垃圾回收站——python爬虫(一)
引言:
爬虫,即请求网页,根据自己所需的数据进行抓取,并且对抓取的数据进行处理从而提取有价值的信息
为什么选择Python?
不止 python 一种语言可以爬虫,像 C/C++, Java, PHP 等都可以用来写爬虫的程序,但是 Python的优势更大:Python 的代码简洁,开发效率高,并且支持多种爬虫模块等,使得编写爬虫程序更简单。
”盗亦有道“——Robots协议
作为”大盗“想抓取网络上面的数据,也要遵守“大盗的君子协议”
几乎每一个网站都有一个 robots.txt 的文档,网站通过 Robots 协议说明哪些页面可以抓取,哪些页面不能抓取。它是国际互联网界通行的道德规范,虽然没有写入法律,但是每一个爬虫都应该遵守这项协议。
robots协议本身也只是一个业内的约定,是不具有法律意义的,所以遵不遵守呢也只能取决于用户本身的底线了。
以淘宝为例,访问淘宝的 Robots 协议:https://www.taobao.com/robots.txt
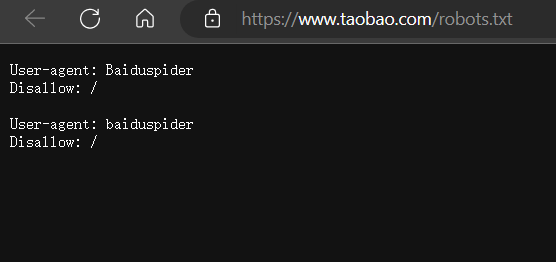
User-agent: Baiduspider
Disallow: /
这一句代码的意思是除前面指定的爬虫外,不允许其他爬虫爬取任何数据。
准备:
软件安装:
(后面的教程也是使用的这两个软件进行的,如果用的其他软件可能会有部分不同)


