
Bias and Variance 偏置和方差
偏置和方差
参考资料:http://scott.fortmann-roe.com/docs/BiasVariance.html
http://www.cnblogs.com/kemaswill/
Bias-variance 分解是机器学习中一种重要的分析技术。给定学习目标和训练集规模,它可以把一种学习算法的期望误差分解为三个非负项的和,即本真噪音、bias和 variance。
本真噪音是任何学习算法在该学习目标上的期望误差的下界;( 任何方法都克服不了的误差)
bias
度量了某种学习算法的平均估计结果所能逼近学习目标的程度;(独立于训练样本的误差,刻画了匹配的准确性和质量:一个高的偏置意味着一个坏的匹配)
variance 则度量了在面对同样规模的不同训练集时,学习算法的估计结果发生变动的程度。(相关于观测样本的误差,刻画了一个学习算法的精确性和特定性:一个高的方差意味着一个弱的匹配)
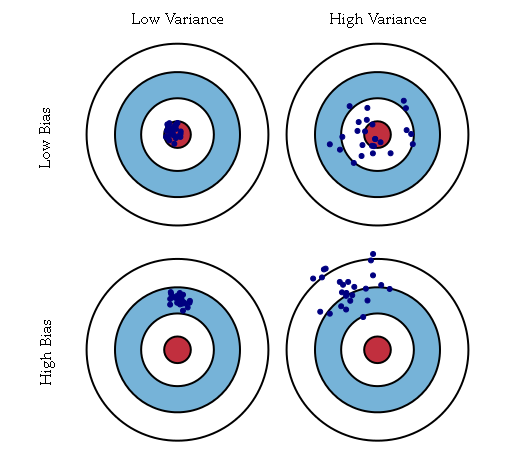
偏置刻画的是构建的模型和真实模型之间的差异。例如数据集所反映的真实模型为二次模型,但是构建的是线性模型,则该模型的结果总是和真实值结果直接存在差异,这种差异是有构建的模型的不准确所导致的,即为偏置bias;如上图中的下面两个图,真实的模型是红心(即每次都是要瞄准红心的),但是构建的模型是偏离红心的(即在射击时瞄准的是红心偏上方向)。
方差刻画的是构建的模型自身的稳定性。例如数据集本身是二次模型,但是构建的是三次模型,对于多个不同的训练集,可以得到多个不同的三次模型,那么对于一个固定的测试点,这多个不同的三次模型得到多个估计值,这些估计值之间的差异即为模型的方差;如上图中的右侧两图,不论构建的模型是否是瞄准红心,每个模型的多次结果之间存在较大的差异。
偏置-方差分解(Bias-Variance Decomposition)是统计学派看待模型复杂度的观点。
假设我们有K个数据集,每个数据集都是从一个分布p(t,x)中独立的抽取出来的(t代表要预测的变量,x代表特征变量)。对于每个数据集D,我们都可以 在其基础上根据学习算法来训练出一个模型y(x;D)来。在不同的数据集上进行训练可以得到不同的模型。学习算法的性能是根据在这K个数据集上训练得到的 K个模型的平均性能来衡量的,亦即:

其中的h(x)代表生成数据的真实函数,亦即t=h(x).
我们可以看到,给定学习算法在多个数据集上学到的模型的和真实函数h(x)之间的误差,是由偏置(Bias)和方差(Variance)两部分构成的。其 中偏置描述的是学到的多个模型和真实的函数之间的平均误差,而方差描述的是学到的某个模型和多个模型的平均之间的平均误差。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号