JavaScript中国象棋程序(7) - 置换表
“JavaScript中国象棋程序” 这一系列教程将带你从头使用JavaScript编写一个中国象棋程序。这是教程的第7节。
这一节主要介绍置换表。正如象棋百科全书网所说的,没有置换表,就称不上是完整的计算机博弈程序。
7.1、置换表
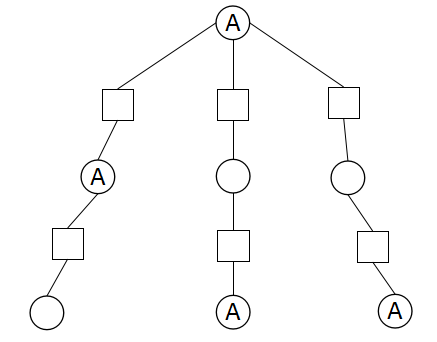
上图所示的搜索树中,局面A出现了3次,程序也搜索了3次,这浪费了很多时间。何不把A的搜索结果保存在表里,后面再搜索到A时直接查表取值,避免重复搜索呢?保存搜索结果的表,就是置换表。由于哈希表的读写速度很快,通常置换表就由哈希表来实现。
7.1.1、哈希表
哈希表是用散列方法存储的线性表。它以节点的关键字K为自变量,通过一个确定的函数关系h,计算出对应的函数值h(K),然后把这个值解释为节点的存储地址,将节点存入h(K)所指的存储位置上。在查找时,根据要查找的关键字用同一函数h计算出地址,再到相应的单元里查找要找的节点。函数h(K)称为散列函数或哈希函数。
如:11个元素的关键字分别为18,27,1,20,22,6,10,13,41,15,25。用11个连续存储空间来存放,选取关键字与元素位置间的函数为h(K) = key mod 11。(mod是取余运算)
7.1.2、存储
在我们的程序中,关键字K就是上节已经用到的Zobrist校验码。哈希函数同样是取余运算:
h(K) = Zobrist % TableSize
其中,TableSize是哈希表的长度。
但是这个函数在速度上有个瓶颈,因为“电脑一做除法就成了傻瓜”。因此,TableSize最好是2的整数次幂,这样就能把“取余运算”转化为“按位与运算”。比如取TableSize = 16,那么有:
7 mod 16 = 7, 17 mod 16 = 1, 25 mod 16 = 9
转换为按位与运算就有:
7 & 15 = 7, 17 & 15 = 1, 25 & 15 = 9
也就是说,和15进行与运算,就是对16取余。(可参考这篇文章)
因此,h(K) = Zobrist & (TableSize - 1),其中TableSize是2的整数次幂。
每个哈希表项存储的内容包括:深度(depth)、节点类型(flag)、分值(vl)、最佳走法(mv)、Zobrist Lock校验码。后面会介绍这些字段的作用。
7.1.3、冲突处理
以TableSize = 16为例,
7 mod 16 = 7
23 mod 16 = 7
因此,通过哈希函数算得的位置可能存在冲突。我们处理冲突的方法很简单——深度优先的替换。如果新节点深度高于旧节点,直接用新节点替换旧结点;否则,保留旧节点不变。
7.1.4、查找
由于Zobrist校验码不足以保证局面的唯一性,我们对每个局面都生成一个Zobrist Lock校验码(生成方式与Zobrist校验码一样),并保存在哈希表表项中。
查找置换表时,首先根据Zobrist校验码计算出哈希表中的地址,然后再比较Zobrist Lock校验码是否一致,一致的话才能说明是同一局面。
7.2、节点类型

(a)alpha节点 (b)beta节点 (c)PV节点
如上图所示,(10,20)是指搜索到C节点时,alpha为10,beta为20。
在图(a)中,所有子节点的值均小于alpha值10,最后C点取值为9,C点称为alpha点。
在图(b)中,节点C通过走法1到达D1取值为24,超过了beta值20,剪去了D2和D3两个分支,同时C点取值24。24并不是C点的真实值,我们只知道C点的值不比24小。这样的C点称为beta节点。
在图 (c)中,C点的取值为14,它是所有子节点中的最大值,反映了C点的真是情况,所以C点称为PV节点(Principal Variation)。
