《Unix/Linux系统编程》第四章学习笔记
第四章 并发编程
教材知识点归纳
本章主要讲述并发编程,介绍了并行计算的概念,指出了并行计算的重要性;比较了顺序算法与并行算法,以及并行性与并发性;解释了线程的原理及其相对于进程的优势;介绍了Pthread中的线程操作,包括线程管理函数,互斥量、连接、条件变量和屏障等线程同步工具;通过具体示例演示了如何使用线程进行并发编程,包括矩阵计算、快速排序和 用并发线程求解线性方程组等方法;解释了死锁问题,并说明了如何防止并发程序中的死锁问题。
并行计算导论
在早期,大多数计算机只有一个处理组件,称为处理器或中央处理器(CPU)。受这种硬件条件的限制,计算机程序通常是为串行计算编写的。要求解某个问题,先要设计一种算法,描述如何一步步地解决问题,然后用计算机程序以串行指令流的形式实现该算法。在只有一个 CPU 的情况下,每次只能按顺序执行某算法的一个指令和步骤。但是,基于分治原则(如二叉树查找和快速排序等)的算法经常表现出高度的并行性,可通过使用并行或并发执行来提高计算速度。并行计算是一种计算方案,它尝试使用多个执行并行算法的处理器更快速地解决问题。
过去,由于并行计算对计算资源的大量需求,普通程序员很少能进行并行计算。近年来,随着多核处理器的出现,大多数操作系统(如Linux)都支持对称多处理(SMP)。甚至对于普通程序员来说,并行计算也已经成为现实。显然,计算的未来发展方向是并行计算。因此,迫切需要在计算机科学和计算机工程专业学生的早期学习阶段引入并行计算。
