
从TVM到Tilelang:深度学习的编译
深度学习编译器 TVM
在深度学习的训练和推理过程中,性能优化是一个永恒的主题。不同的硬件(CPU、GPU、NPU、FPGA 等)有不同的计算特性,如果每次都手写 CUDA 内核或 ARM 汇编,不仅耗时,而且难以维护。
这时,一个跨平台的深度学习编译器——Apache TVM (Tensor Virtual Machine) 就派上用场了。
一、什么是 TVM?
TVM 是一个 开源深度学习编译框架,它的目标是:
- 让各种深度学习模型(来自 PyTorch、TensorFlow、ONNX 等)
- 能够 自动优化并运行在各种硬件上(CPU/GPU/NPU/FPGA)。
一句话总结:
👉 TVM 就是深度学习领域的“LLVM + GCC”,专门为 AI 算子和模型生成高效代码。
二、TVM 的核心思想
TVM 的设计核心可以拆解为 三个层次:
-
图级优化(Relay IR)
- 深度学习模型是一张“计算图”(Graph)。
- TVM 会做算子融合(fusion)、常量折叠、冗余消除等优化。
-
算子优化(TIR & Scheduling)
- 单个算子(如矩阵乘法、卷积)的实现方式可能千变万化。
- TVM 提供了一种 调度语言,你可以描述算子如何分块 (tiling)、向量化、并行化。
-
自动调优(AutoTVM / Ansor)
- 手工调度很累,TVM 提供 自动搜索优化参数 的方法。
- 通过测量真实运行性能,找到最优调度,性能可接近甚至超过手写 CUDA 内核。
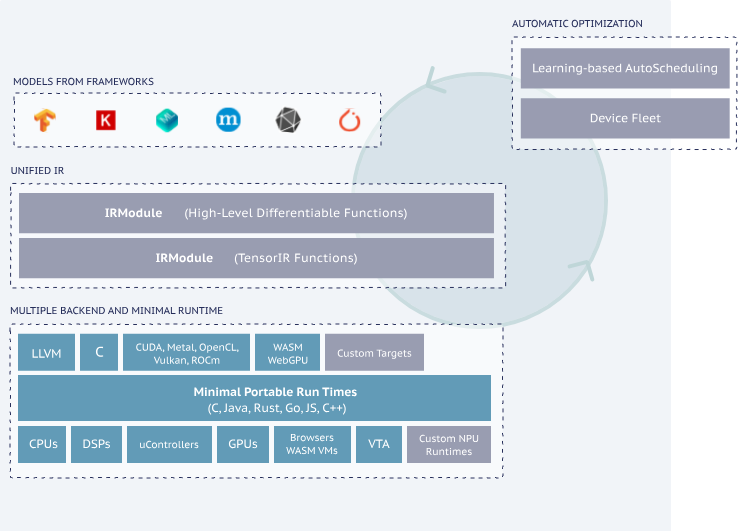
三、一个实例:矩阵乘法
我们从一个简单的矩阵乘法例子开始,展示 TVM 的使用流程。
1. 定义计算公式
在 TVM 里,先用 te.compute 定义数学公式:
import tvm
from tvm import te
N = 1024
A = te.placeholder((N, N), name="A")
B = te.placeholder((N, N), name="B")
k = te.reduce_axis((0, N), name="k")
# C[i, j] = sum(A[i, k] * B[k, j])
C = te.compute((N, N), lambda i, j: te.sum(A[i, k] * B[k, j], axis=k), name="C")
这部分就像写数学公式,没有涉及任何优化。
2. 写调度(优化策略)
接下来定义“怎么计算”,比如分块 (tiling)、并行化:
s = te.create_schedule(C.op)
i, j = C.op.axis
k = C.op.reduce_axis[0]
# 分块 32×32
io, ii = s[C].split(i, 32)
jo, ji = s[C].split(j, 32)
# 调整计算顺序
s[C].reorder(io, jo, ii, ji, k)
# 并行外层循环
s[C].parallel(io)
s[C].unroll(ji)
3. 生成 CUDA 代码
TVM 会把调度转成 GPU 内核:
fmatmul = tvm.build(s, [A, B, C], target="cuda")
print(fmatmul.imported_modules[0].get_source()) # 打印生成的 CUDA 代码
你会发现生成的 CUDA 内核已经做了分块和优化。
4. 在 GPU 上运行
用 NumPy 随机数据测试:
import numpy as np
ctx = tvm.cuda(0)
a_np = np.random.randn(N, N).astype("float32")
b_np = np.random.randn(N, N).astype("float32")
c_np = np.dot(a_np, b_np)
a_tvm = tvm.nd.array(a_np, ctx)
b_tvm = tvm.nd.array(b_np, ctx)
c_tvm = tvm.nd.empty((N, N), dtype="float32", device=ctx)
fmatmul(a_tvm, b_tvm, c_tvm)
np.testing.assert_allclose(c_tvm.numpy(), c_np, rtol=1e-4)
print("✅ TVM matmul works correctly!")
