

微调 - LoRA
一、什么是 LoRA
- 与其说 Lora 是一个算法,不如说 lora 是一个工程技巧?
- 给大模型加几张 “小炒纸”,只训练几张纸,就能让他学会新本事 —— 省时、省力、省钱?
| 方式 | 描述 |
| 全量微调 | 把整本书从头到位重写一遍,加入做菜的知识。费时、费力! |
| LoRA 微调 | 不碰原书的一个字!只给他加几页薄薄的 “做菜速查小贴士”(低秩矩阵)。训练时只更新这几页贴士的内容。需要做菜时,书翻到对应位置看一眼贴士就行。 |
二、LoRA 原理(演示)
2.1、假设大模型原始矩阵 W 的尺寸为 5*4:
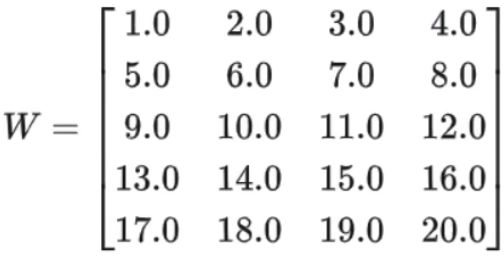
2.2、全量微需要更新 5*4 = 20 个参数,假设微调后的参数是:
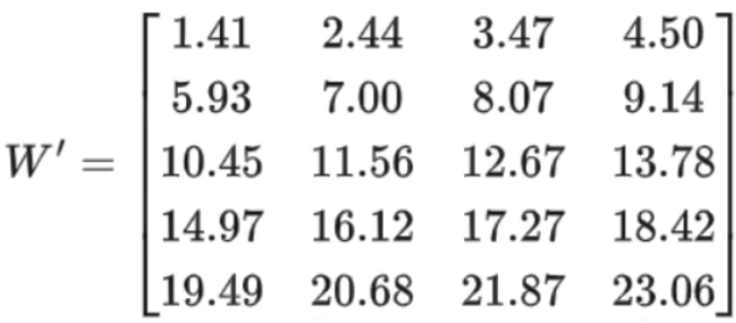
2.3、微调后参数变为 W + ΔW
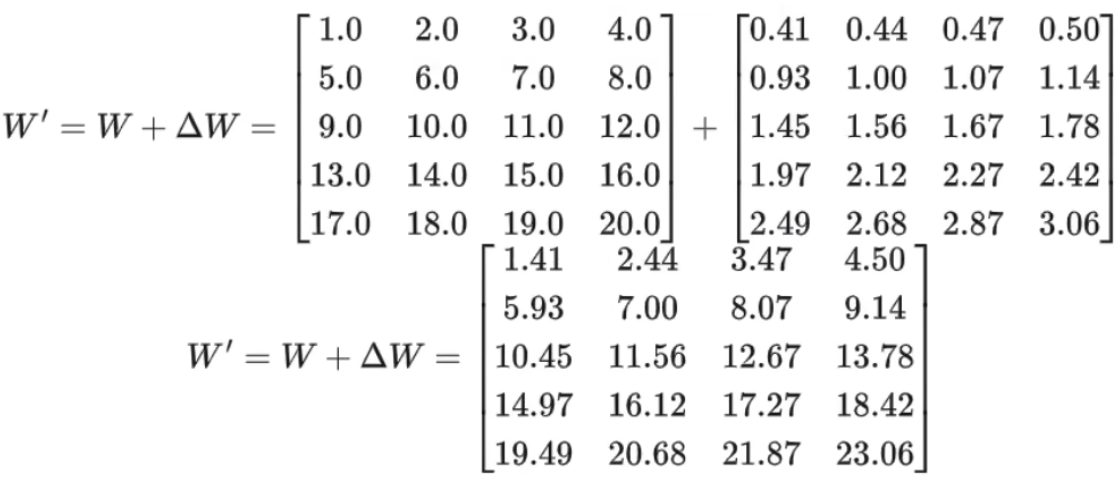
2.4、对于其中增量 ΔW 可通过低秩分解,表示为两个小矩阵的乘积:

具体参数如下:
- 矩阵A:尺寸 5*2,共10个参数
- 矩阵B:尺寸 2*4,共8个参数
- LoRA总参数:10+8=18个参数
结论:LoRA 微调的调参对象从 W 变为 A 和 B,参数量从 20 -> 18
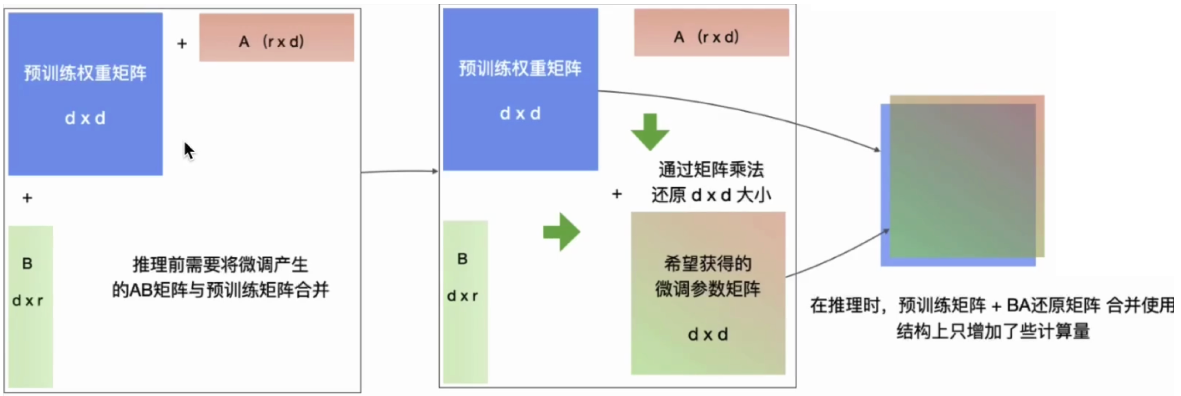
2.5、为什么可以对增量权重 ΔW 做低秩分解?
核心思想:矩阵中的信息往往是不均匀的,很多维度是冗余的,只需抓住 “主要方向” 即可有效表达变化。
在线性代数中,矩阵的秩(rank)是指其线性独立的行或列的数量。
若矩阵为 “低秩”,意味着他的信息可以用少量独立方向表达。
示例:

其中,第五行是前两行的线形组合,未提供新信息;第 5 列全为 0,也无增量信息。
因此,该矩阵的行秩和列秩均为 4。
2.6、实际案例:
一个 512*512 的权重矩阵(共 262,144 参数):
- 全微调:更新全部 262,144 个参数
- LoRA(r=8):仅需
A(512*8)= 4096 + B(8*512)= 4096 => 总计 8,192 参数
=> 参数量减少 97% !
三、LoRA 微调资源消耗
访问 https://llamafactory.cn/gpu-memory-estimation.html 选择「显存计算助手」

选择一个模型后下面就可以看到显存大小
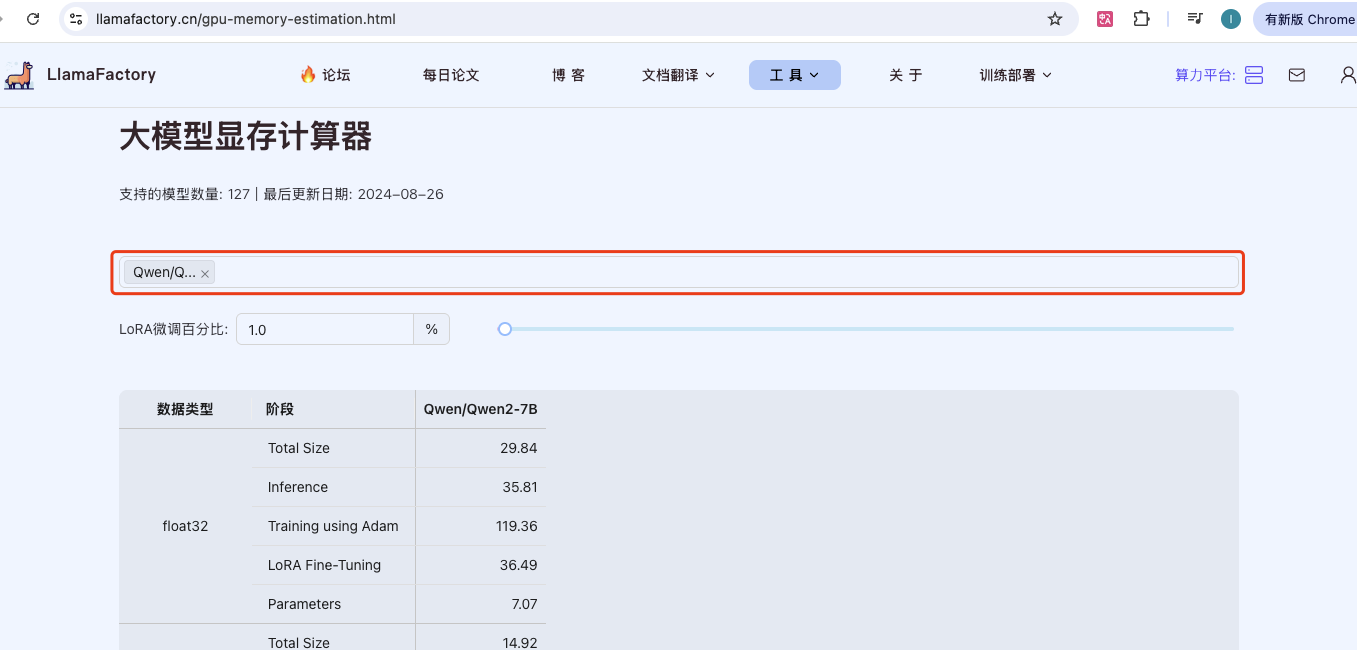
翻到最后,可以看到计算公式和参数解释。

四、LoRA 调参
以 LLaMA-Factory 的配置为例(此处为示意,实际需要结合工具修改):
| 参数 | 说明 |
| r | LoRA 秩(rank),控制 A 和 B 的中间维度 |
| lora_alpha | 缩放系数,常设为 2r 或手动调整 |
| lora_dropout | Dropout 比例,防过拟合(通常 0.05 ~ 0.1) |
