作业题
1.文字回答:ImageNet数据集与ILSVRC之间的关系是什么?
ILSVRC比赛从ImageNet中挑选1000类的1200000张做训练集,所用的数据集是ImageNet的子集。
2.文字回答:AlexNet训练过程的数据增强中,针对位置,采用什么方法将一张图片有可能变为2048张不一样的图片(1个像素值不一样,也叫不一样)?
先将图片同一缩放至256x256,然后随机剪裁出224x224区域,最后随机进行水平翻转
3.文字回答:AlexNet使用的Dropout,在使用过程中需要注意什么?
训练和测试两个阶段的数据尺度变化测试时,神经元输出值需要乘以p。
4.文字回答:读完该论文,对你的启发点有哪些?
1)GPU卷积核学习的内容有差异:GPU1学习频率方向频率, GPU2学习颜色特征。
The network has learned a variety of frequency- and orientation-selective kernels, as well as various colored blobs.
2)网络学习到的高级特征可以用来图像分类、编码等,相似图片具有相近的高级特征
If two images produce feature activation vectors with a small Euclidean separation, we can say that the higher levels of the neural network consider them to be similar.
3)深度与宽度可以决定网络能力
Their capacity can be controlled by varying their depth and breadth.
4)更强大GPU及更多数据可进一步提高模型性能
All of our experiments suggest that our results can be improved simply by waiting for faster GPUs and bigger datasets to become available.
5)图片缩放细节:对短边先缩放
Given a rectangular image, we first rescaled the image such that the shorter side was of length 256, and then cropped out the central 256x266 path from the resulting image.
6)RELU不需要对输入进行标准化,但是sigmoid/tanh激活函数有必要对输入进行标准化
RELUs have the desirable property that they do not require input normaliation to prevent them from saturating.
7)图片检索可基于高级特征,效果优于基于原始图像
This should produce a much better image retrieval method than applying autoencoders to the raw pixels.
8)网络结构具有相关性,不可轻易移除某一层
It is notable that our network's performance degrades if a single convolutional layer is removed.
9)采用视频数据可能有新突破
Ultimately we would like to use very large and deep convolutional nets on video sequences.
10) 用ReLU来训练可以比用tanh更快
Deep convolutional neural network with ReLUs train several times faster than their equivalents with tanh units.
11) 我们采用的并行化方案基本上把一半的内核(我们的神经元)放在每个GPU上,还有一个额外的技巧:GPU只在特定的层中通信。
The parallelization scheme that we employ essentially puts half of the kernels (our neurons) on each GPU, with one additional trick: the GPUs communicate only in certain layers.
12) 避免过拟合的两个方法
extract random 224x224 patches from the 256x256 images
alter the intensities of the RGB channels in traninig images. Specially, we perform PCA on the set of RGB pixel values throughout the ImageNet training set. To each training image, we add multiples of the found principal components, with magnitudes proportional to the corresponding eigenvalues times a random variable drawn from a Gaussian with mean zero and standard deviation 0.1.
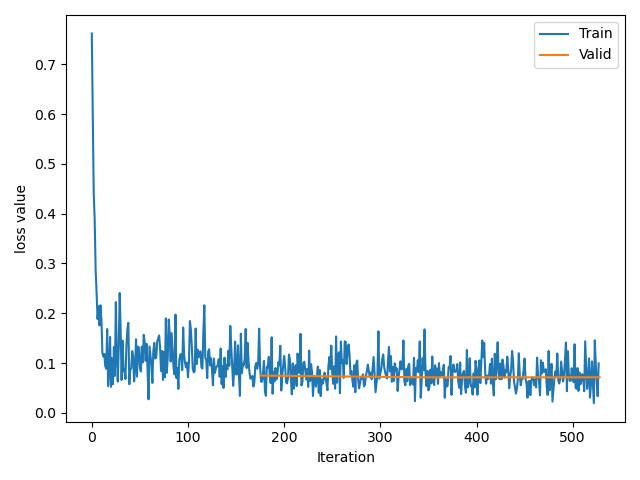
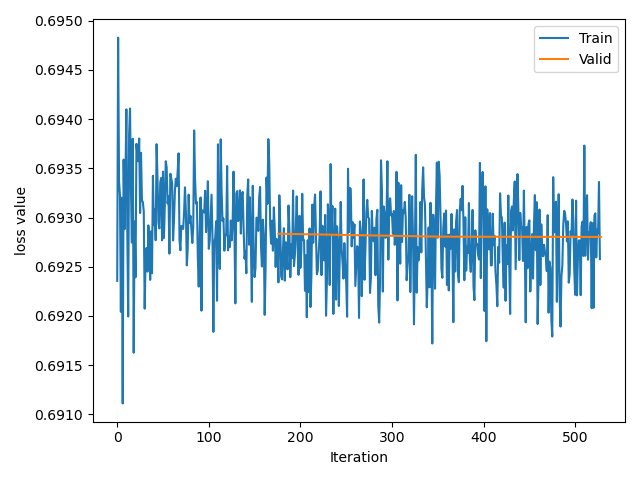
5.代码实践:在猫狗数据集上,对比采用预训练模型和不采用预训练模型这两种情况,训练曲线有何差异,截图打卡。
采用预训练模型:
![]()
不采用预训练模型:
![]()
可以明显看出,不加载预模型开始训练,训练速度慢,持续震荡,很难收敛
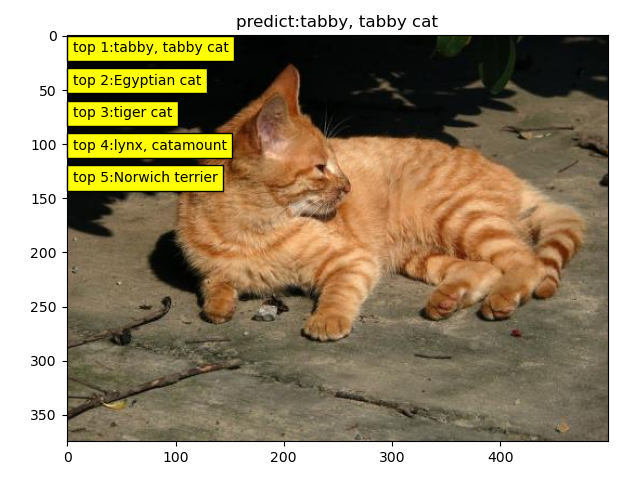
测试结果:
![]()
6.文字:本篇论文的学习笔记及总结


 浙公网安备 33010602011771号
浙公网安备 33010602011771号