

部署千文3大预言模型环境
部署
8C/16G/Ubuntu24 需要图形化界面
rambo@ub24-2:~$ curl -fsSL https://ollama.com/install.sh | sh
>>> Installing ollama to /usr/local
>>> Downloading Linux amd64 bundle
######################################################################## 100.0%
>>> Creating ollama user...
>>> Adding ollama user to render group...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service.
>>> The Ollama API is now available at 127.0.0.1:11434.
>>> Install complete. Run "ollama" from the command line.
WARNING: No NVIDIA/AMD GPU detected. Ollama will run in CPU-only mode.
解释:
这个警告表示在我的Ubuntu24虚拟机中,没有检测到支持加速的 NVIDIA 或 AMD GPU;
因此 Ollama 将使用 CPU 模式运行,这会比GPU模式慢很多,尤其是在运行大型模型时
这不是一个“错误”(error),不会阻止 Ollama 正常运行,只是提示你缺少硬件加速
#选择适合自己的开源模型,通过下方的命令进行安装部署:
0.6B参数模型:ollama run qwen3:0.6b
1.7B参数模型:ollama run qwen3:1.7b
4B参数模型:ollama run qwen3:4b
8B参数模型:ollama run qwen3:8b
14B参数模型:ollama run qwen3:14b
32B参数模型:ollama run qwen3:32b
注:上述6个是密集型模型,如果显存大于4G且小于8G的就用前3个,如果显存是8G以上的可用上述6个中的后2个或30B
30B混合专家模型,包含3B个活动参数:ollama run qwen3:30b-a3b
235B混合专家模型,包含22B个有效参数:ollama run qwen3:235b-a22b
注:235B仅限于高级的专业显卡才可以,普通的电脑就不要想了
因为我用的CPU来跑,所以就用上述最小的模型
rambo@ub24-2:~$ ollama run qwen3:0.6b
pulling manifest
pulling 7f4030143c1c: 100% ▕████████████████████████████████████████████████████████████████▏ 522 MB
pulling eb4402837c78: 100% ▕████████████████████████████████████████████████████████████████▏ 1.5 KB
pulling d18a5cc71b84: 100% ▕████████████████████████████████████████████████████████████████▏ 11 KB
pulling cff3f395ef37: 100% ▕████████████████████████████████████████████████████████████████▏ 120 B
pulling b0830f4ff6a0: 100% ▕████████████████████████████████████████████████████████████████▏ 490 B
