
动态计算分配(Dynamic Compute Allocation)技术:MoD
在语言建模中,并非所有的tokens和序列都需要相同的时间或努力来准确地进行预测。然而transformer在前向传递(forward pass)中对每个token消耗相同数量的计算资源。理想情况下,transformer应通过不必要地消耗计算资源来使用更小的总计算预算。
条件计算(Conditional computation)是一种试图通过仅在需要时消耗计算资源来减少总计算量的技术。不同的算法提供了何时以及应使用多少计算资源的解决方案。然而,这个挑战性问题的一般性公式可能无法很好地适应现有的硬件限制,因为它们倾向于引入动态计算图。最有前途的条件计算方法可能是那些与当前硬件堆栈协调一致的方法,这些硬件堆栈优先考虑静态计算图和已知张量大小,这些大小被选中是为了最大化硬件利用率。
作者们考虑了使用静态计算预算进行语言建模的问题,该预算可以比传统transformer使用的计算预算少。网络必须学会如何通过在每个layer对每个token做出决策来动态分配可用的计算资源,决定从可用预算中在哪里消耗计算资源。在其实现中,总计算是用户定义的,并且在训练前是不变的,而不是网络即兴决策的函数。因此,可以提前预期并利用硬件效率提升,例如减少内存占用或每次前向传递减少FLOPs。正如作者将展示的那样,这些收益可以在不牺牲整体性能的情况下获得。
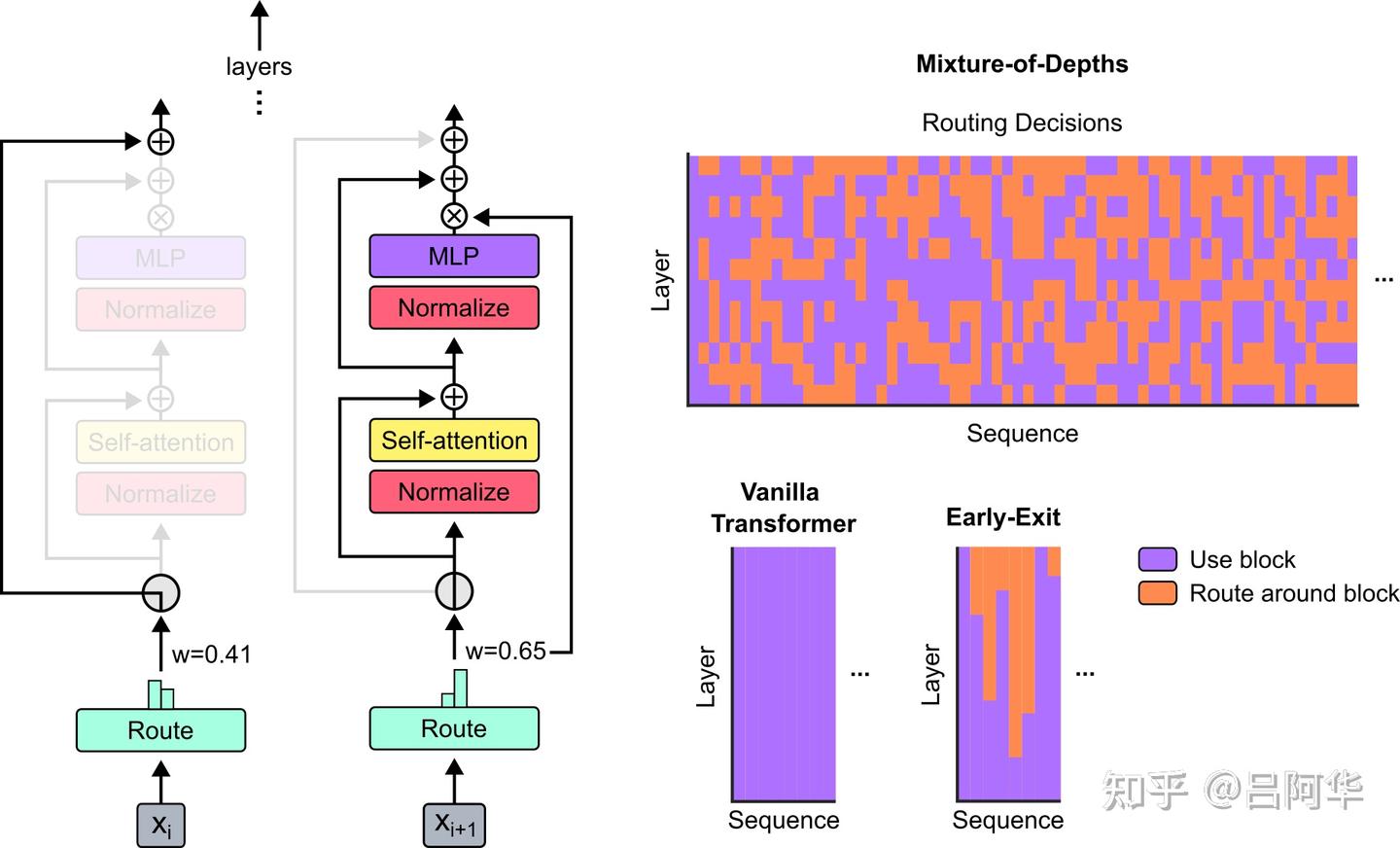
作者利用了类似于混合专家(Mixture of Experts,MoE) transformer的方法,其中在网络深度上进行动态的token级别的路由决策。与MoE不同的是,作者选择要么对一个token应用计算(如标准变换器的情况),要么通过残差连接(Residual Connection)传递它(保持不变并节省计算资源)。与MoE相反,作者将这种路由策略应用于前向多层感知机(Multi-Layer Perceptron, MLP)和多头注意力(Multi-head Attention)。由于这也影响了我们处理的key和query,路由不仅决定了更新哪些token,还决定了哪些token可以被关注。作者将这种策略称为混合深度(Mixture-of-Depths,MoD)。
