

YOLO模型训练自己数据-VOC格式数据集制作-ubuntu c++文件夹内图片批量读取与重命名
参考)YOLOv2训练自己的数据集(voc格式)进行实验,基本上是正确的,但其初始给出的代码并非是在linux下可以运行的,因此参考部分博客写了下面的程序,可以实现对文件夹内图片的批量读取以及更改名称符合VOC数据集习惯。另原文有部分小错误,本文已经修改,但后文属于转载,版权属原作者所有,本文仅为记录和交流用。如下文所示。
1 准备数据
#include <dirent.h>
#include <sys/stat.h>
#include <unistd.h>
#include <stdio.h>
#include <string.h>
#include <opencv2/opencv.hpp>
#define img_num 2000
char img_file[img_num][1000];
int list_dir_name(char* dirname, int tabs)
{
DIR* dp;
struct dirent* dirp;
struct stat st;
char tab[tabs + 1];
char img_count=0;
/* open dirent directory */
if((dp = opendir(dirname)) == NULL)
{
perror("opendir");
return -1;
}
/* fill tab array with tabs */
memset(tab, '\t', tabs);
tab[tabs] = 0;
/**
* read all files in this dir
**/
while((dirp = readdir(dp)) != NULL)
{
char fullname[255];
memset(fullname, 0, sizeof(fullname));
/* ignore hidden files */
if(dirp->d_name[0] == '.')
continue;
/* display file name */
//printf("img_name:%s\n", dirp->d_name);
strncpy(fullname, dirname, sizeof(fullname));
strncat(fullname, dirp->d_name, sizeof(fullname));
strcat(img_file[img_count++], fullname);
printf("Image %3d path:%s\n",img_count-1,img_file[img_count-1]);//fullname=dir+file name,the absolute path of the image file
/* get dirent status */
if(stat(fullname, &st) == -1)
{
perror("stat");
fputs(fullname, stderr);
return -1;
}
/* if dirent is a directory, call itself */