| target_modules | 应用 LoRA 的模块(如 q_proj,v_proj,ffn 等) |
实用调参技巧:
- 从小秩开始:大多数任务可以从 r=8 或 r=16 起步,评估效果后再决定是否增大。
- 数据集大小与秩的关系
- 小数据集(<5k 样本):建议 r=8
- 大数据集(>50k 样本):可尝试 r=32 甚至 r=64
- 复杂任务策略。对于复杂推理任务,推荐组合使用:
- 增大 r 至 32 或 64
- 启用 rsLoRA 提升稳定性
- 扩展 target_modules(如,加入 FFN 层)
- 如果 LoRA 训练出现以往时,可以将 rank 调大,如从 r=8 调到 r=64(原因是,与基础模型的数据领域相差较大,则需要更大的秩)
- 基础模型大小选择
- 一般情况,参数越大效果越好,资源允许推荐选择30B以上的模型;
- 参数多量化低的模型要优于参数低量化高的模型,例如:33B-fb4 模型要优于 13b-fb16 模型。
- 训练数据清洗
- 在数据处理过程中,可能会有各种类型数据(例如,PDF、Word、HTML、代码文件等),对于这种不同类型的数据需要都处理成文本,同时还要过滤掉一些干扰项或乱码的数据。
- 对于空的文档或文档长度低于100进行过滤,进一步减少噪音。
五、开源微调项目
1、一个 LoRA 微调开源项目
网址:https://github.com/mymusise/ChatGLM-Tuning/blob/master/finetune.py
2、一个 QLoRA 微调开元项目(微调的 百川 模型)
网址:https://github.com/wp931120/baichuan_sft_lora/blob/main/sft_lora.py
六、实战微调 LoRA 项目
源代码如下:
# -*- coding: utf-8 -*-
import json
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, Trainer, DataCollatorForLanguageModeling
from peft import LoraConfig, get_peft_model, PeftModel
from datasets import Dataset
from modelscope import snapshot_download
def load_dataset(dataset_path: str='./ruozhiba_qa.json', tokenizer=None):
"""
加载数据集并预处理
Args:
dataset_path: 待训练的数据集路径
tokenizer: 分词器,用于对文本进行 tokenize 处理
"""
# 加载数据集
with open(dataset_path, 'r', encoding='utf-8') as f:
data = json.load(f)
# 转换为适合训练的格式(Dataset 格式)
processed_data = []
