systolic array架构设计综述
systolic array(SA)即脉动阵列。对于大规模的乘累加运算,SA将单个乘累加单元和数据流控制部件组成的process element(PE)进一步组织成大规模阵列,数据在PE之间打拍脉动传输。由于深度学习时代,计算负载以大规模的general matrix multiplication(GEMM)操作为核心,而SA在计算GEMM时,具备在较低访存需求的情况下实现高计算吞吐率,可拓展性强等优势,因此成为了被众多加速器广泛采用的GEMM计算单元架构,典型的就是Google的TPU系列芯片。
SA可以根据驻留数据的类型不同,区分为input stationary(IS),weight stationary(WS)和output stationary(OS)三种模式,如下图所示:

上述讨论的是GEMM的情况,对于卷积运算等其他运算类型还有更多的模式,例如Eyeriss的row stationary(RS)模式。但本文只对上述三种最经典的数据流模式进行介绍。
对于IS,WS,OS三种模式来说,工作负载类型会严重影响各自的性能表现。由于驻留的数据对象不同,在不同的数据复用场景下,各自有各自的优劣势空间。例如,对于输入数据高度复用的场景,输入驻留的IS模式会有最好的性能表现;对于权重数据高度复用的场景,权重驻留的WS模式会有最好的性能表现;对于输出数据高度复用的场景,输出驻留的OS模式会有最好的性能表现。
由于不同的负载的数据复用特性存在较大的差异,甚至同一类负载中,不同的层次都有很大的数据复用特性差异(例如transformer模型的self-attention层次,Q,K,V矩阵是跟随输入变化,动态生成然后直接参与到下一次计算的,因此适合输出数据复用的OS模式,但transformer中的fc层又是典型的权重高度复用的计算类型,因此适合权重数据复用的WS模式)。因此我们无法说哪一种数据流模式是最优的,只有最适合的。
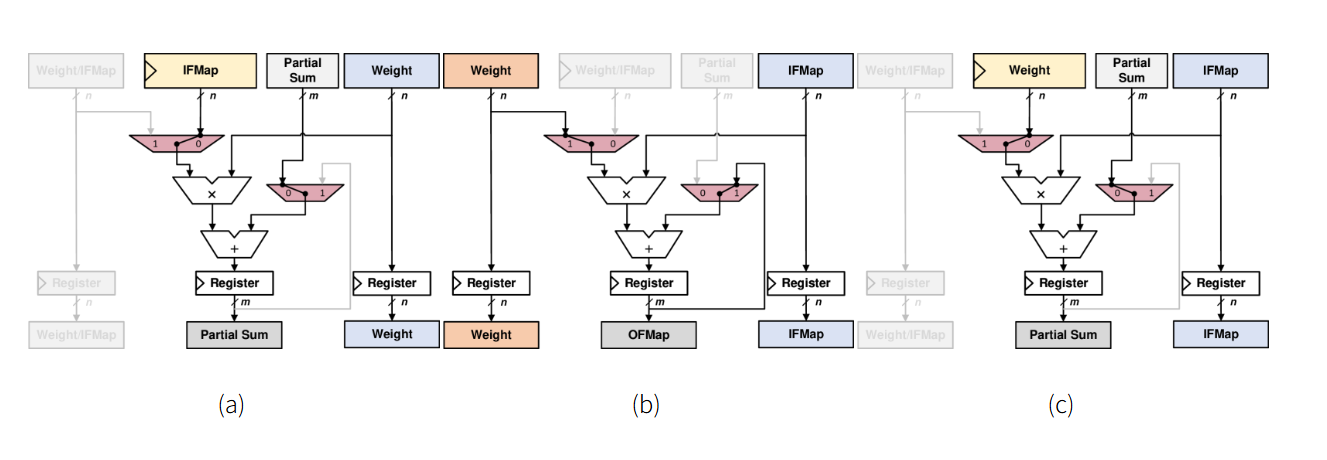
正是源于SA这种对负载的数据复用特性的敏感性,目前大量的学术工作致力于实现可以支持多种数据流模式的新型混合SA结构,例如Flex-TPU同时支持了IS,WS,OS三种模式,其PE设计如下图所示:

可根据负载情况,动态配置为(a) IS模式,(b) OS模式,(c) WS模式。
还有UCB开源的gemmini加速器,采用了WS和OS混合的设计模式:

