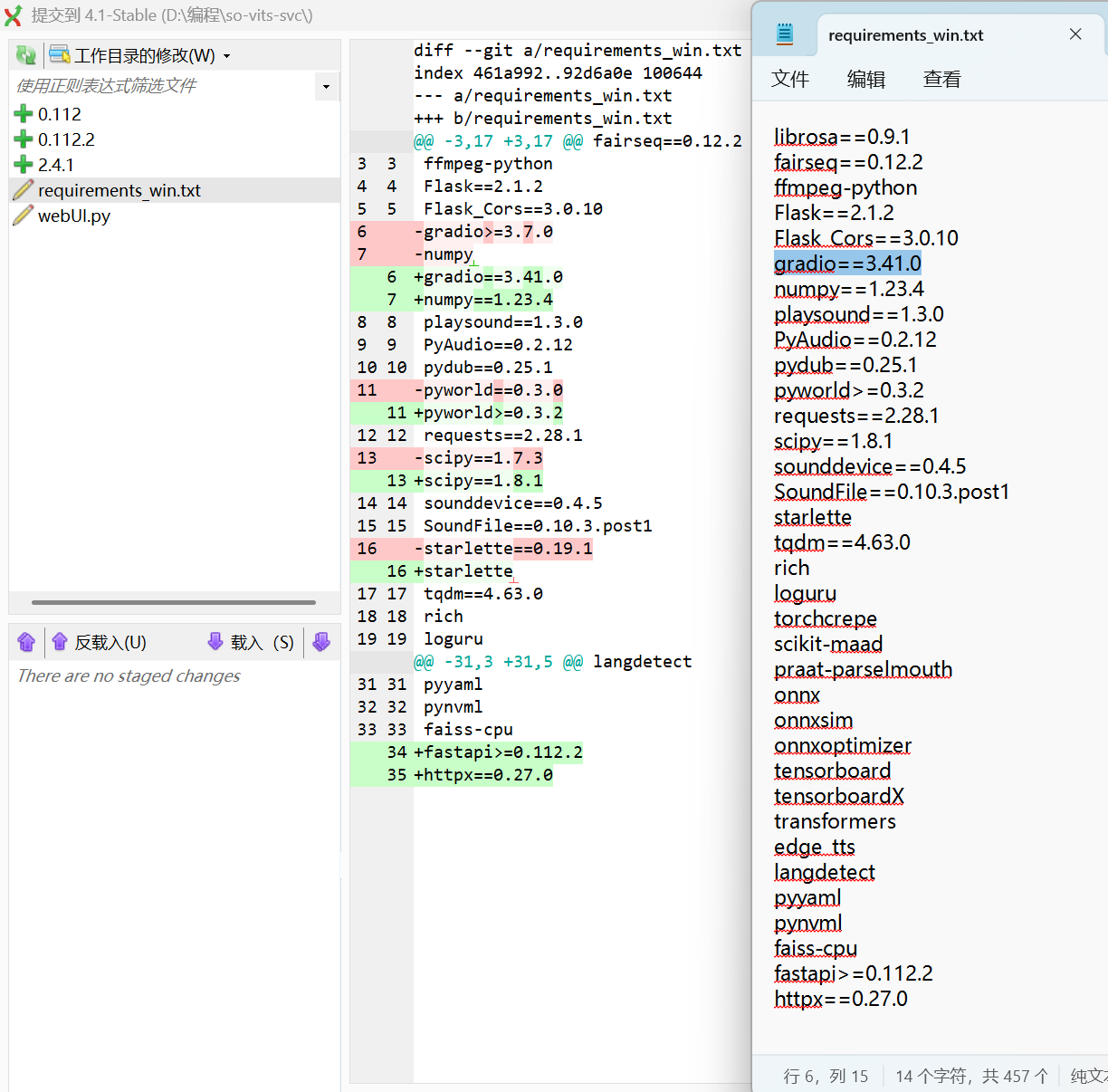
3,调整依赖库版本
直接从github拉取的4.1-Stable分支,依赖库有一些问题,需要修改。具体改动如图所示
(注:降级pip版本是为了支持这里>=的写法,并且某些库内部依赖也有这种写法。因此,就算把requirements_win中所有>=都改成==,依然需要降级pip)
改动完成后使用已下命令安装:
pip install -r requirements_win.txt
三、安装CUDA12.X对应的pytorch,以及推理代码兼容性调整
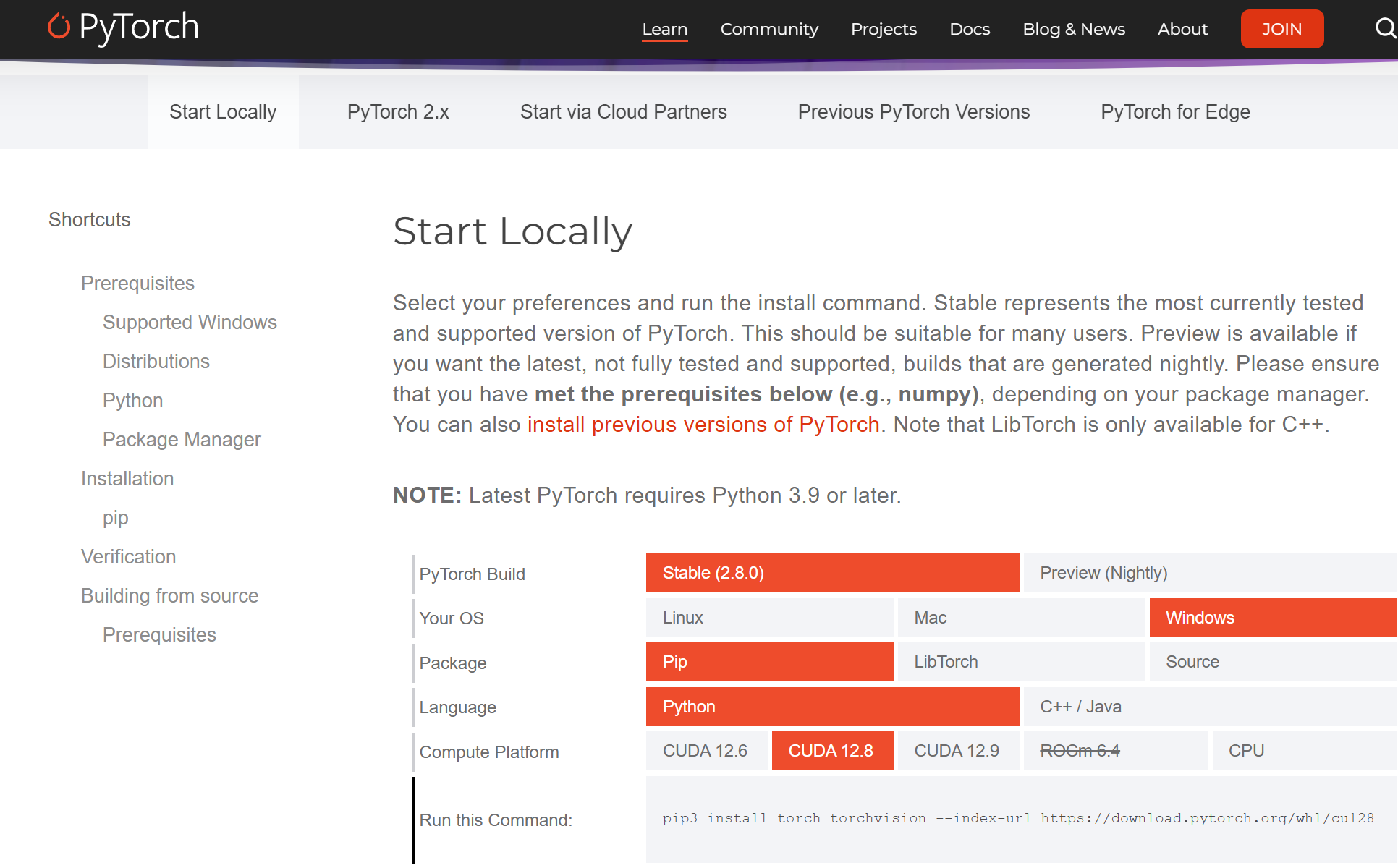
1,安装pytorch的CUDA版本
在pytorch官网,调整好CUDA的对应版本,复制相应的下载指令
2,安装和pytorch版本一致的torchaudio
输入命令:pip install torchaudio==2.8.0+cu128 --index-url https://download.pytorch.org/whl/cu128
注:此处以torchaudio2.8.0,CUDA12.8为例,请自行调整上述指令的版本,url地址和之前pytorch官网复制的一致
3,检测是否安装成功
在python命令行输入以下代码,进行测试:
import torch import torchaudio print(f"PyTorch版本: {torch.__version__}") print(f"Torchaudio版本: {torchaudio.__version__}") print(f"CUDA是否可用: {torch.cuda.is_available()}")
4,兼容性调整
在webUI中添加以下代码,新版的pytorch有安全反序列化问题,之后就可以正常启动webUI进行推理了
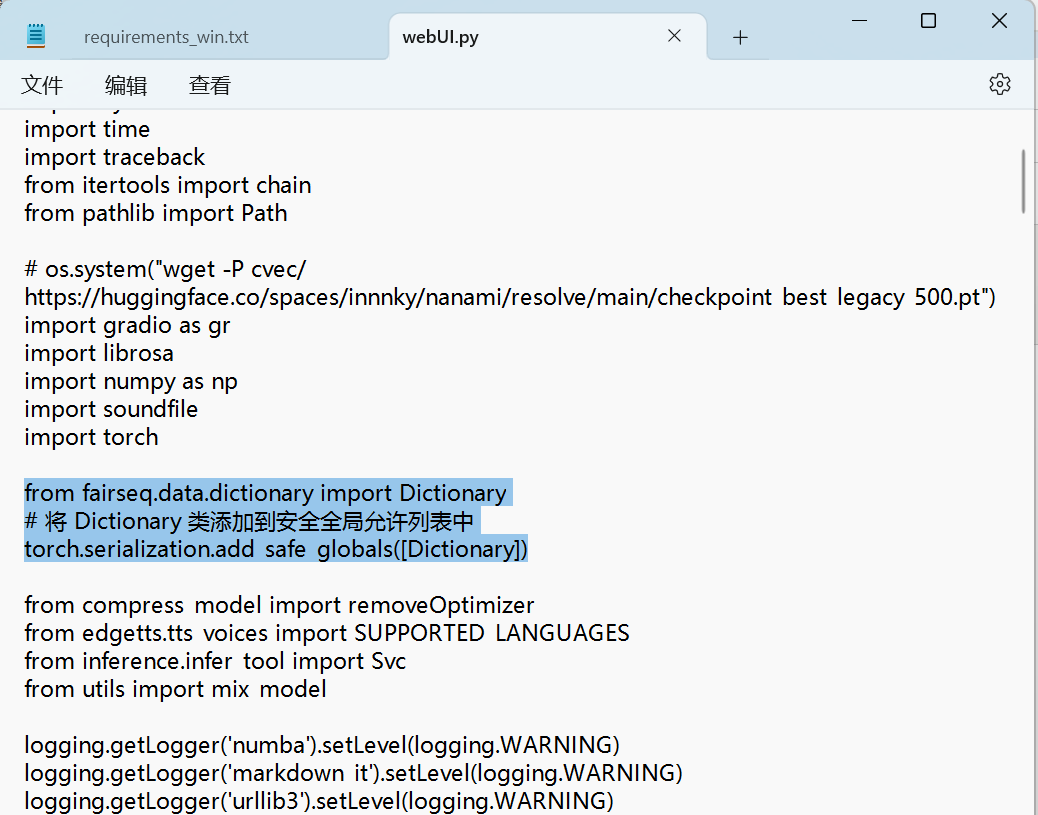
from fairseq.data.dictionary import Dictionary # 将 Dictionary 类添加到安全全局允许列表中 torch.serialization.add_safe_globals([Dictionary])
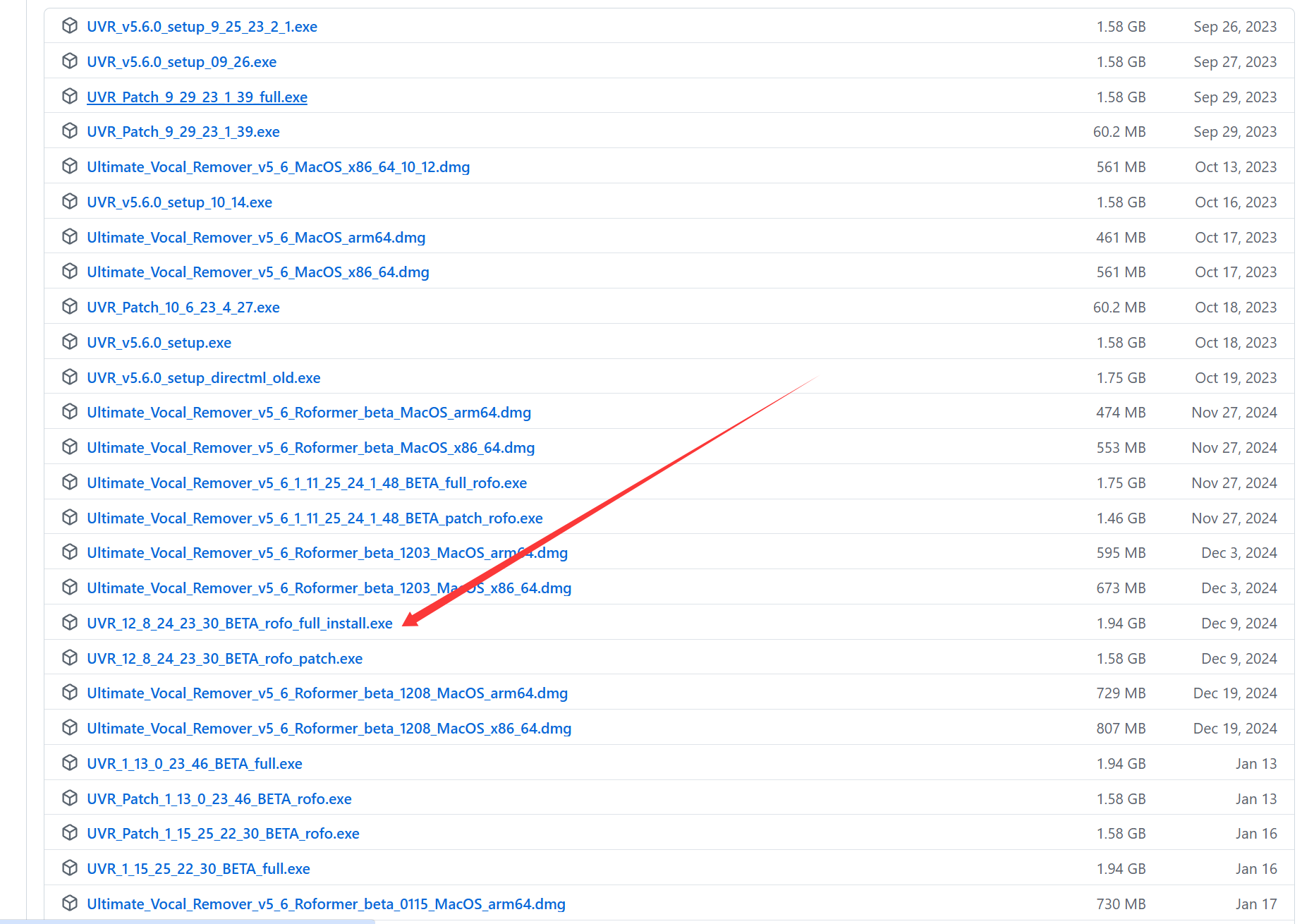
2025.9补充:50系显卡如果需要UVR5的GPU推理,请拉到最底下,下载12_8版本(以前的显卡使用5.6.0版本即可)
UVR5官网:https://ultimatevocalremover.com/
四、训练代码调整(2025.10补充)
这一块非常复杂,我研究了好久,难度不亚于当年适配A卡,大家请对照着慢慢一步步更改。
这个项目最初是python3.8,pytorch1.13。而50系显卡不兼容老的CUDA架构,不想用Docker的话,就只能强行升级到python3.10,pytorch2.8,版本跨度大,因此难度较大
