

Recurrent Neural Network[survey]
0.引言
我们发现传统的(如前向网络等)非循环的NN都是假设样本之间无依赖关系(至少时间和顺序上是无依赖关系),而许多学习任务却都涉及到处理序列数据,如image captioning,speech synthesis,music generation是基于模型输出序列数据;如time series prediction,video analysis,musical information retrieval是基于模型输入需要序列数据;而如translating natural language,engaging in dialogue,controlling a robot是输入和输出都需要序列数据,所以非循环NN是无法直接处理这些任务的。假如说基于传统的非循环NN采用滑框的形式来处理先后关系,可是因为是滑框大小是必须固定的,对于序列数据是可变长度情况下,还是没法解决。而且对于对话系统或者说自动驾驶等任务来说,也没法基于所谓的分类器和回归器去组合成一个新模型从而解决问题。所以还是需要一些能够显示的处理时序依赖关系的方法。
那么问题来了,为什么不能用HMM呢?
因为HMM必须基于离散的适度数量的状态集合\(S\)中去状态转换,即使使用了viterbi算法,算法时间复杂度也是O(\(|S|^2\)),所以一旦状态增多,那么HMM的复杂度就急速上升了,而且如果采用滑框形式来融合多个状态,一旦窗口变大,计算复杂度也指数上升了,所以HMM对于长时依赖问题也是很麻烦的。
所以RNN系列应运而生了。一方面基于非线性激活函数的固定size的RNN几乎可以拟合任意的数学计算,并且RNN是基于NN的,不但可以用SGD方式训练,而且还可以增加正则项等来缓解过拟合问题;另一方面,RNN的图灵完备特性使得其一旦结构定义了,就不太可能生成任何其他随意的模式(固定性)。
即此刻的状态包含上一刻的历史,又是下一刻变化的依据。 这其实包含了可编程神经网络的核心概念,即, 当你有一个未知的过程,但你可以测量到输入和输出, 你假设当这个过程通过RNN的时候,它是可以自己学会这样的输入输出规律的, 而且因此具有预测能力。 在这点上说, RNN是图灵完备的.转自知乎
RNN的研究可以追溯到19世纪80年代。
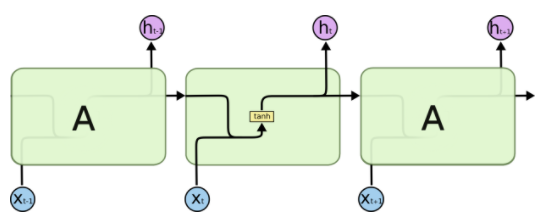
图0.1 RNN结构图
而这种模型虽然能够处理时间依赖或者顺序依赖关系,可是内部隐藏层的输出会循环的连接到下一个时间步的隐藏层,如果\(W_{hh}\)小于1(大于1),那么时间长了,就会导致梯度消失(爆炸)。
0.1 RNN的展开
对于RNN本身的结构,其还算是清晰的。不过介于目前的训练方式都是梯度下降的。如何训练也是个问题。如下图
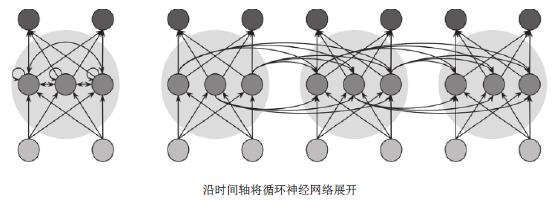
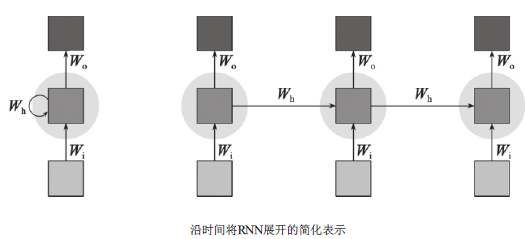
图0.1.1 RNN的随时间展开
如图0.1.1所示,RNN的随时间展开,就是将隐含神经元复制t次,并将它们的连接从一个副本跨连到相邻的另一个副本。这样便可将那些循环连接移除,而不更改计算的语义。经过上述处理,便形成了一个前馈网络,且相邻时间步之间的权值都拥有相同的强度。如假设RNN公式如下:
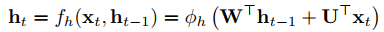
图0.1.2 RNN公式
- 前向:那么对于图0.1.1中任意两个相邻的副本,假设前一个是时间步t-1,后一个是时间步t,则从时间步t-1的隐藏层输出\(h_{t-1}\),连接到时间步t的隐藏层输入,与\(x_t\)一起送入当前隐藏层,即展开的形状和不展开是完全对等的。故而展开的\(W_{t,t-1}\)就等于不展开时候\(W_{t,t-1}\),同时\(W_{t,t-1}\)也等于\(W_{t+1,t}\),即展开就是复制而已。
- 后向:在一个序列中,RNN的权重都是固定的。即如图0.1.1的下面的图,在一个序列中,输入,输出,循环这三个权重都是固定的(那么就类似CNN中卷积层那种感觉:在一个feature map中,每个滤波器的权重都是相同的)。也就是:先如博客1中介绍的一样,按照正常的展开进行BP计算每个连接的梯度;然后如博客2或者《Deep Learning》花书中10.2.2介绍的一样,是按照时间将梯度相加,作为当前连接所需要更新的梯度,即如\(W_o\),先计算展开时候每个时间步对应的梯度,然后在进行\(W_o\)的梯度更新的时候,$ \triangledown W_o=\sum_tTW_ot$。
图0.1.3 2层RNN及对应的展开
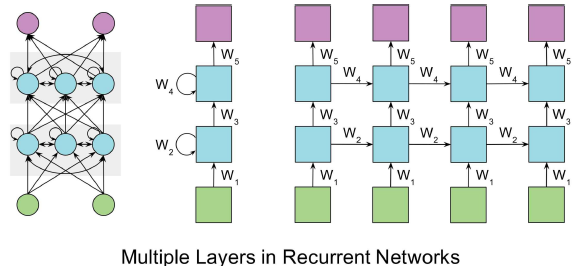
1. 现代RNN结构
因为图0.1这种RNN基本有着训练困难等问题,所以现在关于RNN的都不是最原始的RNN结构。在之前,就有很多关于如何解决训练难的问题,如:
- 梯度消失:换结构,LSTM;使用二阶优化算法《Deep learning via hessian-free optimization》,《Learning recurrent neural networks with hessian-free optimization 》;RNN权重增加正则《On the difficulty of training recurrent neural networks》;不要一起学习循环权重《The echo state approach to analysing and training recurrent neural networks-with an erratum note》,《Harnessing nonlinearity:Predicting chaotic systems and saving energy in wireless communication》 ;小心的初始化《On the importance of initialization and momentum in deep learning》;
- 梯度爆炸:处理梯度爆炸的问题相对梯度消失来说,就暴力了一些了,就是简单的对梯度的范式做个硬性限制 《Statistical Language Models based on Neural Networks》,《 On the difficulty of training recurrent neural networks》