如果从哈希表中是一个PV节点,那么当前所搜索节点的值,就是哈希表中存储的值。
如果哈希表中是个beta节点,值为value。由于beta节点会发生剪枝,value不是一个准确值。只能说明当前搜索节点的值,不小于value。
如果哈希表中是个alpha节点,值为value。对于不超出边界的Alpha-Beta搜索,value显然不是个准确值,只能说明当前搜索节点的值不大于value。对于超出边界的Alpha-Beta搜索,例如上面的图(a),我个人觉得,9就是节点C的真实情况吧。让我不解的是,在程序中,使用的正是超出边界的搜索,却没有把alpha节点的值作为准确值来处理。
7.3、杀棋分数调整
在第5节,我们已经考虑了杀棋的分值,把输棋的分值与搜索层数结合起来:
输棋分值 = -MATE_VALUE + 搜索层数
赢棋分值 = MATE_VALUE - 搜索层数
现在使用置换表之后,由于相同的局面,可能位于不同的层数,所以不能再把这个调整后的分值存入置换表。我们的做法是,存入置换表时,存储与层数无关的分值(比如-MATE_VALUE);读取置换表时,再调整为与层数相关的分值(-MATE_VALUE + 当前搜索层数)。
7.4、杀手走法
第5节我们介绍了历史表,将一些好的走法(beta节点引发剪枝的走法、PV节点估值最好的走法)保存到历史表。根据国家象棋的经验,一个节点好的走法,在它兄弟节点也很可能就是好的走法。但是兄弟节点的走法,在当前节点下未必能走,所以在尝试杀手走法以前先要对它进行走法合理性的判断。
如何保存和获取“兄弟节点中产生截断的走法”呢?我们可以把这个问题简单化——距离根节点步数(distance)同样多的节点,彼此都称为“兄弟”节点,换句话说,亲兄弟、堂表兄弟以及关系更疏远的兄弟都称为“兄弟”。
我们可以把距离根节点的步数(distance)作为索引值,构造一个杀手走法表。我们的程序每个杀手走法表项存有两个杀手走法,走法一比走法二优先:存一个走法时,走法二被走法一替换,走法一被新走法替换;取走法时,先取走法一,后取走法二。
7.5、优化走法顺序
利用各种信息渠道(如置换表、杀手走法、历史表等)来优化走法顺序的手段称为“启发”。之前我们只用历史表作启发,但从这个版本开始,我们采用了多种启发方式:
1、如果置换表中有过该局面的数据,但无法完全利用,那么多数情况下它是浅一层搜索中产生截断的走法,我们可以首先尝试它;
2、然后是两个杀手走法(如果其中某个杀手走法与置换表走法一样,那么可以跳过);
3、然后生成全部走法,按历史表排序,再依次搜索(可以排除置换表走法和两个杀手走法)。
7.6、核心代码说明
本节的代码可以在 Github 下载,也可以直接clone
git clone -b step-7 https://github.com/Royhoo/write-a-chinesechess-program
Search中新增或修改的主要属性和方法:
(1)、hashMask
hashMask = 哈希表长度 - 1
用于将哈希函数的“取余运算”,转化为“按位与运算”。
(2)、recordHash(flag, vl, depth, mv)
记录哈希表
(3)、probeHash(vlAlpha, vlBeta, depth, mv)
查询哈希表
(4)、setBestMove(mv, depth)
该函数之前只更新历史表,目前要同时更新杀手走法表。
MoveSort中修改的方法:
(1)、next()
该方法是获取排序后的一个走法,目前加入置换表走法、杀手走法、历史表走法三种启发。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号