北航 2022 软工第三次结对编程作业
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 北航 2022 春季敏捷软件工程 |
| 这个作业的要求在哪里 | 作业说明链接 |
| 我在这个课程的目标是 | 学习现代软件工程开发的模式,锻炼团队协作开发的能力 |
| 这个作业在哪个具体方面帮助我实现目标 | 学习结对编程方法,并加以实践 |
项目地址
- 教学班级:周五班
- 项目地址:https://github.com/Coekjan/Word-Chain
PSP 表格耗时记录
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 120 |
| · Estimate | · 估计这个任务需要多少时间 | 60 | 120 |
| Development | 开发 | 860 | 1410 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 120 |
| · Design Spec | · 生成设计文档 | 30 | 60 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 30 | 60 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 30 |
| · Design | · 具体设计 | 120 | 180 |
| · Coding | · 具体编码 | 300 | 600 |
| · Code Review | · 代码复审 | 120 | 180 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 180 | 180 |
| Reporting | 报告 | 260 | 250 |
| · Test Report | · 测试报告 | 180 | 180 |
| · Size Measurement | · 计算工作量 | 20 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 60 |
| 合计 | 1180 | 1780 |
接口设计
看教科书和其它资料中关于 Information Hiding,Interface Design,Loose Coupling 的章节,说明你们在结对编程中是如何利用这些方法对接口进行设计的。
Information Hiding
Information Hiding 指的是“信息隐藏”,即面向对象中的“封装”的思想。使用封装的手段可以达到“划分对象,逐个击破”的目的。在现实世界中的软件工程中,工程复杂度已经成为软件开发的最大挑战。在开发这样的程序时,人类大脑的计算能力已经不能把握程序的所有细节,但是程序是一个精密的系统,一个微小的错误都有可能导致其崩溃。软件代码巨大的复杂度和人类大脑的局限性之间冲突,这是软件开发中的一个重要问题。
而利用 Information Hiding 可以将一个问题分成几个部分,并根据实际情况为问题中的实体建立对象,然后将问题中的操作分为两种:
- 对象内的操作和对象间的联系。在处理对象内的操作时,只考虑对象本身,而不去考虑本对象以外的世界;
- 在处理对象间的操作时,将每个对象看作一个原子,只考虑对象与对象间的联系,而不考虑每个对象内部实现的细节。
通过这种手段,可以将思考范围局限在某个具体的小对象,或者只需要考虑整个问题的宏观架构,大大减轻了思维的复杂度。
在我们的设计中,Information Hiding 体现在了两个方面:
- 我们将整个 Core 部分的程序划分为了
Graph,CoreInterface,WordMap三个部分。其中三个部分之间只有接口函数进行交互,隐藏内部的成员细节 - 我们的整个项目有 Core, CLI, GUI 三个部分。其中三个部分都通过统一的接口进行交互。Core 部分不需要关心 GUI 的实现方式,只需要提供计算结果;反之亦然
Interface Design
Interface Design 指的是“接口设计”。接口设计是实现 Information Hiding 的一种手段,它的目的是为了将程序的接口和实现分离,从而使得程序的可维护性和可扩展性更高。程序的不同模块之间通过接口连接,只要一个模块满足接口的要求,另一个模块就可以通过调用相应的接口使用。