首先我们需要安装 Python ,直接下载最新版即可(可能需要挂**FQ才能进入网页)
https://www.python.org/downloads/
其次我们需要一个运行Python的环境,我用的是 PyChram
https://www.jetbrains.com/pycharm/download/#section=windows
这里附带 Pycharm 破解方法(仅用于学习)
https://www.exception.site/article/35
添加库:
根据需求添加第三方库,这里我们只添加 请求库 和 解析库
请求库:requests
解析库:bs4,BueatifulSoup4,lxml
另外:xlwt(用于制作 excel 表)
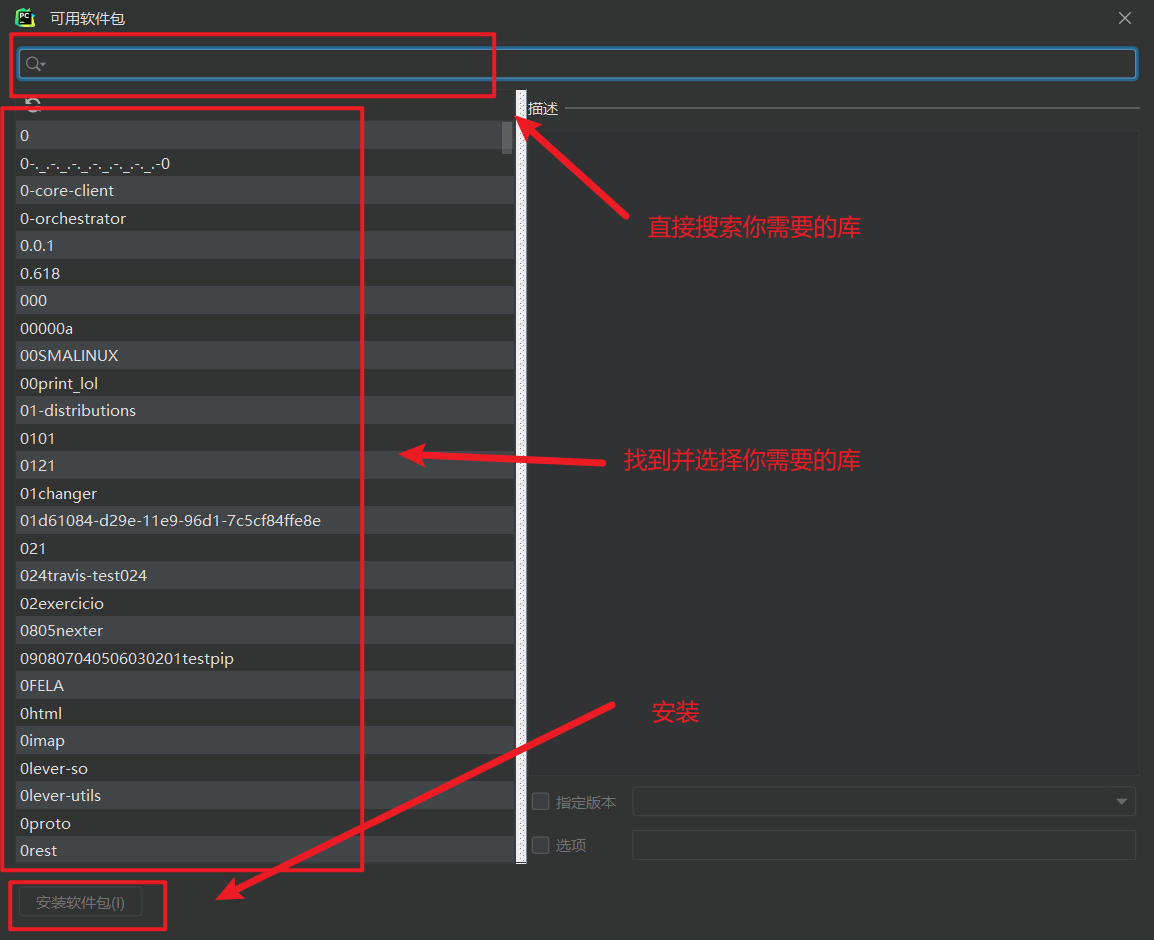
- 打开你的设置( File -> Settings )
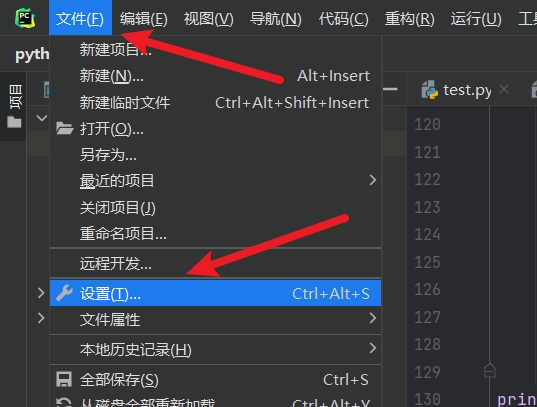
- 找到你的 Python 解释器( Project Interpreter )
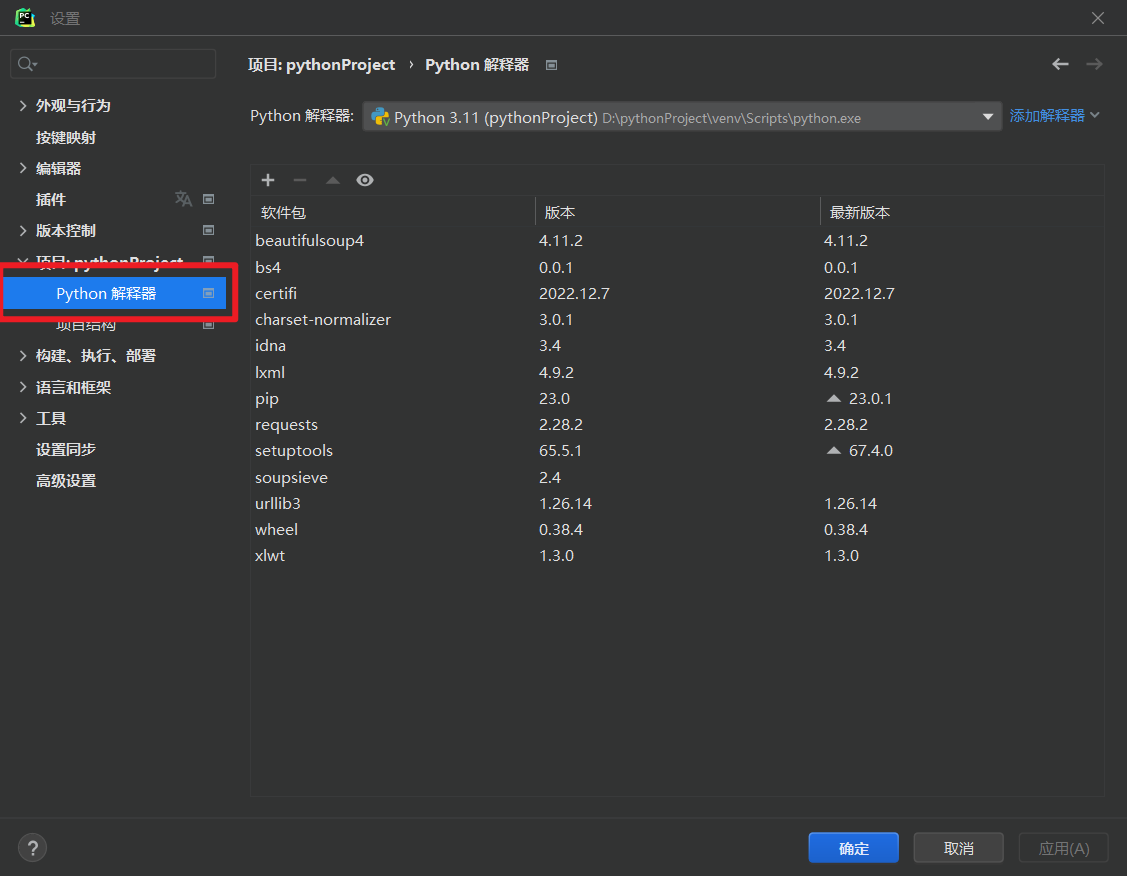
- 添加需要的库
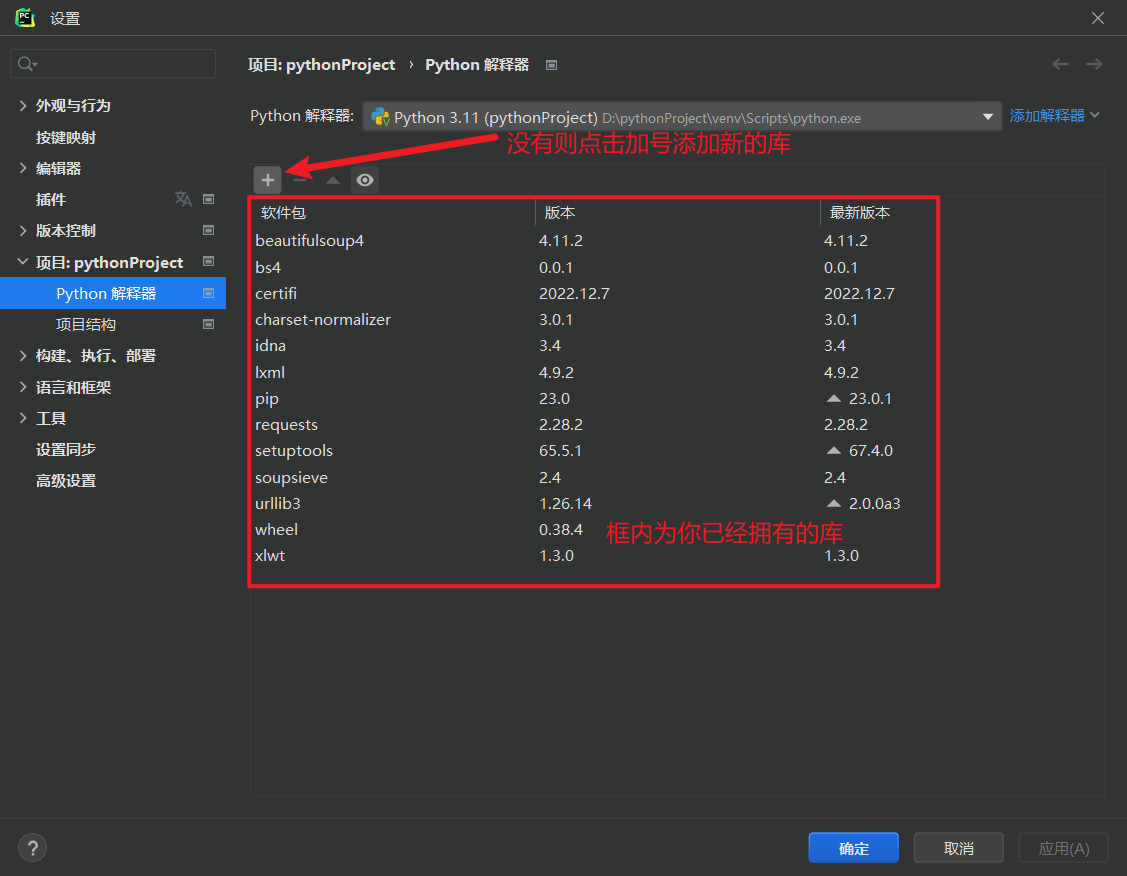
干货:
