

DRL模型训练:原始奖励函数记录以及绘制
一些参考图片:
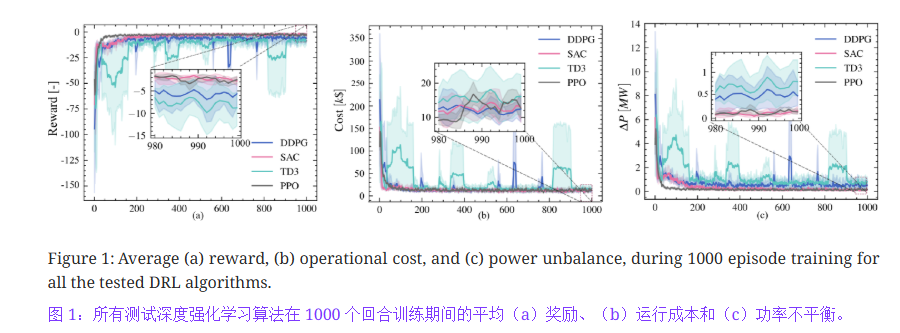
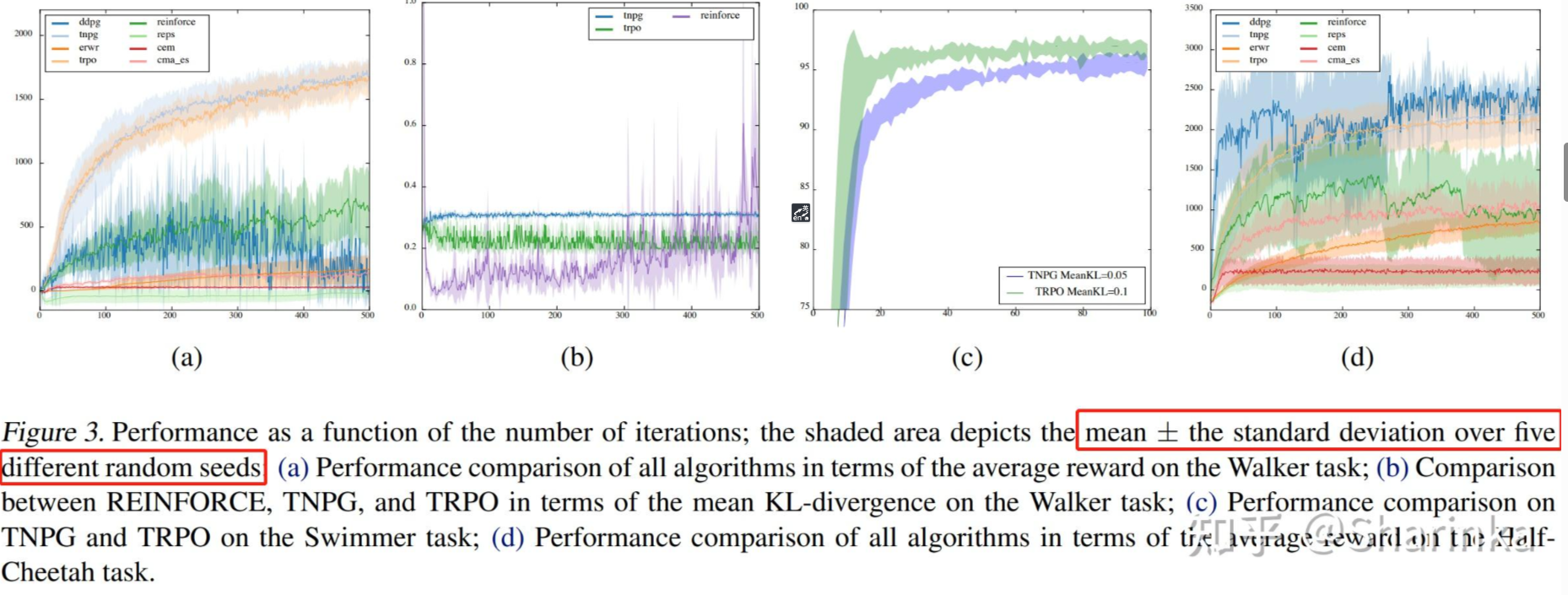

1. 使用sb3库,
调用callback,会记录每个episode结束时的reward;
使用tensorboard记录的rollout/ep_rew_mean,会自动每4个ep平均,并进行平滑,得到的不是原始数据。
from stable_baselines3.common.callbacks import BaseCallback
import os
import numpy as np
class RewardLoggingCallback(BaseCallback):
def __init__(self, save_path, verbose=0):
super().__init__(verbose)
self.save_path = save_path
self.episode_rewards = []
def _on_step(self) -> bool:
# SB3 会在 episode 结束时把 episode info 放在 infos 中
if len(self.locals.get("infos", [])) > 0:
for info in self.locals["infos"]:
if "episode" in info.keys():
self.episode_rewards.append(info["episode"]["r"])
return True
def _on_training_end(self) -> None:
os.makedirs(os.path.dirname(self.save_path), exist_ok=True)
np.save(self.save_path, np.array(self.episode_rewards))
if self.verbose > 0:
print(f"Saved episodic rewards to {self.save_path}")
2.调用seaborn库
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# 假设你通过 callback 保存的数据是多个实验 run 的结果
# 例如保存成: run1_rewards.npy, run2_rewards.npy, ...
files = [
'run1_rewards.npy',
]
# 定义滑动平均函数
def moving_average(x, window=50):
return np.convolve(x, np.ones(window)/window, mode="valid")
# 收集所有数据
data = []
for run_id, f in enumerate(files):
rewards = np.load(f)
smoothed = moving_average(rewards, window=20)
for i, r in enumerate(smoothed):
data.append({"timestep": i, "reward": r, "run": run_id})
df = pd.DataFrame(data)
# seaborn 绘制:均值曲线 + 阴影表示方差区间
plt.figure(figsize=(8, 5))
sns.lineplot(
data=df,
x="timestep",
y="reward",
hue=None,
estimator="mean",
errorbar="sd" # 可选 "ci" 表示置信区间,"sd" 表示标准差
)
plt.title("Episode Reward (Smoothed, Multiple Runs)")
plt.xlabel("Episode")
plt.ylabel("Reward")
plt.tight_layout()
plt.show()
参考
https://zhuanlan.zhihu.com/p/635706668
https://www.deeprlhub.com/d/114
https://zhuanlan.zhihu.com/p/75477750
https://arxiv.org/abs/2208.00728

 浙公网安备 33010602011771号
浙公网安备 33010602011771号