作者还提到,MoD技术还允许在性能和速度之间进行权衡。一方面,可以训练一个MoD transformer在最终的对数概率训练目标上比普通transformer提高1.5%,并且训练所需的挂钟时间(wall-clock time)相当。另一方面,可以将一个MoD transformer训练达到与isoFLOP最佳的传统transformer相同的训练损失,但每次前向传递使用的FLOPs少得多(高达50%)。这些结果表明,MoD transformer学会了智能路由策略(即跳过不必要的计算),因为它们可以在每次前向传递的FLOPs足迹较小的情况下,实现相同或更好的序列对数概率。
*本文只摘译精华部分,需要了解全文的请至文末跳转至原文链接阅读。
*楼主会用GPTs翻译形成初稿,然后自己精读后完成终稿,力求每一句话自己都能理解后再输出译文。实现Mixture-of-Depths Transformers
MoD Transformer的顶层设计策略包含三个步骤:
- 设置静态计算预算:这个计算预算低于等效的传统transformer,通过限制在序列中可以参与一个块计算的token数量(即自注意力和随后的MLP)来实现。例如,虽然传统transformer可能允许序列中的所有token参与自注意力,但在这种方法中可能会将可参与数量限制为序列中token数量的50%。
- 使用每个模块的路由器:利用每个模块的路由机制为每个token分配一个标量权重,以此来表明路由对于该token参与模块计算还是绕过计算的偏好。
- 识别top-k个标量权重:根据标量权重选择前 个token参与到模块的计算中。由于确切的 个token会参与计算,这保证了在整个训练过程中计算图和张量的大小保持不变;只有token的参与是动态的,并且对上下文敏感,这一点由路由机制决定。
定义计算预算
为了在每个前向传递中强制实施总体计算预算,作者采用了“容量(capacity)”的概念。这里的“容量”指的是构成特定计算输入的token的总数,例如,参与自我关注机制(self-attention)的token,或者MoE transformers中某个特定专家处理的token等。例如,在每个标准transformer模块中,自我关注机制和MLP的处理容量为 𝑇 ,即序列与批处理中所有token的总数。相比之下,MoE transformers对每个专家的多层感知机(MLP)设定的容量小于 𝑇 ,这样做是为了更平均地分配各个专家的计算总量。但是,因为它们在每个模块中使用了多个专家,所以它们的总容量大致相当于一个标准transformer。