verifying sha256 digest
writing manifest
success
>>> Send a message (/? for help) # 这里的字是提示,不用动也不用关
再开一个窗口执行下述命令
下载Cherry-Studio
rambo@ub24-2:~$ sudo apt install -y fuse
rambo@ub24-2:~$ sudo chmod +x Cherry-Studio-1.2.9-x86_64.AppImage
rambo@ub24-2:~$ ./Cherry-Studio-1.2.9-x86_64.AppImage --appimage-extract
rambo@ub24-2:~$ cd squashfs-root/
rambo@ub24-2:~/squashfs-root$ sudo chown root:root chrome-sandbox
rambo@ub24-2:~/squashfs-root$ sudo chmod 4755 chrome-sandbox
rambo@ub24-2:~/squashfs-root$ ./AppRun
注:语言模型知识是截止到2023年之前的
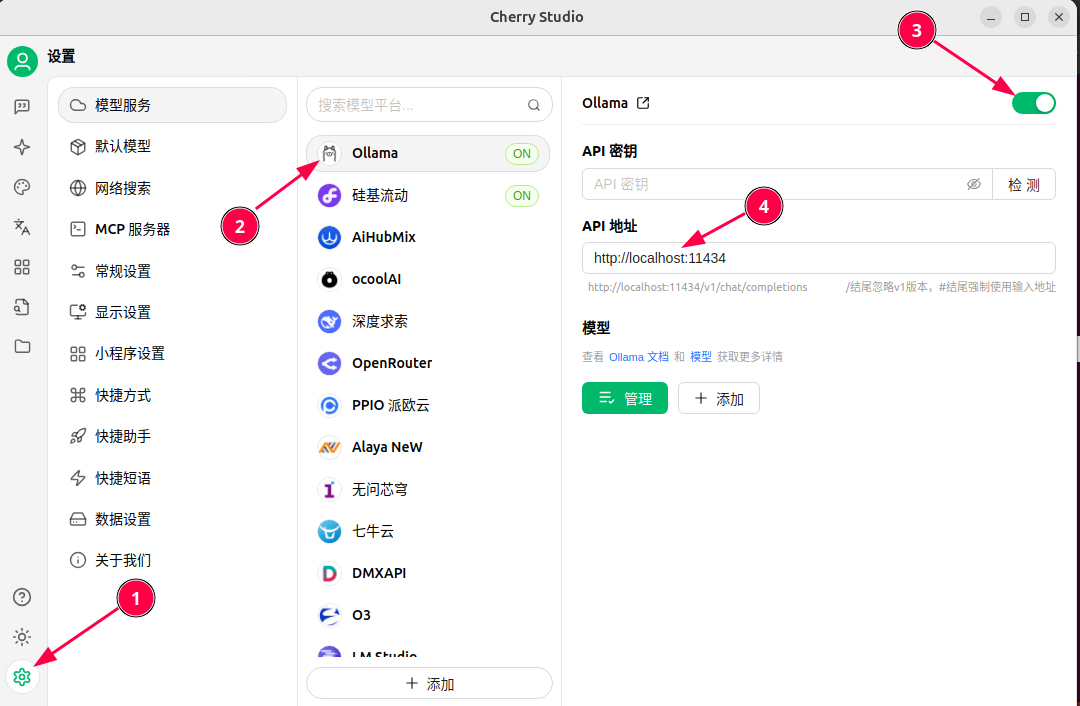


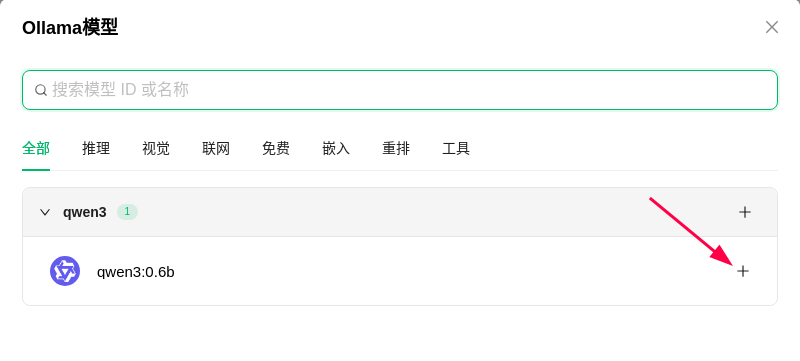
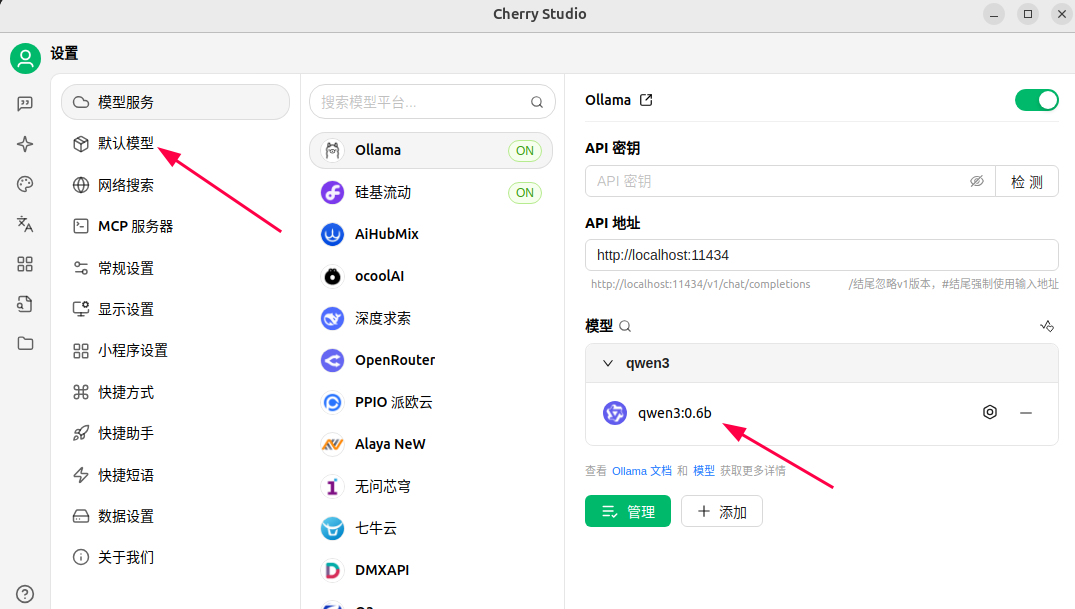
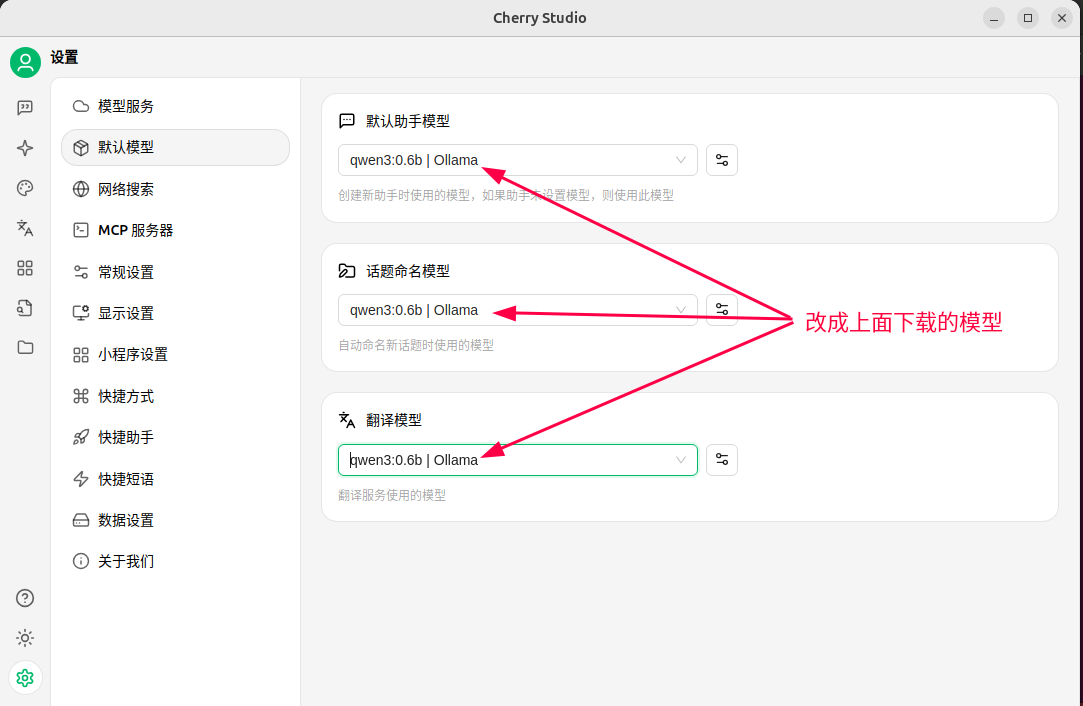
如何卸载已安装过的模型?在CMD终端下:
ollama list # 查询已安装的模型
ollama rm 模型名称 # 卸载并删除模型
比如需要删除gemma2:27b 模型,那么只需输入:ollama rm gemma2:27b

 浙公网安备 33010602011771号
浙公网安备 33010602011771号