
RAGFlow - 第一个知识库&聊天 (一)
一、注册 RAGFlow 账号
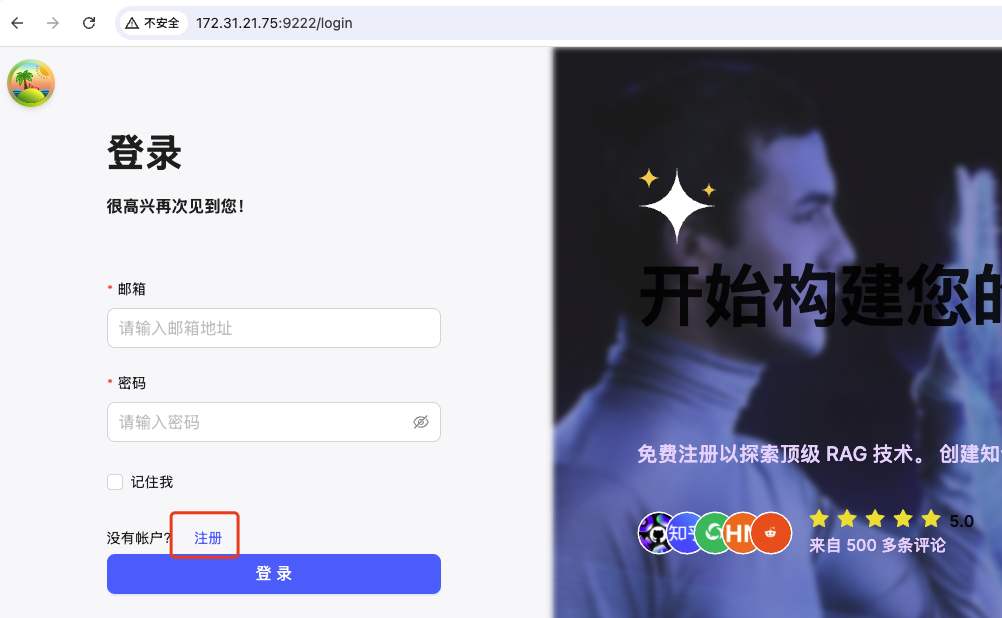
如下图点击 “注册” 根据提示注册账号即可。
二、配置模型
在使用知识库之前必须要先配置模型,如下图
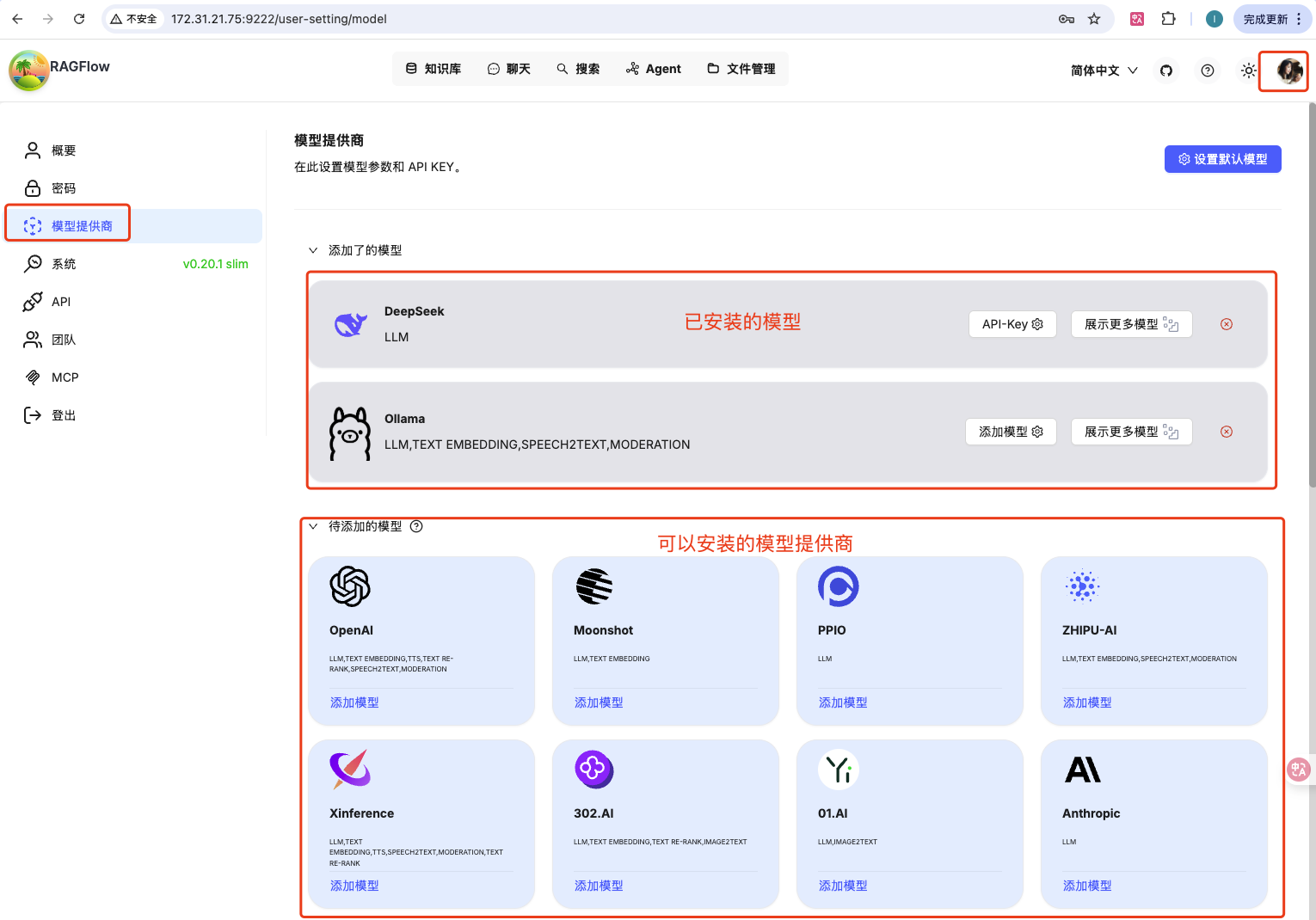
1、添加 DeepSeek 模型
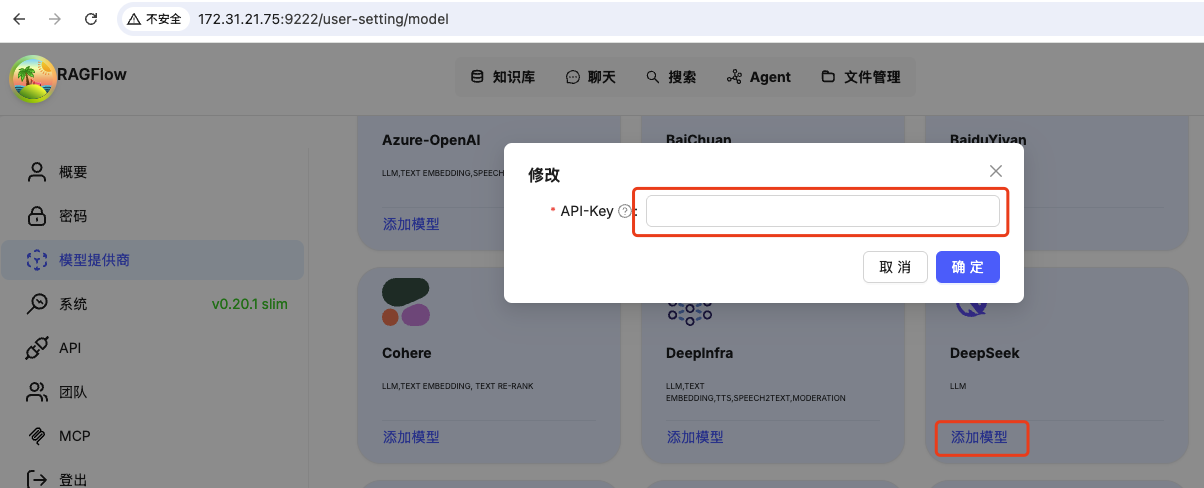
按下图添加 DeepSeek api key 即可。
2、添加 Ollama 模型
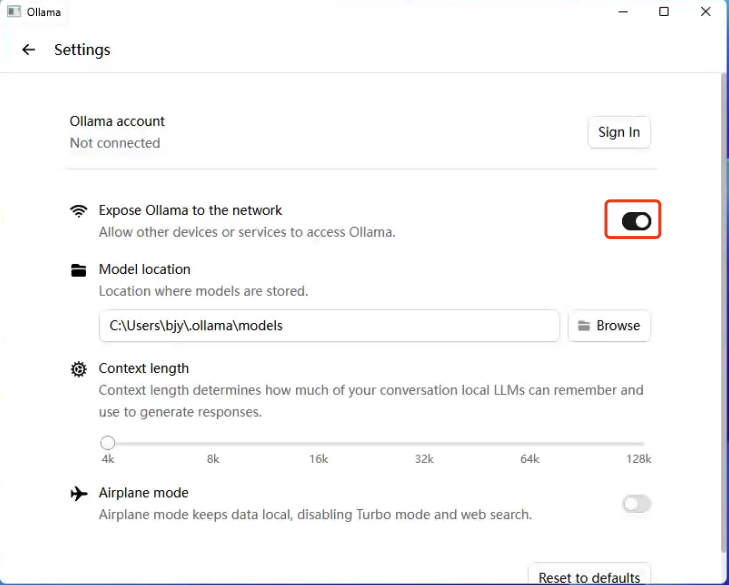
A)配置允许网络访问
B)添加 Ollama 模型
其中:
模型类型: 根据你要添加的模型类型选择 chat、embedding、rerank、image2text
模型名称: 就是执行 ollama list 命令后显示的第一列的名称