近些年,最成功的RNN变种结构来自于1997年的2篇论文:
- 《long short-term memory》就是LSTM模型,通过引入一个记忆单元,用来代替传统RNN中的隐藏层节点,因为有这些记忆单元,网络可以克服之前训练RNN遇到的问题;
- 《bidirectional recurrent neural networks》就是BiRNN,通过引入一种需要同时考虑下一个时间步和上一个时间步的信息来做当前时间步决定的结构,从而成功的应用在NLP的序列标签任务中。
值得庆幸的是,这两种结构并不是互斥的,所以可以融合在一起,比如用它解决了音素的分类(Framewise phoneme classi cation with bidirectional LSTM and other neural network architectures,2005)和手写识别(A novel connectionist system for unconstrained handwriting recognition,2009)。当然后续的《neural turing machine》。
1.1 LSTM
LSTM最开始主要是为了解决梯度消失问题的,该模型通过对标准的RNN增加一层隐藏层,而该隐藏层是以记忆单元的形式表示的。该记忆单元包含了一个自循环连接,而且其中表示的权重是恒等于1(resnet中也是为1的恒等连接),如图1.1.1左边,从而确保梯度无论传递多少次都可以防止消失或者爆炸。该模型之所以叫long-short term memory,主要来自以下解释:
- long-term memory:这是基于权重来解释的,在很长时间的训练step中,其权重变化都不是很大,从而能够编码数据的通用知识(general knowledge),;
- short-term memory:这是基于激励值来解释的,即每个节点短暂的激活值都会直接传递到下一个节点;
- memory:该网络结构引入一个记忆单元来作为中间的信息存储介质。一个记忆单元是一个复合单元,其中由更简单的节点以特定连接模式构成,其中的\(c_t\)就表示为长期的记忆,而\(h_t\)就表示为短期的记忆。相对来说,长期记忆的梯度较小,短期记忆的梯度较大。
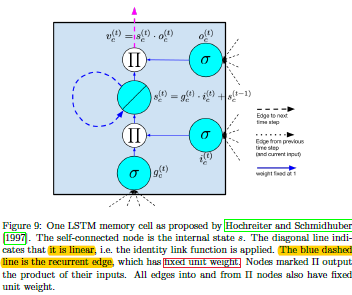
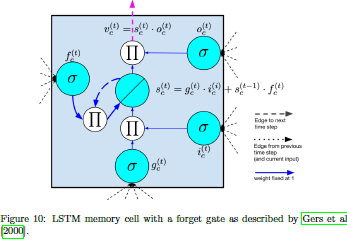
图1.1.1 最初的LSTM和最常用的LSTM模型结构
如图1.1.1,在200年《Learning to forget: Continual prediction with LSTM》中,在基于最初LSTM模型基础上,增加了一个遗忘门,即中间的记忆单元的输出不是以恒等映射的形式输入到下一个时间步的记忆单元,而是增加了一个遗忘门来选择性的增加其中一部分到下一个时间步。
上述都是基于单个记忆单元基础上的LSTM,而当隐藏层中有多个记忆单元时,如图1.1.2所示。

图1.1.2 包含2个记忆单元的LSTM模型结构