1,preprocess_hubert_f0.py更改
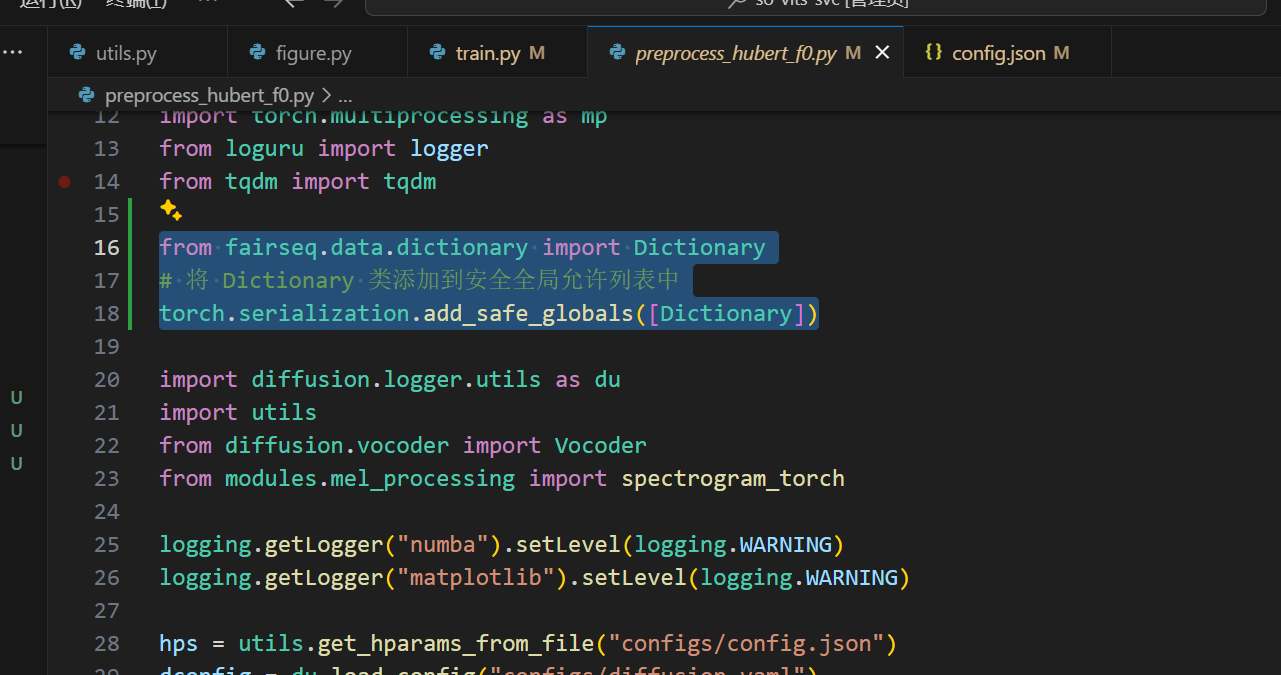
这个和webUI.py的更改是一致的,添加图示代码。具体位置不必和我严格一致,在导入torch之后,主函数之前都行
from fairseq.data.dictionary import Dictionary # 将 Dictionary 类添加到安全全局允许列表中 torch.serialization.add_safe_globals([Dictionary])
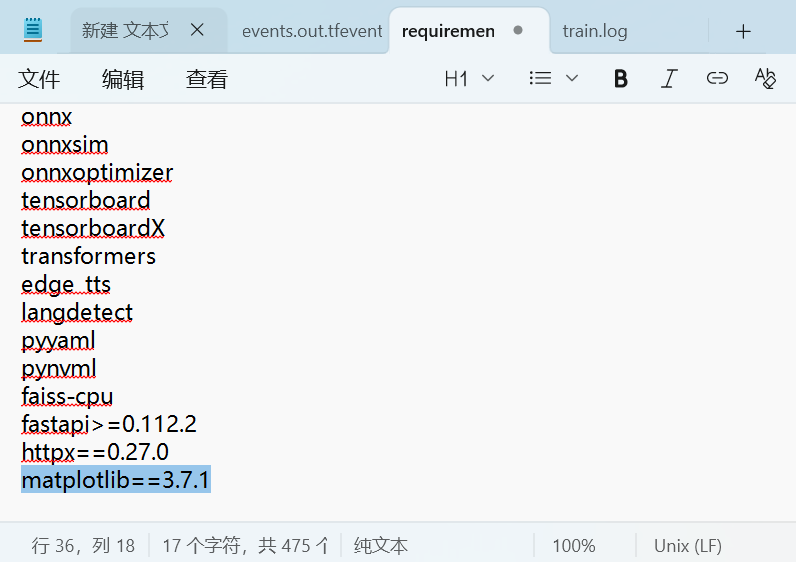
2,调整可视化库matplotlib版本
在conda环境中输入:pip install matplotlib==3.7.1
也可以之前加在requirements_win的最后一并调整,新版的matplotlib有些函数有变化,会导致每200步的那个可视化代码出错
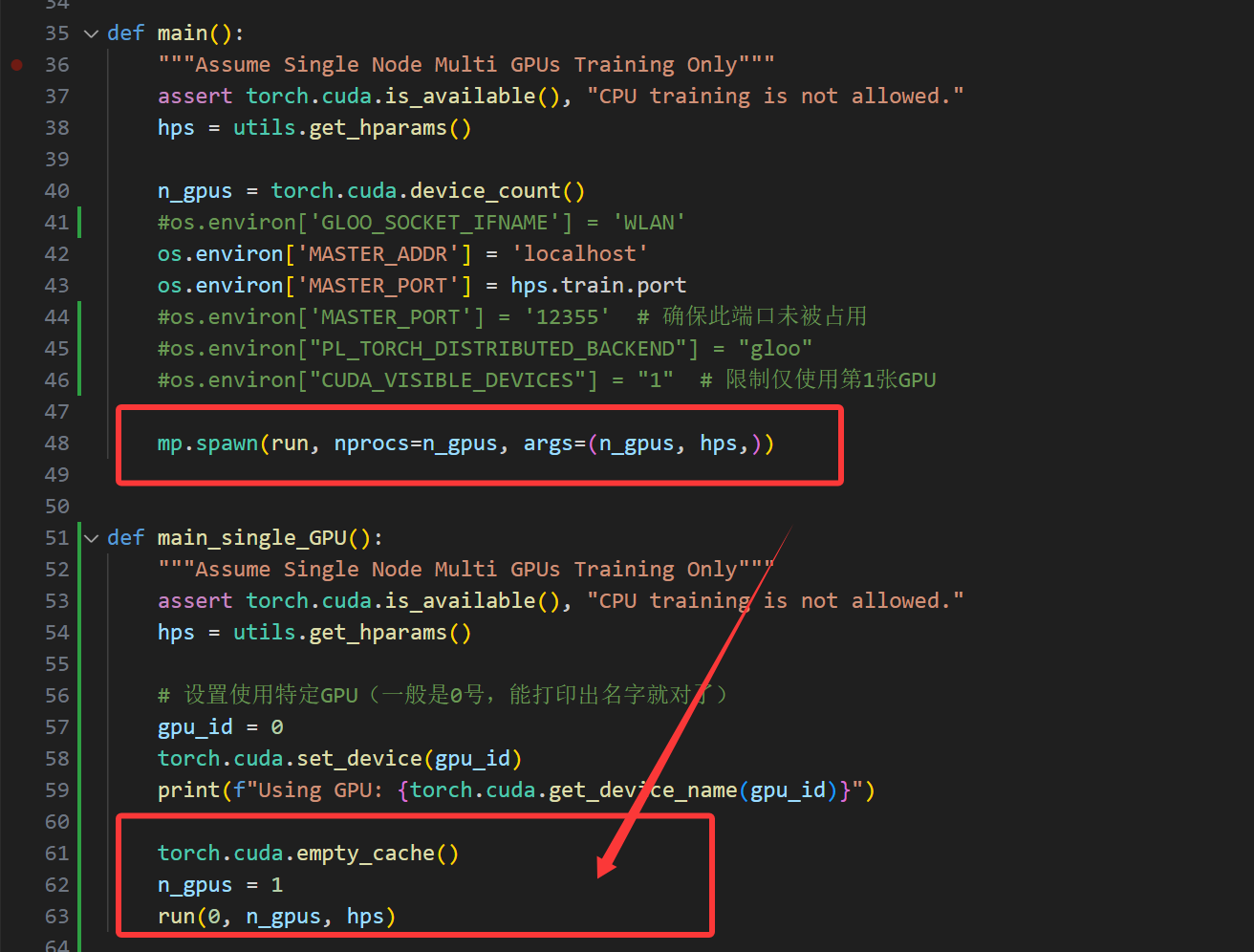
3,train.py调整
原项目的训练支持分布式,但是分布式初始化代码我并未调试成功,考虑到大部分用户应该是单卡训练,所以我移除了分布式训练的代码。
这里问题很多,train.py的完整代码将贴在最后面,不要急
往下讲之前先说两个常见问题
Q1:这里出现过奇怪的显存错误,所以我添加了一些显存控制相关的代码,但是实际并未奏效,你们删掉也可以