一般来说,是token的“容量”决定了采用条件计算的transformers的总浮点运算数,而不是任何路由决策的结果。这是因为静态图实现会考虑到最坏情况;例如,即使实际上只有少数token被路由到某个计算中,该计算的输入也会被填充到其最大容量,如果超出容量,超出部分的token将被排除在计算之外。
用户可以通过降低计算的“容量”来实现每次前向传递比标准transformer更少的计算预算。然而,如果不加选择地减少计算预算,可能会导致性能恶化。作者认为,某些token可能不需要像其他token那样多的处理,这些token可以通过学习过程被识别出来。因此,如果网络能够学习选取合适的token以充分利用其“容量”,则有可能保持其性能不变。下面将介绍可以为此目的而使用的路由机制。
围绕transformer模块进行路由
设想了这样一个场景,即将token按两种不同的计算路径进行分流:一种是自我关注机制和多层感知机(MLP)的组合,另一种则是使用残差连接。后者的计算成本相对较低,其输出完全取决于输入的值。而前者的计算开销则相对较大。
如果把走向自我关注机制和MLP的路径的容量设置为低于 𝑇 (即整个序列和批处理中token的总数),那么每次前向传递的浮点运算次数将低于标准transformer模型。举个例子,如果把一个模块的容量设置为 𝑇 的一半,那么自我关注过程中的查询-键矩阵乘法的计算密集度将只有标准transformer的25%。对MLP的节能效果也可以通过类似的计算来确定。
直观上看,每次前向传递的总浮点运算次数及其所需时间会随着对模块容量进行缩减的决心而降低。然而缩减模块容量的决心以及所采用的路由策略同样会影响到模型的下游表现。在一个极端情况下,如果将每个模块的容量保持在 𝑇 ,并将所有token都路由至模块内部,而不是绕过去,那么就会得到了一个标准transformer模型。在另一个极端情况下,如果将每个模块的容量设置为0,并让所有token绕过这些模块,那就会得到了一个运行速度非常快但几乎不使用transformer大部分参数的模型,其下游性能无疑会很差。作者认为介于这两个极端之间存在一个最优模型,它比标准的Transformer速度更快,且在性能上至少持平。
路由机制
可以通过引入随机性来实现token的路由分配,这有点类似于在网络层或模块中应用“dropout”技术。作者将这种初步的路由策略作为一个基准来进行比较,并发现其性能明显低于标准的transformer模型。
