Spark SQL 及其DataFrame的基本操作
1.Spark SQL出现的 原因是什么?
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个叫作Data Frame的编程抽象结构数据模型(即带有Schema信息的RDD),Spark SQL作为分布式SQL查询引擎,让用户可以通过SQL、DataFrame API和Dataset API三种方式实现对结构化数据的处理。但无论是哪种API或者是编程语言,都是基于同样的执行引擎,因此可以在不同的API之间随意切换。
Spark SQL的前身是 Shark,Shark最初是美国加州大学伯克利分校的实验室开发的Spark生态系统的组件之一,它运行在Spark系统之上,Shark重用了Hive的工作机制,并直接继承了Hive的各个组件, Shark将SQL语句的转换从MapReduce作业替换成了Spark作业,虽然这样提高了计算效率,但由于 Shark过于依赖Hive,因此在版本迭代时很难添加新的优化策略,从而限制了Spak的发展,在2014年,伯克利实验室停止了对Shark的维护,转向Spark SQL的开发。
2.用spark.read 创建DataFrame
Spark SQL DataFrame的基本操作
1.创建:spark.read.text() ;spark.read.json()
file='file:///D:/Spark/spark-2.4.7-bin-hadoop2.7/examples/src/main/resources/people.txt' df = spark.read.text(file)
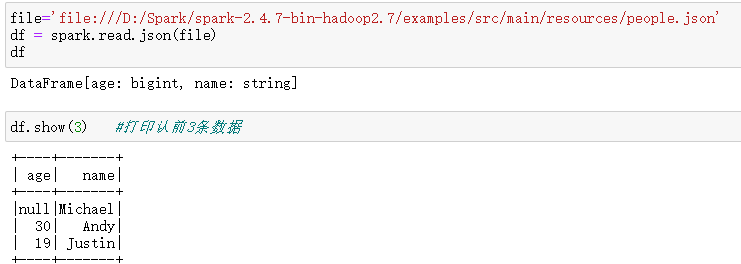
file='file:///D:/Spark/spark-2.4.7-bin-hadoop2.7/examples/src/main/resources/people.json' df = spark.read.json(file)
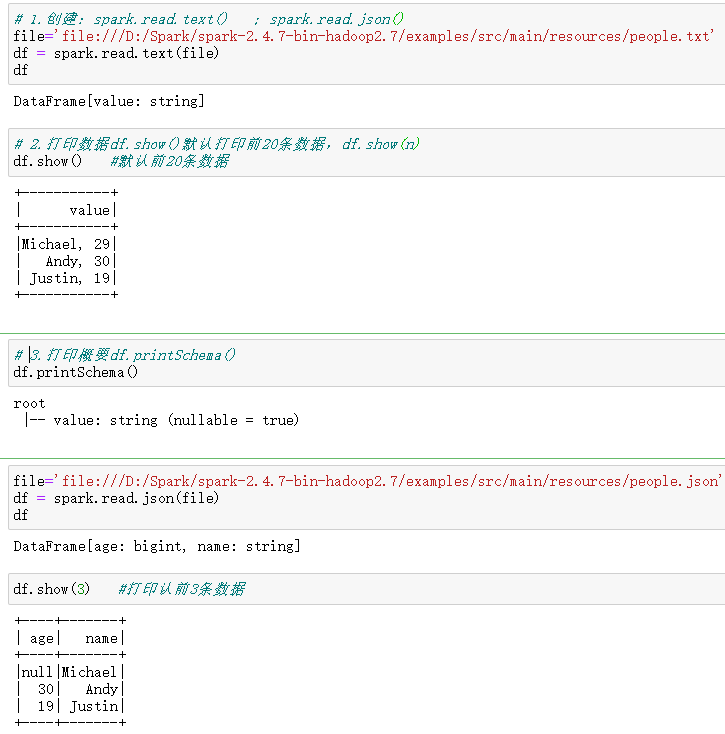
2.打印数据df.show()默认打印前20条数据,df.show(n)
3.打印概要df.printSchema()

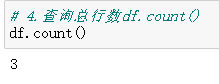
4.查询总行数df.count()
5.df.head(3) #list类型,list中每个元素是Row类

6.输出全部行 df.collect() #list类型,list中每个元素是Row类

7.查询概况 df.describe().show()