在我们的项目中,通过接口设计,我们将三个模块进行解耦,使得每个模块都可以独立地进行自己的工作,同时让我们后续的模块交换成为了可能。
Loose Coupling
Loose Coupling 指的是“松耦合”思想。Loose Coupling 可以看作是 Information Hiding 带来的必然结果。通过信息隐藏和合理的接口设计,程序中各个部分的关联变得更加清晰,相互之间的耦合度也大大降低。松耦合带来的一个直接好处就是可以大大降低维护的复杂度。一旦确定了接口后,只要不对接口进行修改,那么不同模块之间只需要满足接口规范,那么在修改其中一个模块的实现时,只需要在局部修改代码,避免了大规模的重构。
在我们的设计当中,Loose Coupling 体现在计算核心、命令行处理、图形界面处理三个部分都各司其职。需要改进某个部分的内部实现时,不会影响整个程序的功能,也不会影响另外两个部分的实现。其中 Core 部分专门负责运算,CLI 只负责处理命令行的输入和报错,GUI 只负责图形界面的信息处理。因此当计算部分的算法发生改变时,不会影响到 CLI 和 GUI 部分的处理;而 GUI 部分界面的改变也不会影响 Core 部分的修改。
计算模块接口的设计与实现
计算模块的接口设计如下:
public const int ResultBufferMax = 20000;
public const int ErrorHasCircle = -1;
public const int ErrorBufferOverflow = -2;
public static (int, List<string>) GenChainsAll(List<string> words);
public static (int, List<string>) GenChainWord(List<string> words, char head, char tail, bool enableLoop);
public static (int, List<string>) GenChainWordUnique(List<string> words);
public static (int, List<string>) GenChainChar(List<string> words, char head, char tail, bool enableLoop);
-
ResultBufferMax:计算模块若发现结果长度超过ResultBufferMax,则返回ErrorBufferOverflow -
ErrorHasCircle:计算模块若在处理GenChainsAll/GenChainWordUnique,或在处理未指定enableLoop=true时的GenChainWord/GneChainChar时,发现单词环,则返回此异常值 -
GenChainsAll/GenChainWord/GenChainWordUnique/GenChainChar:各参数含义如下:words:单词列表,全由小写英文字母组成head:头字母限制,即要求单词链的头字母是headtail:尾字母限制,即要求单词链的尾字母是tailenableLoop:允许words中隐含单词环
返回值均是一个元组:
- 第一维:在
ErrorHasCircle/ErrorBufferOverflow异常发生时,是这两个异常对应的int值;没有异常时,是单词链的长度 - 第二维:是单词链;在异常发生时的值是未定义的(即调用者应在检测到异常时,不能认为第二维的返回值有意义)
计算模块的接口实现主要分为几个步骤:
- 调用
WordMap.Build,将单词列表映射到int - 根据单词/字母之间的关系,建立图
- 若传入的参数不允许隐含单词环,则先使用
Graph的HasCircle判圈算法,若发现存在圈,则返回ErrorHasCircle与一个空列表 - 调用
Graph中的图论算法,计算结果 - 若结果超长,则返回
ErrorBufferOverflow与一个空列表 - 图论算法计算的结果是一个
int链,需要再用WordMap将int映射回单词 - 返回单词链的长度与单词链