作者认为采用经过学习的路由策略会更为合适。从直观上讲,网络应能够识别哪些token需要进行更多或更少的处理。如果Transformer模型往往使用了超出预测所需的计算资源这个观点成立,那就可以积极减少每个模块的处理容量,并据此决定可以绕过每个模块的token数量。
作者考虑了两种经过学习的路由策略(参见图2):基于token的选择和基于专家的选择。在基于token的选择路由中,路由器为每个token生成一个概率分布,决定它们分配到不同计算路径的可能性(例如,在MoE Transformers中,是分配到不同的专家身份)。然后,根据最高概率,token被分配到它们偏好的路径,同时通过辅助损失来确保所有token不会全部聚集到同一路径。基于token的选择可能会遇到负载不均衡的问题,因为它无法确保token在可能的路径之间恰当分配。“基于专家的选择”则是另一种思路:不是让token选择它们偏好的路径,而是每条路径根据token的偏好来选择它们的top-k token。这种方法可以确保完美的负载平衡,因为每条路径都会确保有 个token被分配给它。然而这可能会导致某些token被处理过度或处理不足,因为有些token可能会成为多条路径的top-k选择,或者完全不被任何路径选择。
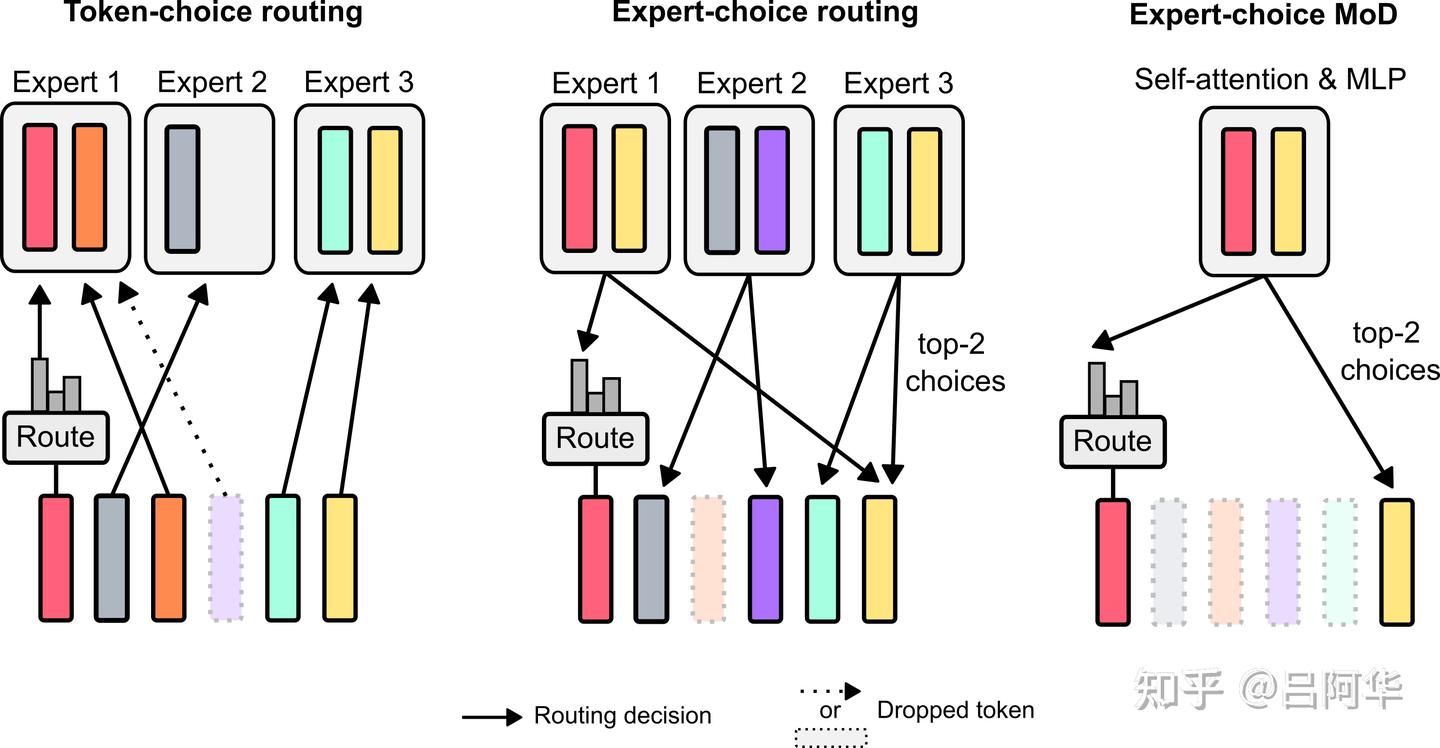
作者最终选择了基于专家的选择路由策略有几个原因。首先,它无需辅助的平衡损失;其次,因为top-k操作基于路由器权重的大小,这种路由机制允许利用相对权重来判断哪些token最需要进行处理;通过适当设置权重,路由器可以确保最关键的token被优先处理,这是基于token选择的路由策略无法实现的。对于特定场景,其中一条计算路径基本上不进行任何操作,确保重要的token不会被分配到这种无操作路径上至关重要。第三,由于我们的路由只涉及两条路径,一个单独的top-k操作就能有效地将token分配到两个互不重叠的集合中,每个集合对应一条计算路径,从而避免了前述的过度或不足处理的问题。
路由实现
作为高层次的直觉提醒,每个token都经过一个路由器进行处理,产生一个标量权重,然后使用top-k权重来选择将通过transformer块的token标识,该块包括自注意力和随后的MLP。
假设对于给定层 𝑙 ,有长度为 𝑆 的序列中的一组token向量,即 𝑋𝑙 ={ 𝑥𝑖𝑙 | 𝑖 是整数, 1≤𝑖≤𝑆 }。给定token向量的路由器权重是通过线性投影产生的标量, 𝑟𝑖𝑙=𝑤θ𝑇∗𝑥𝑖𝑙 。
