
数据并行、张量并行及其实现
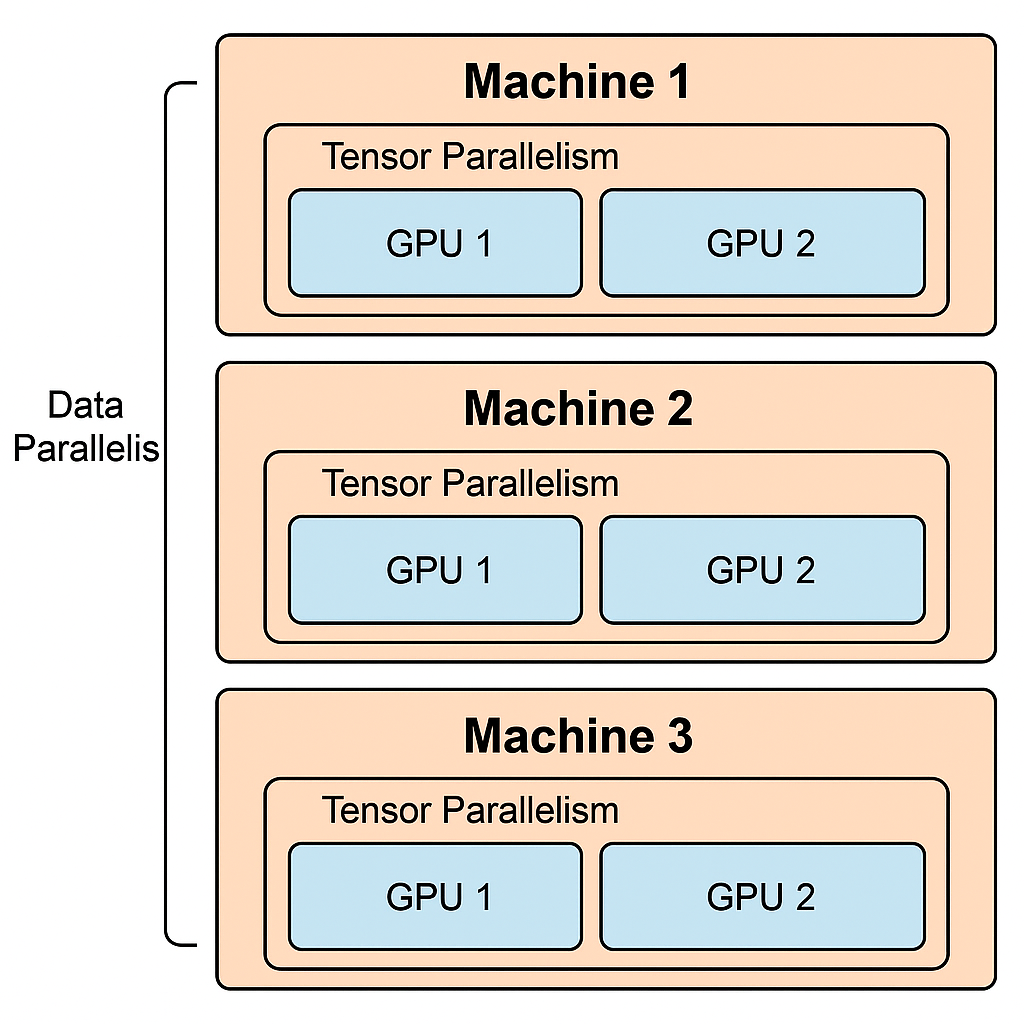
在大模型训练中,通信成本是影响训练效率的关键瓶颈之一。数据并行(Data Parallelism) 和 张量并行(Tensor Parallelism) 通过各自的策略来降低通信开销、提升效率。下面从它们的通信特点和优化方式来分析。
一、数据并行(Data Parallelism)
原理:
每个 GPU 拥有一个完整模型副本,处理不同的数据子集(batch 切片),每个 step 后将 梯度进行 all-reduce 同步。
通信瓶颈:
-
梯度同步必须在每个 step 后完成,尤其在大模型中,梯度量非常大。
-
使用
torch.distributed.all_reduce()同步所有参数梯度。
优化通信的方式:
| 方法 | 描述 |
|---|---|
| 梯度累积 | 每多个 step 才同步梯度,减少通信频率。 |
| 混合精度(FP16/BF16) | 降低梯度数据精度,减少通信体积。 |
| 压缩通信 | 梯度裁剪/量化以减少通信带宽占用。 |
| 高效拓扑(Ring/NCCL树) | 使用拓扑感知的通信算法优化 all-reduce 路径。 |
| ZeRO(Zero Redundancy Optimizer) | 在参数/梯度/优化器状态层面做切分,避免全量通信。 |
通信优势:
-
通信量与模型大小成正比,与 batch size 无关;
-
适合大 batch size 场景,尤其是训练中后期。
二、张量并行(Tensor Parallelism)
原理:
将模型层内部的参数进行切分(如 linear 层的权重矩阵切块),每个 GPU 仅计算一部分张量操作。
例如:
一个 Linear(4096, 4096) 层在 4 张 GPU 上,每个 GPU 只处理 4096x1024 的子矩阵。
通信特点:
-
每一层前后都需要通信:
-
前向传播时:输入张量需切分发送到每个 GPU;
-
反向传播时:每个 GPU 的局部梯度需合并。
-
优化通信的方式:
| 方法 | 描述 |
|---|---|
| 切分兼容的模型结构 | 比如将 FFN 层等宽切分,减少 padding 和重组开销。 |
| 优化广播/收集策略 | 合理安排 all_gather 和 reduce_scatter,避免重复通信。 |
| 通信与计算重叠 | 使用流水线和异步通信,隐藏延迟。 |
| 拓扑感知映射 | 把并行进程映射到通信延迟更低的 GPU 组。 |
通信优势:
-
每层通信量与中间激活维度成正比,而不是整个模型;
-
模型参数越大,切得越细,单 GPU 负载越低。
三、对比总结
| 对比项 | 数据并行 | 张量并行 |
|---|---|---|
| 并行维度 | Batch | 模型参数/激活 |
| 通信时机 | 每 step 后同步梯度 | 每层计算前后同步张量 |
| 通信量与谁相关 | 模型总参数 | 激活张量维度 |
| 优势 | 简单易用、扩展性好 | 节省单卡显存、适合大模型 |
| 通信代价 | 高(全模型梯度) | 中(层内激活) |
| 典型场景 | Batch 足够大时 | 模型太大,单卡放不下时 |
总结
-
数据并行在 batch size 大、通信带宽充足 时表现好;
-
张量并行在 模型太大无法完整加载时 是唯一选择;
-
通常会联合使用:如 Megatron-LM 中同时采用 Tensor + Data 并行以提升利用率、减少通信开销。
张量并行(Tensor Parallelism) 通常用于 同一机器的不同GPU之间,而 数据并行(Data Parallelism) 则用于 跨机器(甚至跨节点)之间的分布式训练。这两种并行方式的分工主要是基于通信成本和可扩展性的考量。
