

linux 安装hdoop、hfds 以及java对hdfs文件操作踩坑
引用:Java操作HDFS - 玄同太子 - 博客园 (cnblogs.com) CentOS安装Hadoop - 玄同太子 - 博客园 (cnblogs.com) HDFS完全分布式搭建过程_背着梦的幸存者-CSDN博客_hdfs搭建
一
CentOS安装Hadoop(伪分布式)
Hadoop的核心由3个部分组成:
HDFS: Hadoop Distributed File System,分布式文件系统,hdfs还可以再细分为NameNode、SecondaryNameNode、DataNode。
YARN: Yet Another Resource Negotiator,资源管理调度系统
Mapreduce:分布式运算框架
1、软件与环境
环境:CentOS-7-x86_64-Minimal-1810
hadoop版本:jdk-8u221-linux-x64.tar.gz,下载地址:https://www.apache.org/dist/hadoop/common/ Index of /hadoop (apache.org)
jdk版本:jdk-8u221-linux-x64.tar.gz,hadoop只支持jdk7和jdk8,不支持jdk11
2、解压安装文件
通过ftp等工具讲安装包上传到服务器上,并解压到/usr/local/目录
cd /usr/local/ tar -zxvf /var/ftp/pub/jdk-8u221-linux-x64.tar.gz tar -zxvf /var/ftp/pub/hadoop-2.9.2.tar.gz
3、配置JDK
修改${HADOOP_HMOE}/etc/hadoop/hadoop-env.sh文件,修改JAVA_HOME配置(也可以修改/etc/profile文件,增加JAVA_HOME配置)。
vi etc/hadoop/hadoop-env.sh // 修改为 export JAVA_HOME=/usr/local/jdk1.8.0_221/
4、设置伪分布模式(Pseudo-Distributed Operation)
修改etc/hadoop/core-site.xml文件,增加配置(fs.defaultFS:默认文件系统名称):
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
//不要端口冲突,9000是一个常用端口,建议 netstat -tnpl 查看端口占用,此外localhost要改为主机对外ip,不然外网可能无法访问端口
</property>
</configuration>
修改etc/hadoop/hdfs-site.xml文件,增加配置(dfs.replication:文件副本数):
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
//不配置的话可能50070访问不了
<property>
<name>dfs.namenode.http.address</name>
<value>slave1:50070</value>
</property>
</configuration>
5、设置主机允许无密码SSH链接
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa // 创建公钥私钥对 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys // chmod 0600 ~/.ssh/authorized_keys // 设置权限,owner有读写权限,group和other无权限
6、格式化文件系统
bin/hdfs namenode -format
7、启动NameNode和DataNode进程(启动hdfs)
./sbin/start-dfs.sh // 启动NameNode和DataNode进程 ./sbin/stop-dfs.sh // 关闭NameNode和DataNode进程
输入地址:http://192.168.114.135:50070,可查看HDFS

8、 启动YARN
./sbin/start-yarn.sh ./sbin/stop-yarn.sh
输入地址:http://192.168.114.135:8088/,可查看YARN
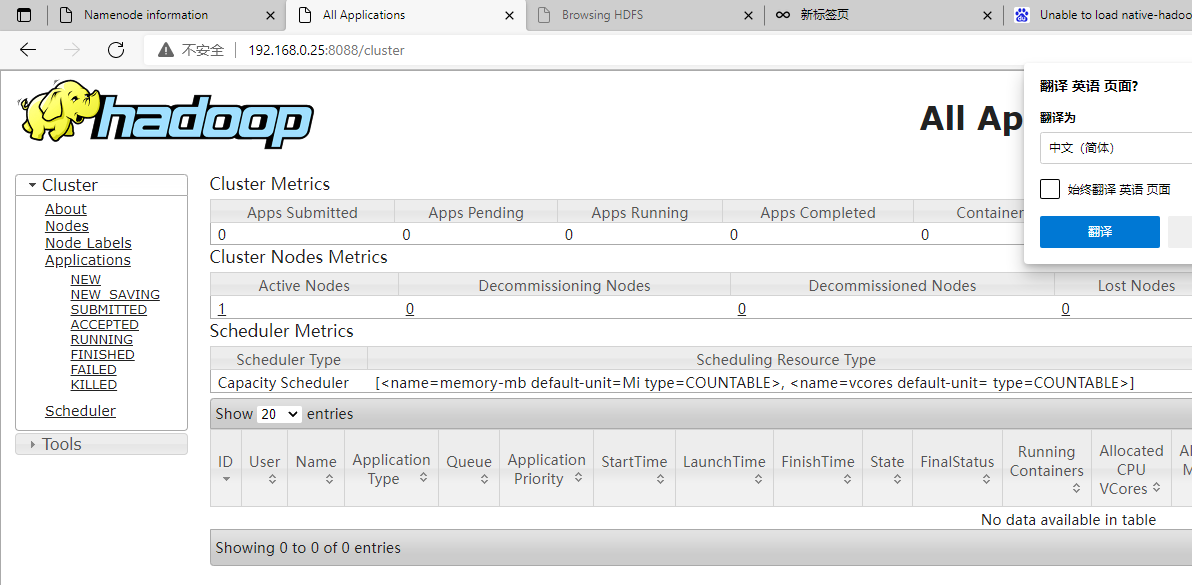
输入地址:http://192.168.0.25:50070/explorer.html,可查看hfds

二
HDFS完全分布式搭建