for item in data:
# 根据模型要求调整输入输出的格式
text = f"Human: {item['instruction']}\nAssistant: {item['output']}"
processed_data.append({'text': text})
# 转换为 Dataset 格式
dataset = Dataset.from_list(processed_data)
# 如果提供了粉刺器,进行 tokenize 处理
if tokenizer is not None:
dataset = dataset.map(
lambda examples: tokenizer(
examples['text'],
truncation=True,
max_length=512 # 根据需要修改
),
batched=True,
remove_columns=dataset.column_names,
)
return dataset
def create_load_model(base_model_path, r: int = 16, device_map: str = "auto", dtype=torch.float32):
"""
创建 LoRA 微调模型
Args:
base_model_path: 基础模型路径
r: LoRA 秩(小数据集(<5k 样本):建议 r=8。大数据集(>50k 样本):可尝试 r=32 甚至 r=64
device_map: 自动设备分配(设备包括:mps-mac系统显卡、cuda-英伟达显卡、cpu)
dtype: 精度,当显存不足时可以调为 float16。包括:float32、float16
"""
# 加载基础模型和分词器
tokenizer = AutoTokenizer.from_pretrained(base_model_path)
# 设置填充令牌
tokenizer.pad_token = tokenizer.eos_token
# 加载基础模型
model = AutoModelForCausalLM.from_pretrained(
base_model_path,
dtype=dtype, # 对 MPS 使用 float32 精度
device_map=device_map, # 自动设备分配(设备包括:mps-mac系统显卡、cuda-英伟达显卡、cpu)
)
# 配置模型 pad token
model.config.pad_token_id = model.config.eos_token_id
# 冻结原始模型参数
for param in model.parameters():
param.requires_grad = False
# LoRA 配置
lora_config = LoraConfig(
r=r, # LoRA 秩
lora_alpha=32, # 缩放因子
lora_dropout=0.1, # Dropout 比率
bias="none", # 是否训练偏置
task_type="CAUSAL_LM",