以下我们来爬取 4399 网页的所有图片
导入你的库
下面的教程用到的就是这几个库,如果有更多需求可以自行导入其他的库
os 和 random 是自带的库所以不需要在设置里面添加

获取网站html信息
向 4399(https://www.4399.com/) 发起请求,获取首页的HTML信息
url = 'https://www.4399.com/'
html = requests.get(url)
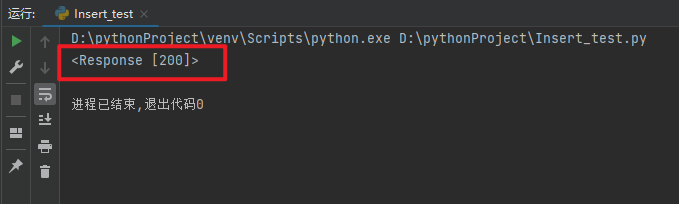
为了检验以下我们是否请求成功,打印一下 html 查看是否成功
print(html) # 查看请求状态是否成功
print(html.text) # 查看网页的代码
状态码 200 即为请求成功
重构 User-Agent
对于大部分网站我们都需要 标明我们的身份 ,某些网站为了防止服务器崩溃等具备一定的反爬能力,网站通过 识别请求头(headers)中的 User-Agent 信息 来判断是否是爬虫访问网站,如果是,网站首先对该 IP 进行预警,对其进行重点监控,当发现该 IP 超过规定时间内的访问次数, 将在一段时间内禁止其再次访问网站。
所以为了防止这种情况,我们会 重构 User-Agent ,将其伪装成“浏览器”访问网站。
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763'}