顺序算法 与 并行算法
- 顺序算法:begin-end代码块列出算法。可包含多个步骤,所有步骤通过单个任务依次执行,每次执行一个步骤,全执行完,算法结束。
- 并行算法:cobegin-coend代码块来指定独立任务,所有任务都是并行执行的,紧接着代码块的下一个步骤将只在所有这些任务完成之后执行。
--- 顺序算法 ---|--- 并行算法 ---
begin | cobegin
step_1 | task_1
step_2 | task_2
... | ...
step_n | task_n
end | coend
//next step | //next step
-----------------------------------------------------
并行性与并发性
通常,并行算法只识别可并行执行的任务,但是它没有规定如何将任务映射到处理组件。在理想情况下,并行算法中的所有任务都应该同时实时执行。然而,真正的并行执行只能在有多个处理组件的系统中实现,比如多处理器或多核系统。在单 CPU 系统中,一次只能执行一个任务。在这种情况下,不同的任务只能并发执行、即在逻辑上并行执行。在单CPU系统中,并发性是通过多任务处理来实现的。
线程
原理
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
线程是独立调度和分派的基本单位。线程可以为操作系统内核调度的内核线程
同一进程中的多条线程将共享该进程中的全部系统资源,如虚拟地址空间,文件描述符和信号处理等等。
一个进程可以有很多线程,每条线程并行执行不同的任务。
使用多线程程序设计的好处是显而易见,即提高了程序的执行吞吐率。在单CPU单核的计算机上,使用多线程技术,也可以把进程中负责I/O处理、人机交互而常被阻塞的部分与密集计算的部分分开来执行,编写专门的workhorse线程执行密集计算,从而提高了程序的执行效率。
线程的优点
与进程相比,线程有许多优点。
(1)线程创建和切换速度更快
(2)线程的响应速度更快
(3)线程更适合并行计算
线程的缺点
(1)由于地址空间共享,线程需要来自用户的明确同步。
(2)许多库函数可能对线程不安全。通常,任何使用全局变量或依赖于静态内存内容的函数,线程都不安全。
(3)在单CPU系统上,使用线程解决问题实际上要比使用顺序程序慢
线程操作
线程的执行轨迹与进程类似。
线程可在内核模式或用户模式下执行。
在用户模式下,线程在进程的相同地址空间中执行,但每个线程都有自己的执行堆栈。线程是独立的执行单元,可根据操作系统内核的调度策略,对内核进行系统调用,变为挂起、激活以继续执行等。
线程管理函数
创建线程
使用pthread_create()函数
int pthread_create (pthread_t *pthread_id, pthread_attr_t *attr, void *(*func)(void *), void *arg);
