
NIO类库
NIO概述
从JDK1.4开始,引入了新的I/O类库,它们位于java.nio包中,其目的在于提高I/O的操作效率。nio是new io的缩写。
参考文章:NIO BIO AIO区别
java.nio包引入了四个关键的数据类型:
- Buffer:缓冲区,临时存放输入或输出数据。
- Charset:把具有Unicode字符串编码转换为其他字符编码,以及把其他字符编码转换为Unicode编码的功能。
- Channel:数据传输管道。能够把Buffer中的数据写到数据汇,或者把数据源的数据读到Buffer。NIO基于Channel和Buffer操作,数据总是从信道读取数据到缓冲区中,或者从缓冲区写入到信道中。
- Selector:支持异步I/O操作,也称为非阻塞I/O操作。Selector用于监听多个信道事件(比如链接打开,数据到达等)使得单线程可以监听多个数据的信道
缓冲器Buffer概述
数据输入和输出往往是比较耗时的操作。缓冲区从两个方面提高I/O的操作效率
- 减少实际的物理读写次数
- 缓冲区在创建时被分配内存,这块内存一直被重用,这可以减少动态分配和回收内存区域的次数
旧IO类库中的BufferInputStream BufferOutStream BufferReader BufferWriter在实现中都运用了缓冲区。新I/O包公开了Buffer API,使得程序可以直接控制和运用缓冲区
所有缓冲区都有以下属性。
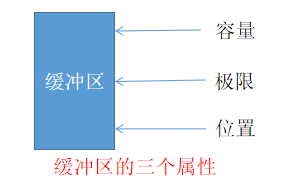
- 容量:表示缓冲区可以保存多少数据。
- 极限:表示缓冲区的当前终点,不能对缓冲区中超过极限的数据进行读写操作。极限值是可以修改的,这有利于缓冲区的重用。
列如 假定容量为100的缓冲区已经填满了数据,接着程序在重用缓冲区时,仅仅将十个新的数据写入缓冲区,这样时可以将极限值设置为10,这样就不能访问先前的数据。
极限值是一个非负整数值,不应该大于容量值。
- 位置:表示缓冲区下一个读写单元的位置,每次读写缓冲区的数据时,都会改变该值,为下一次读写数据做准备。位置是一个非负整数值,不应该大于容量值。
以上三个属性的关系为 容量≥极限 ≥位置 ≥0
缓冲区提供了用于改变以上三个属性的方法。
-
clear()使缓冲区为一系列新的通道读取或相对放置 操作做好准备:它将极限设置为容量大小,将位置设置为 0。 -
flip()使缓冲区为一系列新的通道写入或相对获取 操作做好准备:它将极限设置为当前位置,然后将位置设置为 0。 -
rewind()使缓冲区为重新读取已包含的数据做好准备:它使极限保持不变,将位置设置为 0。
Channel概述
通过Channel用来连接缓冲区与数据源或数据汇。数据源的数据经过通道到达缓冲区,缓冲区的数据经过通道到达数据汇。
中文意思“通道”,表示IO源与目标打开的连接,类似于传统的“流”(通道与流的不同之处在于通道是双向的)。但是Channel不能直接访问数据,
Channel最重要的两个接口ReadableByteChannel和WritableByteChannel。ReadableByteChannel声明了read(ByteBuffer dst)方法,该方法把数据源的数据读入到指定的ByteBuffer缓冲区中。
FileChannel是Channel接口的实现类,代表与一个文件相连的通道FileChannel类没有提供公开的构造方法,因此客户程序不能用new语句来构造它的实例。
不过,在FileInputStream FileOutputStream类中提供了getChannel()方法,该方法返回相应的FileChannel对象。
字符编码Charset概述
Charset类的每个实例代表指定的字符编码类型,提供了以下用于编码转换的方法。(把Charset对象表示的字符编码简称为当前字符编码)
- public final ByteBuffer encode(String str)
把参数str指定的字符串转换为当前字符的编码,把转换后的当前字符编码存放在一个ByteBuffer对象中,并将其返回。
- public final ByteBuffer encode(CharBuffer cb)
把参数cb指定的字符缓冲区中的字符转换为当前字符的编码,把转换后的当前字符编码存放在一个ByteBuffer对象中,并将其返回。原先参数cb缓冲区内的字符使用Unicode编码。
- public final CharBuffer decode(ByteBuffer bb)