url = 'https://www.4399.com/'
html = requests.get(url,,headers = header)
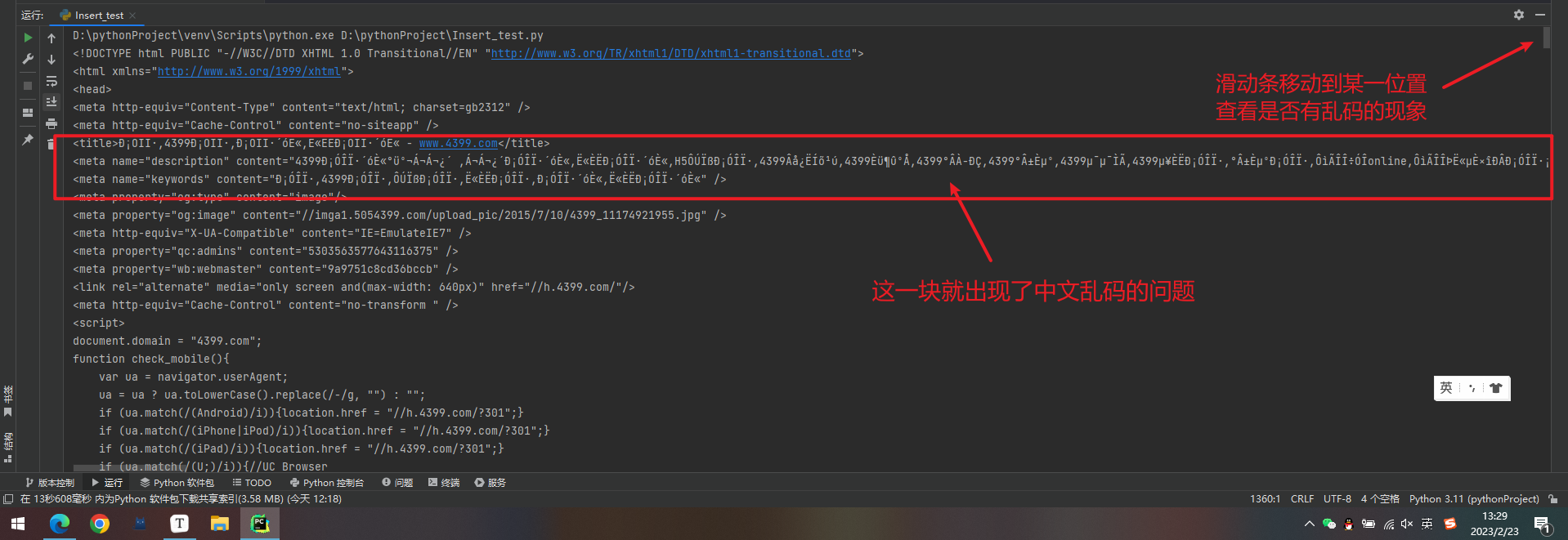
对于不同的网站会有不同的编码,获取的 html 信息一般默认是编译器的编码,如果编码不同会出现中文乱码的问题
这里我们直接打印一下 html 的网页代码进行查看
print(html.text) # 查看网页的代码
检测乱码问题
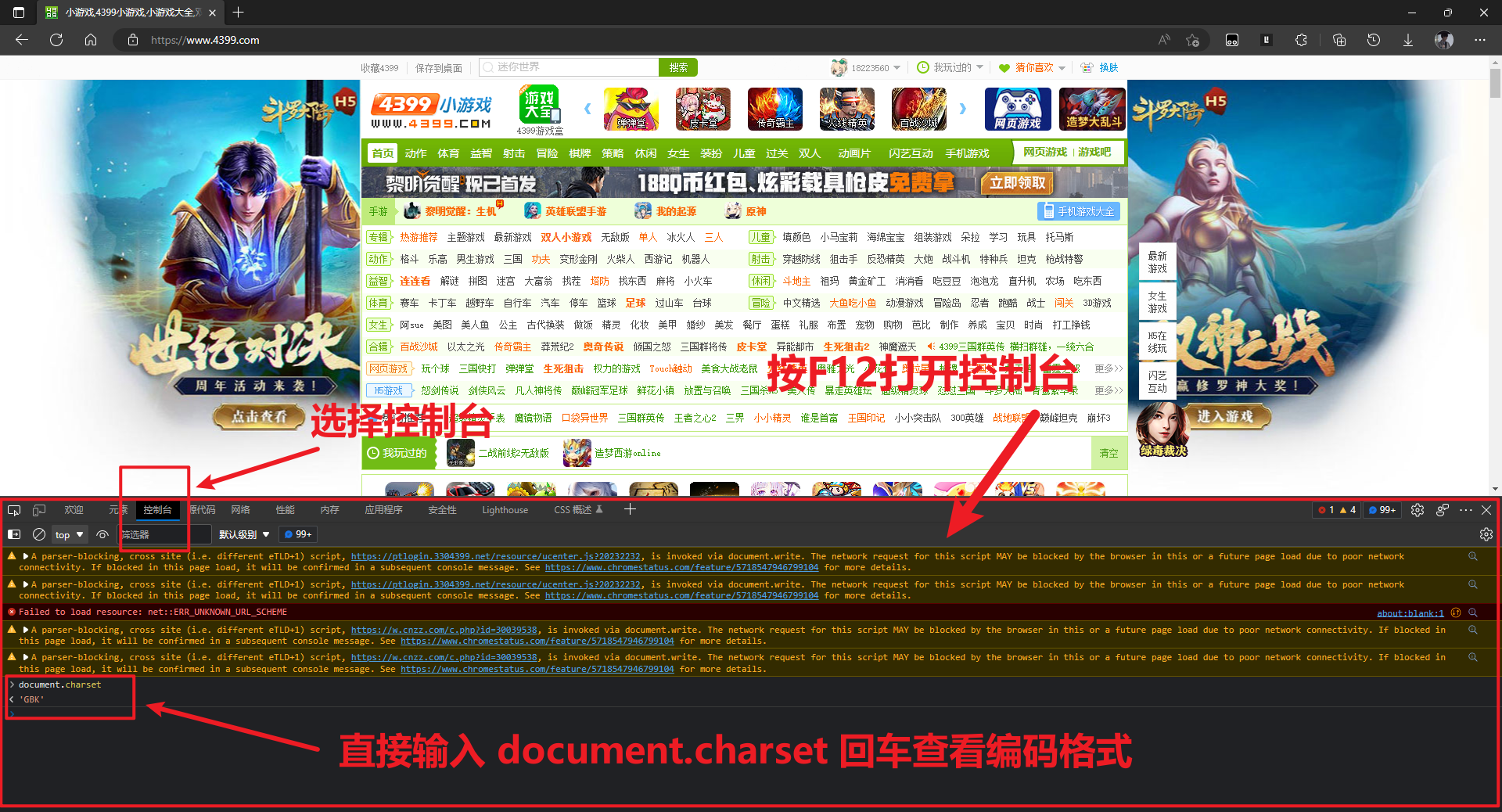
如果每次获取 html 信息都要打印一次查看是否乱码过于繁琐,不如直接查看网站的编码格式
按 F12 打开网站的开发者模式,选择控制台,输入 document.charset 查看编码格式,这里显示4399网页的编码格式为 gbk
然后需要在的代码中 更改编码格式为网站的编码格式 以防止乱码问题,再次打印检查是否存在乱码
html = requests.get(url,headers = header)
html.encoding = 'gbk' # 中文乱码转换编码为gbk
print(html.text)
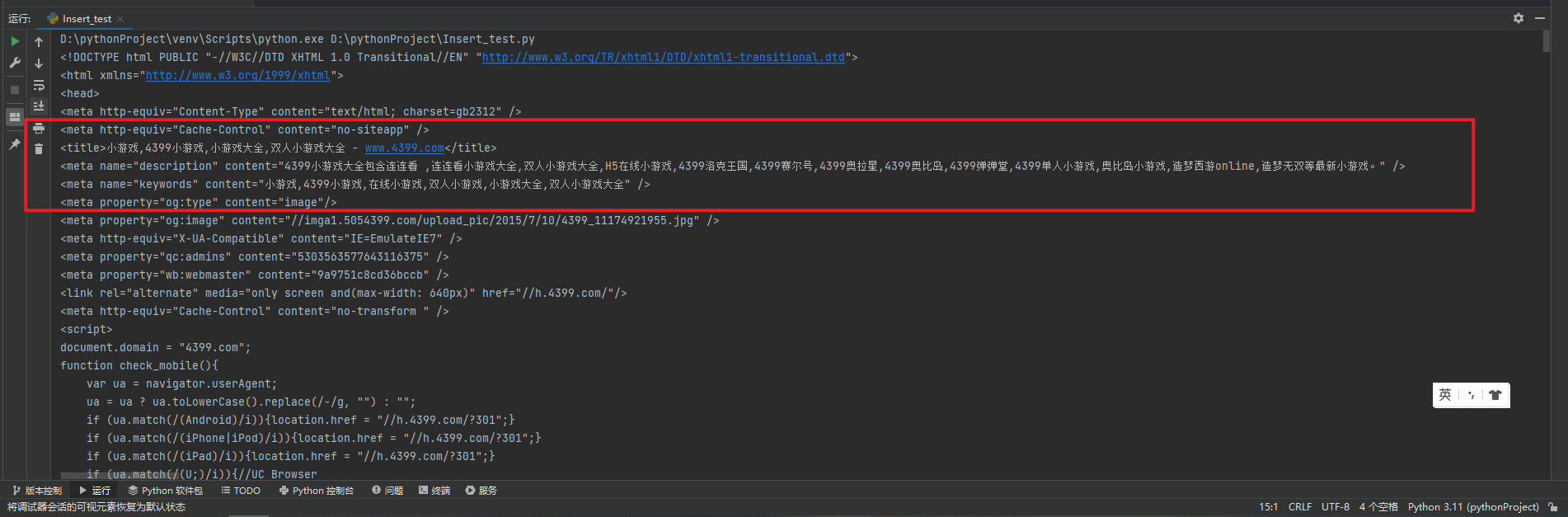
乱码问题已经成功处理。