图1.1.2中因为粉红色线和黑色线画的还是有些模糊的,所以有些理不清。不过基于当前时间步来说,其中的2个记忆单元的输出都会互相输出到下一个时间步,即一个记忆单元的输出会到下一个时间步的自身记忆单元和另一个记忆单元
1.2 BRNN
和LSTM相比,另一个用的最成功的RNN就是BRNN了,该结构中,有2层隐藏层,其中每个隐藏层都连接到输出和输入。这2个隐藏层可以微分,且都有自循环连接,不过一个是朝着下一个时间步连接的,另一个是朝着上一个时间步连接的。
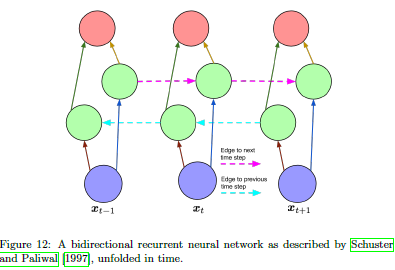
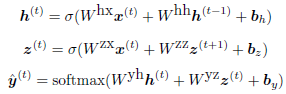
图1.2.1 BRNN示意图
给定一个输入序列和一个目标序列,BRNN可以先基于时间维度展开,然后采用传统的BP方法来训练。图1.2.1中,\(h^{t}\),\(z^{t}\)就是前向和后向的连接。
这里接着给出《Bidirectional Recurrent Neural Networks》上有关训练部分的文章截图,可以看出BRNN的训练相对RNN稍微有点计算量,大致是2倍。

图1.2.1 BRNN论文中的截图
BRNN的一个限制是他不能连续的运行,因为他需要在序列的开始和结束都各有一个固定的占位符,而且该模型也没法用在ML中的在线环境,因为你没法得到未来的数据。不过对于如词性标注任务,或者给定一个句子,用来做其中某个单词基于其前后单词基础上是否合理的评价等任务还是很好的。
1.3 NTM
神经图灵机是通过增加可以访问的外置存储来扩展RNN,这样使得RNN的能力能够处理较为复杂的算法,如排序。NTM的2个主要组件是一个控制器和一个记忆矩阵:
- 控制器:可以是一个循环神经网络或者就是前向神经网络,基于输入然后返回输出到外部,就如计算机从内存中读取指令一样;
- 记忆矩阵:该记忆矩阵是一个\(N\times M\)的大矩阵,行表示一个记忆向量,列表示该向量维度
NTM可以使用随机梯度下降等方式去end-to-end的训练。Graves et al在NTM上测试了几种不同的任务:copy,priority sort等。实验测试了是否NTM可以通过有监督学习的方式来训练从而正确且高效的实现这些算法。有趣的是,即使输入的样本长度大于训练集中的样本,也能合理的泛化。
2. 最优RNN模型的探索
Rafal Jozefowicz等人在2015年的工作主要目的就是研究是否LSTM结构是最优的,是否有其他更优的结构。他们构建了1w个不同的RNN结构,在此上进行了超过1k个不同结构搜索,并找到一个在大部分情况下都优于LSTM和GRU的结构,并且发现对于LSTM的遗忘门偏置的一个重要结论,即偏置初始值需要大于等于1,这样可以拉近LSTM与GRU之间的差异。并且作者发现输入门很重要,输出门不太重要,遗忘门在任何情况下都特别重要,除了在语言建模的时候(这也与《Learning longer memory in recurrent neural networks》中的意见一致,那篇论文是在标准RNN上增加一个硬编码的整合单元,其结构就和没有遗忘门的LSTM差不多,其在语言建模上效果不错)。在Rafal Jozefowicz的论文中LSTM的结构和对应公式,如图2.1。
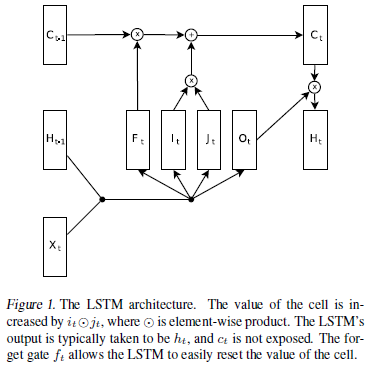
