
Context-Aware Multi-View Summarization Network for Image-Text Matching
- 目的
- 1.1 目标
- 1.2 困难
- 实现策略
- 2.1 网络结构
- 2.2 AGSA模块
- 2.3 图像嵌入模块
- 2.4 文本嵌入模块
- 实验结果
-
目的
-
1.1 目标
- 为了解决多模态情况下,降低文本与图像的不一致性,解决匹配(align)问题
-
1.2 困难
-
文本表示的多样性(多段文字都可以表示一张图像)、图像识别的困难性等
![]()
-
-
-
实现策略
-
2.1 网络结构
-
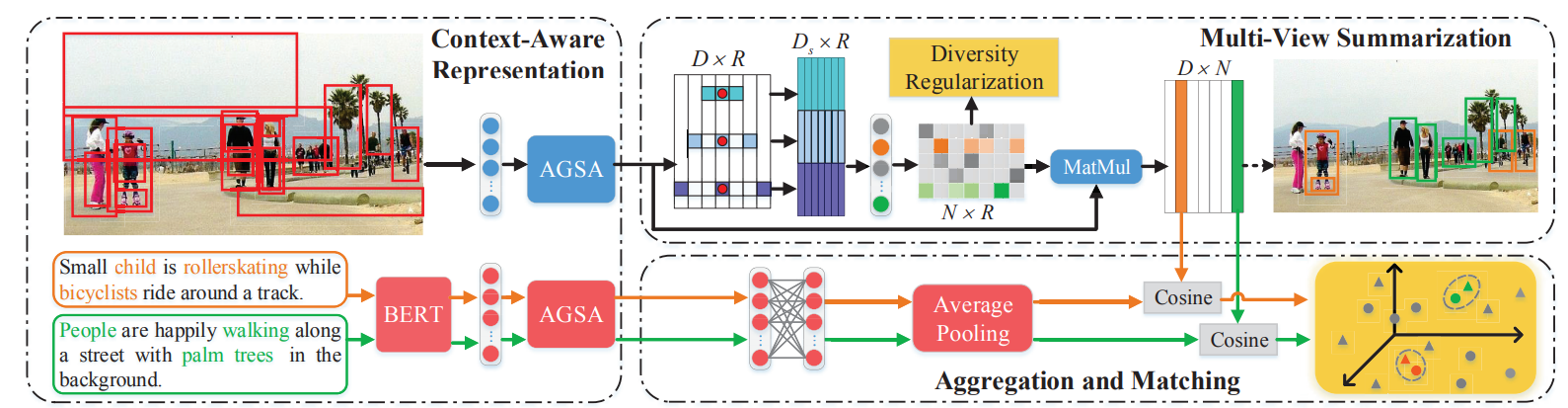
网络结构如下,主要分为三个模块,第一个是图像嵌入模块,第二个是文本嵌入模块,第三个是对loss的设计
![]()
-
-
2.2 AGSA模块
-
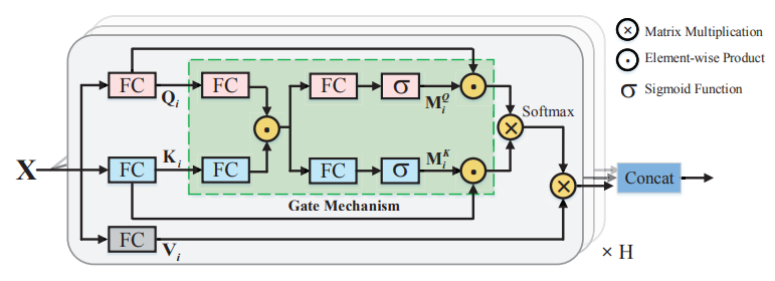
网络结构中多次用到AGSA模块,它主要是为了利用模态间的信息引入的,目的是提高图像和文本的表示能力,它的结构是
![]()
其中FC层表示全连接层,点表示逐像素相乘,X表示矩阵相乘,可以明显的看到这里利用了注意力机制。
它的处理过程主要有
![]()
这里X代表输入,W代表全连接层参数,Q,K,V分别代表之后的输出,可以从图中进行参考。之后进行
![]()
得到G,其中W为可学习的全连接参数,Q,K为上层的输出,b为偏置项。
再之后,经过FC层和激活函数,得到M,同前面类比,W为参数,b为偏置项,G为上层的输出
![]()
最后使用得到的注意力机制提取的特征,具体的,若设
![]()
显然这里Q,K做积,正则化后过softmax层,最后与原始向量V相乘,我们可以借助attention函数表示处理过程为
![]()
其中M为上层得到的输出,Q,K为一开始经过FC层的输出,V为原始向量经过一层FC得到的输出(请参阅图示)
