
OHEM
样本不平衡问题
如在二分类中正负样本比例存在较大差距,导致模型的预测偏向某一类别。如果正样本占据1%,而负样本占据99%,那么模型只需要对所有样本输出预测为负样本,那么模型轻松可以达到99%的正确率。一般此时需使用其他度量标准来判断模型性能。比如召回率ReCall(查全率:样本中所有标记为正样本的有多少被模型预测为正样本)。
从数据层解决办法:
1、欠采样(undersampling):将模型中类别较多的样例除去一些,使类别样本数量平衡。但此法由于除去一些样本,导致丢失许多信息。一种改进办法是EasyEnsemble,将数量多的类别分成几份,分别与少数类别组合,形成N份数据集。从全局上看信息没有丢失。还有one-sided selection;data decontamination
2、过采样(oversampling):增加数量少的类别样本。简单方法使用直接复制、数据增强、添加噪声等。典型算法是SMOTE 算法:通过对少数样本进行插值来获取新样本的。一般过采样的效果要好于前采样。推荐了解:Synthetic Minority Over-sampling Technique(SMOTE:在样本和其相邻的样本之间产生一个样本) ;Ranked Minority Over-sampling (RAMO:通过判断样本周围正负样本的比例来判断其难分程度,根据权重生成少类数据集,再使用SMOTE生成样本);Random Balance (RB:在数据集数量相同的情况下,随机设置正负比例率,生成一堆不平衡数据集);Cluster-based oversampling;DataBoost-IM;class-aware sampling
从模型层解决办法:
1、阈值移动:在二分类中,若 y/(1-y) > 1,则预测为正例。然而只有当样本中正反比例为1:1时,阈值设置为0.5才是合理的。对于样本不平衡(m+ 代表正例个数, m- 代表负例个数),改进决策规则:若 y/(1-y) > (m+) / (m-) ,则预测为正例。因为训练集是总体样本的无偏采样,观测几率就代表真实几率,决策规则中 ( (m+) / (m-) ) 代表样本中正例的观测几率,只要分类器中的预测几率高于观测几率达到改进判定结果的目标。
2、代价敏感学习:在医疗中,“将病人误诊为健康人的代价”与“将健康人误诊为病人的代价”不同。通常,不同的代价被表示成为一个N×N的矩阵Cost中,其中N是类别的个数。Cost[i, j]表示将一个i 类的对象错分到j 类中的代价。代价敏感分类就是为不同类型的错误分配不同的代价,使得在分类时,高代价错误产生的数量和错误分类的代价总和最小。
其他方法:
1、One-class classification单分类,针对极端不平衡分类问题效果不错。
2、融合上述方法:EasyEnsemble ; BalanceCascade ;SMOTEBoost;two-phase
training(现在平衡数据集上预训练网络,然后在不平衡数据集上fine-tuning最后输出层)
更多信息
难分样本问题 Online Hard Example Mining,OHEM