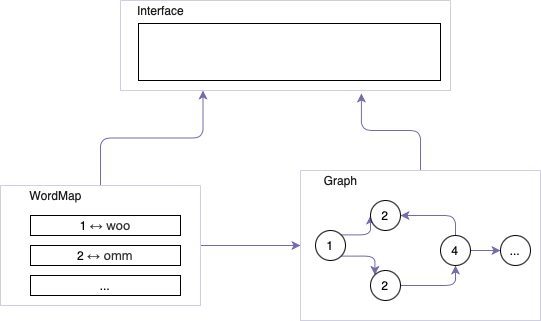
UML

计算模块接口部分的性能改进
为了考察程序的性能,我们使用了性能测试部分所用的参数 -r 来测试。下面是对于一组数据的性能分析图(火焰图与各模块耗时分析):
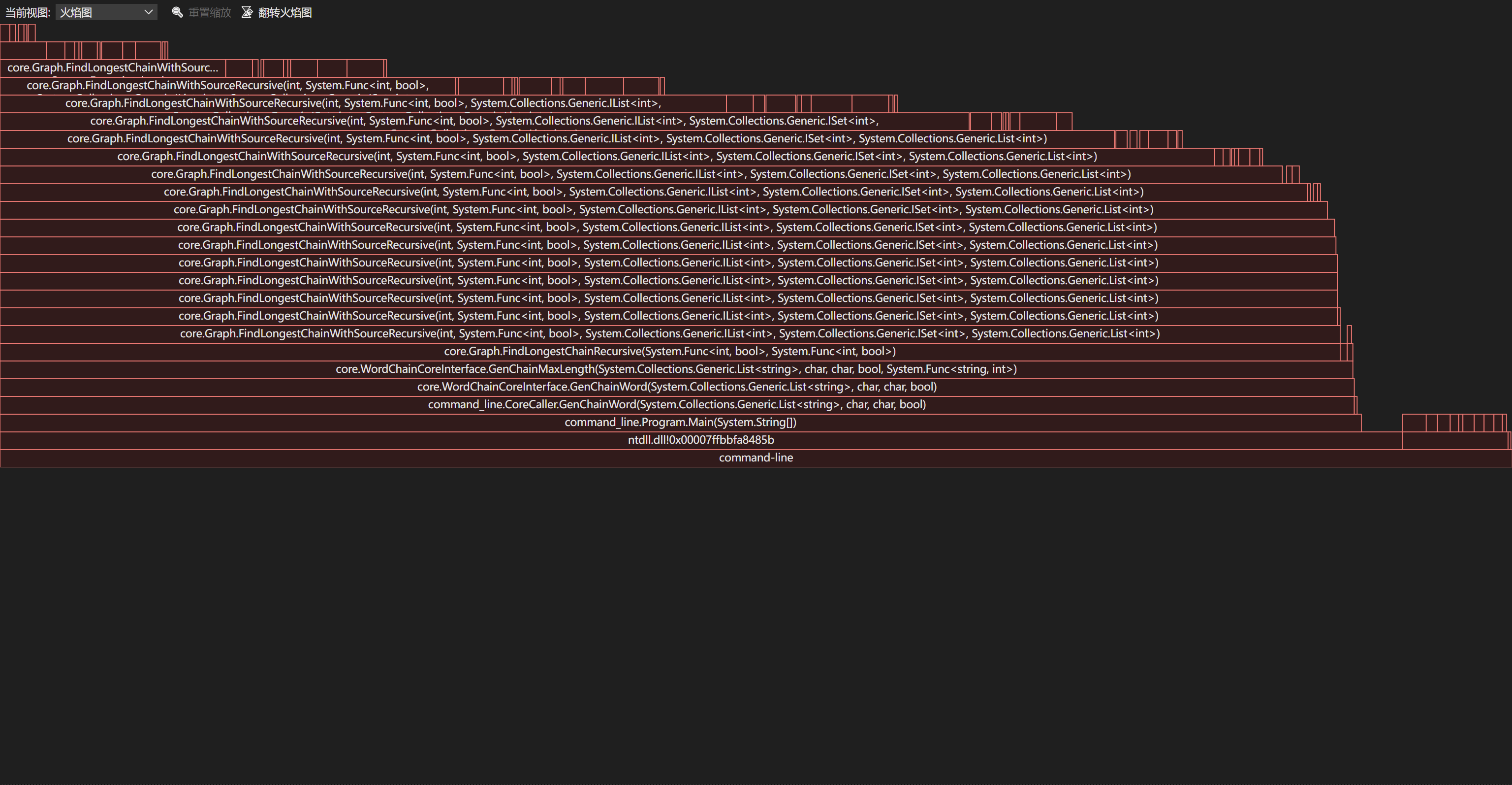
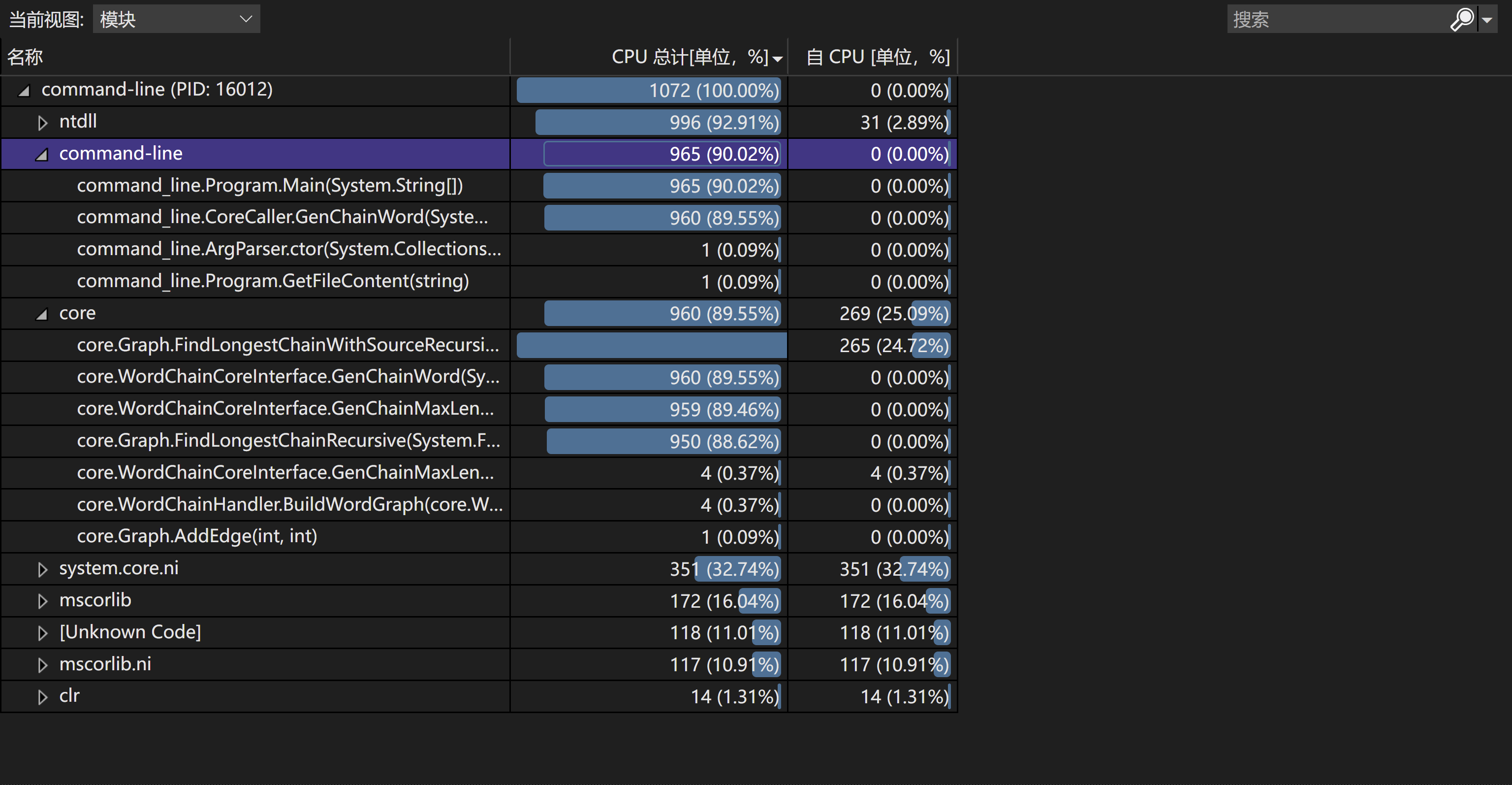
可以发现,大部分时间花费在 FindLongestChainWIthSourceRecursive 这个方法上。这个方法用于在单词图上进行 DFS。
为了优化这个函数的性能,我们使用了哈希来记录已经遍历过的节点,并且对其进行减枝。后续考虑包括使用 Tarjan 算法进行缩点,利用缩点后拓扑排序的结果对于搜索树进行减枝。
契约式设计
看 Design by Contract,Code Contract 的内容,并描述这些做法的优缺点,说明你是如何把它们融入结对作业中的
契约式设计在我们的面向对象课程中已经接触到过。在契约式设计中,会先定义每个组件的前置条件、后置条件和不变式。同时保证这些条件都是形式化的、精确的、可验证的。由此就可以严格地定义组件的行为,并为后续的验证提供帮助。
契约式编程的优点有以下几种:
- 严格精确:契约式设计使用类似于数学的形式化语言进行描述,因此其表达的含义消除了自然语言中的二义性,同时也涵盖了所有隐含的条件,因此可以更加精确地验证组件的行为。
- 简化测试:通过对于前置条件、后置条件和不变式的严格规定,对象与方法的行为和副作用也被严格定义,因此在测试时可以简化许多不必要的逻辑
- 可靠:使用契约式编程后,可以在测试阶段更加精确地验证组件的行为。一旦通过了测试,那么这份代码的行为也更加可靠
同时,契约式编程有以下的缺点:
- 冗长:由于契约式设计需要严格描述方法的行为,因此当某个方法行为比较复杂时,需要大量的形式化语句对其进行描述,描述的结果也十分冗长。同时在代码中嵌入大量的断言也会严重影响其可读性
- 耗时:契约式设计需要大量的时间花费在定义方法的行为上,这段时间可能甚至比代码实际开发的时间还要长
在我们的结对作业中,我们在权衡之后使用了断言的方法将契约式编程融入我们的作业。例如下面这段代码中,我们通过断言约束了传入值的行为,这使得当输入不符合要求时,我们可以尽早地在测试阶段就发现错误。
public int GetId(string word) {
Debug.Assert(_wordToId.ContainsKey(word.ToLower()));
return _wordToId[word.ToLower()];
}
计算模块部分单元测试展示
单元测试部分介绍
根据题目要求,我们对计算模块的每一部分都进行了单元测试,包括:
- 图与相关算法测试
GraphTest - 接口测试
WordChainCoreInterfaceTest - 单词集测试
WordMapTest
单元测试部分代码展示
图与相关算法测试
public void DagFindLongestChainTest1() {
var graph = new Graph();
bool HeadLimit(int i) => i == 5 || i == 4;
bool TailLimit(int i) => i == 1;
for (var i = 1; i <= 6; i++) {
graph.AddNode(i, i);
}
graph.AddEdge(5, 1);
graph.AddEdge(2, 4);
graph.AddEdge(4, 3);
graph.AddEdge(6, 1);
Assert.IsFalse(graph.HasCircle());
var chainWithNoLimit = graph.DagFindLongestChain(_ => true, _ => true);
Assert.IsNotNull(chainWithNoLimit);
Assert.IsTrue(chainWithNoLimit.SequenceEqual(new List<int>(new[] {2, 4, 3})));
var chainWithHeadLimit = graph.DagFindLongestChain(HeadLimit, _ => true);