因为条件限制,HDFS安装在多个安装在同一系统内的centos7虚拟机上,为了方便(只是搭建用于测试一个api),并没有改为静态ip。
1 前期准备
四个安装在同一机子上的虚拟机,互相可以ping通,我的IP地址依次是192.168.31.128 192.168.31.129 192.168.31.130 192.168.31.131
修改每一台机器的host,并安装jdk,hdoop(hdfs,暂时不启动),这里可以先在一台虚拟机上进行所有步骤,然后clone三个。
(1)关闭防火墙,修改host
vim /etc/hosts
在后面添加
192.168.31.128 node1 192.168.31.129 node2 192.168.31.130 node3 192.168.31.131 node4
(2) 安装jdk,并配置
(3) 解压hadoop压缩包,并配置hdoop的path
我依旧吧jdk放在了 /usr/local/java 里,把hdoop解压在了 /usr/local/hadoop-2.10.1 里,
然后修改 /etc/profile /root/.bashrc
在尾部插入下面的代码并source
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.5
export JAVA_HOME=/opt/java/jdk1.8.0_151
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
2 时间同步
在每一台机器上输入
①各个节点安装ntp命令 yum install ntp
②上网查找最新的时间服务器,这里使用阿里云时间服务器 ntp1.aliyun.com(本步无需输入命令)
③同步时间 ntpdate ntp1.aliyun.com
3 配置免密登录
node01->node01 node01->node02 node01->node03 node01->node04
①所有节点均要执行 ssh-keygen -t rsa -P ‘’ -f ~/.ssh/id_rsa
②以下命令只在node01节点执行,将node01的公钥加入到其他节点的白名单中
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node01
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node02
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node03
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node04
4 修改hdfs-site.xml配置文件(4、5、6、7步均在node01上操作)注意是在hdoop解压的文件夹内的etc/hdoop 里
vim /usr/local/hadoop-2.10.1/etc/hdoop/hdfs-site.xml 插在两个<configuration>中间
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node02:50090</value>
</property>
5 修改core-site.xml配置文件
与上面的配置文件在同一目录 vim /usr/local/hadoop-2.10.1/etc/hdoop/core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/abc/hadoop/cluster</value>
</property>
6 修改slaves配置文件
在同一目录 ,修改,添加节点
vim /usr/local/hadoop-2.10.1/etc/hdoop/slaves
node02
node03
node04
7 将修改好的文件分发到其他节点所在虚拟机里
此处,只需要分发 /usr/local/hadoop-2.10.1/etc/hdoop 文件夹即可,终端路径是/usr/local/hadoop-2.10.1/etc时
scp -r hadoop root@node02:/usr/local/hadoop-2.10.1/etc
scp -r hadoop root@node03:/usr/local/hadoop-2.10.1/etc
scp -r hadoop root@node04:/usr/local/hadoop-2.10.1/etc
可以查看一下其他虚拟机,达到同步即可,这一步可能要输入密码秘钥
8 在node01里启动hdfs
(1)将所有的HDFS相关的进程关闭
killall java