解析网页获取数据
首先用 BeautifulSoup 解析网页
soup = BeautifulSoup(html.text, 'lxml') # 选用lxml解析器来解析网页代码
解析后我们用网页的开发者模式定位到我们需要爬取的数据位置
这里我选择爬取4399网页中最新好玩小游戏列表中的所有图片
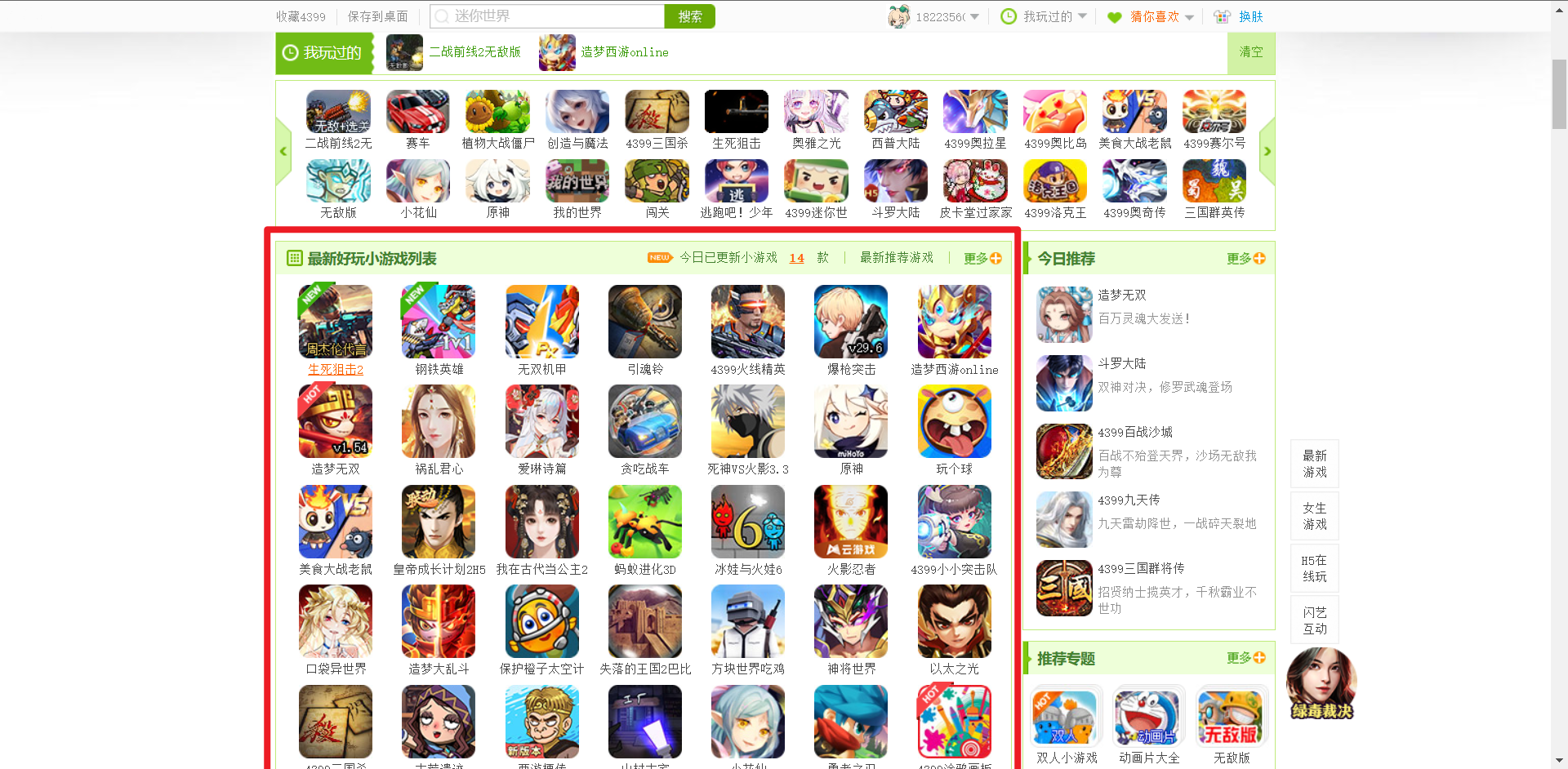
用开发者工具定位到网页图片的位置
- F12打开控制台,选择 元素(element) 标签查看页面代码;
- 点击控制台左上角箭头,然后点击页面上我们需要的信息,我们可以看到控制台中页面代码直接跳转到对应的位置;
- 页面代码中一直向上选择标签直至囊括我们需要的所有信息;
- 记住此时的标签以及熟悉等信息,这将会用于后面解析筛选数据。
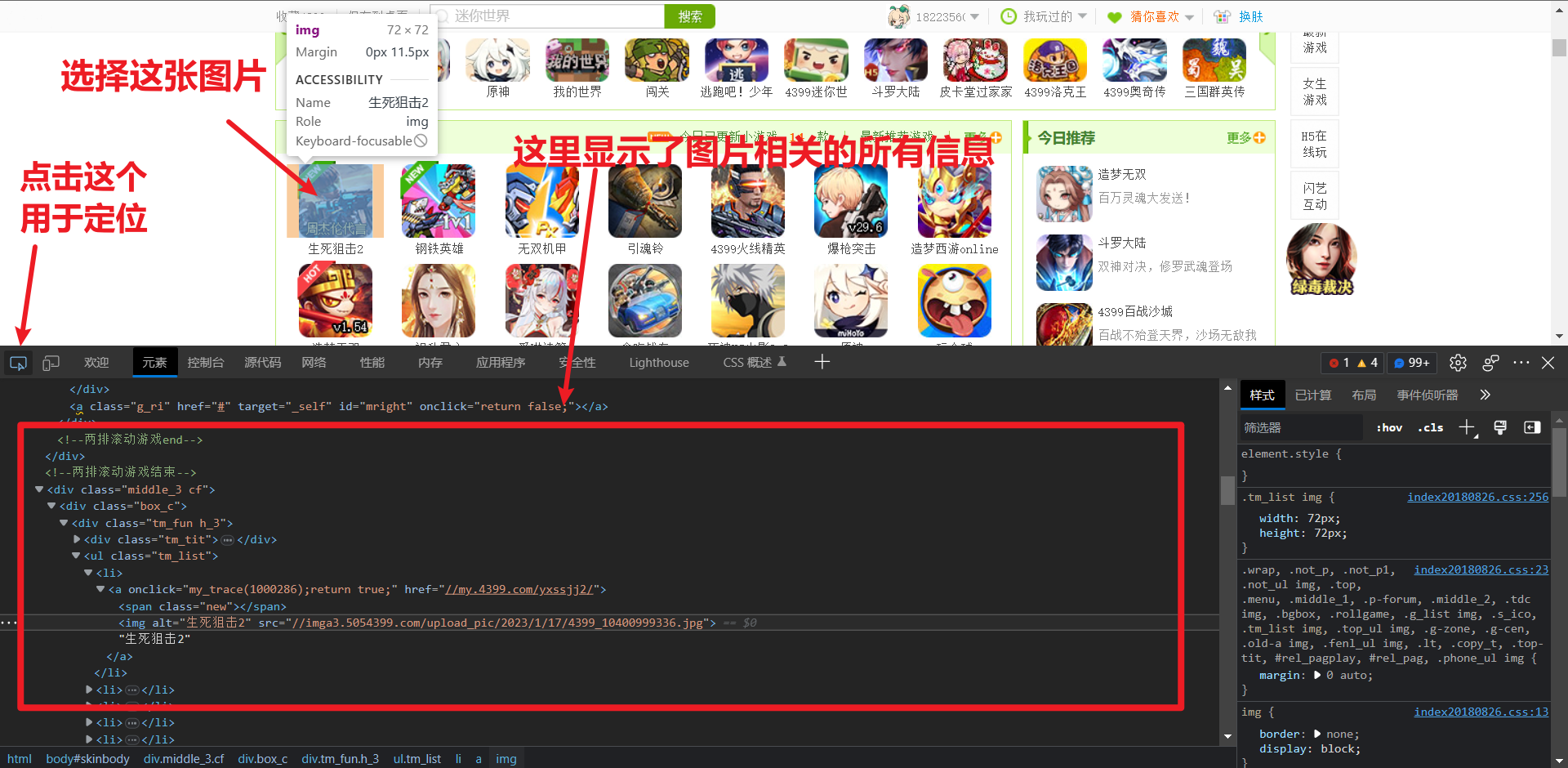
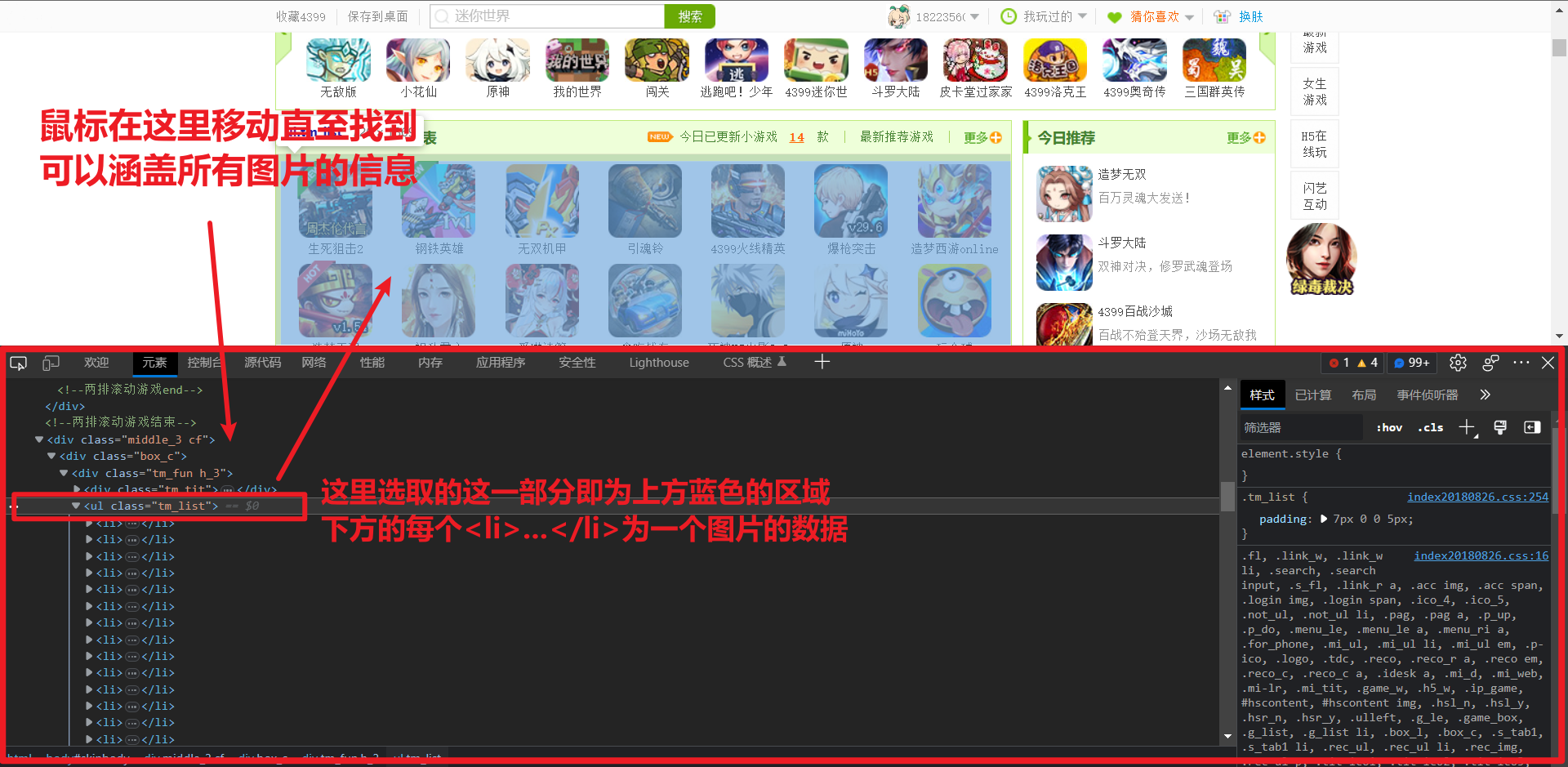
找到了这个区域范围后记住这一行代码的信息 <ul class="tm_list"></ul>
同时也留存上一级的信息以获取更准确的信息 <div class="tm_fun h_3"></div>
通过这一行信息我们利用 BeautifulSoup 来获取这一区域从而获得所有的图片
box_c = soup.find_all('div', attrs={'class': 'tm_fun h_3'})
pic_list = box_c[0].find_all('ul', attrs={'class': 'tm_list'})
关于在第二次查找信息时的 box_c[0] 使用了 [0]:
find_all 函数 返回的是一个列表 ,即此时 box_c 是一个列表,打印一下 box_c 时查看并没有发现有列表的符号[],因为查找到的这一区域的代码全储存在了 box_c[0] 中
而 列表对象是不能使用 find_all 函数 ,所以这里是对 box_c[0] 进行继续查找信息
同样可以打印一下 pic_list 查看获取信息是否正确,这里已经验证是获取了正确信息就不进行展示了
正则表达式
正则表达式(regular expression)是一种字符串匹配模式或者规则,它可以用来检索、替换那些符合特定规则的文本
在使用 Python 编写爬虫的过程中,re 模块通常做为一种解析方法来使用。通过审查网页元素来获取网页的大体结构,然后使用解析模块来提取你想要的网页信息,最终实现数据的抓取。
具体如何使用需要花时间学习,这个比较耗费时间
使用正则表达式的库 import re
通过正则表达式准确获取到 pic_list 中的所有图片 url
Img = re.compile(r'src="(.*?)"')