这个bug把deepseek都整不会了,如果大家遇到这个bug,请重启电脑!重启,不是关机再开!!!
原因分析:之前在A卡配置sovits4.0的第一期提到过快速启动的问题,Windows因为此问题,导致每次关机不彻底,产生了大量显存碎片

Q2:目前的代码可能导致:有人会启动集成显卡,但是独立显卡不启动
这个问题有2个解决方案,我不确定哪个有效。一个是刚刚自定义的main_single_GPU函数,有这段代码,你们自行更改gpu_id为0,1,2,3试一试

还有一个是我在主函数中留下的注释,这个也可以放开试试,同样这个"1"也需要自行调整0,1,2,3试试
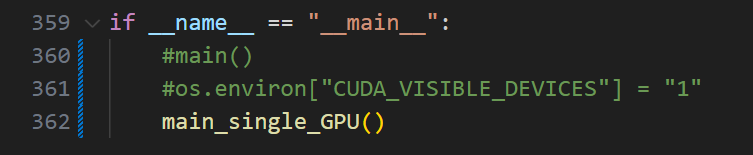
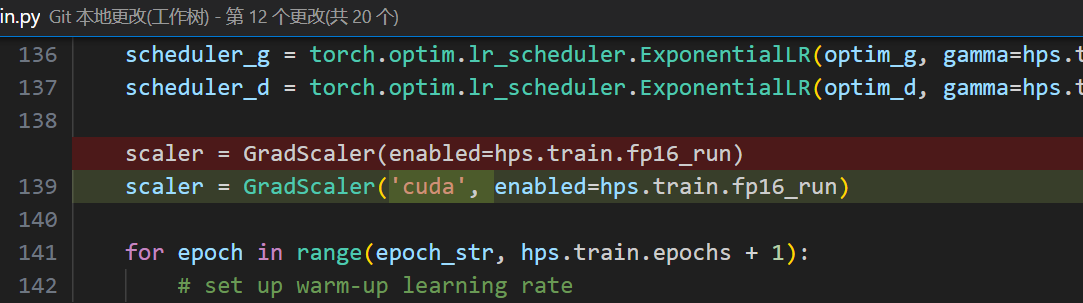
好的,问题讲完,回到正题。更改新版torch弃用的库,把这个.cuda删掉

同时给这两个函数加上一个参数'cuda'
下图的修改有若干处,请务必找到所有的的GradScaler和autocast函数,并对每一处做如图的修改。这个图仅做演示,有好几处修改哈!
移除分布式训练的初始化代码,同时这个workers必须改成0,移除分布式包装
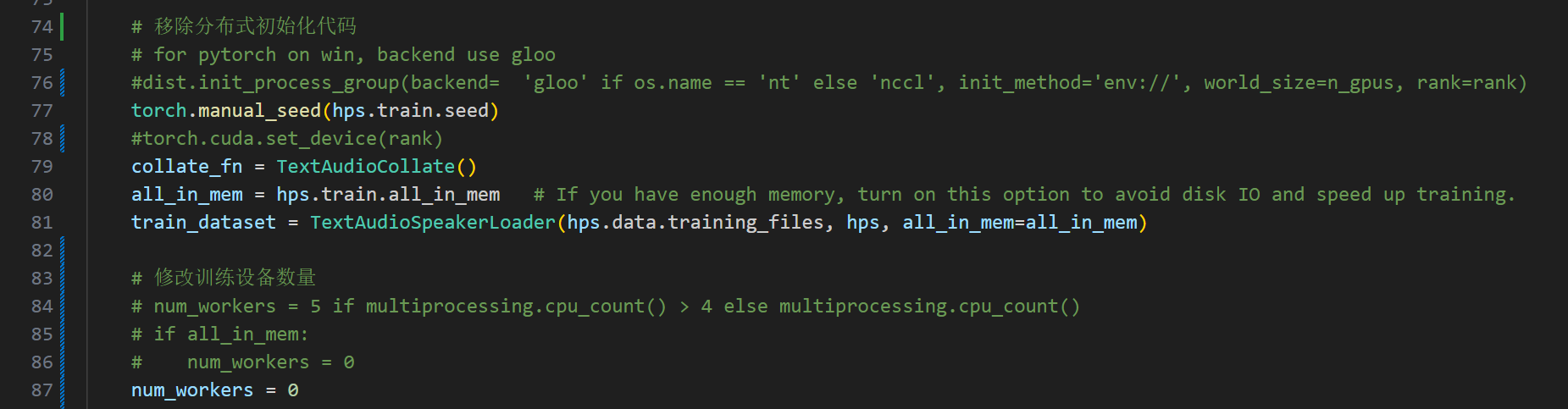

和上面的DDP包装对应,这个module是解包用的
下图修改也有好多处,请找到每一个module进行删除。这个图仅做演示,有好几处修改哈!