(2) 格式化NameNode(创建目录以及文件)在node01节点执行()
bin/hdfs namenode -format
(3)启动NameNode和DataNode进程(启动hdfs)
./sbin/start-dfs.sh // 启动NameNode和DataNode进程 ./sbin/stop-dfs.sh // 关闭NameNode和DataNode进程
访问 192.168.31.128:50070/dfshealth.html#tab-overview

三
Java操作HDFS
◆下载winutils.exe和hadoop.dll
在windows平台下操作hadoop必须使用winutils.exe和hadoop.dll,下载地址:https://github.com/steveloughran/winutils,本文测试使用的是hadoop-2.8.3,虽然这个版本与服务器安装的版本不一致 ,但经测试是有效的。
配置环境变量:
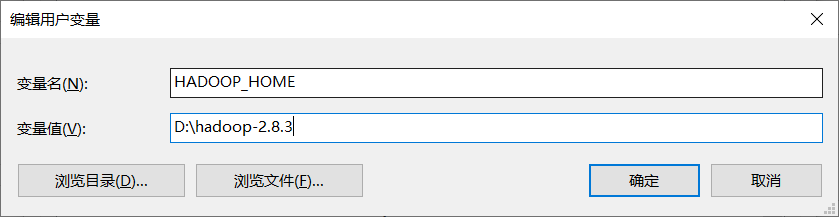
或者在Java代码中设置:
System.setProperty("hadoop.home.dir", "D:\\hadoop-2.8.3");
◆修改core-site.xml配置
设置fs.defaultFS参数值为hdfs://主机IP:9000
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.107.141:9000</value>
</property>
◆pom.xml,尽量让hadoop-client版本与安装的hadoop版本一致

<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.zhi.test</groupId>
<artifactId>hadoop-test</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>hadoop-test</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.version>2.9.2</hadoop.version>
<!-- Logger -->
<lg4j2.version>2.12.1</lg4j2.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- Logger(log4j2) -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${lg4j2.version}</version>
</dependency>
<!-- Log4j 1.x API Bridge -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-1.2-api</artifactId>
<version>${lg4j2.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
</project>
◆Java代码
package com.zhi.test.hadoop;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
/**
* HDFS测试
*
* @author zhi
* @since 2019年9月10日18:28:24
*
*/
public class HadoopTest {
private Logger logger = LogManager.getLogger(this.getClass());
private FileSystem fileSystem = null;
@Before
public void before() throws Exception {
// System.setProperty("hadoop.home.dir", "D:\\hadoop-2.8.3");
Configuration configuration = new Configuration();
fileSystem = FileSystem.get(new URI("hdfs://192.168.107.141:9000"), configuration, "root");
}
@After
public void after() throws Exception {
if (fileSystem != null) {
fileSystem.close();
}
}
/**
* 创建文件夹
*/
@Test
public void mkdir() {