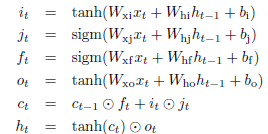
图2.1 LSTM的结构和对应公式
LSTM在不同时期不同人论文中总有些小变化,如图2.1中是与《Generating sequences with recurrent neural networks》中结构很相似,不过是没有peephole连接的。
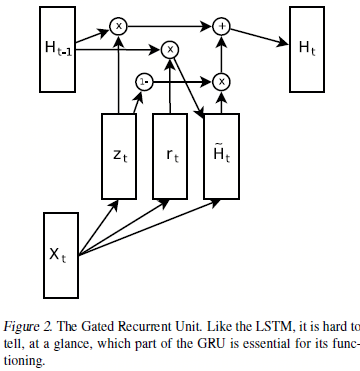
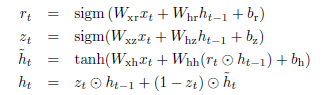
图2.2 GRU的结构和对应公式
2.1 遗忘门
通常大家对神经网络的初始化都是差不多的策略。如在LSTM中遗忘门偏置的初始化为0.5,这会导致每个时间步上梯度以0.5倍消失,从而导致长时依赖无法完成,作者发现只要将遗忘门的偏置\(b_f\)的值设定大点,如1或者2。这样遗忘门整个的值就会差不多接近于1(\(1/{1+e^{-0}}=0.5\),\(1/{1+e^{-1}}=0.73\)),从而保证了梯度的信息流传动。
2.2 结果
作者在对比GRU与LSTM时发现,基于navie的初始化基础上,基本在所有任务中都好于LSTM,不过的确如果将LSTM的遗忘门偏置初始值设的大一点,LSTM的效果还是接近于GRU的。有个有趣的现象就是,按照作者设定的模型搜索流程,最后得到的三个最好的模型都和GRU差不多,所以如果想要找到一个特别优于LSTM的模型,那么至少不是那么轻松的。
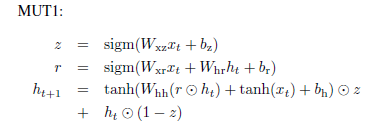
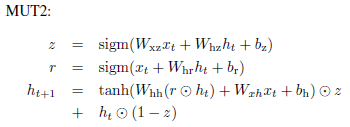
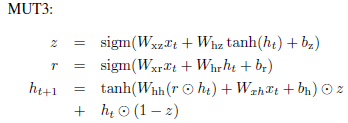
图2.3.1 搜索到的最好的三个结构的公式
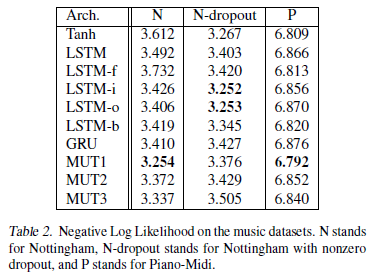
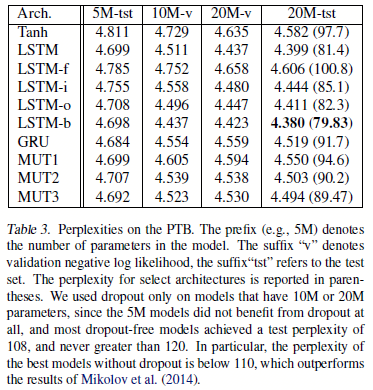
图2.3.2 在music和PTB任务上的结果
如图2.3.2,其中LSTM-i、LSTM-f、LSTM-o表示这个LSTM去掉输入门、遗忘门、输出门之后的结构;LSTM-b表示这个LSTM遗忘门的偏置是1;Tanh就是标准的Tanh RNN。MUT1、MUT2、MUT3是搜索出来的3个最好的模型。总结结果:
- GRU除了在语言建模任务上,其他任务上都好于LSTM
- MUT1在语言建模上的效果和GRU相当,在其他任务上更好;
- LSTM在PTB语言建模任务上当使用了dropout之后,明显好于其他结构
- LSTM中将遗忘门的偏置设定大一点,可以在基本所有任务上都好于其他LSTM和GRU
- MUT1在两个music数据集上是最好的结构,而如果使用了dropout,LSTM-i和LSTM-o可以获得最好的结果。
3. LSTM结构本身的搜索
Klaus Greff着重分析了8个不同的LSTM变种在3个不同任务上的表现:speech recognition《DARPA TIMIT Acoustic-Phonetic