完整的train.py代码如下,你们可以自己一处处对着改,也可以全部复制进去。
import logging import multiprocessing import os import time os.environ['PYTORCH_CUDA_ALLOC_CONF'] = 'expandable_segments:True' import torch import torch.distributed as dist import torch.multiprocessing as mp from torch.amp import GradScaler, autocast from torch.nn import functional as F from torch.nn.parallel import DistributedDataParallel as DDP from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter import modules.commons as commons import utils from data_utils import TextAudioCollate, TextAudioSpeakerLoader from models import ( MultiPeriodDiscriminator, SynthesizerTrn, ) from modules.losses import discriminator_loss, feature_loss, generator_loss, kl_loss from modules.mel_processing import mel_spectrogram_torch, spec_to_mel_torch logging.getLogger('matplotlib').setLevel(logging.WARNING) logging.getLogger('numba').setLevel(logging.WARNING) torch.backends.cudnn.benchmark = True global_step = 0 start_time = time.time() # os.environ['TORCH_DISTRIBUTED_DEBUG'] = 'INFO' def main(): """Assume Single Node Multi GPUs Training Only""" assert torch.cuda.is_available(), "CPU training is not allowed." hps = utils.get_hparams() n_gpus = torch.cuda.device_count() #os.environ['GLOO_SOCKET_IFNAME'] = 'WLAN' os.environ['MASTER_ADDR'] = 'localhost' os.environ['MASTER_PORT'] = hps.train.port #os.environ['MASTER_PORT'] = '12355' # 确保此端口未被占用 #os.environ["PL_TORCH_DISTRIBUTED_BACKEND"] = "gloo" #os.environ["CUDA_VISIBLE_DEVICES"] = "1" # 限制仅使用第1张GPU mp.spawn(run, nprocs=n_gpus, args=(n_gpus, hps,)) def main_single_GPU(): """Assume Single Node Multi GPUs Training Only""" assert torch.cuda.is_available(), "CPU training is not allowed." hps = utils.get_hparams() # 设置使用特定GPU(一般是0号,能打印出名字就对了) gpu_id = 0 torch.cuda.set_device(gpu_id) print(f"Using GPU: {torch.cuda.get_device_name(gpu_id)}") torch.cuda.empty_cache() n_gpus = 1 run(0, n_gpus, hps) def run(rank, n_gpus, hps): global global_step if rank == 0: logger = utils.get_logger(hps.model_dir) logger.info(hps) utils.check_git_hash(hps.model_dir) writer = SummaryWriter(log_dir=hps.model_dir) writer_eval = SummaryWriter(log_dir=os.path.join(hps.model_dir, "eval")) # 移除分布式初始化代码 # for pytorch on win, backend use gloo #dist.init_process_group(backend= 'gloo' if os.name == 'nt' else 'nccl', init_method='env://', world_size=n_gpus, rank=rank) torch.manual_seed(hps.train.seed) #torch.cuda.set_device(rank) collate_fn = TextAudioCollate() all_in_mem = hps.train.all_in_mem # If you have enough memory, turn on this option to avoid disk IO and speed up training. train_dataset = TextAudioSpeakerLoader(hps.data.training_files, hps, all_in_mem=all_in_mem) # 修改训练设备数量 # num_workers = 5 if multiprocessing.cpu_count() > 4 else multiprocessing.cpu_count() # if all_in_mem: # num_workers = 0 num_workers = 0 train_loader = DataLoader(train_dataset, num_workers=num_workers, shuffle=False, pin_memory=True, batch_size=hps.train.batch_size, collate_fn=collate_fn) if rank == 0: eval_dataset = TextAudioSpeakerLoader(hps.data.validation_files, hps, all_in_mem=all_in_mem,vol_aug = False) eval_loader = DataLoader(eval_dataset, num_workers=1, shuffle=False, batch_size=1, pin_memory=False, drop_last=False, collate_fn=collate_fn) net_g = SynthesizerTrn( hps.data.filter_length // 2 + 1, hps.train.segment_size // hps.data.hop_length, **hps.model).cuda(rank) net_d = MultiPeriodDiscriminator(hps.model.use_spectral_norm).cuda(rank) optim_g = torch.optim.AdamW( net_g.parameters(), hps.train.learning_rate, betas=hps.train.betas, eps=hps.train.eps) optim_d = torch.optim.AdamW( net_d.parameters(), hps.train.learning_rate, betas=hps.train.betas, eps=hps.train.eps) # 移除DDP包装,直接使用原模型 #net_g = DDP(net_g, device_ids=[rank]) # , find_unused_parameters=True) #net_d = DDP(net_d, device_ids=[rank]) skip_optimizer = False try: _, _, _, epoch_str = utils.load_checkpoint(utils.latest_checkpoint_path(hps.model_dir, "G_*.pth"), net_g, optim_g, skip_optimizer) _, _, _, epoch_str = utils.load_checkpoint(utils.latest_checkpoint_path(hps.model_dir, "D_*.pth"), net_d, optim_d, skip_optimizer) epoch_str = max(epoch_str, 1) name=utils.latest_checkpoint_path(hps.model_dir, "D_*.pth") global_step=int(name[name.rfind("_")+1:name.rfind(".")])