try {
boolean result = fileSystem.mkdirs(new Path("/test"));
logger.info("创建文件夹结果:{}", result);
} catch (IllegalArgumentException | IOException e) {
logger.error("创建文件夹出错", e);
}
}
/**
* 上传文件
*/
@Test
public void uploadFile() {
String fileName = "hadoop.txt";
InputStream input = null;
OutputStream output = null;
try {
input = new FileInputStream("F:\\" + fileName);
output = fileSystem.create(new Path("/test/" + fileName));
IOUtils.copyBytes(input, output, 4096, true);
logger.error("上传文件成功");
} catch (IllegalArgumentException | IOException e) {
logger.error("上传文件出错", e);
} finally {
if (input != null) {
try {
input.close();
} catch (IOException e) {
}
}
if (output != null) {
try {
output.close();
} catch (IOException e) {
}
}
}
}
/**
* 下载文件
*/
@Test
public void downFile() {
String fileName = "hadoop.txt";
InputStream input = null;
OutputStream output = null;
try {
input = fileSystem.open(new Path("/test/" + fileName));
output = new FileOutputStream("F:\\down\\" + fileName);
IOUtils.copyBytes(input, output, 4096, true);
logger.error("下载文件成功");
} catch (IllegalArgumentException | IOException e) {
logger.error("下载文件出错", e);
} finally {
if (input != null) {
try {
input.close();
} catch (IOException e) {
}
}
if (output != null) {
try {
output.close();
} catch (IOException e) {
}
}
}
}
/**
* 删除文件
*/
@Test
public void deleteFile() {
String fileName = "hadoop.txt";
try {
boolean result = fileSystem.delete(new Path("/test/" + fileName), true);
logger.info("删除文件结果:{}", result);
} catch (IllegalArgumentException | IOException e) {
logger.error("删除文件出错", e);
}
}
/**
* 遍历文件
*/
@Test
public void listFiles() {
try {
FileStatus[] statuses = fileSystem.listStatus(new Path("/"));
for (FileStatus file : statuses) {
logger.info("扫描到文件或目录,名称:{},是否为文件:{}", file.getPath().getName(), file.isFile());
}
} catch (IllegalArgumentException | IOException e) {
logger.error("遍历文件出错", e);
}
}
}
访问http://192.168.107.141:50070/explorer.html#,可查看上传的文件:
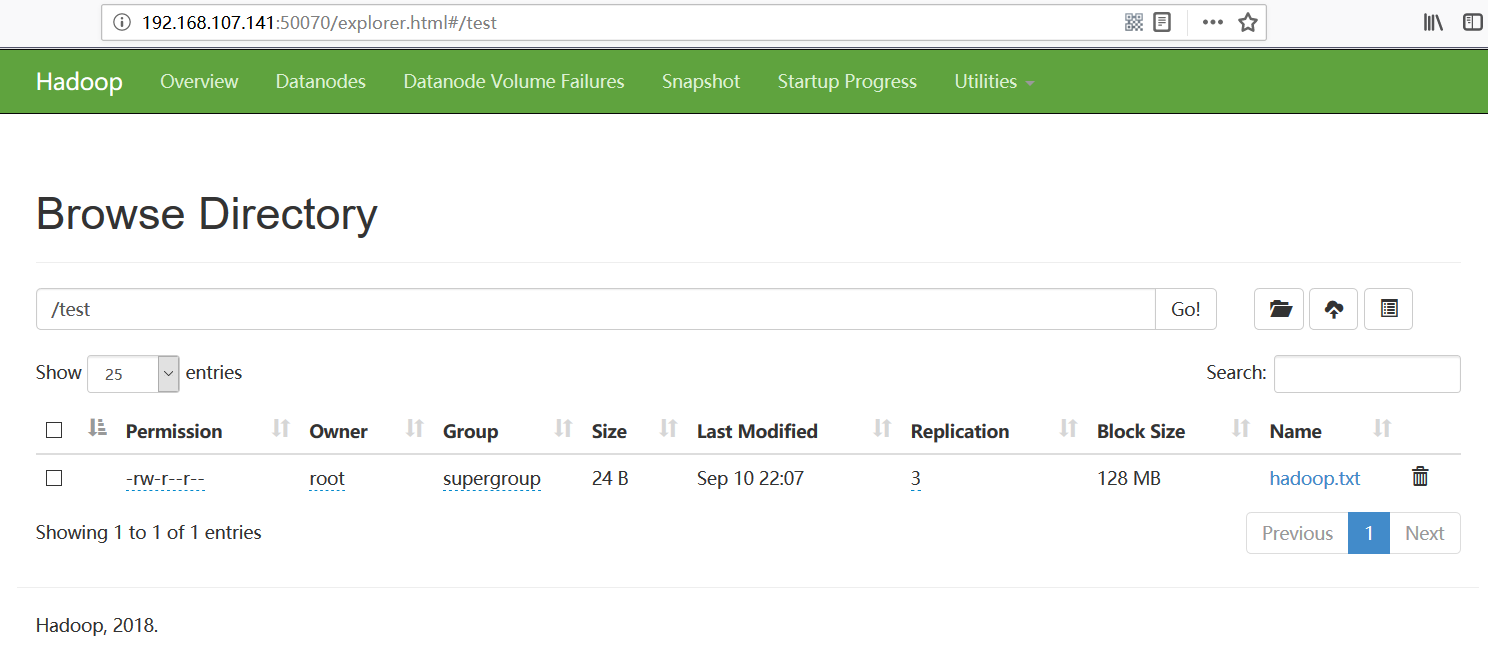
end

 浙公网安备 33010602011771号
浙公网安备 33010602011771号