Assert.IsNotNull(chainWithHeadLimit);
Assert.IsTrue(chainWithHeadLimit.SequenceEqual(new List<int>(new[] {4, 3})));
var chainWithTailLimit = graph.DagFindLongestChain(_ => true, TailLimit);
Assert.IsNotNull(chainWithTailLimit);
Assert.IsTrue(chainWithTailLimit.SequenceEqual(new List<int>(new[] {6, 1})));
var chainWithHeadAndTailLimit = graph.DagFindLongestChain(HeadLimit, TailLimit);
Assert.IsNotNull(chainWithHeadAndTailLimit);
Assert.IsTrue(chainWithHeadAndTailLimit.SequenceEqual(new List<int>(new[] {5, 1})));
}
接口测试
public unsafe void gen_chains_all_Test2() {
var words = new[] {
"woo",
"oow"
};
var (ret, _) = Adapter.Call(words, (s, r) => WordChainCoreInterface.gen_chains_all(
(byte**) s.ToPointer(),
words.Length,
(byte**) r.ToPointer()
));
Assert.IsTrue(ret == WordChainCoreInterface.ErrorHasCircle);
}
单词集测试
public void BuildTest() {
var wordList = new List<string>(new[] {"woo", "oom", "moon", "noox"});
var wordMap = WordMap.Build(wordList);
var wordsInMap = new HashSet<string>(wordMap.GetAllWords());
Assert.AreEqual(wordList.Count, wordsInMap.Count);
Assert.IsTrue(wordList.All(word => wordsInMap.Contains(word)));
}
算法测试构造思路
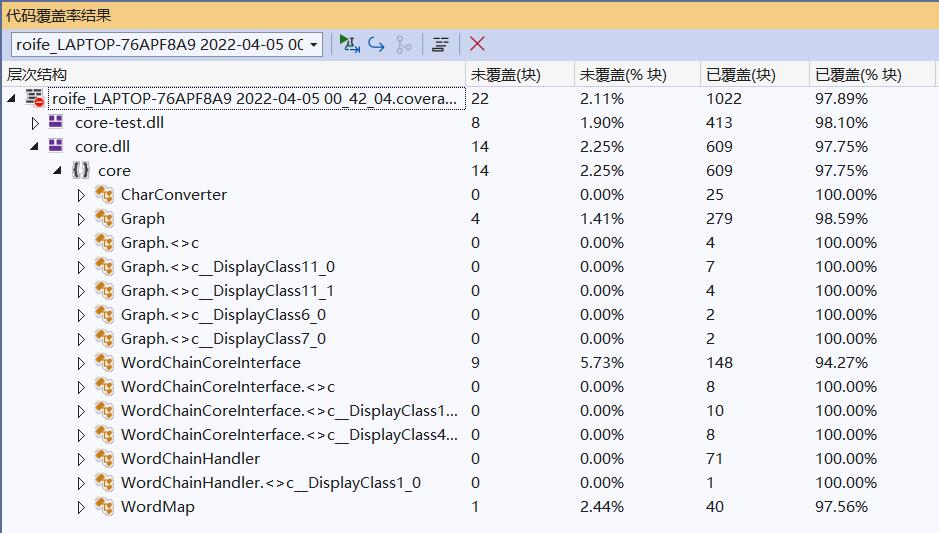
为了尽可能覆盖到代码中的所有情况,我们对代码中几乎所有可能运行到的分支都进行了测试。其中,最关键的是"图与相关算法"部分的数据构造,如下表所示:
| 测试方法 | 测试模式 | 数据特性 |
|---|---|---|
HasCircleTest() |
-w |
带环 |
DagFindLongestChainTest1 第一组 |
-c |
- |
DagFindLongestChainTest1 第二组 |
-c |
指定首字母 |
DagFindLongestChainTest1 第三组 |
-c |
指定尾字母 |
DagFindLongestChainTest1 第四组 |
-c |
指定首尾字母 |
DagFindLongestChainTest2 |
-c |
单词长度差异大 |
FindLongestChainRecursiveTest1 第一组 |
-w |
带环 |
FindLongestChainRecursiveTest1 第二组 |
-c |
带环 |
FindLongestChainRecursiveTest2 |
-w |
复杂带环 |
FindAllChainsTest |
-n |
- |
为了保证测试的效果和覆盖率,同时避免测试运行占用过多时间,我们针对每一种可能的情况都设计了一两个测试。
测试覆盖率
计算模块部分异常处理说明