target_modules=[
"q_proj",
"k_proj",
"v_proj"
],
)
# 应用 LoRA
pef_model = get_peft_model(model, lora_config)
# 打印可训练参数
pef_model.print_trainable_parameters()
return pef_model, tokenizer
def train_lora_model(base_model_path, r: int = 16, device_map: str = "auto", dtype=torch.float32, dataset_path='ruozhiba_qa.json', output_dir='./lora_output'):
"""
LoRA 微调训练
Args:
base_model_path: 基础模型路径
r: LoRA 秩(小数据集(<5k 样本):建议 r=8。大数据集(>50k 样本):可尝试 r=32 甚至 r=64
device_map: 自动设备分配(设备包括:mps-mac系统显卡、cuda-英伟达显卡、cpu)
dtype: 精度,当显存不足时可以调为 float16。包括:float32、float16
dataset_path: 待训练的数据集路径
output_dir: 训练后的 LoRA 权重保存目录
"""
# 创建 LoRA 模型
model, tokenizer = create_load_model(base_model_path, r=r, device_map=device_map, dtype=dtype)
# 加载数据集并 tokenize
train_dataset = load_dataset(dataset_path, tokenizer)
# 数据集收集器
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False, # 因为是因果语言模型,所以不使用 MLM
)
# 训练参数
training_args = TrainingArguments(
output_dir=output_dir,
num_train_epochs=3,
per_device_train_batch_size=1, # 在 MPS 上可能需要更小的 batch size
gradient_accumulation_steps=4, # 模拟更大的 batch size
learning_rate=1e-4,
logging_steps=10,
remove_unused_columns=False,
push_to_hub=False,
logging_dir='./logs',
)
# 训练器
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
data_collator=data_collator,
)
# 开始训练
trainer.train()