这里提供一个菜鸟教程的测试工具,可以检测你的正则表达式是否能提取相应信息
https://www.runoob.com/regexp/regexp-syntax.html

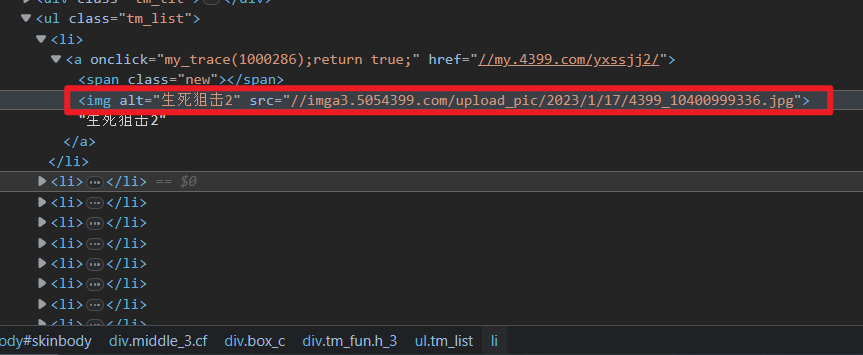
这里的正则表达式获取的信息和实际获取的信息有一定差距
所以创建了正则表达式之后最好还是打印出结果检验是否正确
获取图片url
img = [] # 创建列表存储所有的图片url
for pic in pic_list:
pic = str(pic) # 正则表达式必须使用字符串,所以需要强制转换成字符串
img = re.findall(Img, pic) # 通过正则表达式找到所有图片的 url
# 图片的 url 全部都缺少了 http: 所以需要循环给所有的图片添加上去
for i in range(len(img)):
img[i] = 'http:' + img[i]
print(img[i]) # 检验 img 获取到的图片 url 是否正确
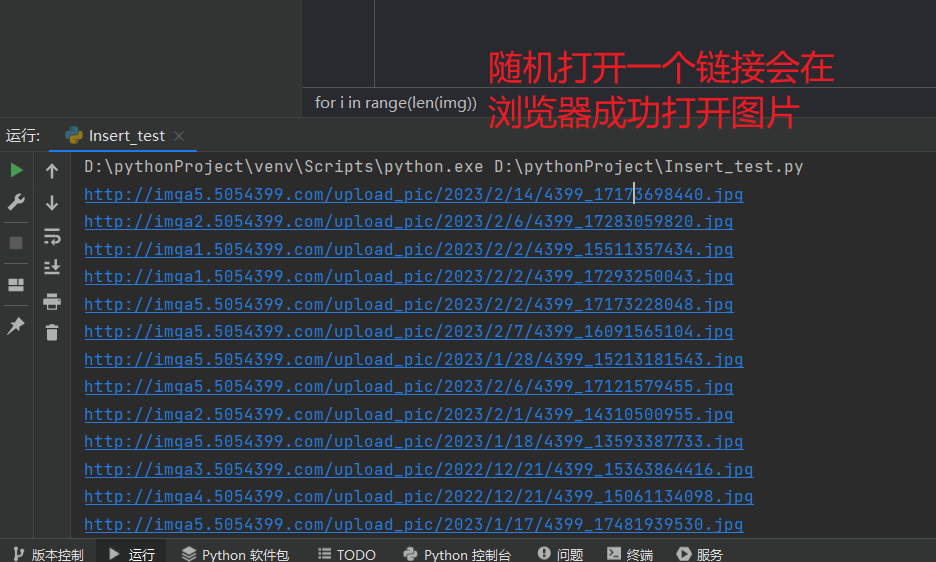
下载图片
创建文件夹
下载图片我们需要用到文件操作,用到 os 库 import os
os.path.exists() # 检测是存在文件
os.mkdir() # 创建文件
选择一个地址作为我们图片保存的文件夹位置,os 库 可以直接创建一个新的文件夹,所以这里选择直接用代码在指定位置创建文件夹用于存储图片
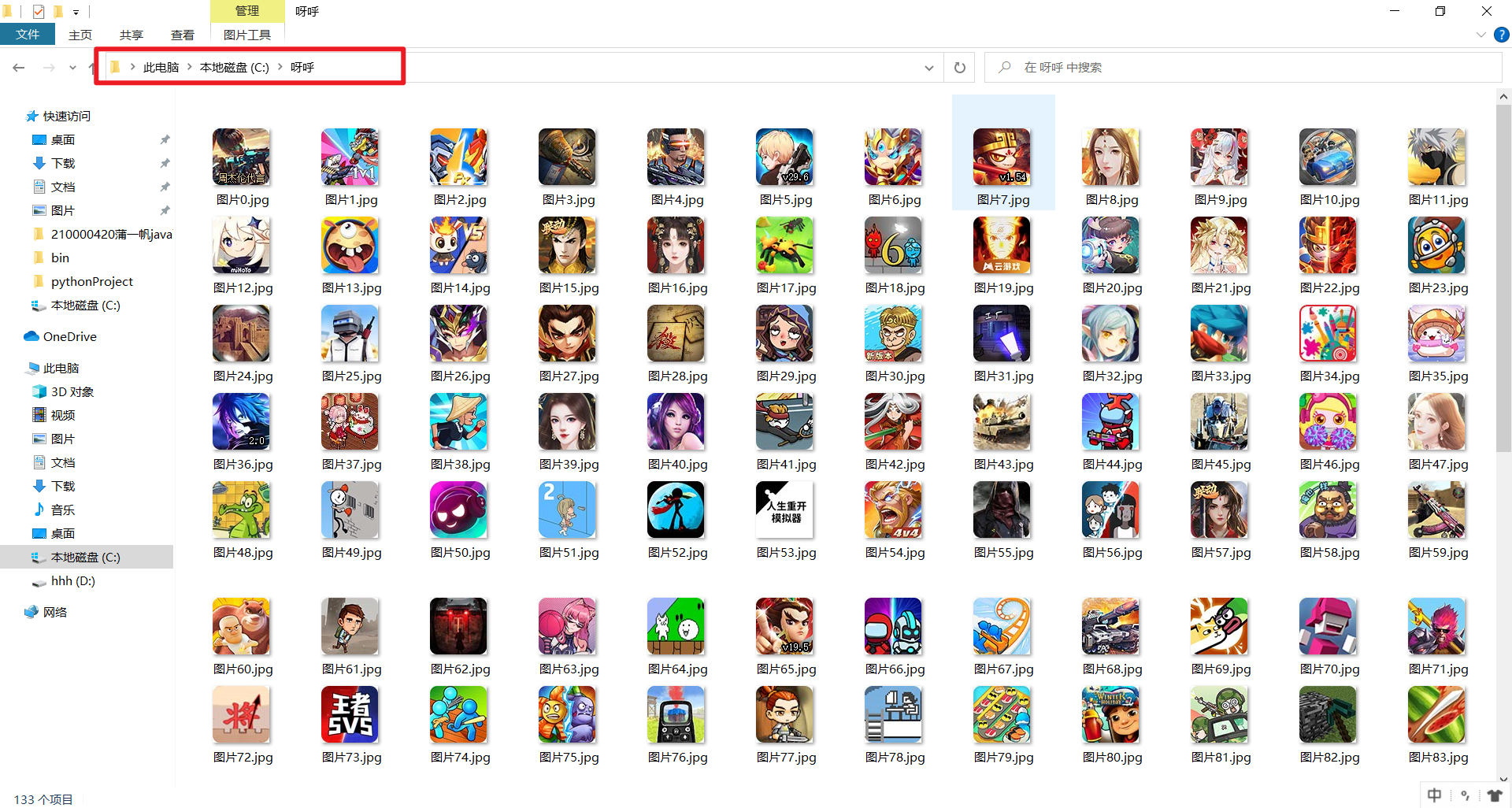
space = 'C:/呀呼' # 在c盘定义一个名为 呀呼 的文件夹
if not os.path.exists(space): # 检测是否c盘已经存在此文件夹,如果不存在则创建一个
os.mkdir(space) # 创建文件夹位置和名称即为 space 所代表的字符串
存储图片
img 中我们已经获取了所有图片的 url, 但是要下载图片同样需要请求
我们通过循环逐一下载所有的图片
并且每下载一张图片我们打印一条信息提示下载成功
创建一个整型的 x 来表示执行到第几张图了,同时我们可以用 x 来给图片命名
x = 0
# 循环 img列表 中的所有 url
for picture in img:
# 对每个 url 进行发送请求
picture = requests.get(picture)