基础 Url: 就是安装 ollama 机器的 ip 地址

3、添加 Ollama Embedding 模型
在添加知识库前需要有 Embedding 模型,用来做文档切分,以便存入向量数据库。
A)bge-m3:latest
RAGFlow 默认模型 bge-m3:latest,参见文档 安装 ollama 及安装模型(https://www.cnblogs.com/rslai/p/19045196)
或者执行命令 ollama pull bge-m3:latest 在 ollama 中安装模型
B)bge-large-zh
号称最好用的中文 Embedding 模型(我试用下来跟 bge-m3:latest 没啥区别)。参见文档 ollama 安装 HuggingFace 上的模型(https://www.cnblogs.com/rslai/p/19045841)
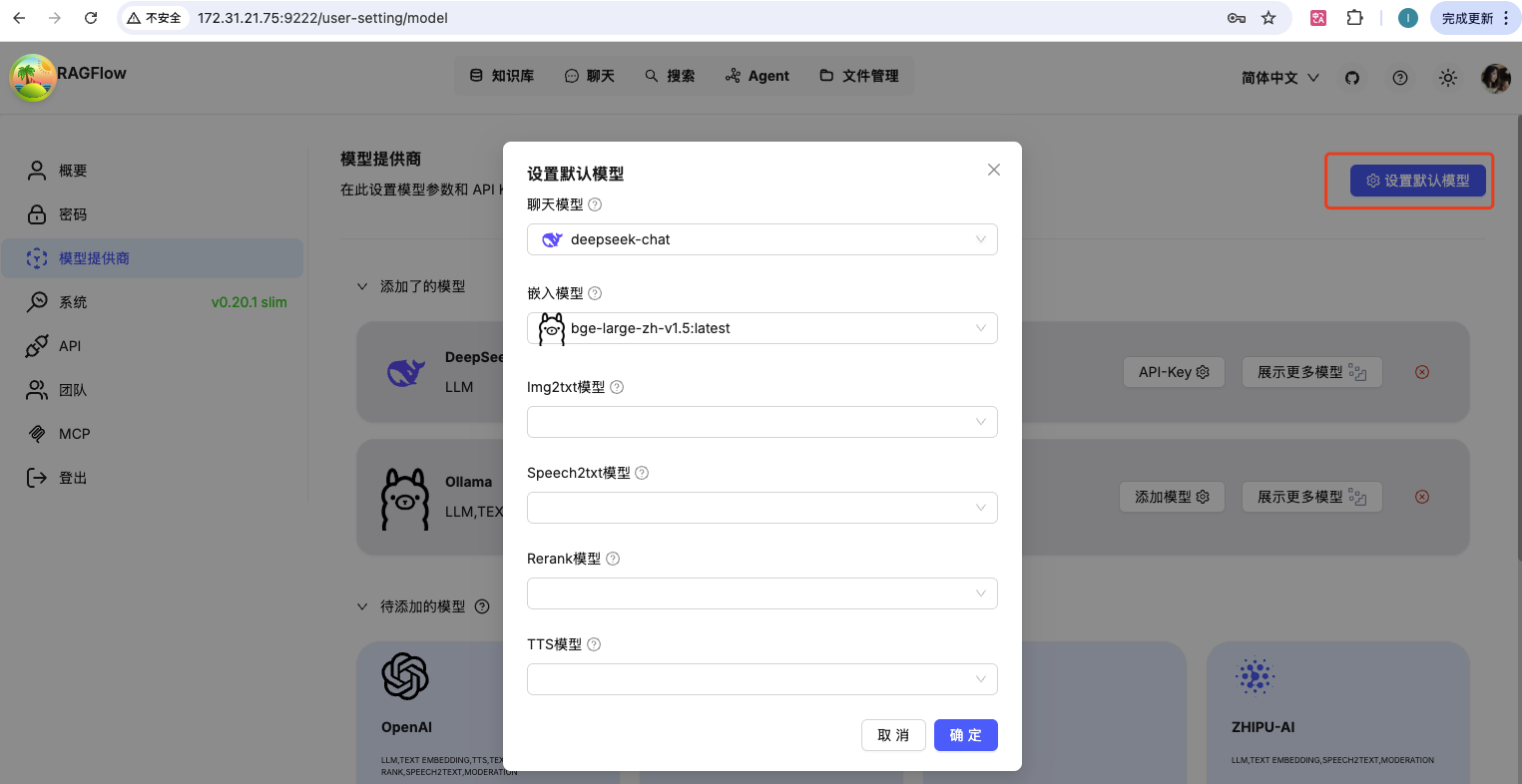
4、设置默认模型
如下图可以设置默认模型,这样在后续操作时不用每次都选。
5、模型类型说明
A)Chat模型 (AI的“嘴皮子”)
- 干啥用的:负责和你聊天对话,生成人类能看懂的回答
- 经典模型:Llama3、Qwen、GPT、DeepSeek
- 举个栗子 : 当你问“如何安装Ollama”,Chat模型就会像话痨同事一样,把安装步骤一条条讲给你听
- 选型秘诀:
- 需要“话多且准”:选参数大的模型(比如70B)
- 电脑配置低:用7B小模型(虽然可能胡说八道)
B)Embedding模型 (文字“翻译官”)
- 干啥用的:把文字变成一串数字(向量),方便计算机理解语义
- 经典模型:BGE、text2vec、OpenAI的text-embedding-3-small
- 灵魂比喻: 相当于给每句话发一个身份证号,说“春天”和“花开”的号码接近,“冰箱”和“宇宙”的号码离得远
- 选型秘诀:
- 中文优先:选bge-large-zh这类中文专用模型
- 速度优先:用small版(精度会下降)
C)Rerank模型 (结果“质检员”)
- 干啥用的:对搜索出的100条结果重新打分,把最相关的排到最前面
- 经典模型:bge-reranker、cohere-rerank
- 举个栗子 : 你搜“苹果”,初步结果可能包含水果、手机、电影公司。Rerank模型会说:“根据上下文,用户其实想查iPhone”,然后把手机相关结果置顶
- 选型秘诀:
- 精准度 vs 速度:大模型准但慢,小模型快但糙
- 可选项少:目前主流就2-3种
D)Image2Text模型 —— 图片的“解码器”
- 干啥用的:把图片里的文字抠出来(比如扫描版PDF/照片里的文字)
- 经典模型:PaddleOCR、Donut、EasyOCR
- 灵魂场景: 你上传一张表情包截图,AI能读出上面的字:“一键三连的都是帅哥美女!”