我们的目标是使用这些路由器权重来确定每个token的块计算的输出。假设 𝑃β(𝑅𝑙) 是路由器权重Rl的第 β 个百分位数,其中 β=1−𝐶/𝑆 , 𝐶 是用户定义的每批元素的容量(一个小于 𝑆 的整数,定义了将由给定函数处理的序列中的token数量)。对于给定token的块输出为:
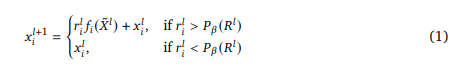
这里, 𝑥~𝑙 是路由器值 𝑟𝑖𝑙>𝑃β(𝑅𝑙) (即“top-k” token)的token集合, 𝑓 包括自注意力和随后的MLP。注意,对于给定的token 𝑥𝑖𝑙+1 的输出可能会依赖于其他token 𝑥𝑖≠𝑗𝑙 ,因为存在自注意力操作。 𝑥~𝑙 的基数是 𝐶 (或 𝑘 ):用户定义的容量。因此,与基线相比,混合深度transformer在块的计算中的输入f包含的token数量较少( 𝐶<𝑆 ),从而使自注意力和MLP的计算成本降低。
值得注意的是,将函数 𝑓 的输出乘以路由器权重会将路由器权重放在“梯度路径”上,从而使它们在语言建模任务的过程中受到梯度下降的影响(作者尝试过将路由器权重包括在绕过块计算的那些token的计算路径中,但只将路由器权重包括在不绕过块计算的那些token的计算路径中似乎足够,并且实现上更简单)。
采样策略
尽管基于专家的选择路由策略有其优势,但存在一个主要问题:该策略下的top-k选择操作与时间顺序无关。这意味着,判断一个特定token的路由权重是否处于序列的top-k位置,依赖于其后token的路由权重值,这在进行自回归采样时是不可知的。
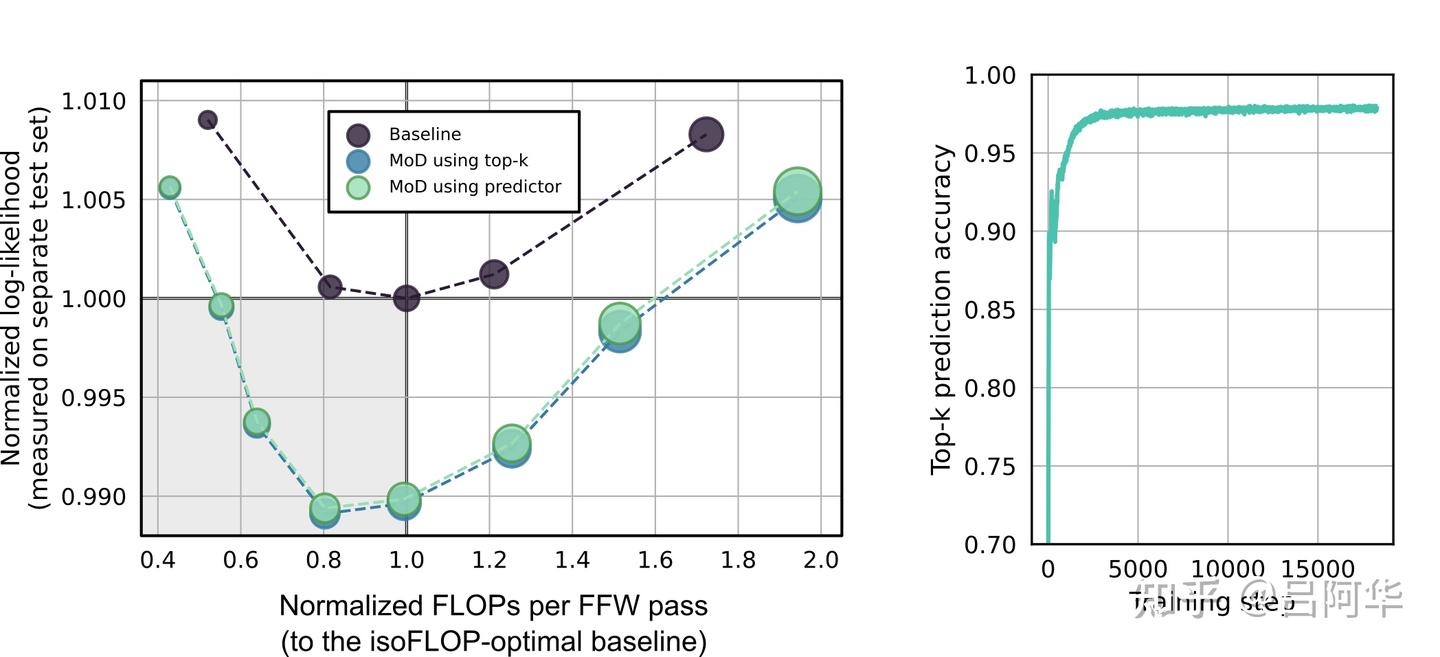
为了克服这一挑战,作者测试了两种方法。第一种方法是引入了一个简单的辅助损失,虽然这对主语言模型的目标产生了大约0.2到0.3%的影响,但它使得测试能够自回归地进行模型采样。作者采用了二元交叉熵损失,其中路由器的输出决定了逻辑值,而这些逻辑值的top-k选择则成为了目标(即,如果一个token在top-k中,则标记为1;否则为0)。直观上,这种损失让路由器输出的sigmoid值趋近于0.5;选入top-k的token的路由输出被推向高于0.5,而未选入top-k的则被推向低于0.5。第二种方法引入了一个小型辅助MLP预测器,这个预测器接收和路由器相同的输入(但应用了梯度停止),其目标是预测特定token是否会在序列中排名前 。这种方法不影响主语言建模目标,并且据观察不会显著影响处理速度。