得到最后的表示h_i,最后,由于存在多个这样的X,我们将结果拼接后与原始向量相加,便于提高学习效率
![]()
-
-
2.3 图像嵌入模块
首先使用Bottom-up Feature Extraction提取出分数最高的R个ROIs,然后他们的区域信息表示成
![]()
x,y表示该区域最左上角那个像素在整个图像的坐标,w,h表示区域所占的长和宽
同时,使用平均池化将得到的第i个ROI表示成向量的形式,即
![]()
最用用f过全连接层,得到v
![]()
其中w仍然是可学习的参数,b为偏置项
为了将区域信息在全局角度上审视,将p进行规范化,如下
![]()
其中w,h,表示全局长宽,带下标i的表示某个区域的长宽
然后过全连接层和激活函数
![]()
将之前得到的vi与现在的pi分别进行拼接,得到V,P作为嵌入,点乘后通过AGSA模块
![]()
得到上下文增强的区域特征矩阵(context-enhanced region feature matrix)
论文中还引入了空洞卷积形成金字塔,对图像的区域信息进行描述,给出K个空洞卷积核,对图像进行卷积,得到输出后拼接,具体地,
![]()
之后过全连接层和softmax层,形式化如下
![]()
参数的意义是十分明显的,W,b,依旧和前面一致。
最后用S增强V,得到V*
![]()
-
2.4 文本嵌入模块
文本嵌入比较简单,主要是先使用一个训练过的BERT进行处理,得到文本嵌入E,而后经过一个全连接层,再过一个AGSA模块,最后经过两个全连接层并与原始输入进行相加,形成残差,最后对其求期望,得到标准化的表示,作者称为context-enhanced sentence feature vector
![]()
-
loss函数
对loss的函数主要使用cos函数进行度量,主要策略是
![]()
其中V,Z是前面得到的图像和文本的嵌入,cos代表标准cosine函数,LR是所设计的部分loss函数
另外,还要对模态间的差异进行最小化,具体地
![]()
其中S经由之前的S得到,并取其L2范数,U代表单位矩阵,范数取frobenius norm