为了简单起见,我们将大部分异常(如文件不存在、首字母限制错误)放在了用户界面进行处理,仅将计算相关的部分异常放在了计算模块中进行处理。
环形单词链异常
异常描述
当输入的参数中不允许环形单词链,但是提供的单词链表有可能构成唤醒单词链时,会触发这个异常。
在代码中,为了处理这种异常,我们设计了对应的异常错误码:
public const int ErrorHasCircle = -1;
在开始计算前,如果接口参数不允许环形单词链,且发现单词链表构成了环形,那么我们会直接返回错误码,不继续进行计算。
if (graph.HasCircle()) {
return (ErrorHasCircle, new List<string>());
}
单元测试样例
[TestMethod]
public unsafe void gen_chains_all_Test2() {
var words = new[] {
"woo",
"oow"
};
var (ret, _) = Adapter.Call(words, (s, r) => WordChainCoreInterface.gen_chains_all(
(byte**) s.ToPointer(),
words.Length,
(byte**) r.ToPointer()
));
Assert.IsTrue(ret == WordChainCoreInterface.ErrorHasCircle);
}
如图所示,为求所有单词链时,输入单词为 woo oow 的情况。根据指导书要求,这种情况下不允许出现环形单词链,而输入却构成了这样的环形单词链,因此会直接异常错误码。
单词链长度异常
异常描述
当输出结果长度限制的 20000 时,会触发这个错误。
在代码中,为了处理这种异常,我们设计了对应的异常错误码:
public const int ErrorBufferOverflow = -2;
在计算完成后,会对计算结果进行检查。如果长度超过了指定的 ResultBufferMax(即 20000),就会触发这个异常并直接返回。
var allChains = graph.FindAllChains();
if (allChains.Count > ResultBufferMax) {
return (ErrorBufferOverflow, new List<string>());
}
单元测试样例
[TestMethod]
public unsafe void gen_chains_all_Test3() {
var wordList = new List<string>(new string[] { "ab" });
for (var c = 'b'; c <= 'b' + 5; ++c) {
var curStr = c.ToString();
for (var i = 0; i < 6; ++i) {
wordList.Add(curStr + ((char) (c + 1)).ToString());
curStr += c.ToString();
}
}
var words = wordList.ToArray();
var (ret, _) = Adapter.Call(words, (s, r) => WordChainCoreInterface.gen_chains_all(
(byte**)s.ToPointer(),
words.Length,
(byte**)r.ToPointer()
));
Assert.IsTrue(ret == WordChainCoreInterface.ErrorBufferOverflow);
}
在这里为了构造出合适的样例,我们构造了一棵单词树,其中每个非叶子结点都有 6 个子节点,并且树高为 6 层。当求这棵单词树上的所有路径时,就能得到超过限制数量的结果。
界面模块的详细设计过程
CLI
CLI 模块主要由参数解析器、分词器、核心模块调用器、异常处理四部分组成。设计过程中我们主要遵循下面的逻辑约定:
-
参数解析器
ArgParser:接受一个命令行参数列表,分析参数列表中表达的的文件、模式参数、头尾字符限制等,并根据n/m/w/c互相排斥h/t/r只适用于w/c两种模式
这两种原则,检验参数的合法性,并做异常处理。
-
分词器
Lexer:接受一个字符串,分析其中包含的单词,转为小写,返回分词的结果。 -