Continuous Speech Corpus CD-ROM》, handwriting recognition《IAM-OnDB-an on-line English sentence database acquired from handwritten text on a whiteboard》,polyphonic music modeling《Harmonising chorales by probabilistic inference》。在所有LSTM变种的每个任务上采用随机搜索的方式进行独立优化,他们的重要性通过fANOVA框架进行评估,总的来说,一共5400个实验,大致需要15个CPU年才能跑完。结果显示没有任何一个变种相对标准LSTM结构有明显的提升。
如上面第2小节所述,不同论文,不同时期对LSTM的结构有些轻微的不同,如Klaus Greff以《Framewise phoneme classification with bidirectional LSTM and other neural network architectures.》中的结构为主要引入观点的结构,称之为vanilla LSTM,该LSTM结构定义如下:

图3.1 有peephole连接的LSTM结构
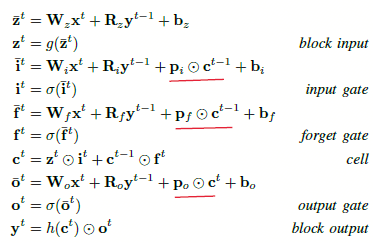

图3.2 基于图3.1中LSTM对应的公式和部分导数
如图3.1,最开始是Gers and Schmidhuber等人在《Recurrent nets that time and count》中认为,为了学习准确的时间,希望记忆单元也能参与到门的控制中,从而添加了peephole连接,并且去掉了输出激活函数,因为没发现这部分有什么作用;然后Graves and Schmidhuber等人在《Framewise phoneme classification with bidirectional LSTM and other neural network architectures》中描述了完整的通过时间维度(backpropagation through time,BPTT)的反向传播进行训练LSTM,通过BPTT进行训练可以使用有限的查分来检查LSTM的梯度,使得在实际实现中更稳定可靠,此时的模型就是vanilla LSTM。当然其他的LSTM变种见本文最下的参考文献。
即LSTM经历了:最原始的LSTM -> 添加遗忘门的LSTM -> 添加了peephole连接的LSTM -> vanilla LSTM
3.1 变种LSTM及对应数据集的设置
Klaus Greff等人的实验中的设置如下:
- 结构选取上,在JSB Chorales任务上:使用的是一个单隐层和一个sigmoid输出层的LSTM;在TIMIT和IAM在线任务上:使用的是BiLSTM,包含2个隐层,大致结构如图1.2.1;
- 目标函数选取上,在JSB Chorales和TIMIT上采用的是交叉熵;在IAM在线任务上采用的是CTC(Connectionist Temporal Classification《Connectionist temporal classification:labelling unsegmented sequence data with recurrent neural networks》)目标函数
