Logstash : 从 SQL Server 读取数据
有些既存的项目把一部分日志信息写入到数据库中了,或者是由于其它的原因我们希望把关系型数据库中的信息读取到 elasticsearch 中。这种情况可以使用 logstash 的 jdbc input 插件从关系型数据库中读取日志数据,然后输出到 elasticsearch 中。本文介绍如何在 windows 系统中配置 logstash 从 SQL Server 数据库中读取数据。
说明:演示的环境为 windows server 2016,logstash 的版本为 6.2.4。
关键步骤
本文将按照下面的顺序介绍使用 logstash 从 SQL Server 数据库导出数据的关键步骤:
- 安装 Java Development Kit(JDK)
- 安装 Logstash
- 安装 SQL Server 的 JDBC 驱动
- 配置 Logstash
- 集成域认证
- 持续读取数据
- 把时间戳设置为记录产生的时间
安装 Java Development Kit(JDK)
运行 logstash 6.2.4 需要先在环境中安装 JDK,请不要安装最新版本的 JDK,最好是安装 JDK8,演示中笔者安装的版本为 jdk-8u111-windows-x64,直接安装到默认的目录中。
在 logstash 的运行脚本中用到了 JAVA_HOME 环境变量,因此我们需要先添加这个环境变量(注意,环境变量的值为 JDK 的实际安装目录):
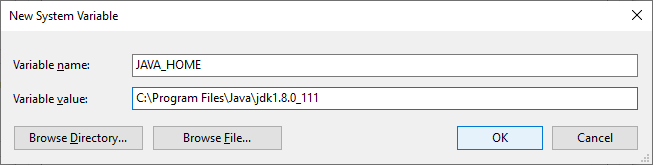
环境变量添加完成后,新启动一个 PowerShell 窗口,执行下面的命令:
> echo $env:JAVA_HOME
通过输出的结果验证环境变量是否被正确添加。
安装 Logstash
请从官方下载 logstash 的 windows 安装包,其实就是一个 zip 文件,比如:logstash-6.2.4.zip。Logstash 的安装非常简单,直接解压缩就可以了。示例中,我把它解压到了 C 盘的根目录下,并重命名为 logstash,因此 logstash 的安装目录为:C:\logstash。
如果你想把 logstash 配置为 windows service 运行在后台,请参考《Windows 下配置 Logstash 为后台服务》一文。
安装 SQL Server 的 JDBC 驱动
Logstash 需要使用 JDBC 驱动从 SQL Server 数据库中读取数据,因此我们还需要安装 JDBC 驱动。同样不要去获取最新版本的驱动程序,请选择 Microsoft JDBC Driver 4.2 for SQL Server。下载安装包 sqljdbc_4.2.8112.200_enu.exe,然后运行它。其实它只是个自解压的压缩包,选个目录并解压缩。笔者选择的 C 盘的根目录,所以驱动文件的绝对路径为:
C:\sqljdbc_4.2\enu\jre8\sqljdbc42.jar
在 logstash jdbc 插件中,我们可以直接指定这个文件的绝对路径,比如:
input { jdbc { jdbc_driver_library => "C:\sqljdbc_4.2\enu\jre8\sqljdbc42.jar" ... } }
除了这种方式,我们还可以通过添加环境变量的方法来指定 JDBC 驱动。在 windows 系统中再添加一个名为 CLASSPATH 环境变量,变量的值为:
.;C:\sqljdbc_4.2\enu\jre8\sqljdbc42.jar
. 表示在当前目录下查找,接着是一个 ;(分号)和后面的绝对路径。如果这个路径中包含空格,需要使用双引号包裹这个路径。
在添加了环境变量 CLASSPATH 后,就可以删除上面配置文件中的 jdbc_driver_library 信息了!本文的示例中将会使用 CLASSPATH 环境变量。
配置 Logstash
从 SQL Server 数据库中读取数据是由 logstash 的 JDBC 插件实现的,该插件作为 input 插件默认已随 logstash 安装,可以直接使用:
input { jdbc { jdbc_driver_class => "com.microsoft.sqlserver.jdbc.SQLServerDriver" jdbc_connection_string => "jdbc:sqlserver://DBSVR_NAME;databaseName=DB_NAME;user=****;password=****;" jdbc_user => "****" jdbc_password => "****" statement => "SELECT * FROM [DB].[SCHEMA].[TABLE]" } } output { file { path => "c:\output.txt" } }
jdbc_connection_string 描述了到 SQL Server 的连接字符串,你需要指定 SQL Server 服务器的地址、目标数据库的名称以及用户名称及其密码。jdbc_user 和 jdbc_password 是对连接字符串中用户名、密码的重复。statement 则用来指定查询语句,它返回的结果会被 logstash 获取到。简单起见,我把结果输出到了本机的 c:\output.txt 文件中,这样比较容易调试。