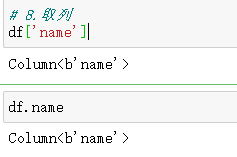
8.取列
df[‘name’]
df.name
df.select()

df.filter()

df.groupBy()

df.sort()

3.观察从不同类型文件创建DataFrame有什么异同?
spark.read操作
| 代码示例 | 描述 |
|---|---|
| spark.read.text("people.txt") | 读取txt格式的文本文件,创建DataFrame |
| spark.read.csv ("people.csv") | 读取csv格式的文本文件,创建DataFrame |
| spark.read.json("people.json") | 读取json格式的文本文件,创建DataFrame |
| spark.read.parquet("people.parquet") | 读取parquet格式的文本文件,创建DataFrame |
txt文件:创建的DataFrame数据没有结构
json文件:创建的DataFrame数据有结构
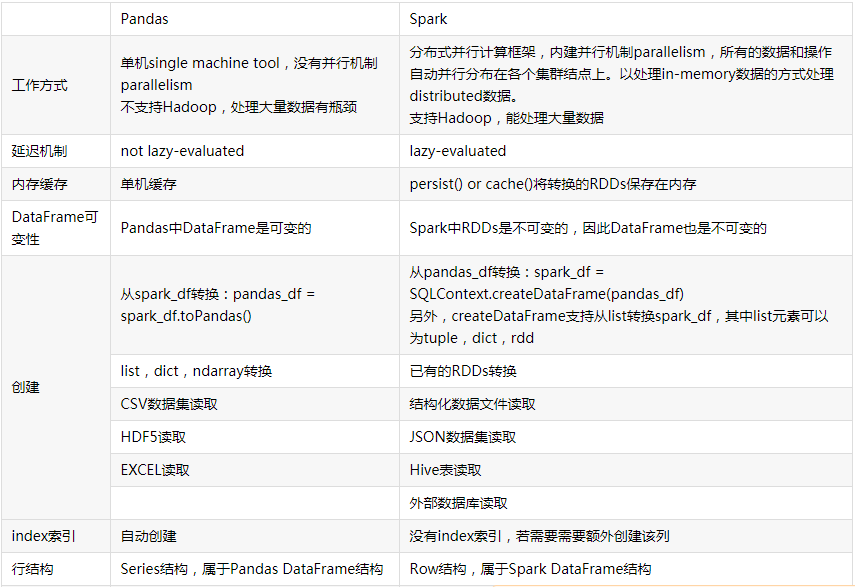
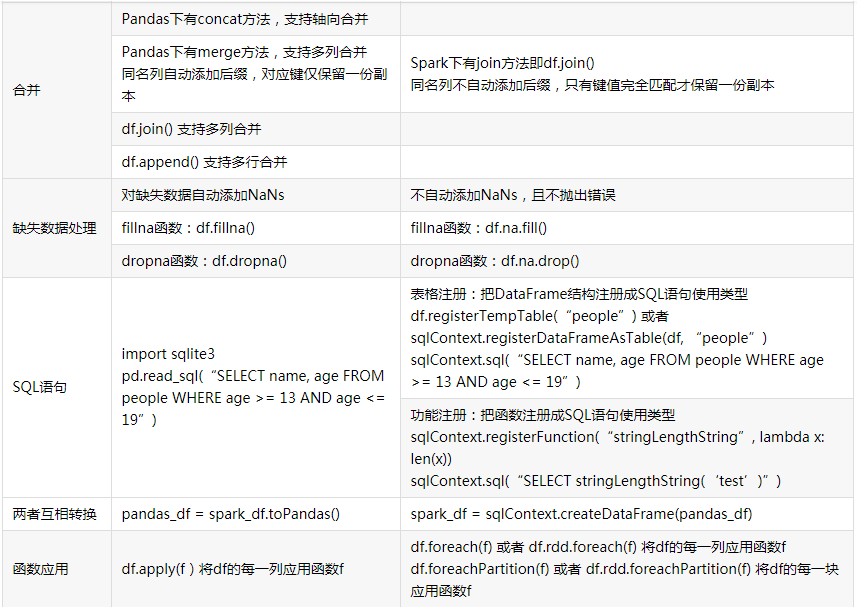
4.观察Spark的DataFrame与Python pandas的DataFrame有什么异同?




 浙公网安备 33010602011771号
浙公网安备 33010602011771号