下面分别从 PyTorch 层面 和 训练框架层面(如 DeepSpeed、Megatron-LM等)说明它们是如何实现这一规则的。
一、PyTorch 层面
PyTorch 本身提供的原始分布式通信API(torch.distributed)和通信后端(如 nccl、gloo)只是基础能力,具体并行策略的实现需开发者手动控制。
1. 设置 GPU 与 Rank 映射
torch.distributed.init_process_group(backend="nccl", init_method="env://")
torch.cuda.set_device(local_rank)
-
local_rank控制当前进程使用的 GPU(同一机器) -
rank/world_size控制整体进程数与并行策略(跨机器)
2. 数据并行实现(PyTorch 原生)
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[local_rank])
这是数据并行,在每台机器上的每个GPU上分别维护一份模型副本。
3. 张量并行手动拆分(低级)
通常要自己对模型的权重做 torch.split、torch.cat 等操作,然后使用 torch.distributed.all_reduce、all_gather 等进行跨 GPU 通信。
二、训练框架层面(如 Megatron-LM、DeepSpeed、vLLM)
这些框架已经在更高层面实现了对不同并行策略的封装,通过配置文件或初始化脚本决定是张量并行还是数据并行。
1. Megatron-LM(经典的张量并行框架)
-
使用
--tensor-model-parallel-size来设置张量并行 -
使用
--pipeline-model-parallel-size设置流水线并行 -
其余进程自动划分为数据并行组
📄 配置:
--tensor-model-parallel-size 4 \
--pipeline-model-parallel-size 2 \
--num-layers 48 \
内部划分:
-
同一个数据并行组中的模型参数是共享的
-
张量并行组中的不同GPU只负责参数的某个切片
-
划分方式在代码中通过
initialize_model_parallel()函数处理
2. DeepSpeed
-
提供 ZeRO、张量并行等多种策略
-
使用
deepspeed_config.json设置tensor_parallel,zero_optimization,pipeline_parallel等
{
"zero_optimization": {
"stage": 2
},
"tensor_parallel": {
"tp_size": 2
}
}
3. vLLM
-
专注于推理优化,训练中不是主力
-
若用于推理时的并行,内部自动根据 GPU 拓扑结构设置 tensor 并行,较少需要显式配置
总结对比表
| 并行方式 | 跨设备位置 | PyTorch层操作 | 框架设置方式 |
|---|---|---|---|
| 张量并行 | 同机多卡 | 手动切分权重 + 通信 | Megatron tensor_model_parallel_sizeDeepSpeed tensor_parallel.tp_size |
| 数据并行 | 跨机或多卡 | DDP (DistributedDataParallel) | 自动由 world size 与 rank 划分 |

如果这篇文章帮助到了你,你可以请作者喝一杯咖啡


 浙公网安备 33010602011771号
浙公网安备 33010602011771号