个人感觉难分样本指的是模型对某个样本学习困难,难以学得其特征。而数据不平衡会导致某一类别在模型中学习迭代次数较少,逐渐成为一种难分样本。
一般解决办法:
1、focal loss:通过模型预测的概率pt,使用(1-Pt)来代表样本难分程度。可以理解为模型对某个样本预测属于其真实label的概率越高,则说明该样本对此模型比较容易学习,反之则难分。
2、《ScreenerNet: Learning Self-Paced Curriculum for Deep Neural Networks》论文提出一个附加网络来帮助主网络区分样本难易程度。
3、《Fine-tuning Convolutional Neural Networks for Biomedical Image Analysis》论文通过对一张图像进行数据增强生成多张图像,然后使用模型预测每张图像的概率。根据多张相同label的增强图像的概率分布区分其样本难易程度。
4、《OHEM: Training Region-based Object Detectors with Online Hard Example Mining》论文提出先使用模型输出概率,据此选出部分难分样本,然后根据这些样本,更新网络参数。
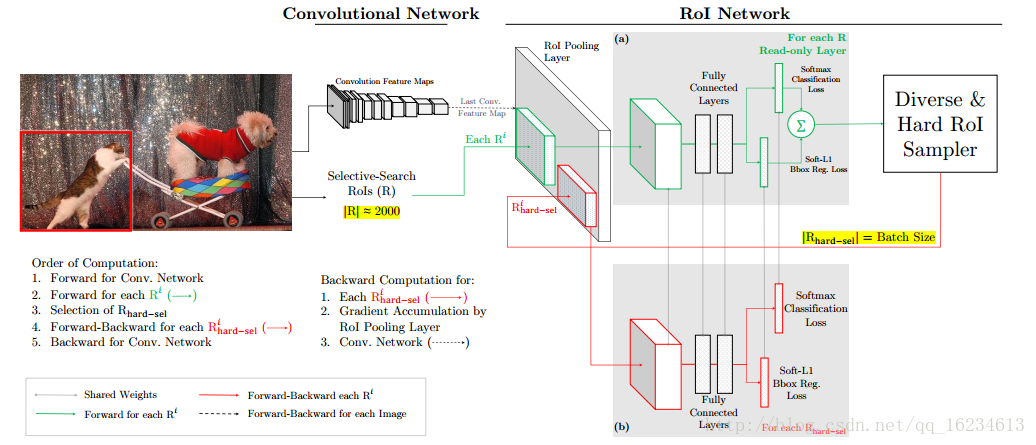
OHEM:
上图绿色和红色分为两个网络但共享权限,通过将提取的RoI传入绿色的只读网络(只进行forward),计算出每个RoI的loss。根据loss排序(可使用NMS)选出部分样本,再输入红色网络(进行forward和backward)学习并进行梯度传播。文中提出另一种办法,在反向传播时,只对选出的样本的梯度/残差回传,而其他的props的梯度/残差设为0。但容易导致显存显著增加,迭代时间增加。
《Fine-tuning Convolutional Neural Networks for Biomedical Image Analysis》中 
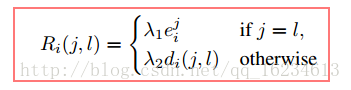
提出首先对一张图像做数据增强,生成一个batches图像,由于这些图像同属一个类别,按理模型预测的结果应该近似,但如果模型预测的不理想,则一定程度上说明图像比较难分。上公式R用于计算图像的难分程度。其思想就是对一张图像的多种变化后进行预测,输出loss后计算样本难分度。focal loss其实就是一种简版,直接根据输出概率计算难分。
ScreenerNet:提出附加网络来输出样本权重,使用该权重与主网络输出结合对主网络参数进行更新。同时使用主网络输出和附网络输出来更新附网络参数。(图中数字为算法运行步骤) 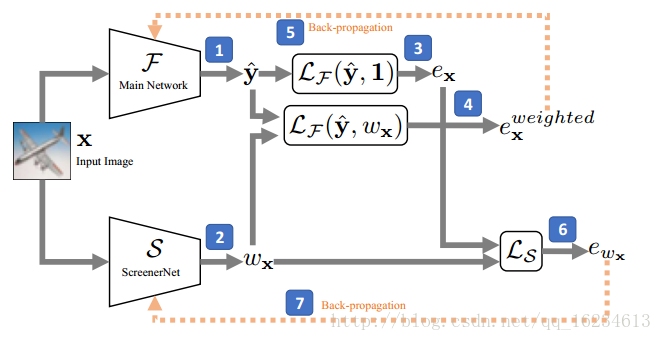
值得注意是在没有label情况下,对附网络的目标函数的设定:
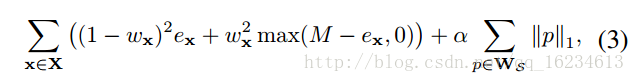

如果这篇文章帮助到了你,你可以请作者喝一杯咖啡


 浙公网安备 33010602011771号
浙公网安备 33010602011771号