- 模型训练上,采用了《On the importance of initialization and momentum in deep learning》中的方法,LSTM部分的梯度计算是用的full BPTT
Klaus Greff等人选取的8种LSTM变种如下,下面的几种变种都是基于图3.1结构为基础的:

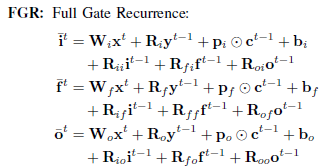
图3.1.1 8种基于vanilla LSTM结构的变种
在超参数选取中,Klaus Greff等人用的是随机搜索,其好处有:
- 容易实现;
- 容易并行;
- 可以均匀的覆盖搜索空间;
- 有利于后续分析超参数的重要性。
不过他们发现在TIMIT数据集上对比传统的动量和Nesterov-style动量两种方法发现,都没什么差别;而且发现如果强行将梯度限制在[-1,1],那么结果会较大下降,所以后续两个数据集上就不clip梯度了。
3.2 实验结果
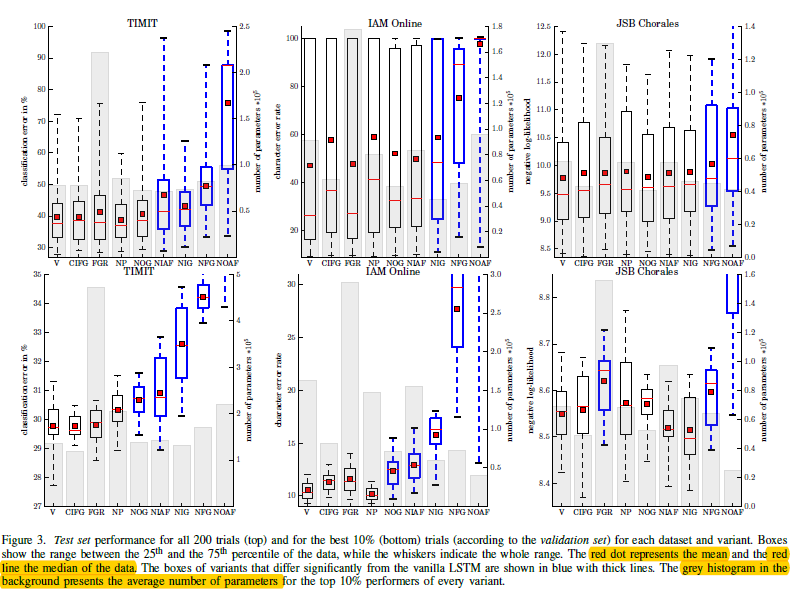
图3.2 基于3个数据集下8种变种的结果
如图3.2,有意思的是,当移除了其中的遗忘门和输出激活函数的时候,结果一下子就变的特别差了;而CIFG模型没有这个问题,这也佐证了GRU模型的有效性;同样NP模型和CIFG模型一样,都没多大准确率下降,这也说明了peephole没多大贡献,不过还是略有帮助的,所以这样的对比实验是有助于减少LSTM模型的复杂性的;从FGR模型可以看出,该方法也没多大用处,在TIMIT和IAM在线任务上准确度提升不大,而且还加大了参数量,所以可以考虑以此简化LSTM;对于NIG,NOG,NIAF等模型上,就可以看出有明显的准确度下降了,所以对于有监督的连续实数数据上的模型来说,输入门,输出门和输入激活函数还是至关重要的。
在超参数对比上:
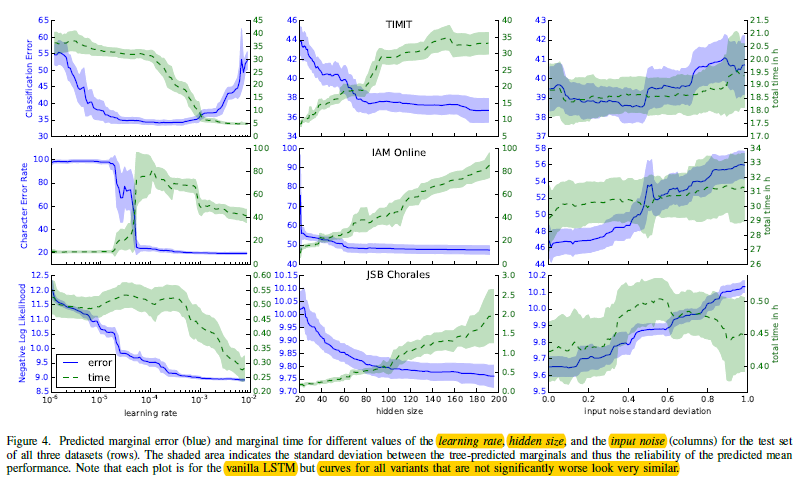
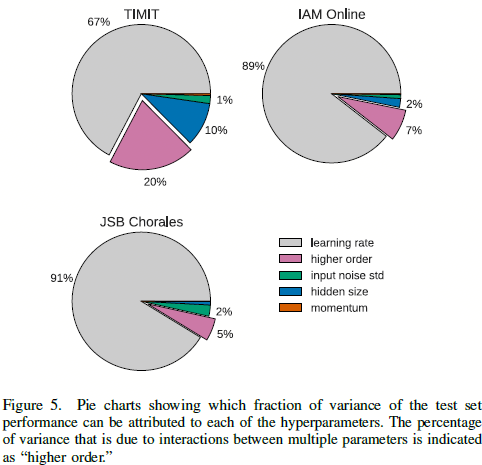
图3.2 基于三个数据集下,vanilla LSTM的结果对比
- 学习率:从图3.2中可以看出影响最大的还是学习率,而且对于不同数据集,最优学习率有所不同,不过给我们的提示就是,可以最开始采用较大学习率,如1.0,然后在当准确度停止不动时候降低学习率,如除以10;而且可以在一个较小的网络上快速的训练,从而得到一个较好的学习率策略,然后直接用到更大的模型上就行;
- 隐藏层大小:从中间一列看,隐藏层越大,模型效果越好,当然训练时间也相对增加;
- 在使用在线SGD训练时,动量带来的收益不大
4. 基于实验角度可视化和理解RNN
5. RNN等模型的应用
参考文献:
- [survey] - Lipton Z C, Berkowitz J, Elkan C. A critical review of recurrent neural networks for sequence learning[J]. arXiv preprint arXiv:1506.00019, 2015.