# 对读写文件时使用 with ,在读写完毕后会自动关闭文件
# 每次都打开一个缓存文件,准备下载图片
# {} 是用后面的format(x) 代替,每次循环 x 都在增加,则图片的名称依次为图片1,图片2...
# 用 fp 来暂时作为打开的缓存文件,然后进行读写操作下载图片
with open(r"C:/呀呼/图片{}.jpg".format(x), 'wb') as fp:
fp.write(picture.content)
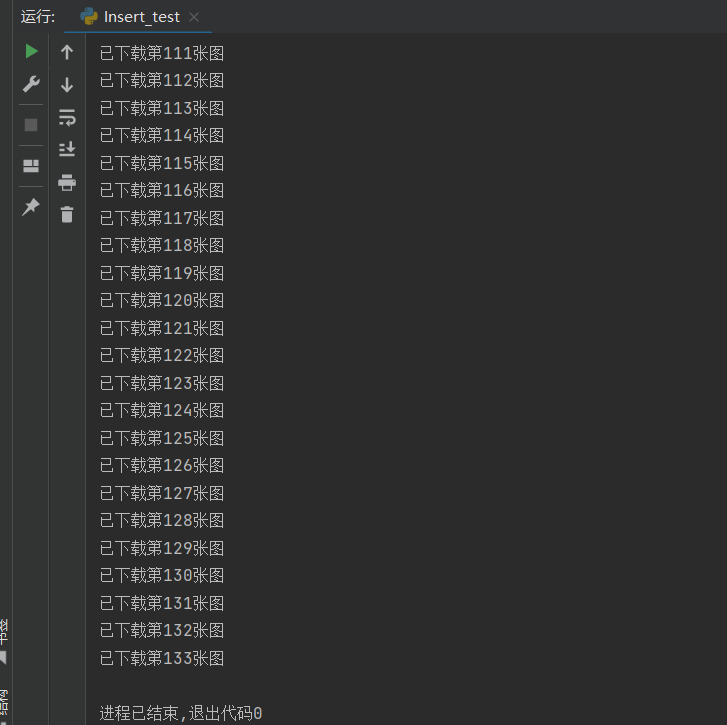
x+=1
print("已下载第%d张图" % x)
到这里我们就已经写完了所有的代码,完整代码见下:
import os
import re
import requests
from bs4 import BeautifulSoup
Img = re.compile(r'img.*src="(.*?)"')
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
' (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763'}
url = 'https://www.4399.com/'
html = requests.get(url, headers=header)
html.encoding = 'gbk' # 中文乱码转换编码为gbk
soup = BeautifulSoup(html.text, 'lxml')
box_c = soup.find_all('div', attrs={'class': 'tm_fun h_3'})
pic_list = box_c[0].find_all('ul', attrs={'class': 'tm_list'})
img = []
for pic in pic_list:
pic = str(pic)
img = re.findall(Img, pic)
for i in range(len(img)):
img[i] = 'http:' + img[i]
space = 'C:/呀呼'
if not os.path.exists(space):
os.mkdir(space)
x = 0
for picture in img:
picture = requests.get(picture, headers=header)
with open(r"C:/呀呼/图片{}.jpg".format(x), 'wb') as fp:
fp.write(picture.content)
x+=1
print("已下载第%d张图" % x)
运行一下查看结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号