但混合数据流SA也会引入额外的设计和控制上的复杂度,并且由于引入了冗余的数据 & 控制部件,因此在特定场景下效率会低于单一数据流模式的SA,目前混合数据流SA结构仍然是一个前沿的学术研究方向。
除了数据流问题之外,SA的规模缩放问题,也是一个重要的问题。具体来说,为了追求更高的计算吞吐率,SA有scale up和scale out两种设计选项,如下图所示(一个褐色的R×C矩阵代表在一个SA上进行的运算):
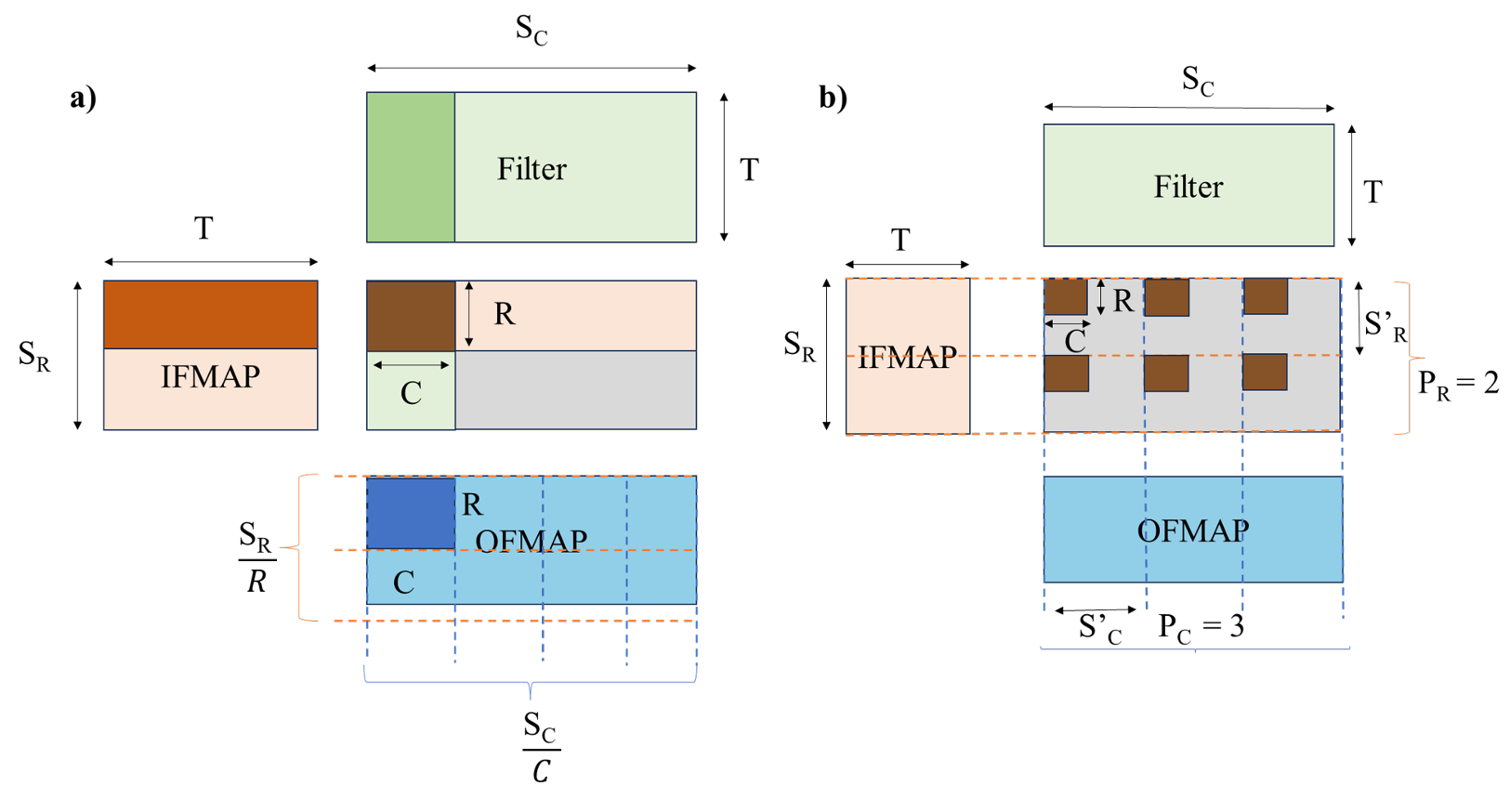
(a) 为scale up方式,即增大单一SA的规模,从而计算更大的负载;(b) 为scale out方式,采用多个并行的小型SA同时计算,将更大的计算负载分担到多个SA上。
scale up的方式简单,但SA的规模增大也会导致计算的总延时线性增大,并且如果计算的矩阵形状不确定,scale up方式容易陷入低利用率的状态;而scale out的方式需要对多个SA进行组织调度,设计的难度增大,但单个SA的延时相对小,且可以更加灵活的支持变化的负载,始终保持均衡的利用率。因此两种方式的trade-off也是一个重要的前沿研究问题。 相关的学术研究工作可以参考:Axon和SOSA。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号