.. [survey] - Jozefowicz R, Zaremba W, Sutskever I. An empirical exploration of recurrent network architectures[C]//Proceedings of the 32nd International Conference on Machine Learning (ICML-15). 2015: 2342-2350.
.. [survey] - Greff K, Srivastava R K, Koutník J, et al. LSTM: A search space odyssey[J]. IEEE transactions on neural networks and learning systems, 2017.
.. [survey] - Karpathy A, Johnson J, Fei-Fei L. Visualizing and understanding recurrent networks[J]. arXiv preprint arXiv:1506.02078, 2015. - [Variants] - Felix A. Gers, Juan Antonio P´erez-Ortiz, Douglas Eck, and J¨urgen Schmidhuber. DEFK-LSTM. In ESANN 2002, Proceedings of the 10th Eurorean Symposium on Artificial Neural Networks, 2002.
.. [Variants] - J Schmidhuber, D Wierstra, M Gagliolo, and F J Gomez.Training Recurrent Networks by EVOLINO. Neural Computation, 19(3):757–779, 2007.
.. [Variants] - Justin Bayer, Daan Wierstra, Julian Togelius, and J¨urgen Schmidhuber. Evolving memory cell structures for sequence learning. In Artificial Neural Networks–ICANN 2009, pages 755–764. Springer, 2009. URL http://link.springer.com/chapter/10.1007/978-3-642-04277-5 76.
.. [Variants] - Rafal Jozefowicz, Wojciech Zaremba, and Ilya Sutskever.An empirical exploration of recurrent network architectures.In Proceedings of the 32nd International Conference on Machine Learning (ICML-15), pages 2342–2350, 2015.
.. [Variants] - Hasim Sak, Andrew Senior, and Franc¸oise Beaufays.Long short-term memory recurrent neural network architectures for large scale acoustic modeling. In Proceedings of the Annual Conference of International Speech Communication Association (INTERSPEECH),2014. URL http://193.6.4.39/~czap/letoltes/IS14/IS2014/PDF/AUTHOR/IS141304.PDF
.. [Variants] - Patrick Doetsch, Michal Kozielski, and Hermann Ney.Fast and robust training of recurrent neural networks for offline handwriting recognition. In 14th International Conference on Frontiers in Handwriting Recognition,2014. URL http://people.sabanciuniv.edu/berrin/cs581/Papers/icfhr2014/data/4334a279.pdf
.. [Variants] - Sebastian Otte, Marcus Liwicki, and Andreas Zell. Dynamic Cortex Memory: Enhancing Recurrent Neural Networks for Gradient-Based Sequence Learning. In Artificial Neural Networks and Machine Learning – ICANN 2014,number 8681 in Lecture Notes in Computer Science,pages 1–8. Springer International Publishing, September 2014. ISBN 978-3-319-11178-0, 978-3-319-11179-7. URL http://link.springer.com/chapter/10.1007/978-3-319-11179-7_1
.. [Variants] - Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre,Fethi Bougares, Holger Schwenk, and Yoshua Bengio.Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv preprint arXiv:1406.1078, 2014. URL http://arxiv.org/abs/1406.1078
.. [Variants] - Junyoung Chung, Caglar Gulcehre, KyungHyun Cho,and Yoshua Bengio. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling.arXiv:1412.3555 [cs], December 2014. URL http://arxiv.org/abs/1412.3555 - [blog][wildml] - BPTT; 中文翻译
- [paper] - Boden M. A guide to recurrent neural networks and backpropagation[J]. the Dallas project, 2002.
- [blog] - 基于时间的反向传播算法BPTT,wildml翻译; 较多总结
- [blog] - 一个pdf; BPTT的pdf; Supervised Sequence Labelling with Recurrent Neural Networks
- [blog] - BPTT为什么会导致RNN梯度爆炸和消失; 循环神经网络的BPTT算法步骤整理,梯度消失与梯度爆炸;
- [blog] - 反向3; 反向4; 反向5; 反向6; 反向7; 反向8; bp反向; 反向9

 浙公网安备 33010602011771号
浙公网安备 33010602011771号