+1 #global_step = (epoch_str - 1) * len(train_loader) except Exception: print("load old checkpoint failed...") epoch_str = 1 global_step = 0 if skip_optimizer: epoch_str = 1 global_step = 0 warmup_epoch = hps.train.warmup_epochs scheduler_g = torch.optim.lr_scheduler.ExponentialLR(optim_g, gamma=hps.train.lr_decay, last_epoch=epoch_str - 2) scheduler_d = torch.optim.lr_scheduler.ExponentialLR(optim_d, gamma=hps.train.lr_decay, last_epoch=epoch_str - 2) scaler = GradScaler('cuda', enabled=hps.train.fp16_run) for epoch in range(epoch_str, hps.train.epochs + 1): # set up warm-up learning rate if epoch <= warmup_epoch: for param_group in optim_g.param_groups: param_group['lr'] = hps.train.learning_rate / warmup_epoch * epoch for param_group in optim_d.param_groups: param_group['lr'] = hps.train.learning_rate / warmup_epoch * epoch # training if rank == 0: train_and_evaluate(rank, epoch, hps, [net_g, net_d], [optim_g, optim_d], [scheduler_g, scheduler_d], scaler, [train_loader, eval_loader], logger, [writer, writer_eval]) else: train_and_evaluate(rank, epoch, hps, [net_g, net_d], [optim_g, optim_d], [scheduler_g, scheduler_d], scaler, [train_loader, None], None, None) # update learning rate scheduler_g.step() scheduler_d.step() def train_and_evaluate(rank, epoch, hps, nets, optims, schedulers, scaler, loaders, logger, writers): net_g, net_d = nets optim_g, optim_d = optims scheduler_g, scheduler_d = schedulers train_loader, eval_loader = loaders if writers is not None: writer, writer_eval = writers half_type = torch.bfloat16 if hps.train.half_type=="bf16" else torch.float16 # train_loader.batch_sampler.set_epoch(epoch) global global_step net_g.train() net_d.train() for batch_idx, items in enumerate(train_loader): c, f0, spec, y, spk, lengths, uv,volume = items g = spk.cuda(rank, non_blocking=True) spec, y = spec.cuda(rank, non_blocking=True), y.cuda(rank, non_blocking=True) c = c.cuda(rank, non_blocking=True) f0 = f0.cuda(rank, non_blocking=True) uv = uv.cuda(rank, non_blocking=True) lengths = lengths.cuda(rank, non_blocking=True) mel = spec_to_mel_torch( spec, hps.data.filter_length, hps.data.n_mel_channels, hps.data.sampling_rate, hps.data.mel_fmin, hps.data.mel_fmax) with autocast('cuda', enabled=hps.train.fp16_run, dtype=half_type): y_hat, ids_slice, z_mask, \ (z, z_p, m_p, logs_p, m_q, logs_q), pred_lf0, norm_lf0, lf0 = net_g(c, f0, uv, spec, g=g, c_lengths=lengths, spec_lengths=lengths,vol = volume) y_mel = commons.slice_segments(mel, ids_slice, hps.train.segment_size // hps.data.hop_length) y_hat_mel = mel_spectrogram_torch( y_hat.squeeze(1), hps.data.filter_length, hps.data.n_mel_channels, hps.data.sampling_rate, hps.data.hop_length, hps.data.win_length, hps.data.mel_fmin, hps.data.mel_fmax ) y = commons.slice_segments(y, ids_slice * hps.data.hop_length, hps.train.segment_size) # slice # Discriminator y_d_hat_r, y_d_hat_g, _, _ = net_d(y, y_hat.detach()) with autocast('cuda',dtype=half_type, enabled=hps.train.fp16_run): loss_disc, losses_disc_r, losses_disc_g = discriminator_loss(y_d_hat_r, y_d_hat_g) loss_disc_all = loss_disc optim_d.zero_grad() scaler.scale(loss_disc_all).backward() scaler.unscale_(optim_d) grad_norm_d = commons.clip_grad_value_(net_d.parameters(), None) scaler.step(optim_d) with autocast('cuda', enabled=hps.train.fp16_run, dtype=half_type): # Generator y_d_hat_r, y_d_hat_g, fmap_r, fmap_g = net_d(y, y_hat) with autocast('cuda', enabled=False, dtype=half_type): loss_mel = F.l1_loss(y_mel, y_hat_mel) * hps.train.c_mel loss_kl = kl_loss(z_p, logs_q, m_p, logs_p, z_mask) * hps.train.c_kl loss_fm = feature_loss(fmap_r, fmap_g) loss_gen, losses_gen = generator_loss(y_d_hat_g) # loss_lf0 = F.mse_loss(pred_lf0, lf0) if net_g.module.use_automatic_f0_prediction else 0 # 修改:移除DDP包装之后,需要移除.module loss_lf0 = F.mse_loss(pred_lf0, lf0) if net_g.use_automatic_f0_prediction else 0 loss_gen_all = loss_gen + loss_fm + loss_mel + loss_kl + loss_lf0 optim_g.zero_grad() scaler.scale(loss_gen_all).backward() scaler.unscale_(optim_g) grad_norm_g = commons.clip_grad_value_(net_g.parameters(), None) scaler.step(optim_g) scaler.update() if rank == 0: if global_step % hps.train.log_interval == 0: lr = optim_g.param_groups[0]['lr'] losses = [loss_disc, loss_gen, loss_fm, loss_mel, loss_kl] reference_loss=0 for i in losses: reference_loss += i logger.info('Train Epoch: {} [{:.0f}%]'.format( epoch, 100. * batch_idx / len(train_loader))) logger.info(f"Losses: {[x.item() for x in losses]}, step: {global_step}, lr: {lr}, reference_loss: {reference_loss}") scalar_dict = {"loss/g/total": loss_gen_all, "loss/d/total": loss_disc_all, "learning_rate": lr, "grad_norm_d": grad_norm_d, "grad_norm_g": grad_norm_g} scalar_dict.update({"loss/g/fm": loss_fm, "loss/g/mel": loss_mel, "loss/g/kl": loss_kl, "loss/g/lf0": loss_lf0}) # scalar_dict.update({"loss/g/{}".format(i): v for i, v in enumerate(losses_gen)}) # scalar_dict.update({"loss/d_r/{}".format(i): v for i, v in enumerate(losses_disc_r)}) # scalar_dict.update({"loss/d_g/{}".format(i): v for i, v in enumerate(losses_disc_g)}) image_dict = { "slice/mel_org": utils.plot_spectrogram_to_numpy(y_mel[0].data.cpu().numpy()), "slice/mel_gen": utils.plot_spectrogram_to_numpy(y_hat_mel[0].data.cpu().numpy()), "all/mel": utils.plot_spectrogram_to_numpy(mel[0].data.cpu().numpy()) } # if net_g.module.use_automatic_f0_prediction: # 修改:移除.module if net_g.use_automatic_f0_prediction: image_dict.update({ "all/lf0": utils.plot_data_to_numpy(lf0[0, 0, :].cpu().numpy(), pred_lf0[0, 0, :].detach().cpu().numpy()), "all/norm_lf0": utils.plot_data_to_numpy(lf0[0, 0, :].cpu().numpy(), norm_lf0[0, 0, :].detach().cpu().numpy()) }) utils.summarize( writer=writer, global_step=global_step, images=image_dict, scalars=scalar_dict ) if global_step % hps.train.eval_interval == 0: evaluate(hps, net_g, eval_loader, writer_eval) utils.save_checkpoint(net_g, optim_g, hps.train.learning_rate, epoch, os.path.join(hps.model_dir, "G_{}.pth".format(global_step))) utils.save_checkpoint(net_d, optim_d, hps.train.learning_rate, epoch, os.path.join(hps.model_dir, "D_{}.pth".format(global_step))) keep_ckpts = getattr(hps.train, 'keep_ckpts', 0) if keep_ckpts > 0: utils.clean_checkpoints(path_to_models=hps.model_dir, n_ckpts_to_keep=keep_ckpts, sort_by_time=True) global_step += 1 if rank == 0: global start_time now = time.time() durtaion = format(now - start_time, '.2f') logger.info(f'====> Epoch: {epoch}, cost {durtaion} s') start_time = now def evaluate(hps, generator, eval_loader, writer_eval): generator.eval() image_dict = {} audio_dict = {} with torch.no_grad(): for batch_idx, items in enumerate(eval_loader): c, f0, spec, y, spk, _, uv,volume = items g = spk[:1].cuda(0) spec, y = spec[:1].cuda(0), y[:1].cuda(0) c = c[:1].cuda(0) f0 = f0[:1].cuda(0) uv= uv[:1].cuda(0) if volume is not None: volume = volume[:1].cuda(0) mel = spec_to_mel_torch( spec, hps.data.filter_length, hps.data.n_mel_channels, hps.data.sampling_rate, hps.data.mel_fmin, hps.data.mel_fmax) # 修改,移除DDP包装之后,需要移除.module # y_hat,_ = generator.module.infer(c, f0, uv, g=g,vol = volume) y_hat,_ = generator.infer(c, f0, uv, g=g,vol = volume) y_hat_mel = mel_spectrogram_torch( y_hat.squeeze(1).float(), hps.data.filter_length, hps.data.n_mel_channels, hps.data.sampling_rate, hps.data.hop_length, hps.data.win_length, hps.data.mel_fmin, hps.data.mel_fmax ) audio_dict.update({ f"gen/audio_{batch_idx}": y_hat[0], f"gt/audio_{batch_idx}": y[0] }) image_dict.update({ "gen/mel": utils.plot_spectrogram_to_numpy(y_hat_mel[0].cpu().numpy()), "gt/mel": utils.plot_spectrogram_to_numpy(mel[0].cpu().numpy()) }) utils.summarize( writer=writer_eval, global_step=global_step, images=image_dict, audios=audio_dict, audio_sampling_rate=hps.data.sampling_rate ) generator.train() if __name__ == "__main__": #main() #os.environ["CUDA_VISIBLE_DEVICES"] = "1" main_single_GPU()