if(S_ISDIR(st.st_mode) && list_dir_name(fullname, tabs + 1) == -1)
return -1;
}
return img_count;
}
int main(int argc, char* argv[])
{
char* dir="/home/robot/Downloads/mark_recognition/car_img/simple_3class/";
printf("%s\n", dir);
char sum=list_dir_name(dir, 1);
printf("Img total num:%d\n",sum);
int i;
char order[1000];
char txt_path[1000];
char* txt_name="train.txt";
memset(txt_path, 0, sizeof(txt_path));
strcat(txt_path,dir);
strcat(txt_path,txt_name);
FILE *fp = fopen(txt_path, "w");
for (i = 0; i<sum; ++i)
{
char img_path[1000];
memset(img_path, 0, sizeof(img_path));
printf("Source %s\n", img_file[i]);
IplImage *pSrc = cvLoadImage(img_file[i]);
sprintf(order, "%05d.jpg", i);
strcat(img_path,dir);
strcat(img_path,order);
cvSaveImage(img_path, pSrc);
fprintf(fp, "%05d\n", i);
printf("Save as%s\n", img_path);
cvReleaseImage(&pSrc);
}
fclose(fp);
return 0;
}
2 标记图像目标区域
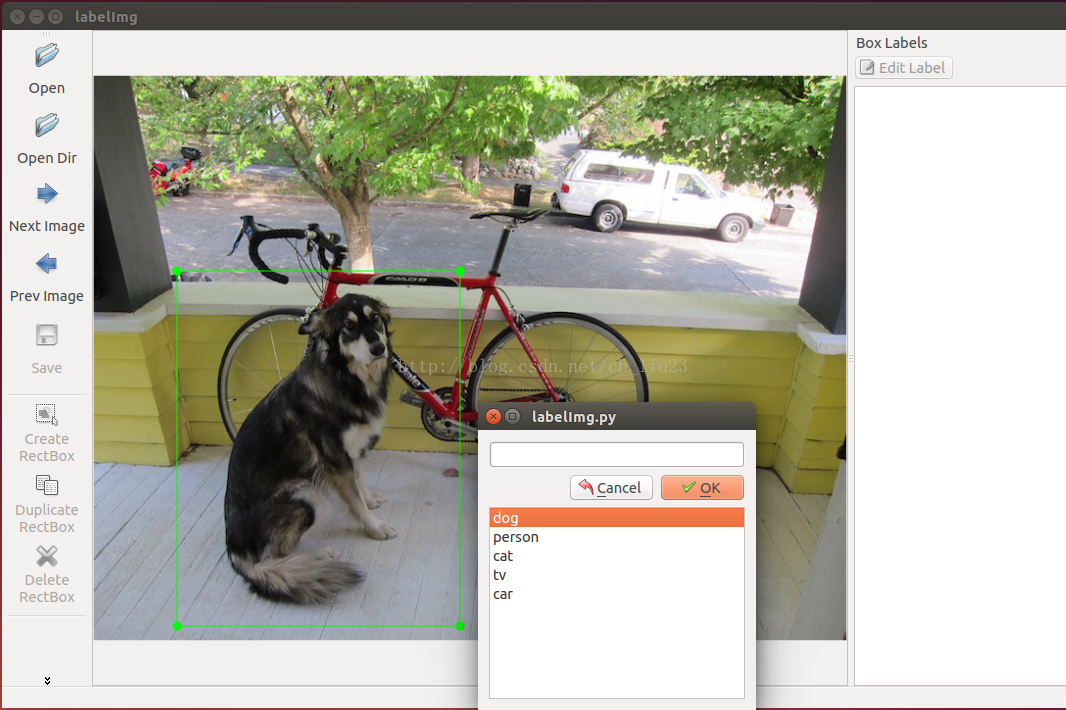
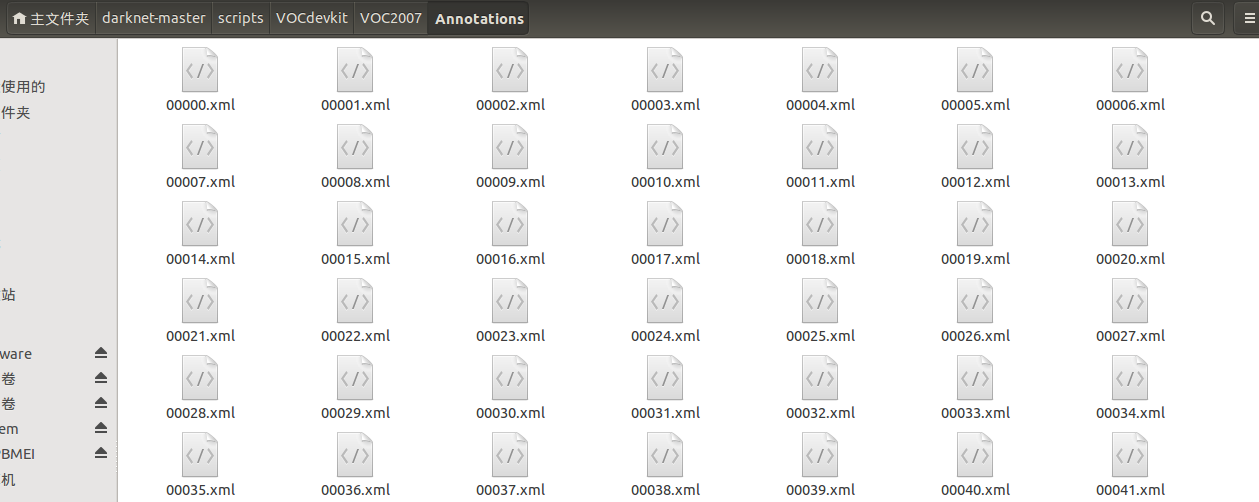
通常save之后会将标记的信息保存在xml文件,其名字通常与对应的原始图像一样。最后生成的画风是这样的
有时候在Windows下用该工具label图像,可能会出现size那里的width和height都为0,如果在label之前已经归一化了图像大小那么就可以用下面两行命令来修改这个0值
同理修改宽: 同理修改高: 在对应目录下执行即可,这样就可以把后缀添上。这样就做按照VOC做好了我们的数据集,接下来就是放到算法中去训练跑起来。
3 用YOLOv2训练
1).生成相关文件
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
#sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
#classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