请根据你的实际情况更新上面的配置文件,并保存到 C:\logstash\sql.conf 文件中,然后以管理员权限启动 PowerShell 并进入到 C:\logstash 目录,执行下面的命令:
> .\logstash.bat -f .\sql.conf
如果配置信息正确, statement 指令指定的 SQL 语句的执行结果就会被保存到 C:\output.txt 文件中。
集成域认证
Windows 平台下很多场景中都会使用集成域认证的方式进行身份认证,比如在上例中采用集成域认证的方式代替连接字符串中的用户名和密码:
input { jdbc { jdbc_driver_class => "com.microsoft.sqlserver.jdbc.SQLServerDriver" jdbc_connection_string => "jdbc:sqlserver://DBSVR_NAME;databaseName=DB_NAME;integratedSecurity=true;" jdbc_user => "" statement => "SELECT * FROM [DB].[SCHEMA].[TABLE]" } }
在 jdbc_connection_string 字符串中我们用 integratedSecurity=true 替换了用户名和密码,并且删除了配置项 jdbc_password。 配置项 jdbc_user 也被设置成了空字符串,因为此时 jdbc_user 的值可以随便设置,但不能不设置。
配置 sqljdbc_auth.dll
如果此时启动 logstash 会收到 "无法加载 sqljdbc_auth.dll" 的错误。原因是使用域集成认证时,需要加载 sqljdbc_auth.dll,默认的设置无法找到这个 dll。这个 dll 就在我们安装的 JDBC 驱动目录下,我们需要在 C:\logstash\config\jvm.options 文件中显示指定它的路径。比如添加下面的行:
-Djava.library.path=C:\sqljdbc_4.2\enu\auth\x64
因为我们的演示环境是 x64 架构的,所以这里指定 x64 目录,对于 x86 架构的系统,请指定 x86 目录。
现在就可以通过域认证的方式访问 SQL Server 了,重新执行一遍前面的命令试试!
持续读取数据
使用现在的配置,每执行一遍 .\logstash.bat -f .\sql.conf 命令就会把数据重复追加到 output.txt 文件中一遍。也就是说,每次执行 statement 语句返回的结果都基本一样,不仅无法持续地从数据库读取数据,还会重复输出已经获取过的内容。我们可以使用 jdbc 插件的内置变量 sql_last_value 和配置项 schedule、use_column_value、tracking_column 解决这个问题:
schedule => "* * * * *" statement => "SELECT * FROM [DB].[SCHEMA].[TABLE] WHERE id > :sql_last_value" use_column_value => true tracking_column => "id"
schedule => "* * * * *" 表示每隔一分钟重复执行一次数据读取的操作,它支持 crontab 的语法,所以我们可以根据需要灵活设置读取数据的间隔。内置变量 sql_last_value 会在本地保存一个值,它记录了上次读取的最后一条记录中的一个值,如果 use_column_value 被设置为 true 且 tracking_column 被设置为 "id",则 sql_last_value 保存的就是 id 列的最后一个值(在关系型数据库中,id 列是比较常见的设计)。
上面配置的含义为:
- sql_last_value 变量总是记录上次读取的最后一条记录中的 id。
- 每隔一分钟执行一次数据读取操作。
- 每次只读取上次读取后新增的数据。
把时间戳设置为记录产生的时间
在日志的查询操作中,很多行为是基于默认的 @timestamp 字段的。@timestamp 字段可以简单的理解为日志记录产生的时刻。但是如果我们的日志记录是从数据库或其它地方导入过来的,@timestamp 字段默认记录的是导入日志的时刻,这是不正确的。如果原有的日志记录中保存有日志产生的时刻,我们就可以由它来获得 @timestamp 字段的值:
filter { mutate { add_field => { "logtime" => "%{actiondatetime}" } } date { match => ["logtime", "ISO8601"] target => "@timestamp" remove_field => [ "logtime" ] } }
上面的配置假设数据库中 actiondatetime 列保存了 datetime 类型的数据,通过一个临时字段 logtime 把 actiondatetime 列保存的信息设置给 @timestamp。这样导入后的日志记录的 @timestamp 字段与 actiondatetime 字段保持一致。
参考:
Jdbc input plugin
How to copy SQL Server data to Elasticsearch using LogStash

 浙公网安备 33010602011771号
浙公网安备 33010602011771号