- 选型秘诀:
- 中文场景:优先选PaddleOCR(国产之光)
- 复杂排版:用Donut(但吃显卡)
三、添加知识库
1、创建知识库
输入名称后即可创建知识库

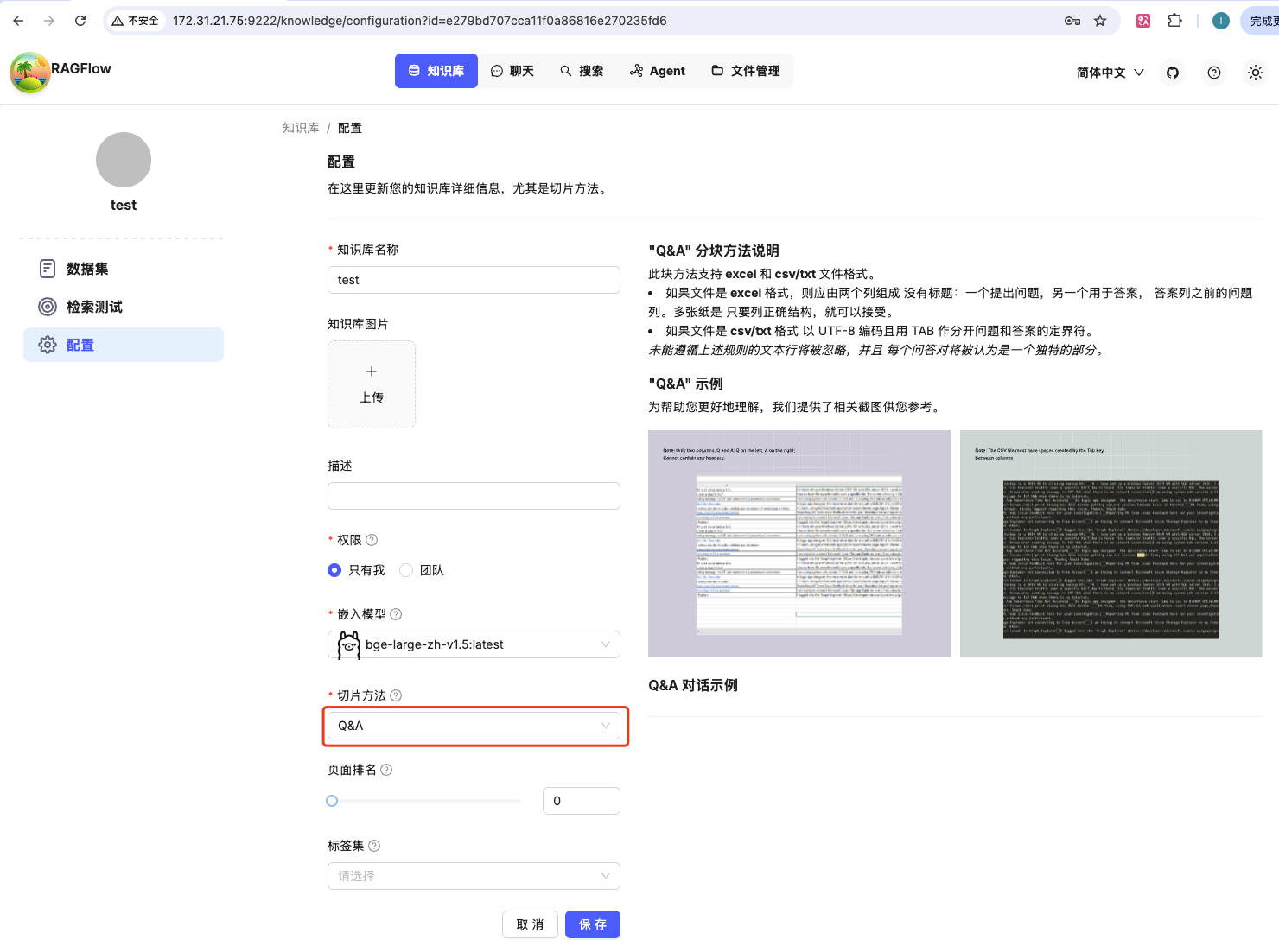
2、配置切片方法
默认 General,它支持的格式较多但需要通过分段标识来分块。
选 Q&A 按照问答对的方式添加知识库。注意上传 excel 的时候第一列是 问题,第二列是 回答,不要要写列头。