线程ID
使用pthread_equal()函数对线程ID进行比较
int pthread_equal(pthread_t t1,pthread_t t2);
返回值:不同线程返回0,否则返回非0
线程终止
线程可以调用函数进行终止
void pthread_exit(void *status);
返回值:0退出值表示正常终止,非0值表示异常终止
线程连接
一个线程可以等待另一个线程的终止,通过函数终止线程的退出状态。
int pthread_join (pthread_t thread, void **status ptr);
返回值:以status_ptr返回
线程同步
互斥量
最简单的同步工具是锁,它允许执行实体仅在有锁的情况下才能继续执行。在Pthread中,锁被称为互斥量。在使用之前必须对他们进行初始化。
有两种方法可以初始化互斥址:
静态方法:pthreaa—mutex_t m = PTHREAD_MUTEX_INITIALIZER;
定义互斥量 m, 并使用默认属性对其进行初始化。
动态方法:使用 pthread_ mutex _init() 函数,可通过attr参数设置互斥属性。
死锁预防
互斥量使用封锁协议。如果某线程不能获取互斥量,就会被阻塞,等待互斥量解锁后再继续。在任何封锁协议中,误用加锁可能会产生一些问题。最常见和突出的问题是死锁。
有多种方法可以解决可能的死锁问题,其中包括死锁预防、死锁规避、死锁检测和恢复等。