最后将两部分loss融合,加入超参数λ
![]()
-
-
实验结果
-
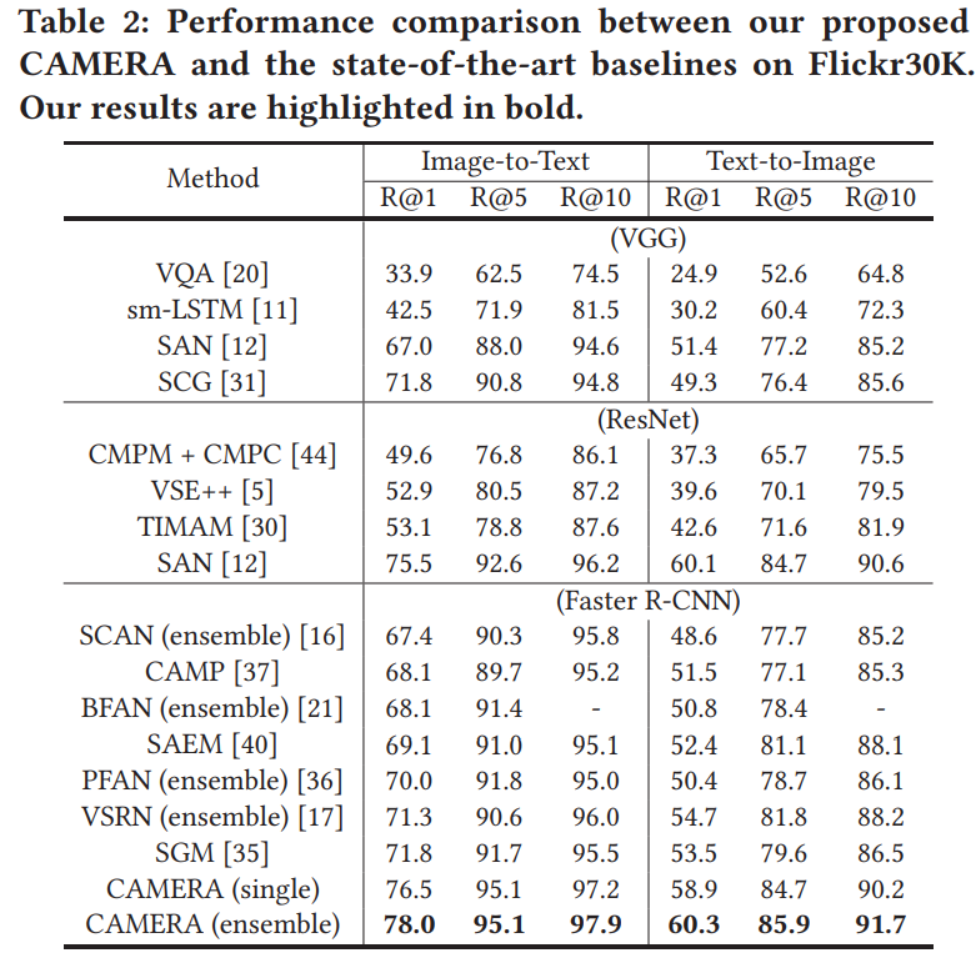
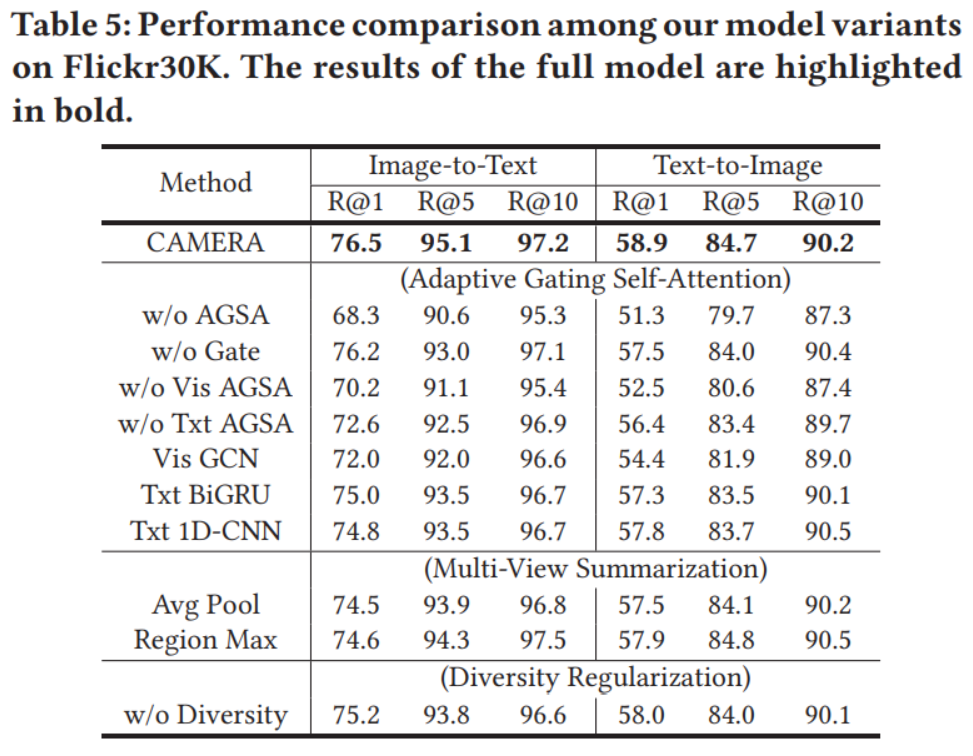
作者使用了多个数据集进行了实验,并进行了消融实验,我们仅取一部分作为代表
![]()
![]()
-

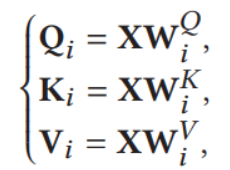
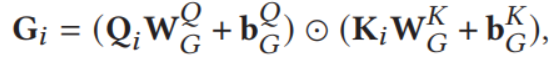
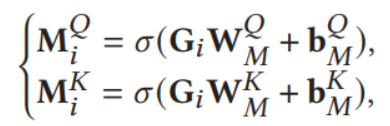

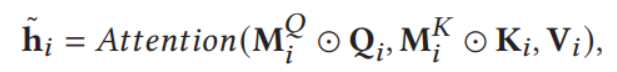
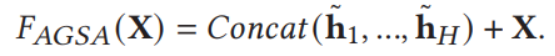
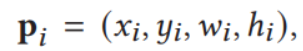
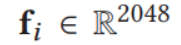

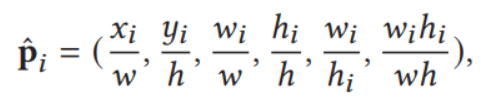
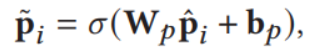
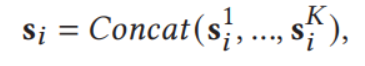
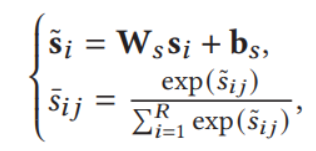
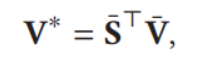
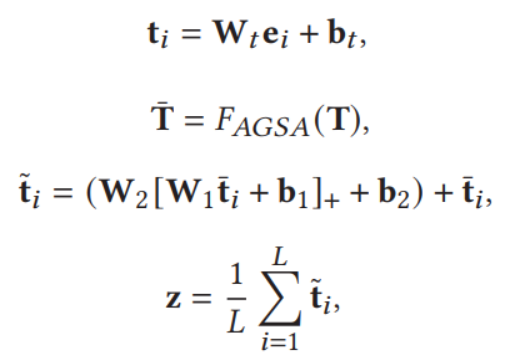
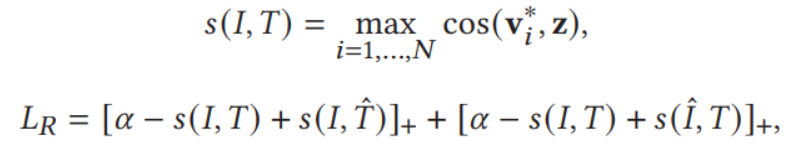
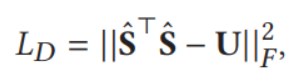
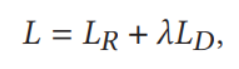

 浙公网安备 33010602011771号
浙公网安备 33010602011771号