到这里,我们就用 TVM 成功编译并运行了一个 GPU 上的矩阵乘法。
四、自动调优:AutoTVM
如果你不想手动写调度,TVM 提供了 AutoTVM 和 Ansor。
它们会自动搜索最佳参数,比如 tile 大小、线程划分方式。
例子(伪代码):
from tvm import autotvm
task = autotvm.task.create("matmul", args=(1024,), target="cuda")
tuner = autotvm.tuner.XGBTuner(task)
tuner.tune(n_trial=200, measure_option=..., callbacks=[...])
最后,TVM 会把最优配置保存下来,下次直接用即可。
这就是为什么 TVM 可以在 不同硬件 上跑得飞快:
👉 它不是写死的,而是自动学习最佳优化方案。
五、TVM 的生态
- 前端:支持从 PyTorch、TensorFlow、ONNX 导入模型。
- 后端:支持 CUDA、ROCm、Metal、ARM CPU、RISC-V、FPGA、各种 AI 芯片。
- 工具:AutoTVM、Ansor、VTA(FPGA 研究)、TileLang(高级算子 DSL)。
六、总结
- TVM 是一个深度学习编译器,目标是“一次建模,处处高效运行”。
- 它有三层优化:图优化 → 算子调度 → 自动调优。
- 实例里我们看到了如何用 TVM 写一个矩阵乘法,并在 GPU 上运行。
- 借助 AutoTVM/Ansor,TVM 能自动逼近手写内核的性能。
未来,随着 NPU/FPGA 等新硬件的兴起,TVM 的跨平台编译能力会越来越重要。
TileLang 在 TVM 中如何简化算子开发
1. 背景:为什么需要 TVM
深度学习模型通常运行在多种硬件(CPU、GPU、AI 芯片)上,而不同硬件的 最佳算子实现方式 差异巨大。
比如矩阵乘法,在 CPU 上可能需要 向量化 + cache blocking,而在 GPU 上则依赖 线程块分配 + shared memory。
如果手写 CUDA 或 AVX 内核,不仅耗时,还无法快速适配不同硬件。
为了解决这一问题,TVM 出现了。
- TVM(Tensor Virtual Machine) 提供了一种统一的中间表示(TIR),开发者只需要用数学公式描述算子,然后通过 调度(schedule) 把计算映射到硬件。
- 这样,TVM 就像一个“编译器”,能把高层的算子逻辑翻译为底层高效代码。
2. AutoTVM 与 Ansor:自动化探索
虽然 TVM 提供了手写调度的能力,但调度本身非常复杂:
要考虑分块大小、循环展开、内存层次、线程分配等等。
于是,TVM 引入了自动化调优工具:
- AutoTVM:基于人工设计的 调度模板,然后用搜索算法(如 XGBoost)探索最优参数。
- Ansor:更进一步,采用 无模板自动调度,通过代价模型和搜索自动生成调度方案。
问题:
无论是 AutoTVM 还是 Ansor,虽然减少了人工搜索,但 算子定义和调度描述仍然过于底层(TIR/TE 级别),开发者门槛很高。
3. TileLang 的出现:简化算子开发
为了解决 TVM 可用性 问题,社区提出了 TileLang。
- TileLang 是建立在 TVM TIR 之上的高层 DSL(领域特定语言)。
- 它的目标是:让开发者像写数学公式一样描述算子逻辑,并用更直观的 API 来定义调度(tile、parallel、unroll 等)。
- 底层仍然使用 TVM 的 IR(TIR),因此保留了跨硬件编译的能力。
换句话说:
👉 TileLang = 简化语法 + 自动与 TVM 集成。
4. 示例对比
4.1 TVM 写法(矩阵乘法)