# 保存 LoRA 权重
model.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
def inference_lora_model(base_model_path, lora_path='./lora_output', dtype=torch.float32):
"""
使用 LoRA 微调后的模型进行推理
Args:
base_model_path: 基础模型路径
lora_path: LoRA 训练后的权重路径
dtype: 精度,当显存不足时可以调为 float16。包括:float32、float16
"""
# 加载原始模型
model = AutoModelForCausalLM.from_pretrained(
base_model_path,
dtype=dtype, # 使用 float32 精度
)
tokenizer = AutoTokenizer.from_pretrained(base_model_path)
# 加载 LoRA 权重
model = PeftModel.from_pretrained(model, lora_path)
# 合并 LoRA 权重到原始模型
model = model.merge_and_unload()
# 设置填充令牌
tokenizer.pad_token = tokenizer.eos_token
model.config.pad_token_id = model.config.eos_token_id
# 测试推理
test_prompts = [
"只剩一个心脏了还能活吗?",
"如何知道学习一门编程语言?",
"你是谁?能帮我解决什么问题?",
]
for prompt in test_prompts:
# 构造完整的输入
full_prompt = f"Human: {prompt}\nAssistant:"
inputs = tokenizer(full_prompt, return_tensors="pt")
outputs = model.generate(
**inputs,
max_length=100,
num_return_sequences=1,
temperature=0.7,
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"提示:{prompt}")
print(f"回复:{generated_text}\n")
def merge_and_save_lora_model(base_model_path, lora_path='./lora_output', dtype=torch.float32, save_path='./model_output'):
"""
合并 LoRA 权重到基础模型并保存为完整模型
Args:
base_model_path: 基础模型路径
lora_path: LoRA 训练后的权重路径
dtype: 精度,当显存不足时可以调为 float16。包括:float32、float16
save_path: 合并后模型的保存路径