通过这些方法,可以根据路由器的输出决定token是被路由进模块还是绕过模块,而这个决策过程不需要依赖于任何未来token的信息。作者提供了证据表明,这是一个相对简单的辅助任务,可以快速达到99%的准确率。
训练策略
所有模型均采用相同的基本超参数配置,例如训练步骤的余弦调度、128的批次大小、2048的序列长度,唯一的变化是在等效浮点操作(isoFLOP)分析期间调整了模型的层数、头数和嵌入大小,以生成不同规模的模型。
成果
训练及等效浮点操作(isoFLOP)比较
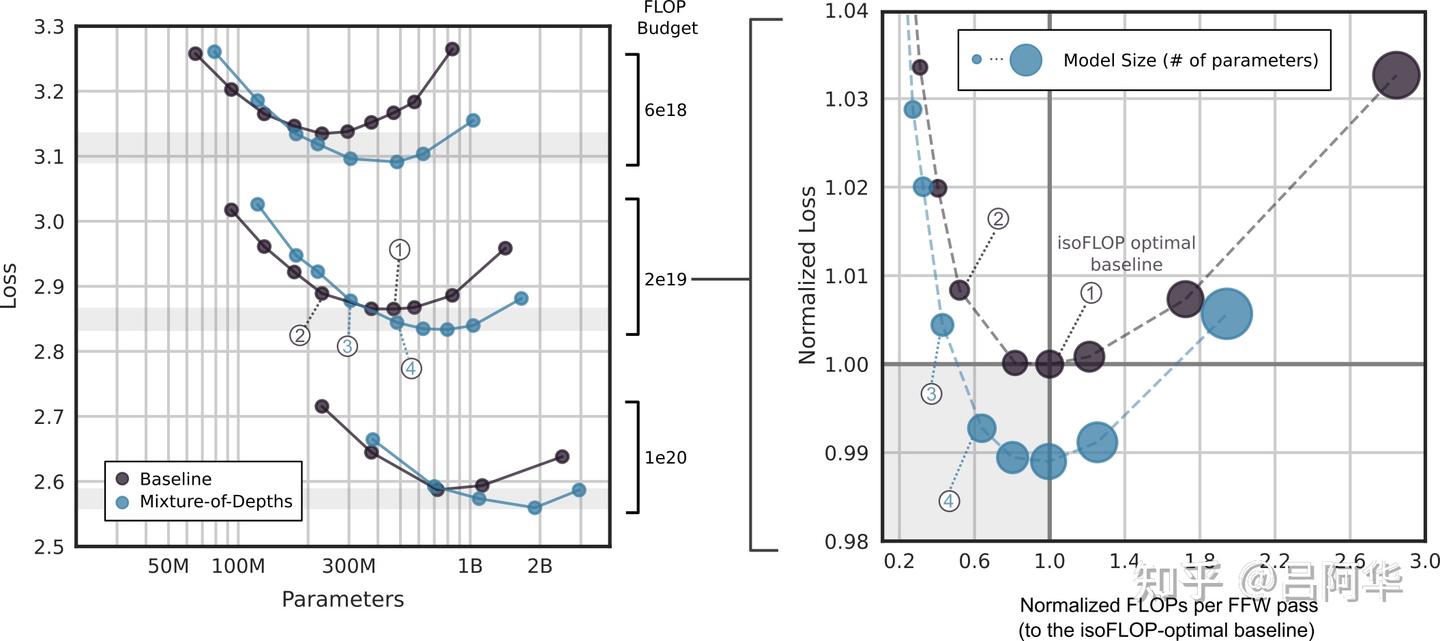
作者首先训练了具有相对较低计算预算(6e18)的模型,以此来确定最合适的超参数设定(参见图3)。总体而言,作者观察到 MoD transformer模型使得基准的等效浮点操作(isoFLOP)曲线展现出“下降并向右延伸”的趋势。换句话说,最佳的MoD transformer在达到更低的损失值的同时,其参数数量也更多。这种现象的一个积极影响是,存在一些参数规模较小的MoD模型,在其超参数设定下虽然不是isoFLOP最优的,但它们的性能与最优基准模型相当或更好,同时训练速度更快。例如,一个拥有220M参数的MoD变种(图3中的模型#3)略微超过了isoFLOP最优的基准模型(同样是220M,图3中的模型#1),但在训练过程中的速度快了60%以上。关键在于,这两个模型变种在相同硬件上训练时所需的实际时间大致相同(如图3所示)。 作者尝试了对每个块或每隔一个块进行路由的策略,容量设置从总序列的12.5%到95%不等。他发现每隔一个块进行路由对于实现强性能至关重要,同时,作者也发现激进地减少容量(将容量减少到总序列的12.5%,即有87.5%的token绕过块时)可以带来渐进的性能提升,但减少到12.5%这个比例以下性能开始下降。这表明,只要模型有机会频繁地进行全容量的自注意力和MLP计算,它就能对大幅度的容量减少保持稳定的性能。 学习路由的重要性不言而喻,采用随机路由策略的MoD transformer(通过对从高斯分布中采样得到的路由器权重执行top-k操作实现)性能大大低于基准模型和常规MoD transformer(如图3所示)。
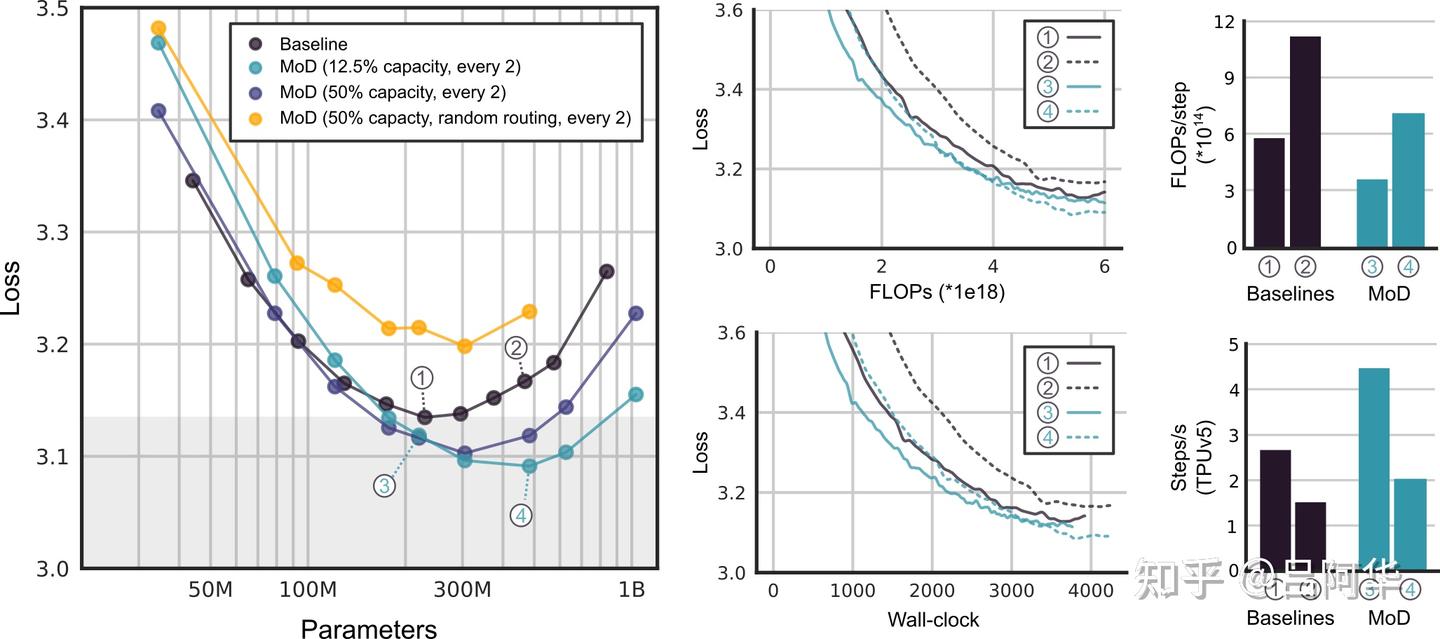