把参数指定的ByteBuffer中的当前字符编码转换为Unicode编码,把转换后的Unicode编码存放在一个CharBuffer对象中,将其返回。
Selector
1)多路复用器(Selector),他是NIO编程的基础,非常重要。多路复用器提供选择已经就绪的任务的能力。
2)简单说,就是Selector会不断地轮询注册在其上的通道(Channel),如果某个通道发生了读写操作,这个通道就处于就绪状态,会被Selector轮询出来,然后通过SelectionKey可以取得就绪的Channel集合,从而进行后续的IO操作。
3)一个多路复用器(Selector)可以负责成千上万Channel通道,没有上限,这也是JDK使用了epoll代替了传统的select实现,获得连接句柄没有限制。这也就意味着我们只要一个线程负责Selector的轮询,就可以接入成千上万个客户端,这是JDK NIO库的巨大进步。
4)Selector线程就类似一个管理者(Master),管理了成千上万个管道,然后轮询那个管道的数据已经准备好,通知cpu执行IO的读取或写入操作。
5)Selector模式:当IO事件(管道)注册到选择器以后,selector会分配给每个管道一个key值,相当于标签。selector选择器是以轮询的方式进行查找注册的所有IO事件(管道),当我们的IO事件(管道)准备就绪后,select就会识别,会通过key值来找到相应的管道,进行相关的数据处理操作(从管道里读或写数据,写到我们的数据缓冲区中)。
利用FileChannel读写文件
public class FileChannelTester { public static void main(String[] args) throws Exception { final int size = 1024; final String path = "D:\\test.txt"; //向文件中写数据 FileChannel fc = new FileOutputStream(path).getChannel(); fc.write(ByteBuffer.wrap("你好,".getBytes())); fc.close(); //向文件末尾添加数据 fc= new RandomAccessFile(path,"rw").getChannel(); fc.position(fc.size()); fc.write(ByteBuffer.wrap("朋友!".getBytes())); fc.close(); //读数据 fc = new FileInputStream(path).getChannel(); ByteBuffer buff = ByteBuffer.allocate(size); fc.read(buff); buff.flip(); Charset cs = Charset.defaultCharset(); System.out.println(cs.decode(buff)); fc.close(); } }
- 在上面main()方法中,先从文件输出流中得到一个FileChannel对象,然后通过它把ByteBuffer对象中的数据写到文件中。
"你好,".getBytes()使用平台的默认字符集将此 String 编码为 byte 序列,并将结果存储到一个新的 byte 数组中。ByteBuffer类的wrap(byte[])把一个字节数组包装成一个ByteBuffer对象。
- main()方法接着从RandomAccessFile对象中得到一个FileChannel对象,定位到文件末尾,然后向文件中写入字符串"朋友!",该字符串仍然采用本地平台的字符编码。
- main()方法接着从文件输入了中得到一个FileChannel对象,然后调用ByteBuffer.allocate()方法创建了一个ByteBuffer对象 容量为1024个字节。
fc.read(buff)方法把文件中的数据读入到ByteBuffer中。接下来buff.flip()方法把缓冲区的极限limit设置为当前位置,
在把position设为0,这使得接下来的cs.decode(buff)方法仅仅操作刚刚写入缓冲区的数据。cs.decode()方法把缓冲区的数据转换为Unicode编码,然后打印该编码所代表的字符串。以上程序打印结果为"你好,朋友!"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号