五、训练和推理流程
1,底模文件放置
把底模文件放在对应位置,这个可以参考github的官方介绍
2,数据集预处理
把数据集弄成10-20秒的小段,有一些超过20s没关系,但是最好别超过30s。
这里以某游戏角色的数据集为例,看到数据是几百个短小的片段。可以先大概听一遍,去调(吐字不清晰/有其他杂音)的语音 。
网上也有很多切分/合成工具可以用。如果你们的数据集和我一样,也可以使用我的代码
import os from pydub import AudioSegment from pydub.utils import mediainfo def get_audio_duration(audio): """获取音频时长(秒)""" return len(audio) / 1000.0 def merge_audio_files(input_folder, output_folder, min_segment=10, max_segment=20): """ 合并音频文件为10-20秒的片段 参数: input_folder: 输入文件夹路径 output_folder: 输出文件夹路径 min_segment: 最小片段长度(秒) max_segment: 最大片段长度(秒) """ # 确保输出文件夹存在 os.makedirs(output_folder, exist_ok=True) # 获取所有wav文件并按文件名排序 audio_files = sorted([f for f in os.listdir(input_folder) if f.lower().endswith('.wav')]) temp_audio = AudioSegment.empty() # 初始化temp音频 output_files = [] # 存储所有输出的文件路径 output_counter = 1 # 从1开始计数 for i, filename in enumerate(audio_files): filepath = os.path.join(input_folder, filename) audio = AudioSegment.from_wav(filepath) duration = get_audio_duration(audio) # 如果音频大于10秒,直接输出 if duration >= min_segment: # 如果有暂存的temp音频,先输出 if len(temp_audio) > 0 and get_audio_duration(temp_audio) > min_segment: output_path = os.path.join(output_folder, f"merged_{output_counter}.wav") temp_audio.export(output_path, format="wav") output_files.append(output_path) output_counter += 1 temp_audio = AudioSegment.empty() # 输出当前大音频 output_path = os.path.join(output_folder, f"merged_{output_counter}.wav") audio.export(output_path, format="wav") output_files.append(output_path) output_counter += 1 else: # 检查temp+当前音频是否超过20秒 combined_duration = get_audio_duration(temp_audio + audio) if combined_duration > max_segment: # 超过20秒,输出temp if len(temp_audio) > 0: output_path = os.path.join(output_folder, f"merged_{output_counter}.wav") temp_audio.export(output_path, format="wav") output_files.append(output_path) output_counter += 1 temp_audio = audio # 重置temp为当前音频 else: # 不超过20秒,合并到temp temp_audio += audio # 处理最后一个temp音频 if len(temp_audio) > 0: last_duration = get_audio_duration(temp_audio) # 如果最后一个temp不足10秒,找到最短的输出文件并追加 if last_duration < min_segment and len(output_files) > 0: # 找到最短的输出文件 shortest_file = min(output_files, key=lambda x: get_audio_duration(AudioSegment.from_wav(x))) shortest_audio = AudioSegment.from_wav(shortest_file) # 合并到最短文件 combined_audio = shortest_audio + temp_audio combined_audio.export(shortest_file, format="wav") else: # 否则正常输出最后一个temp output_path = os.path.join(output_folder, f"merged_{output_counter}.wav") temp_audio.export(output_path, format="wav") output_files.append(output_path) print(f"处理完成,共生成{len(output_files)}个合并文件") # 使用示例 if __name__ == "__main__": input_folder = "********" # 替换为你的输入文件夹路径 output_folder = "********" # 替换为你的输出文件夹路径 merge_audio_files(input_folder, output_folder)
把生成的数据放在一个文件夹里面(文件夹名不能有中文字符),放在如下路径
接下来依次执行以下命令:
python resample.py
python preprocess_flist_config.py --speech_encoder vec768l12
python preprocess_hubert_f0.py --f0_predictor dio(默认dio,可选crepe,dio,pm,harvest)
如果使用浅层扩散:python preprocess_hubert_f0.py --f0_predictor dio --use_diff
3,模型训练
主模型训练:python train.py -c configs/config.json -m 44k
浅层扩散模型训练:python train_diff.py -c configs/diffusion.yaml
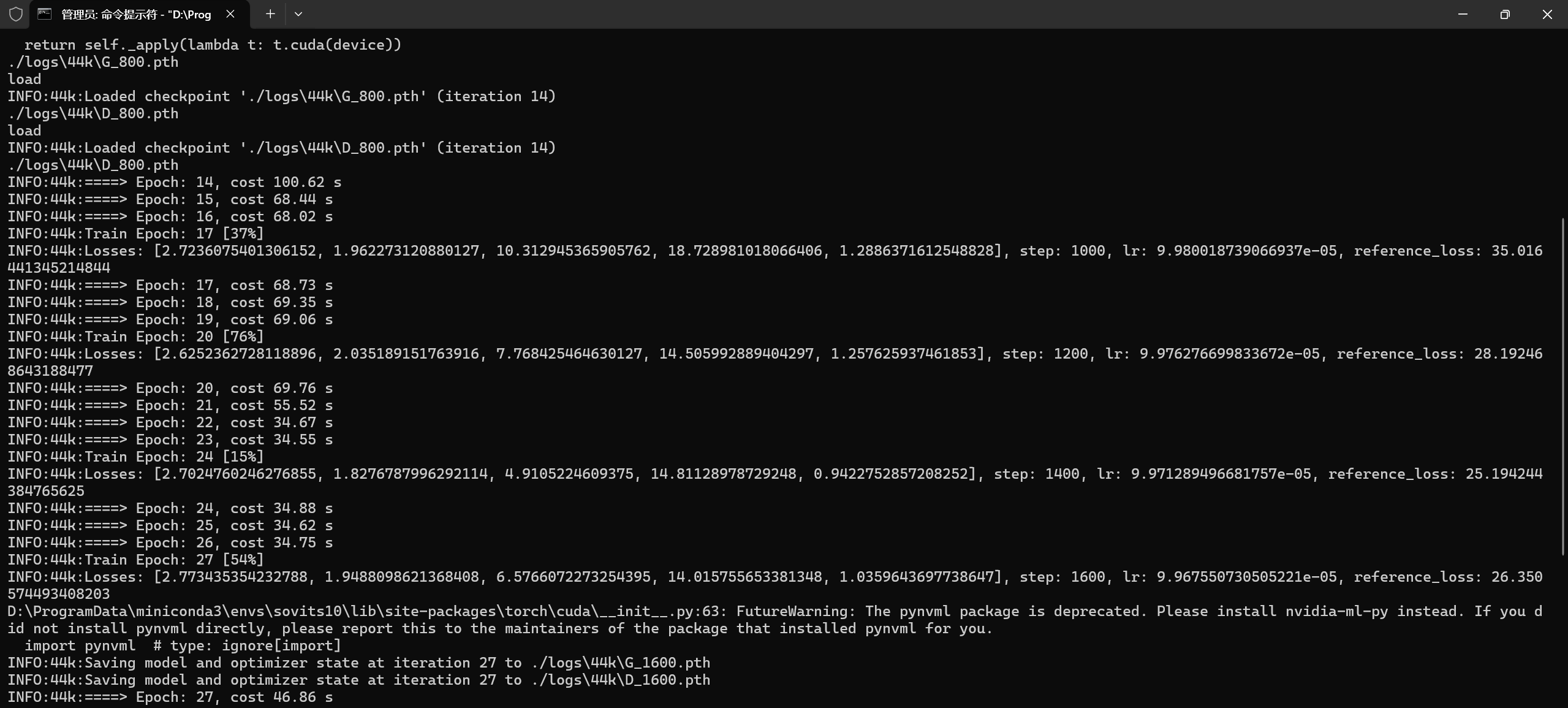
如下图所示就是正常训练的情况了,大概8-15分钟可以生成一个checkpoint(如果一边看视频一边训练会慢一点),可以看出5060比4060的性能提升还是可以的。
我这里是87min的训练数据,时长不同会导致epoch时间不同,epoch时间无参考价值。
(注:5060 8G显存可能带不动batch12,建议配置文件保持默认的batch6,lr0.0001)
4,歌曲推理
启动webUI代码:python webUI.py
把训练好的G_xxxx.pth和config放到对应位置,然后点击加载模型
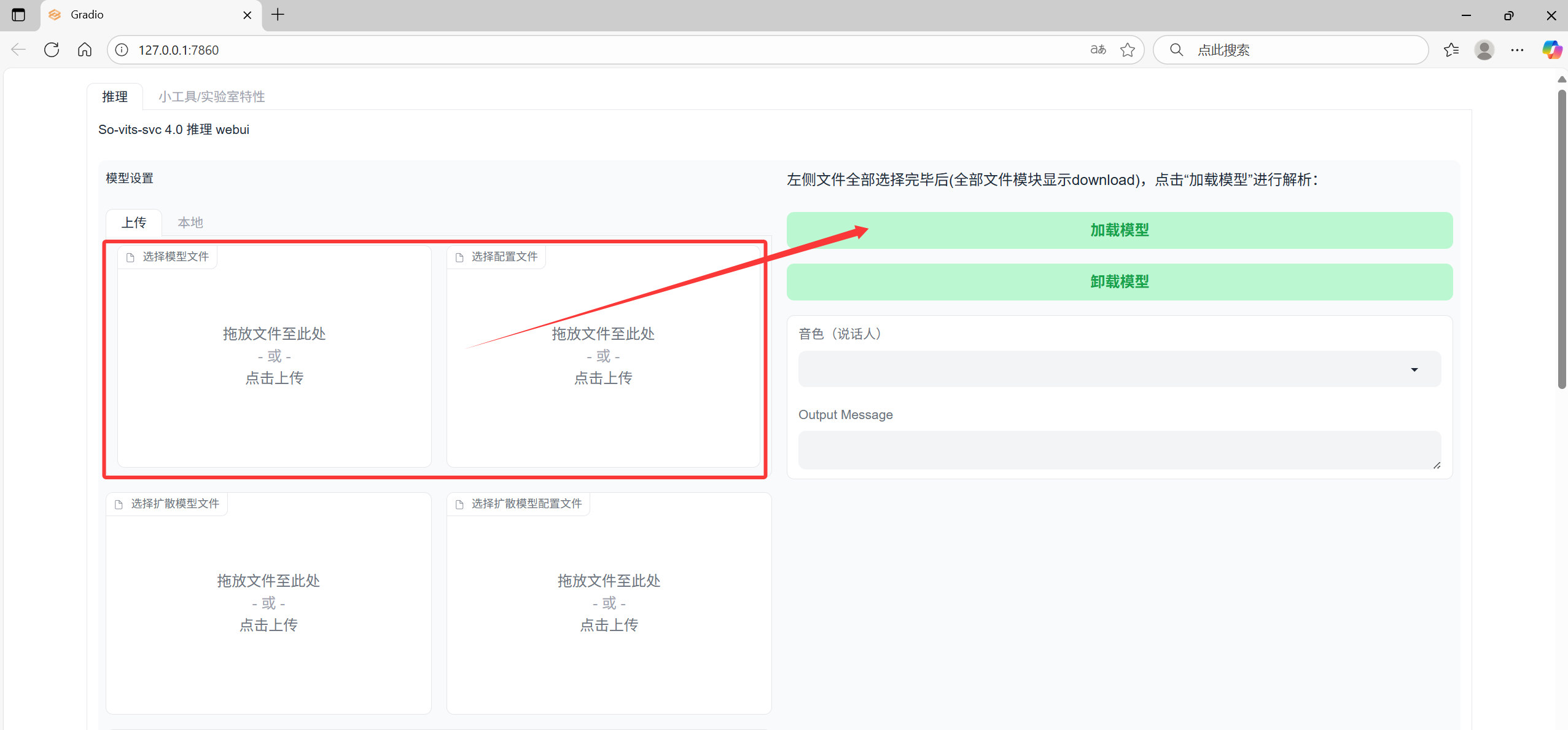
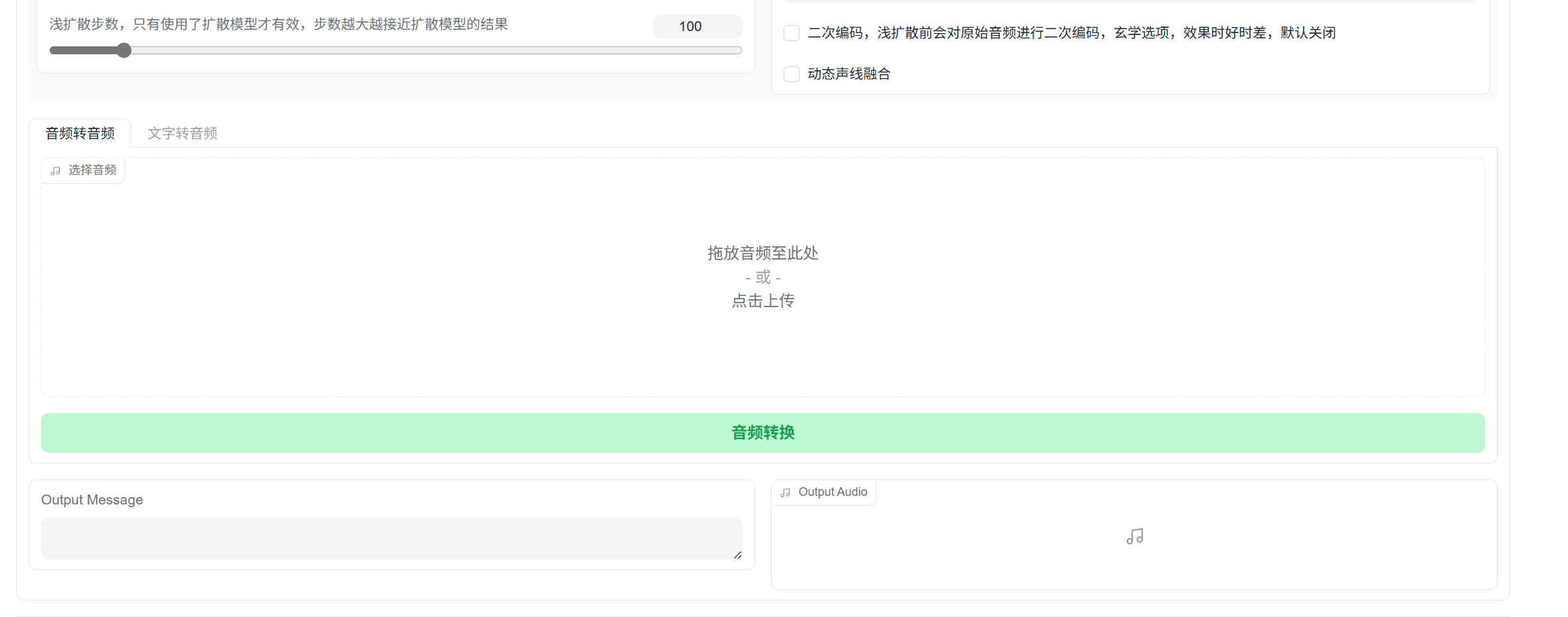
把歌曲用UVR5提取人声,然后用AU切成60s以内的小段(80s也可以,但是不切会爆显存) ,依次放入下面推理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号