"""
# 加载原始模型
model = AutoModelForCausalLM.from_pretrained(
base_model_path,
dtype=dtype,
)
tokenizer = AutoTokenizer.from_pretrained(base_model_path)
# 加载 LoRA 权重
model = PeftModel.from_pretrained(model, lora_path)
# 合并 LoRA 权重到原始模型
model = model.merge_and_unload()
# 设置填充令牌
tokenizer.pad_token = tokenizer.eos_token
model.config.pad_token_id = model.config.eos_token_id
# === 保存合并后的模型 ===
print(f"开始保存合并后的模型到 {save_path}")
model.save_pretrained(save_path)
tokenizer.save_pretrained(save_path)
# 可选:保存为 safetensors 格式(更安全)
model.save_pretrained(
save_path,
safe_serialization=True # 这会生成 .safetensors 文件
)
tokenizer.save_pretrained(save_path)
print("模型保存完成!")
def download(model_id: str = "LLM-Research/Llama-3.2-1B"):
"""下载基础模型"""
# 从ModelScope下载模型--第一次比较耗时
base_model_path = snapshot_download(
model_id=model_id,
cache_dir="./model_cache",
)
if __name__ == "__main__":
model_id="LLM-Research/Llama-3.2-1B" # 模型 id,可以从 https://modelscope.cn/ 查找对应 model_id
base_model_path = "./model_cache/LLM-Research/Llama-3___2-1B" # 基础模型下载后保存的本地路径
dataset_path = "./ruozhiba_qa.json" # 待训练的数据集路径
r=16 # LoRA 秩(小数据集(<5k 样本):建议 r=8。大数据集(>50k 样本):可尝试 r=32 甚至 r=64
device_map="mps" # 自动设备分配(设备包括:auto-自动检测,不要使用auto,可能回报错、mps-mac系统显卡、cuda-英伟达显卡、cpu)
dtype=torch.float32 # 精度,当显存不足时可以调为 float16。包括:float32、float16