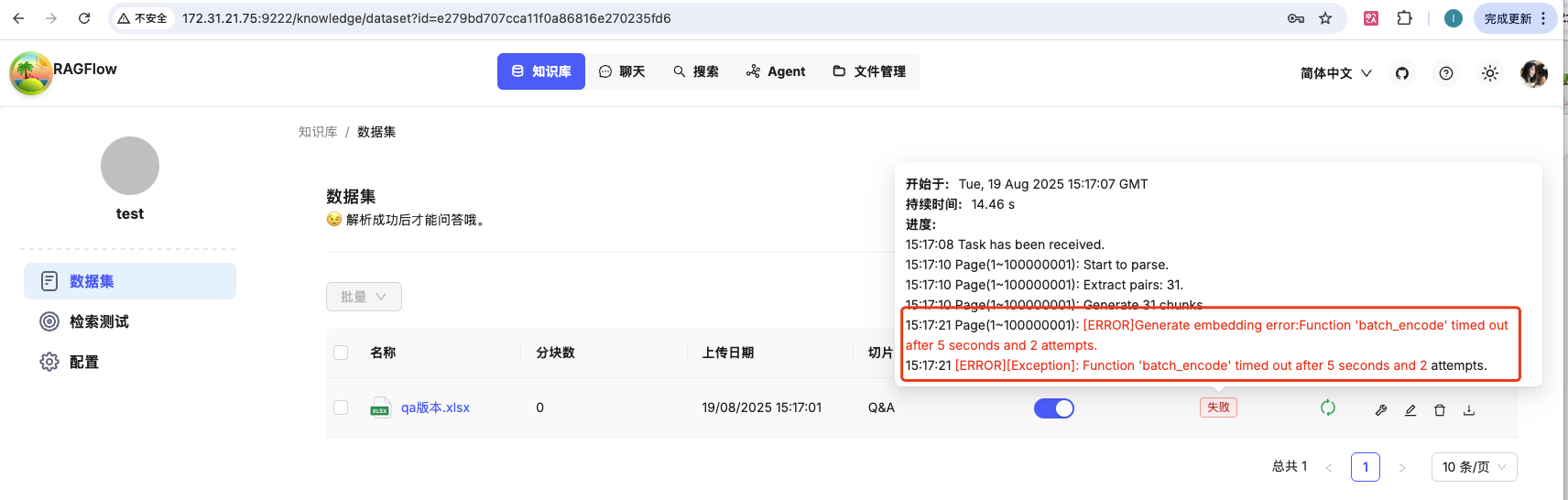
3、修改 EMBEDDING_BATCH_SIZE
由于我的电脑配置较差,会在知识库解析时报如下图错,你可以先执行 步骤4 当报错时在来处理。
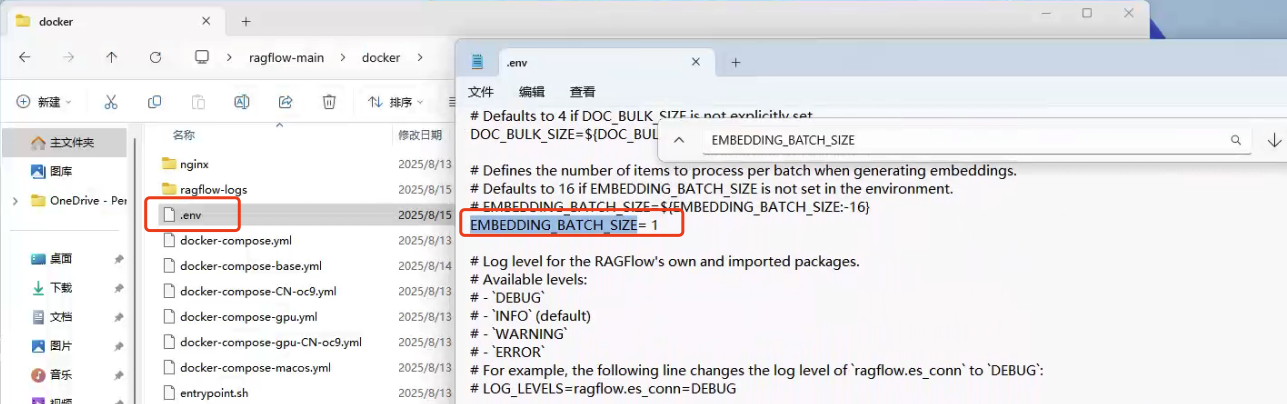
进入 docker 目录,打开 .env 文件,将 EMBEDDING_BATCH_SIZE 改为 2或者4(由于我电脑太差只能改为1)