核心模块调用器
CoreCaller:调用核心模块,并将核心模块处理的结果送回调用者,需要注意的是当遇到异常处理模块返回值异常时应进行异常处理。 -
异常处理的捕获者是唯一的,是
Main函数的try-catch块。
GUI
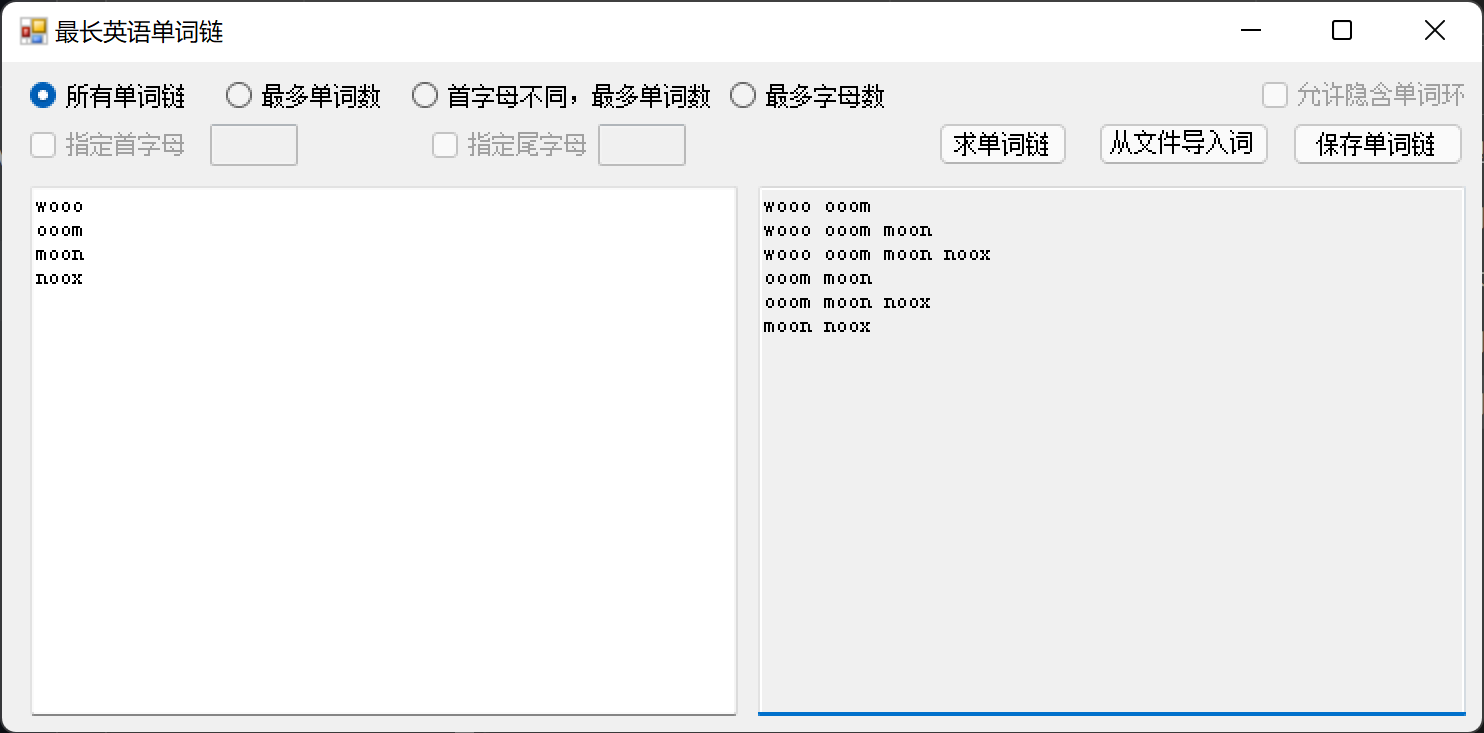
如图所示,GUI 分为了模式选择,参数选择,按钮以及输入输出部分。
其中,既可以选择从文件中导入,也可以手动在文本框中输入数据。
选择不同的模式时,我们采用了防呆设计,即对应的参数选择部分也会根据题目要求进行调整,防止用户错误输入:
private void radioAll_CheckedChanged(object sender, EventArgs e) {
if (radioAll.Checked || radioDiffHeadMaxWords.Checked) {
checkHead.Enabled = false;
checkTail.Enabled = false;
checkLoop.Enabled = false;
} else {
checkHead.Enabled = true;
checkTail.Enabled = true;
checkLoop.Enabled = true;
}
}
在错误提示上,我们也选择了 WinForm 原生的错误提示框,使用图形化的方式给予用户反馈:
private void buttonRead_Click(object sender, EventArgs e) {
OpenFileDialog dialog = new OpenFileDialog();
dialog.Filter = "txt files (*.txt)|*.txt";
if (DialogResult.OK == dialog.ShowDialog()) {
string path = dialog.FileName;
if (!File.Exists(path)) {
MessageBox.Show("无法找到文件", "发生错误", MessageBoxButtons.OK);
}
try {
var rawInput = File.ReadAllText(path);
var wordList = Lexer.Lex(rawInput).ToArray();
textWords.Text = string.Join("\r\n", wordList);
} catch (IOException) {
MessageBox.Show("无法读取文件", "发生错误", MessageBoxButtons.OK);
}
}
}
界面模块与计算模块的对接
CLI
CLI 对接计算模块时,是通过 CoreCaller 模块与计算模块对接的。CoreCaller 模块将调用逻辑封装后暴露给 CLI 中的调用者:
public static List<string> GenChainsAll(List<string> words);
public static List<string> GenChainWord(List<string> words, char head, char tail, bool enableLoop);
public static List<string> GenChainWordUnique(List<string> words);
public static List<string> GenChainChar(List<string> words, char head, char tail, bool enableLoop);
注意,此处的接口是
CoreCaller提供给 CLI 的,与计算模块core.dll的接口不一致
CoreCaller 主要是对异常值进行了封装,即当检测到 core.dll 的异常返回值时,主动抛出异常(在 CLI 的 Main 函数中捕获异常并输出异常信息)。
GUI
由于同样使用了 Core 模块,因此与 CLI 中类似,在 GUI 中也使用了相同的接口名称与 Core 进行对接:
public static List<string> GenChainsAll(List<string> words);