图4中呈现了6e18、2e19和1e20总FLOPs规模下的等效浮点操作分析。对于这些更大的FLOP预算,FLOP最优的混合深度(MoD)transformer拥有比基准模型更多参数的趋势依旧存在。特别值得注意的是,有些MoD变体的训练速度显著快于等效FLOP最优的基准模型(在相同硬件上训练时以每秒步骤数衡量),同时还能实现更低的损失值(在图4中展示的是每次前向传递的标准化FLOPs而非实际的挂钟时间,但根据作者的实验,这两者之间有很强的相关性。可以生成一个相对挂钟时间的图表,基本趋势依然存在)。 提高训练速度主要有两个途径。首先,MoD transformer中每参数的FLOP比率低于基准,因为部分token被绕过了模块。因此,对于同等大小的模型,transformer每次前向传递所需的FLOPs更少。其次,因为等效浮点操作最优的MoD transformer在模型大小和损失降低方面都优于等效浮点操作最优的基准,存在一些更小的MoD变体,其性能与等效FLOP最优基准相当或更好,并且由于模型规模较小,训练速度更快。因此,存在着既能与等效浮点操作最优基线保持一致的性能又能提高训练速度的MoD transformer,这既因为它们每参数使用的浮点操作数更少,也因为它们使用的参数总数更少。 图4还展示了另一个重要的发现:最优的MoD transformer是那些每次前向传递使用的FLOPs数量与等效浮点操作最优基准相同的模型。这一发现使作者能够直接预测对于特定的等效FLOP训练预算,哪种规模的MoD transformer将表现最佳:只需调整MoD配置(即容量和路由频率)下的模型规模,使其每次前向传递的浮点运算数与等效浮点操作最优基准相等,就可以获得该配置下表现最佳的MoD变体。实际经验表明,在模型扩展时增加深度而非宽度是更优的选择。 然而,尽管每次前向传递的FLOPs决定了哪个模型会成为等效FLOP最优,但它并不预测最优损失是否能超越基线(参见图3)。具体来说,最优的容量配置似乎可以通过经验来确定。我们发现,最佳做法是使用12.5%的容量块,并且每隔一个块进行路由。
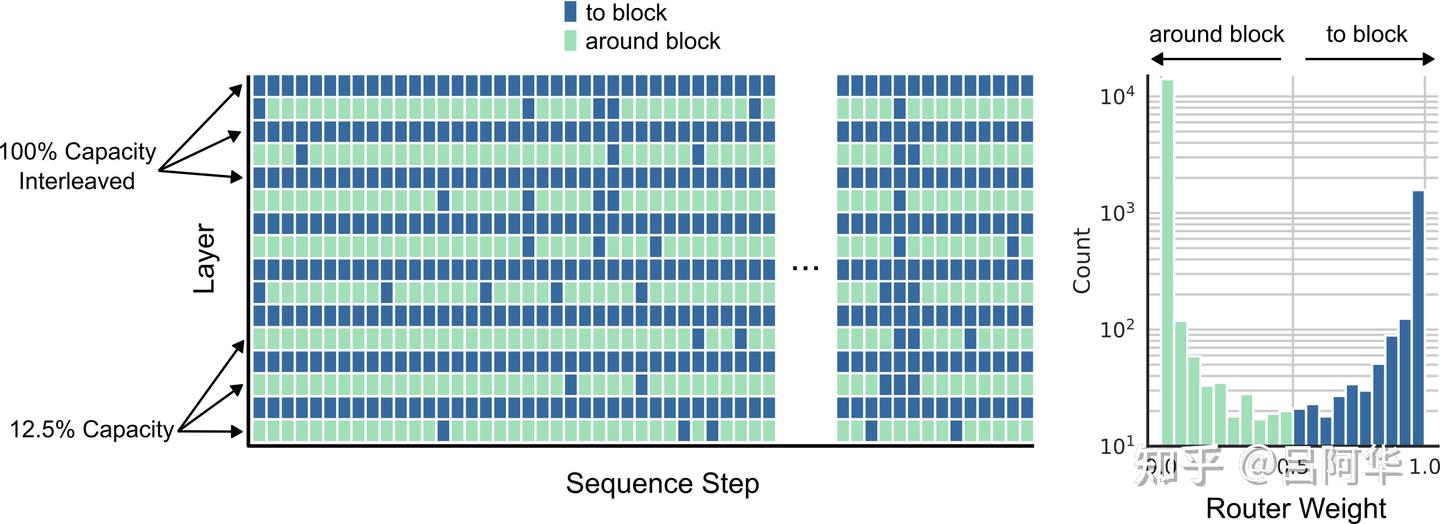