执行如下命令重启 RAGFlow
docker compose -f docker-compose.yml up -d
4、上传知识库文件并解析

刚上传,如下图,点击运行开始解析

上传成功后如下图。
可以点击名称,查看这个文件切分的内容。
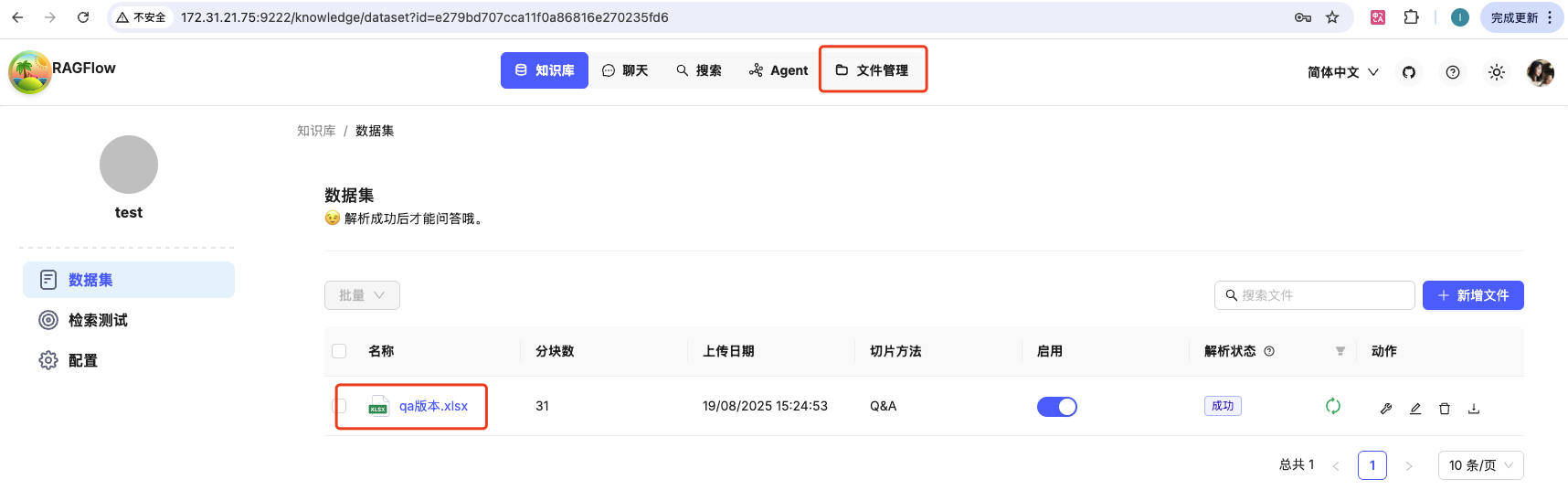
也可以在文件管理中,查看那个知识库中上传了哪些文档。
5、检索测试