public static List<string> GenChainWord(List<string> words, char head, char tail, bool enableLoop);
public static List<string> GenChainWordUnique(List<string> words);
public static List<string> GenChainChar(List<string> words, char head, char tail, bool enableLoop);
其中,GUI 能够利用图形界面的优势避免异常的输入,因此接口设计上更加简单。
结对的过程
我们主要是用 Live Share 和 Code with me 进行共同开发。
在结对编程的过程中,我们先各自阅读指导书,讨论并交换了对于题目的理解。然后根据指导书的要求选择了 C# 作为我们的开发语言,并且讨论了 Core/CLI/GUI/Test 各个部分的实现方法。接着我们开始将程序划分为若干个部分,并交流各个部分的设计以及互相协作的方式。
在设计完成后,我们开始进行正式的编码阶段。在这个阶段中,我们使用轮换的方式进行开发。在开发时每个人都会轮流在分支上进行提交代码,并且每个人都会在提交代码后进行代码的审核。为了保证两个人都对项目有足够的理解,我们没有严格区分两个人的任务,在每个部分的编码中两个人都参与了开发工作。
在编码的过程中,我们发现结对过程的开发与传统的单人开发有许多的不同。例如在 Debug 的时候,单人开发时我更喜欢使用 Debug 工具进行调试,因为长时间的调试所培养了一定的肌肉记忆,在过程中可以全程跟着断点进行调试。但是当两个人一起 Debug 时,使用调试器需要向另一个人解释调试的思路,这会让 Debug 的速度大大减慢。我们此时发现两个人直接阅读代码更容易发现一些问题。通过阅读代码的交流,两个人也能够更迅速地定位到 Bug 的部分。
优缺点分析
结对编程的优缺点分析
- 优点
- 可以进行实时的代码复审,减少了 bug 出现的可能性
- 结对的双方在开发过程中可以实时交流,避免了因为沟通不畅而导致的 bug,例如接口问题等
- 可以让结对者双方互相促进,提高二者的编程能力
- 缺点
- 双方在结对开始的时候需要一定的时间磨合
- 结对过程中需要两个人同时在场,当两个人时间不一致时,约定一个统一的时间进行结对有些难度
- 结对的过程中只有一个人在进行开发,因此开发的速度会慢一些,比起独自开发再对接需要花费更长的时间来完成同样的项目
成员的优缺点分析
- roife (19373189):
- 优点:学习过 GUI 的绘制,了解部分问题的算法
- 缺点:不太习惯 Visual Studio,对于 C# 语法不够了解,写代码有些拖延
- coekjan (19373372):
- 优点:比较熟悉工程性代码的解耦设计,曾经写过不少工程性代码
- 缺点:不太懂算法,对代码风格之类的有强迫症
交换模块测试
- 交换对象:@Chenrt-ggx & @Dr-Bluemond
- 最终的成品可在 Github 仓库 的最后一次 CI 成品中找到。
交换小组使用 C++ 开发计算模块,因此需要使用 Visual Studio 的一些设置,使得我们的 C# 模块与 C++ 协同:
- 修改 C++ 项目的运行时设置,将 C++ 模块设置运行在 CLR 运行时上,并禁用
/permissive。 - 在 C# 项目中使用
[DllImport("bin/core.dll", CallingConvention = CallingConvention.Cdecl)]来引入 C++ 项目的 dll 库。 - 编译项目时注意依赖顺序,首先要编译 C++ 项目,然后再编译 C# 项目。这主要是在编写 CI 脚本时需要注意,VS 会自动安排合适的编译顺序。
另外,由于采用 C 类型的接口,我们需要使用 C# 中的 fixed/unsafe 等方法与 C 类型接口交互:
internal abstract class Adapter {
private const int MaxSpace = 1024;
private static byte[][] ConvertStringArrayToSByteDim2Array(string[] stringArray) {