作者发现,在更大模型规模下,MoD transformer与等规模的基准模型相比,在内存使用上能够实现节约,有些变体甚至减少了对总体设备的需求(例如,需要更小规模的TPU架构)。虽然作者并未对此进行深入研究,但随着模型规模增加,这种节省可能在选择要训练的模型变种时成为一个重要因素,对自回归采样期间的KV缓存大小也可能产生积极影响。 图5呈现了一种采用间隔路由块策略训练的MoD transformer的路由决策。即便采取了大胆绕过部分块的路由策略,transformer模型相对于基准模型仍能取得性能上的提升。作者观察到了一些可能需要进一步研究的现象,即某些token在transformer的深度方向上似乎参与了每一个处理块的计算,而另一些token则尽可能选择绕过这些块。初步分析显示,更频繁参与块计算的token与其输出预测的熵值较高有关,这可能指向那些更难以进行预测的情况。
自回归性能评估
作者对MoD变种在自回归采样中进行了评估(参见图6)。每种模型都在相同的保留数据集上进行了测试,该数据集包含了256000个序列(合计500M个token)。当实验从基于top-k的路由策略切换到基于预测器的路由策略时,性能略有下降。和训练场景相似,有些MoD变种在性能上超越了等效浮点操作最优的基准模型,同时它们每次前向传递所需的浮点计算量更少。这些结果表明,MoD transformers提供的计算效率提升不仅限于训练场景。
混合深度与专家模型(MoDE)
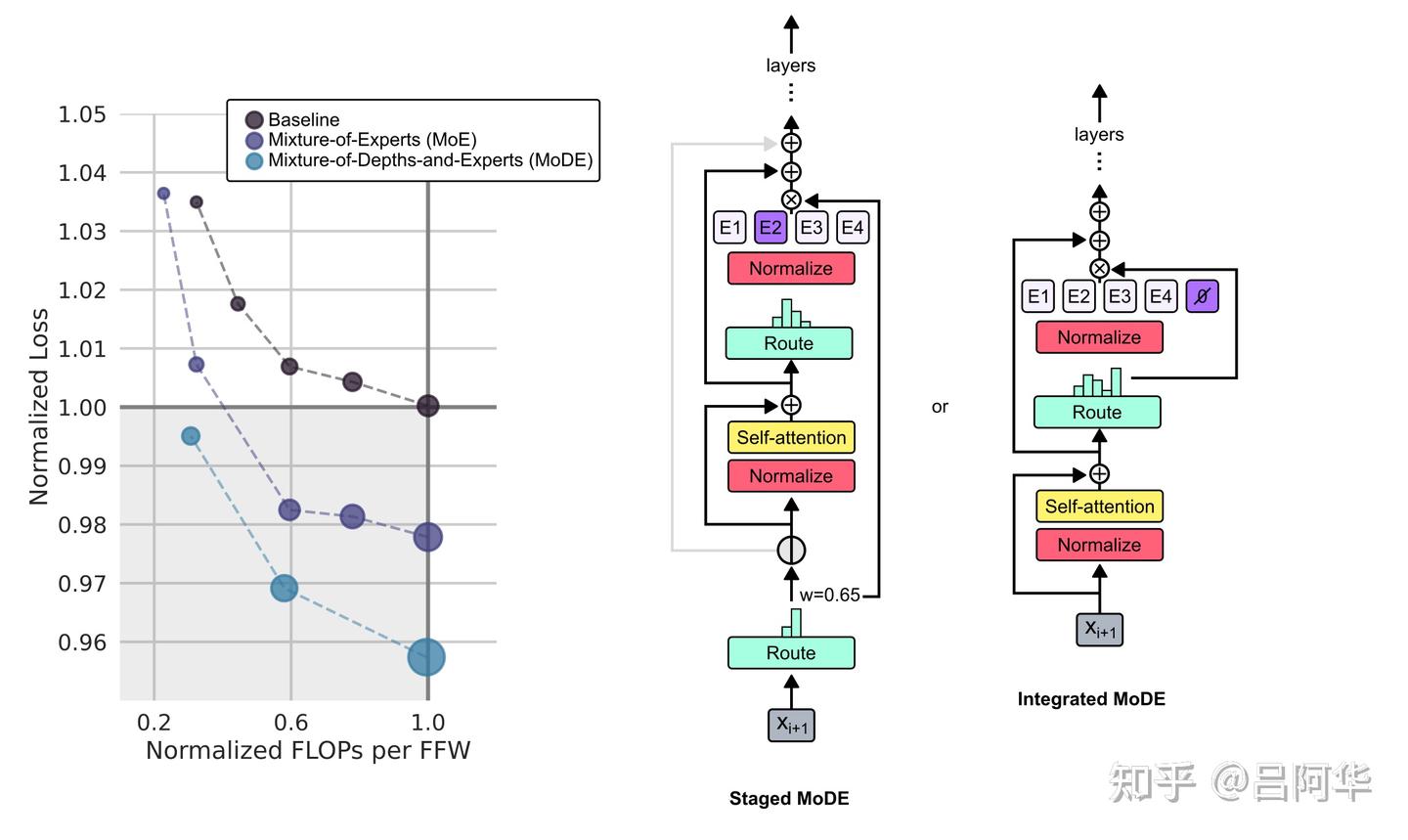
MoD技术不仅可以与MoE模型结合(共同构成MoDE模型),也可以和标准transformer模型结合使用。图7展示了MoD所提供的性能提升可以与MoE的提升相结合。作者尝试了两种方案:一种是阶段性MoDE,它在自注意力步骤之前对token进行路由,要么绕过块,要么朝向块;另一种是集成MoDE,它通过在传统MLP专家中加入“无操作”专家来实现MoD路由。 前者的优势在于它允许token跳过自注意力步骤,后者则因简化了路由机制而有优势。作者发现,以集成方式实现MoDE的性能明显优于仅在传统MoE模型中通过减少专家的容量和依赖token丢弃来实现残差路由的做法。他认为这是因为在集成MoDE机制中,token显式地学习选择绕过专家的残差路径,相对于仅仅因为容量减少而被动丢弃,这种做法更为有效。
*文章翻译到此结束,感谢同学们的认真阅读,如发现有错误或疑问请在评论区留言。
*翻译辛苦,码字不易,如果感觉有收获,欢迎赞同/喜欢/收藏本文,并关注楼主
原文地址

如果这篇文章帮助到了你,你可以请作者喝一杯咖啡


 浙公网安备 33010602011771号
浙公网安备 33010602011771号