可以在此测试查询的结果,如下图。

四、创建聊天
知识库:可以选择多个

找回次数可以选成 3

chat 模型可以选择 deepseek

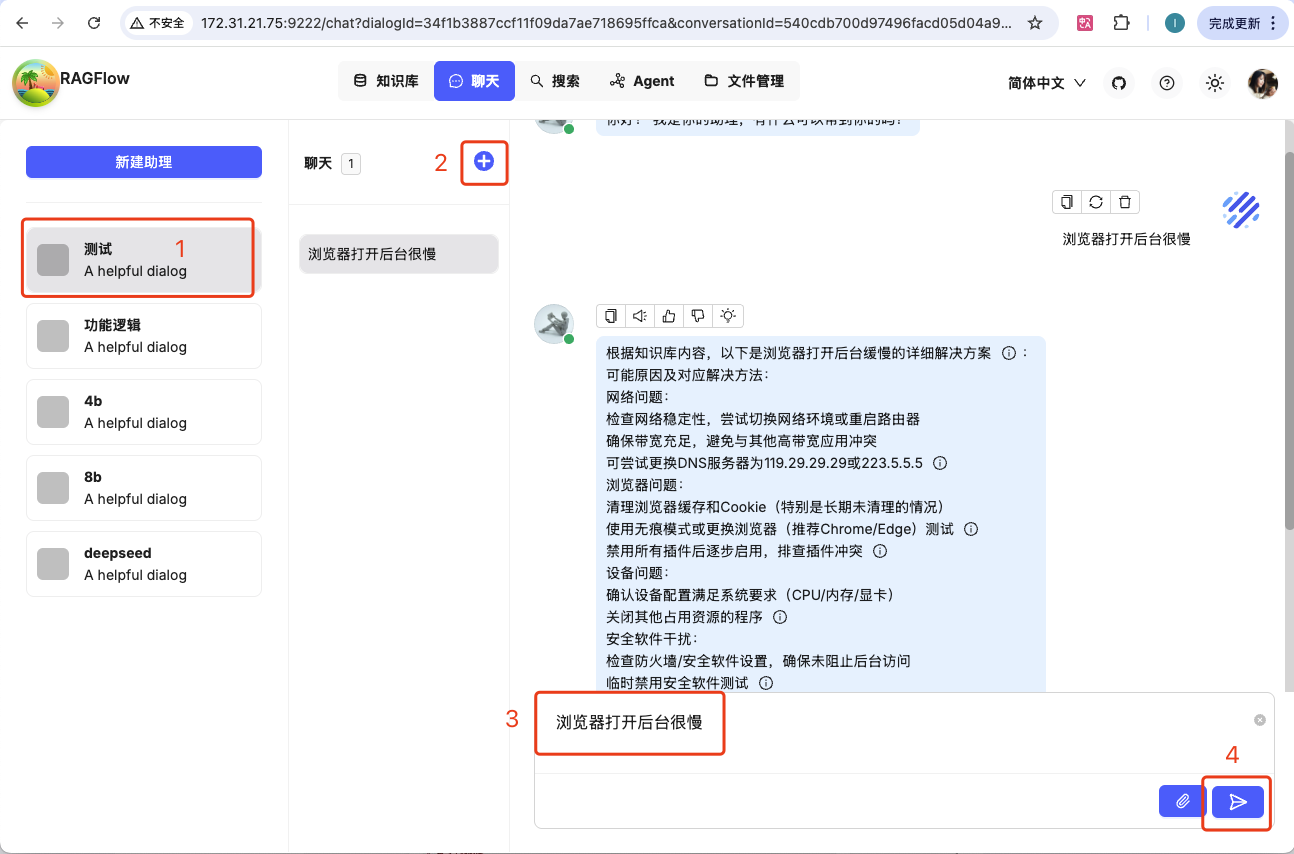
按下图操作即可测试回答效果。
参考文档:
https://zhuanlan.zhihu.com/p/1908166815730869455

 浙公网安备 33010602011771号
浙公网安备 33010602011771号