jieba分词
jieba分词用python编写,代码清晰,扩展性好,对jieba有改进的想法可以很容易的自己写代码进行魔改。
jieba分词的基本思路
jieba分词对已收录词和未收录词都有相应的算法进行处理,其处理的思路很简单,当然,过于简单的算法也是制约其召回率的原因之一。
其主要的处理思路如下:
1.加载词典dict.txt
2.从内存的词典中构建该句子的DAG(有向无环图)
3.对于词典中未收录词,使用HMM模型的viterbi算法尝试分词处理
4.已收录词和未收录词全部分词完毕后,使用dp寻找DAG的最大概率路径
5.输出分词结果
jieba分词为了快速地索引词典以加快分词性能,使用了前缀数组的方式构造了一个dict用于存储词典。
在旧版本的jieba分词中,jieba采用trie树的数据结构来存储,其实对于python来说,使用trie树显得非常多余。
trie树
trie树又叫字典树,是一种常见的数据结构,用于在一个字符串列表中进行快速的字符串匹配。其核心思想是将拥有公共前缀的单词归一到一棵树下以减少查询的时间复杂度,其主要缺点是占用内存太大了。
trie树按如下方法构造:
一个以and at as cn com构造的trie树如下图:
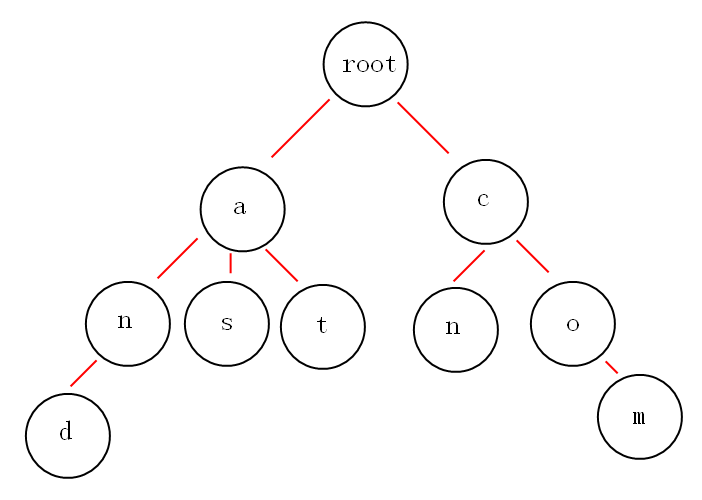
遍历每行文件,对于每个单词的每个字母,在trie树(trie和p变量)中查找是否存在,如果存在,则挂到下面,如果不存在,就建立新子树。
jieba分词采用python 的dict来存储树,这也是python对树的数据结构的通用做法。
使用trie树的问题
本来jieba采用trie树的出发点是可以的,利用空间换取时间,加快分词的查找速度,加速全切分操作。但是问题在于python的dict原生使用哈希表实现,在dict中获取单词是近乎O(1)的时间复杂度,所以使用trie树,其实是一种避重就轻的做法。
前缀数组
在2014年的某次PR中(https://github.com/fxsjy/jieba/pull/187 ),提交者将trie树改成前缀数组,大大地减少了内存的使用,加快了查找的速度。
现在jieba分词对于词典的操作,改为了一层word:freq的结构,存于lfreq中,其具体操作如下:
1.对于每个收录词,如果其在lfreq中,则词频累积,如果不在则加入lfreq
2.对于该收录词的所有前缀进行上一步操作,如单词'cat',则对c, ca, cat分别进行第一步操作。除了单词本身的所有前缀词频初始为0.
def gen_pfdict(self, f): lfreq = {} ltotal = 0 f_name = resolve_filename(f) for lineno, line in enumerate(f, 1): try: line = line.strip().decode('utf-8') word, freq = line.split(' ')[:2] freq = int(freq) lfreq[word] = freq ltotal += freq for ch in xrange(len(word)): wfrag = word[:ch + 1] if wfrag not in lfreq: lfreq[wfrag] = 0 except ValueError: raise ValueError( 'invalid dictionary entry in %s at Line %s: %s' % (f_name, lineno, line)) f.close() return lfreq, ltotal
很朴素的做法,然而充分利用了python的dict类型,效率提高了不少。
jieba分词有多种模式可供选择。可选的模式包括:
全切分模式
精确模式
搜索引擎模式
# encoding=utf-8 import jieba seg_list = jieba.cut("我来到北京清华大学", cut_all=True) print("Full Mode: " + "/ ".join(seg_list)) # 全模式 seg_list = jieba.cut("我来到北京清华大学", cut_all=False) print("Default Mode: " + "/ ".join(seg_list)) # 精确模式 seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式 print(", ".join(seg_list)) seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式 print(", ".join(seg_list))
输出结果为:
【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学 【精确模式】: 我/ 来到/ 北京/ 清华大学 【新词识别】:他, 来到, 了, 网易, 杭研, 大厦 (此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了) 【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造

 浙公网安备 33010602011771号
浙公网安备 33010602011771号