import tvm
from tvm import te
N = 1024
k = te.reduce_axis((0, N), "k")
A = te.placeholder((N, N), name="A")
B = te.placeholder((N, N), name="B")
C = te.compute((N, N), lambda i, j: te.sum(A[i, k] * B[k, j], axis=k))
s = te.create_schedule(C.op)
i, j = C.op.axis
io, ii = s[C].split(i, 32)
jo, ji = s[C].split(j, 32)
s[C].reorder(io, jo, ii, ji, k)
s[C].parallel(io)
s[C].unroll(ji)
这段代码需要 手动管理 axis、split、reorder,理解成本很高。
4.2 TileLang 写法(矩阵乘法)
import tilelang
from tilelang import Tensor, Program, compute, reduce
N = 1024
A = Tensor((N, N), "float32", "A")
B = Tensor((N, N), "float32", "B")
k = reduce((0, N), "k")
C = compute((N, N), lambda i, j: A[i, k] * B[k, j], reduce_axis=k, name="C")
prog = Program()
with prog.function("matmul", args=[A, B, C]):
i, j = C.op.axis
io, ii = prog.split(i, 32)
jo, ji = prog.split(j, 32)
prog.reorder(io, jo, ii, ji, k)
prog.parallel(io)
prog.unroll(ji)
对比可以看到:
- 计算逻辑:用
compute定义,几乎就是数学公式C[i, j] = Σ A[i, k] * B[k, j]。 - 调度逻辑:
prog.split、prog.parallel,语法直观,避免底层te.schedule的繁琐。
5. TileLang 在 TVM 技术栈中的位置
可以总结为一条技术演进路线:
-
TVM (TE/TIR)
- 提供跨硬件的中间表示和调度机制。
- 问题:太底层,学习成本高。
-
AutoTVM / Ansor
- 让调度搜索自动化,减少人工调优。
- 问题:算子定义和调度描述仍然复杂。
-
TileLang
- 在 TVM 基础上提供简洁 DSL。
- 开发者可以快速写出高性能算子,同时仍然能享受 AutoTVM/Ansor 的优化能力。
- 语法类似 Triton,但继承了 TVM 的跨平台优势。
6. 总结
- TVM 解决的是跨硬件优化的问题;
- AutoTVM / Ansor 解决的是自动调优的问题;
- TileLang 解决的是开发者易用性的问题。
三者形成一个层次递进的体系:
👉 TVM 打基础 → AutoTVM/Ansor 提升自动化 → TileLang 提升开发效率。
未来,如果你需要开发一个新算子:
- 不想自己写复杂 CUDA → 用 TileLang 定义算子;
- 想获得最优性能 → 结合 AutoTVM/Ansor 调优;
- 想跨平台部署 → TVM 帮你编译到不同硬件。
这样,整个生态就完整了。

如果这篇文章帮助到了你,你可以请作者喝一杯咖啡


 浙公网安备 33010602011771号
浙公网安备 33010602011771号