spark
Spark是UC Berkeley AMP lab开发的一个集群计算的框架,类似于Hadoop,但有很多的区别。最大的优化是让计算任务的中间结果可以存储在内存中,不需要每次都写入HDFS,更适用于需要迭代的MapReduce算法场景中,可以获得更好的性能提升。例如一次排序测试中,对100TB数据进行排序,Spark比Hadoop快三倍,并且只需要十分之一的机器。Spark集群目前最大的可以达到8000节点,处理的数据达到PB级别,在互联网企业中应用非常广泛.
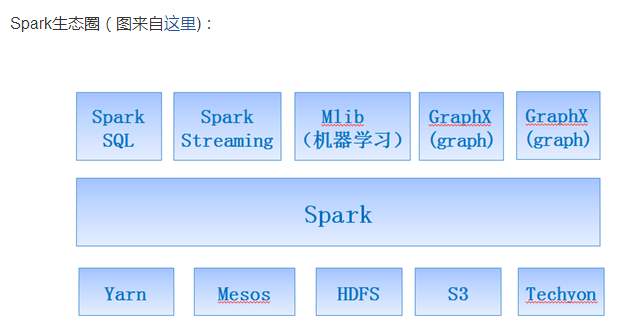
Spark SQL 是一个分布式查询引擎.
Spark Streaming 适用于实时处理流式数据。
Spark 的 MLlib 库相关知识,掌握 MLlib 的几个基本数据类型,并且可以动手练习如何通过机器学习中的一些算法来推荐电影。
GraphX是Spark用于解决图和并行图计算问题的新组件。
GraphX包含了一些用于简化图分析任务的的图计算算法。你可以通过图操作符来直接调用其中的方法。
SparkR是一个提供轻量级前端的R包,集成了Spark的分布式计算和存储等特性。
DataFrame让Spark具备了处理大规模结构化数据的能力,在比原有的RDD转化方式更加易用、计算性能更好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号