sets=[('2007', 'train')]
classes = [ "person"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id)) #(如果使用的不是VOC而是自设置数据集名字,则这里需要修改)
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w') #(同上)
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()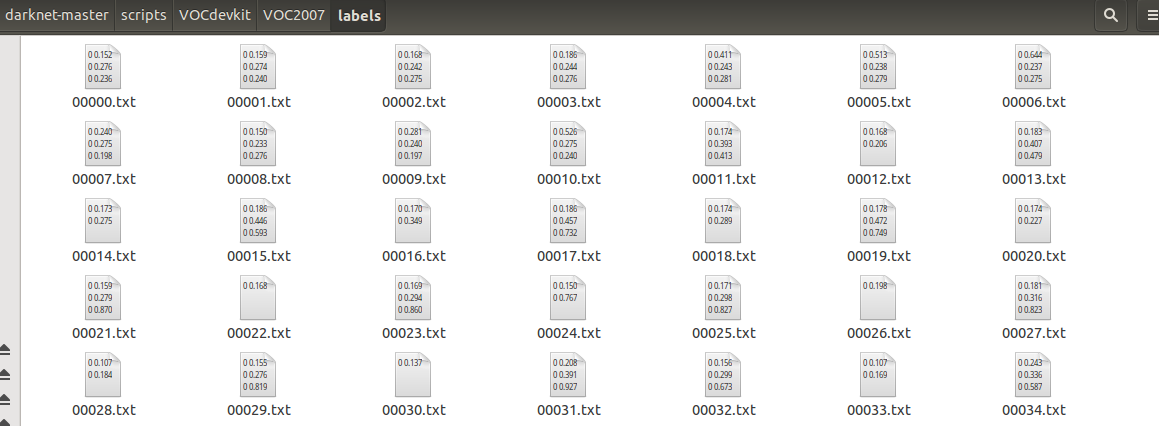
2).配置文件修改
做好了上述准备,就可以根据不同的网络设置(cfg文件)来训练了。在文件夹cfg中有很多cfg文件,应该跟caffe中的prototxt文件是一个意思。这里以tiny-yolo-voc.cfg为例,该网络是yolo-voc的简版,相对速度会快些。主要修改参数如下
另外也可根据需要修改learning_rate、max_batches等参数。这里歪个楼吐槽一下其他网络配置,一开始是想用tiny.cfg来训练的官网作者说它够小也够快,但是它的网络配置最后几层是这样的画风:
这里没有类别数,完全不知道怎么修改,强行把最后一层卷积层卷积核个数修改又跑不通会出错,如有大神知道还望赐教。
修改好了cfg文件之后,就需要修改两个文件,首先是data文件下的voc.names。打开voc.names文件可以看到有20类的名称,本例中只有一类,检测人,因此将原来所有内容清空,仅写上person并保存, 备注:若此处为多个类的训练,请同voc_label.py 中顺序一致。
接着需要修改cfg文件夹中的voc.data文件。也是按自己需求修改,我的修改之后是这样的画风:
修改后按原名保存最好,接下来就可以训练了。ps:yolo v1中这些细节是直接在源代码的yolo.c中修改的,源代码如下
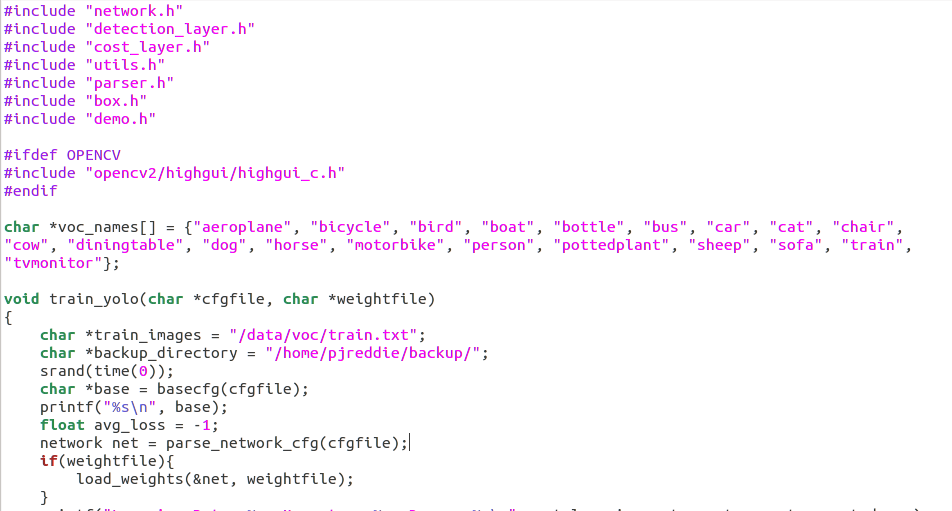
比如这里的类别,训练样本的路径文件和模型保存路径均在此指定,修改后从新编译。而yolov2似乎摈弃了这种做法,所以训练的命令也与v1版本的不一样。
3).运行训练and 测试
上面完成了就可以命令训练了,可以在官网上找到一些预训练的模型作为参数初始值,也可以直接训练,训练命令为
./darknet detector train ./cfg/voc.data cfg/tiny-yolo-voc.cfg
./darknet detector test cfg/voc.data cfg/tiny-yolo-voc.cfg result/yolo-voc_400.weights testImage/738780.jpg
或者
./darknet detector test cfg/voc.data cfg/tiny-yolo-voc.cfg results/tiny-yolo-voc_final.weights 0000.jpg

 浙公网安备 33010602011771号
浙公网安备 33010602011771号