var result = new byte[stringArray.Length][];
for (var i = 0; i < stringArray.Length; i++) {
var byteArray = Encoding.ASCII.GetBytes(stringArray[i]);
var byteArrayWithEnd = new byte[byteArray.Length + 1];
Array.Copy(byteArray, byteArrayWithEnd, byteArray.Length);
result[i] = byteArrayWithEnd;
}
return result;
}
private static unsafe void Dim2ArrayToDoublePointer(byte[][] array, byte** result) {
for (var i = 0; i < array.Length; i++) {
fixed (byte* ptr = array[i]) {
result[i] = ptr;
}
}
}
public static unsafe (int, List<string>) Call(string[] words, Func<IntPtr, IntPtr, int> simple) {
var wordsCharArray = ConvertStringArrayToSByteDim2Array(words);
var selfManagedWordSpace = Marshal.AllocHGlobal(sizeof(byte*) * wordsCharArray.Length).ToPointer();
var selfManagedResultSpace = Marshal.AllocHGlobal(sizeof(byte*) * 20000).ToPointer();
Dim2ArrayToDoublePointer(wordsCharArray, (byte**) selfManagedWordSpace);
var result = new List<string>();
var backendResult = simple((IntPtr) selfManagedWordSpace, (IntPtr) selfManagedResultSpace);
if (backendResult >= 0 && backendResult < 20000) { // convention
for (var i = 0; i < backendResult; i++) {
var bytes = ((byte**) selfManagedResultSpace)[i];
var str = new StringBuilder();
for (var p = bytes; *p != 0; p++) {
str.Append((char) *p);
}
result.Add(str.ToString());
}
}
Marshal.FreeHGlobal((IntPtr) selfManagedWordSpace);
Marshal.FreeHGlobal((IntPtr) selfManagedResultSpace);
return (backendResult, result);
}
}
这段代码用 C# 的 Marshal.AllocHGlobal/Marshal.FreeHGlobal 来手工分配/回收内存。随后,使用类似下面的方法,即可调用 dll 库的函数:
public static unsafe List<string> GenChainsAll(List<string> words) {
var (ret, chains) = Adapter.Call(words.ToArray(), (s, r) => {
return gen_chains_all((byte**) s, words.Count, (byte**) r);
});
// ...
return chains;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号