# 1、下载基础模型
# download(model_id)
# 2、训练 LoRA 模型
train_lora_model(base_model_path, r=r, device_map=device_map, dtype=dtype, dataset_path=dataset_path)
# 3、使用 LoRA 微调后的模型进行推理(测试)
# inference_lora_model(base_model_path, dtype=dtype)
# 4、合并 LoRA 权重到基础模型并保存为完整模型
# merge_and_save_lora_model(base_model_path, dtype=dtype)
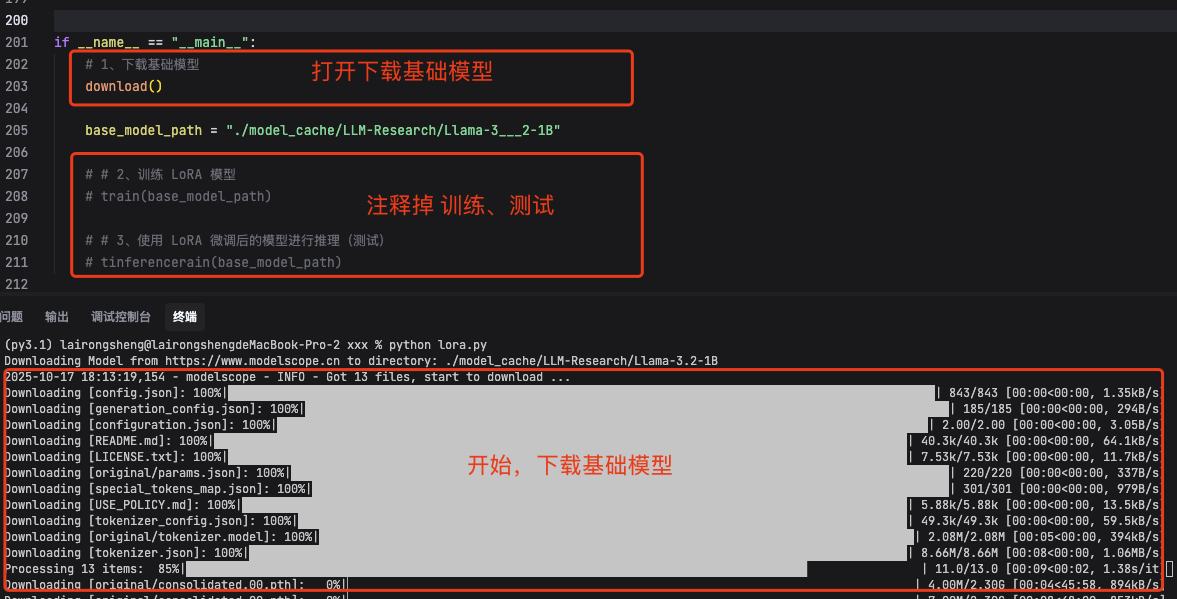
1、下载基础模型
按照下图打开下载基础模型代码,运行。
2、训练模型
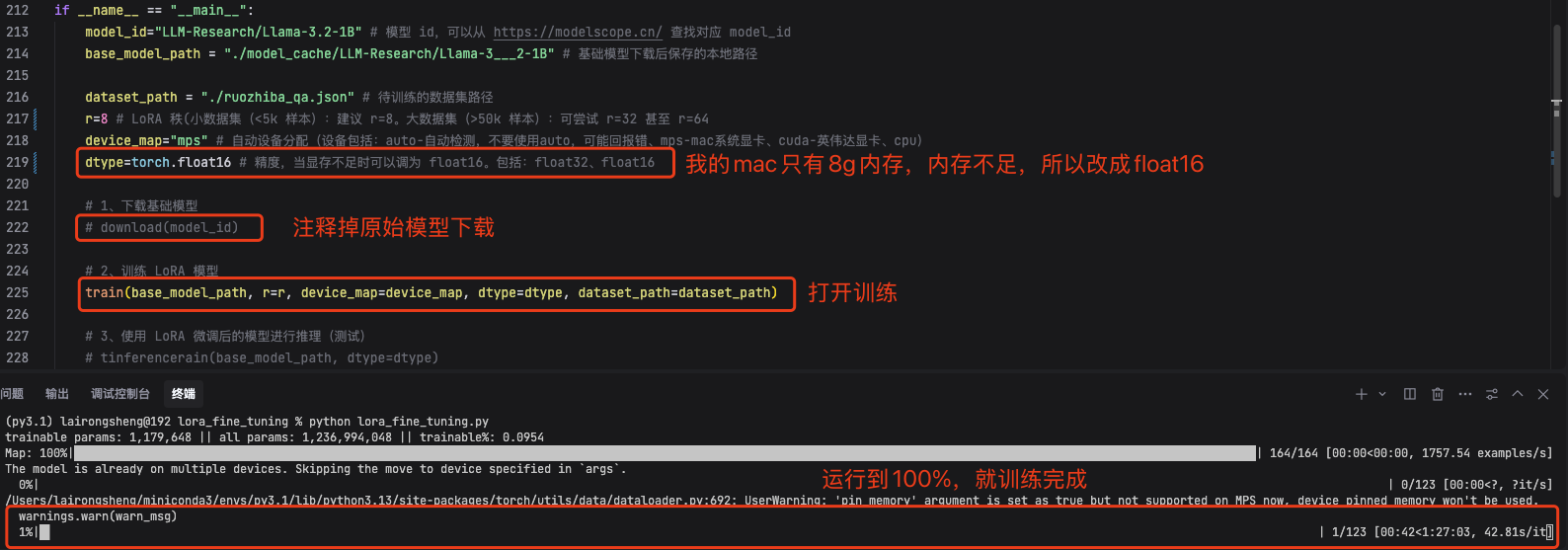
3、测试训练后的效果
打开 tinferencerain 后就可以测试训练后的效果,如下图

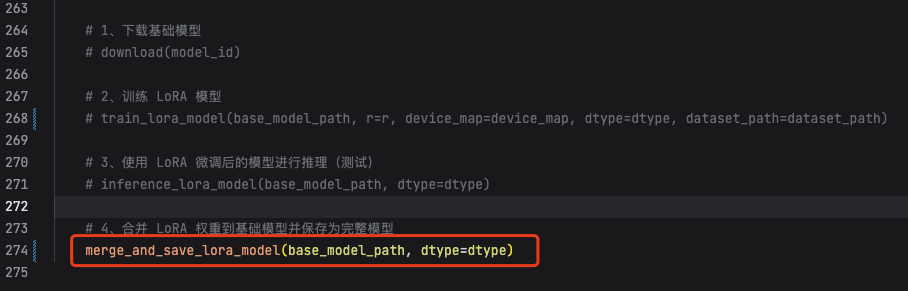
4、合并 LoRA 权重到基础模型并保存为完整模型
打开 merge_and_save_lora_model 后重新运行即可,如下图
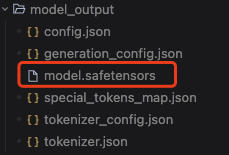
模型生成后会保存到 model_output 目录中,模型文件是 model.safetensors,如下图。
当然这个合并后的模型就可以直接上传 modescope 或 Hugging Face 等平台了。
5、将生成的模型导入 ollama 中使用
参考文档 ollama 安装 HuggingFace 上的模型 中的 「四、ollama 安装 新型安全模型存储格式(.safetensors)模型」,先将 safetensors 格式转为 GGUF 格式后就可以导入 ollama 了。
如果你的显存不足,想调整量化精度可以在转为 GGUF 格式增加 --outtype 参数,例如:
python convert_hf_to_gguf.py /Users/rslai/Desktop/bge-reranker-v2-m3 --outtype q8_0 --outfile /Users/rslai/Desktop/e/bge-reranker-v2-m3.gguf
目前我用的 llama.cp 参数 outtype 支持如下:
- f32:32位浮点数(全精度),最大精度,文件体积最大
- f16:16位浮点数(半精度),精度较高,文件体积减半
- bf16:Brain Float 16 专为AI训练设计,动态范围更大,适合特定硬件和训练场景
- q8_0:8位量化,权重以8位存储,质量损失很小,体积比f16小约25%,性能接近f16
- tq1_0:1位量化(极强压缩),文件体积最小,质量损失较大
- tq2_0:2位量化,比1位量化质量更好,体积仍然很小

 浙公网安备 33010602011771号
浙公网安备 33010602011771号