在实际系统中,唯一可行的方法是死锁预防,试图在设计并行算法时防止死锁的发生。一种简单的死锁预防方法是对互斥量进行排序,并确保每个线程只在一个方向请求互斥量,这样请求序列中就不会有循环。
条件变量
作为锁,互斥量仅用于确保线程只能互斥地访问临界区中的共享数据对象。条件变量提供了一种线程协作的方法。在Pthread中,使用类型pthread_cond_t来声明条件变量,而且必须在使用前进行初始化。
条件变量可以通过两种方法进行初始化
静态方法
pthread_cond_t con = PTHREAD_COND_INITALLIZER;
动态方法
使用pthread_cond_init()函数,通过attr参数设置条件变量。
实践代码与截图
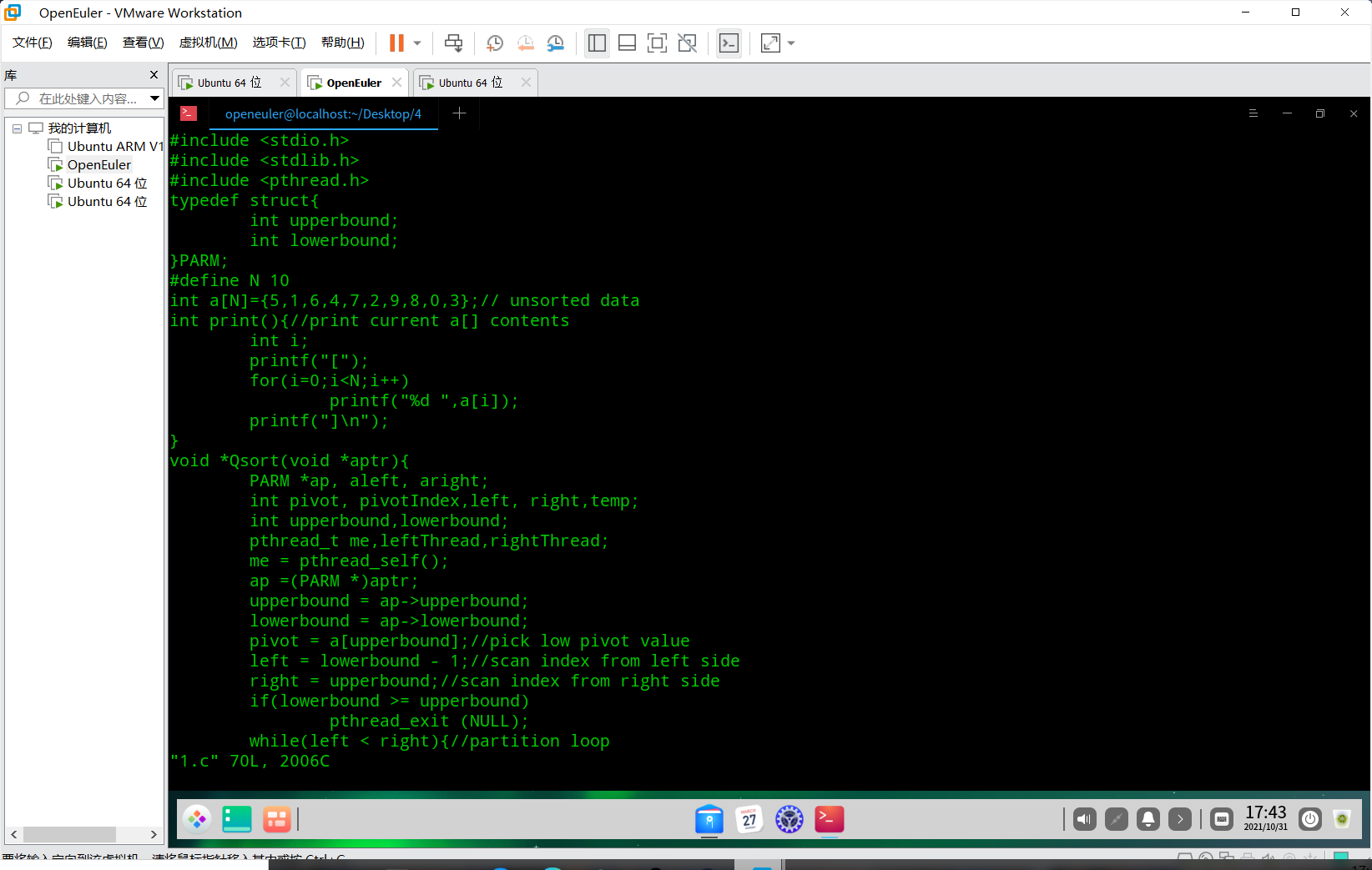
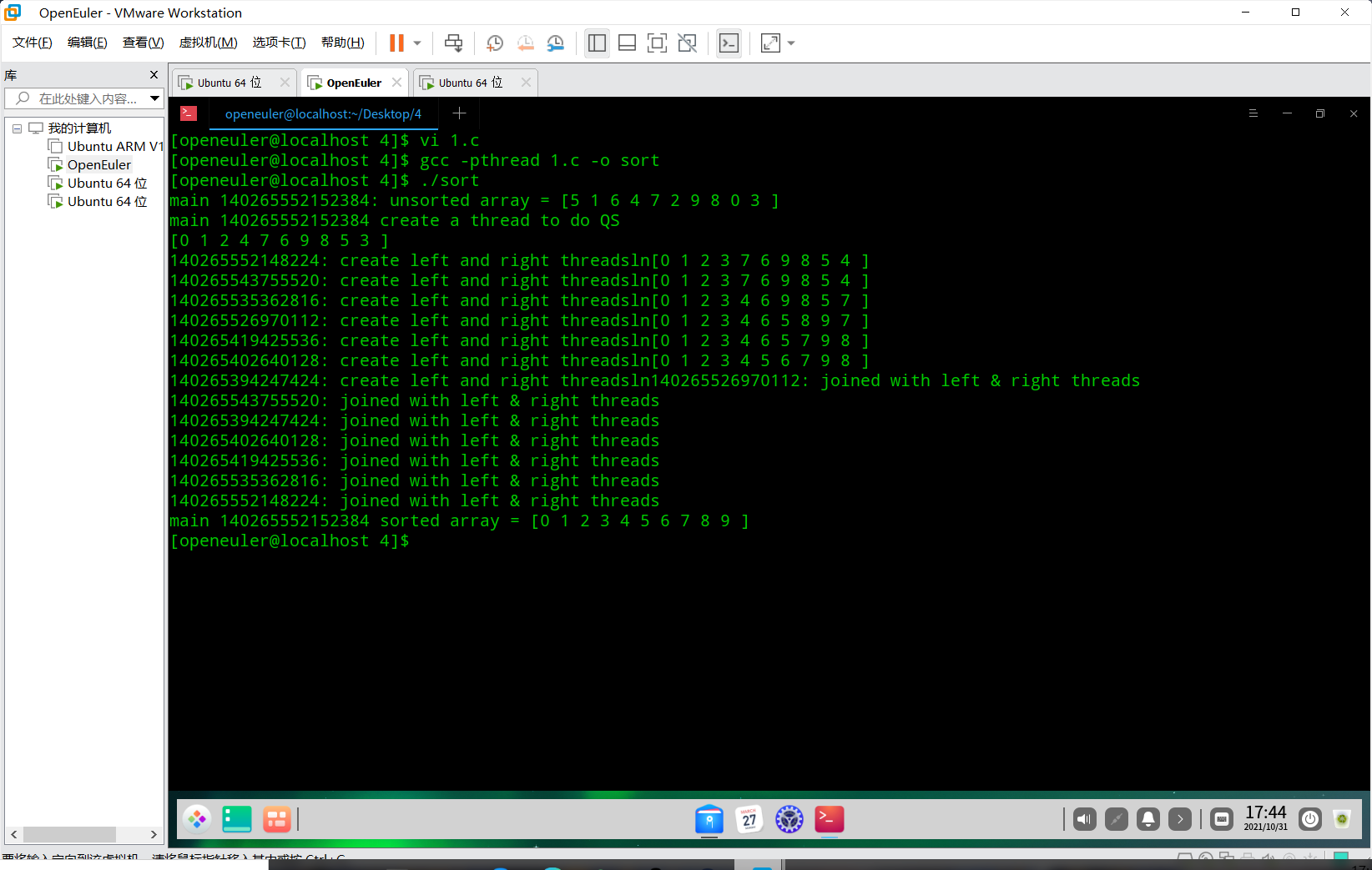
并发线程快速排序
注:需要用gcc -pthread -o quicksort quicksort.c来编译多线程,否则会发生错误。
参考博客pthread_create问题解决
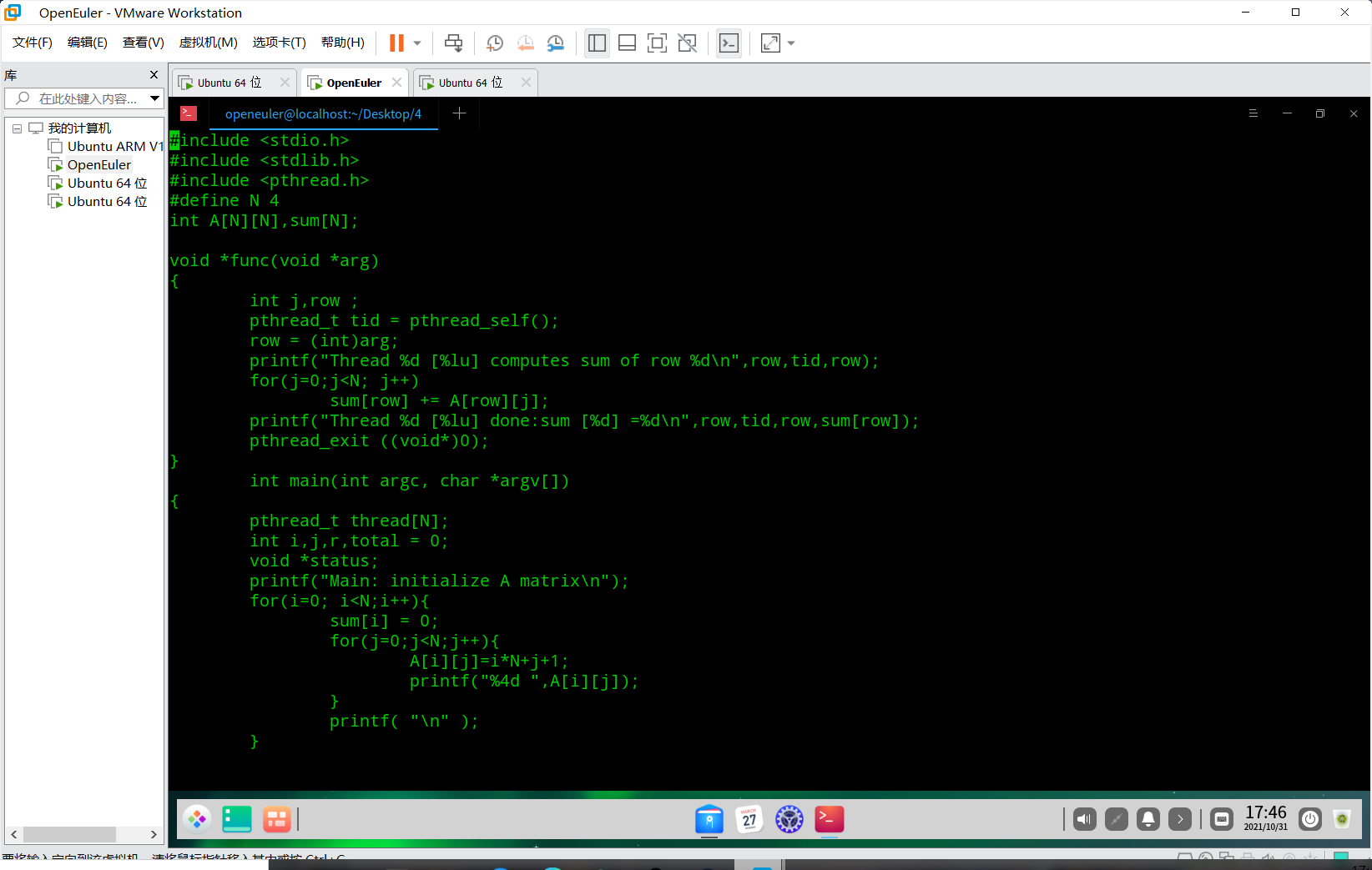
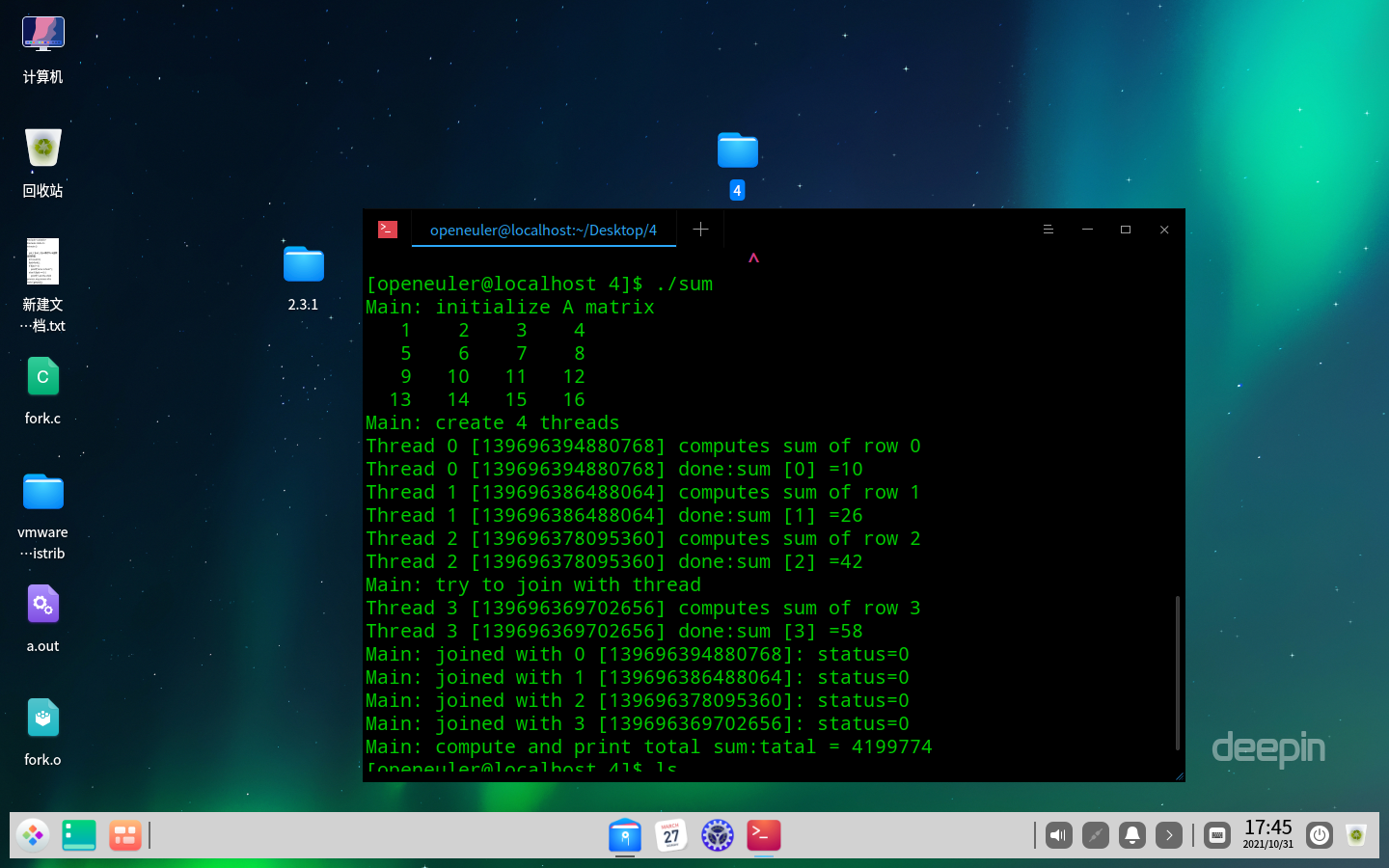
线程计算矩阵的和

 浙公网安备 33010602011771号
浙公网安备 33010602011771号