BUAA OO 第三次作业总结
规格实现策略
实现规格的时候,我一般分为下面的几个步骤:
- 实现比较简单的类规格,例如异常等
- 快速浏览一遍主要的规格,结合方法名,大概知道每个方法在做什么事。
- 比如
hasPerson/contains这种,不读规格也知道在干啥
- 比如
- 实现 Trivial 的方法
- 例如
getSize等
- 例如
- 实现耦合度比较低的类
- 例如
Person。而Network这种耦合度则比较高
- 例如
- 对于比较复杂的方法,先跳过,标记一个
TODO
一开始我阅读规格时,往往会比较快得扫两眼就动手写,因为看多了就能知道一些特定模式的规格的写法,而且也可以根据方法名猜测规格的意思。
当然,在实现一个比较复杂的方法时,也有几个步骤:
- 首先,实现所有的
exceptional_behavior,因为他们往往比较简单,而且可以在方法的开头直接识别并抛出异常 - 阅读
normal_behavior,如果有多条就分类 - 对于每个方法识别出模式和背后的含义
最后需要对着每一条规格检查自己的方法。
发现新增规格
每次作业相比于前一次都可能增加规格,那么要怎么找到这些新增的规格呢?
答案是使用 diff 对比两次作业的规格。
这里推荐可以使用 VScode 进行比较,或者使用 vimdiff。可以清楚地看到两次作业规格的区别。
规格的模式
我把规格分为“保证不变”和“如何修改”,看规格的时候先分出每一条规格属于哪种。
对于保持不变的规格可以不管。
前者例如“保持前面的元素不变”等:
/*@
@ ensures (\forall int i; 0 <= i && i < \old(people.length);
@ (\exists int j; 0 <= j && j < people.length; people[j] == (\old(people[i]))));
*/
测试策略
阅读代码
规格化的一个好处是架构已经给定了,写出来的代码不会千奇百怪。所以阅读代码是一个性价比很高的选择。
由于同学在互测之前都已经自己写过了代码,因此对于哪些方法可能超时/出错也有数了。阅读代码时可以先看那些比较容易出错的方法。
随机测试
我的测试主要集中在压力测试,即疯狂加人/加关系,然后调用特定的函数看结果。
本单元的测试数据相对于前面的单元比较容易构造,但是在 judge 上比较困难(因为实现 judger = 实现规格 = 实现本单元作业)。因此我使用的方法是以对拍为主,即和自己的程序进行对拍。
容器选择经验
常用容器
这次作业中我主要使用了三种容器:
ArrayList<T>:最直接的选择,用来实现 JML 规格中的大部分数组HashMap<K, V>:处理对应关系HashSet<T>:处理集合关系
ArrayList<T>
一般用来 JML 中的数组,是最普通的选择。
HashMap<K, V>
JML 中常有“对应”的数据,例如下面这个:
/*@ensures (\old(getMessage(id)) instanceof EmojiMessage) ==>
@(\exists int i; 0 <= i && i < emojiIdList.length && emojiIdList[i] == ((EmojiMessage)\old(getMessage(id))).getEmojiId();
@emojiHeatList[i] == \old(emojiHeatList[i]) + 1);
不难发现,这个规格的意思是“先找到 emojiId 所在的位置,然后将改变位置的 emojiHeatList 的值。这不难发现是一种对应关系,即 id 与 heat 一一对应。所以我们用 HashMap 维护。
HashSet<T>
HashSet<T> 用于处理集合关系,它和 ArrayList<T> 很像,但是一般要满足两个要求:
- 元素没有顺序关系
- 需要进行集合相关的判断(例如
contains)
其他容器
除此之外,由于题目中的 Message 在发消息时需要将消息插到“队列头部”,所以我还使用了一个 LinkedList<T>。在最短路算法中,我使用了 PriorityQueue<T> 来维护一个堆。
自建容器
这里我自己写了三个泛型容器类:
Dsu<T>:用来维护并查集Relation<T>:用来存储关系数据Graph<T>:维护关系图,主要用于最短路计算
其中 Dsu<T> 和 Graph<T> 是出于性能考虑维护的,而 Relation<T> 则是可以简化代码的逻辑。
性能问题分析
本次作业可能出现的性能问题,我认为集中出现在几个“统计”相关的指令上,下面我将进行一一分析。
queryNameRank
其实这个指令出现性能问题的可能性不大。由于姓名长度有限制,这里不妨假设比较两个字符串的复杂度是一个常数,那么求出 qnr 的复杂度就是 \(O(n)\) 的。这里我是用 Stream 实现的:
people.values().stream().filter(person1 -> person.compareTo(person1) > 0).count() + 1;
// count() 用来统计 Stream 中的元素数量,返回为 long 类型
然而对高级数据结构有了解的人,可以发现这个地方可以用平衡树优化,用 Treap/Splay 可以将其优化到 \(O(\log n)\)。但是个人认为意义不大。
queryBlockSum / isCircle
很明显可以用并查集。
这个地方在实现的时候,我写了一个泛型类 Dsu<T>:
public class Dsu<T> {
private final HashMap<T, T> father;
private final HashMap<T, Integer> size;
public Dsu();
public T getFather(T u);
public boolean isSameSet(T a, T b);
public void add(T a);
public void merge(T a, T b);
public int queryBlockSum();
}
需要注意的是虽然一般来说大家都喜欢偷懒,写并查集的时候只写路径压缩,但是在某个群里听说只写路径压缩运气不好,在某些数据下退化成了一条链。所以建议写的时候加上按秩合并。这样查询的复杂度是均摊线性的。
getAgeMean / getAgeVar
即要算
所以我们令
这两个量都可以在 addPerson 和 delPerson 的时候维护。那么:
getValueSum
对于每个 Group 我维护了一个 relations 的集合,在 addPerson/delPerson 以及 Network 中添加关系时进行维护。
那么结果就是:
relations.stream().mapToInt(Relation::getVal).sum();
sendIndirectMessage
跑堆优化的最短路即可,这个很好写,用自带的 PriorityQueue<T> 就能做。
可以在增加关系和人员的时候维护一个 Graph 类,然后需要计算 sendIndirectMessage 时算出最短路。
public class Graph<N> {
private static final int INF = 0x3f3f3f3f;
private final HashMap<N, HashSet<Relation<N>>> relations;
public Graph();
public void addNode(N node);
public void addEdge(N src, N dst, int value);
public int getShortestPathValue(N src, N dst);
}
架构设计与分析
架构不是规格规定了吗,有什么好说的。
我觉得这里有价值的讲的是规格以外的,为了性能为添加的“架构联系”。因此这里我只列出部分必要的方法和分析。
下面为了简洁起见,我也不会将异常放进来。
第九次作业
UML 图
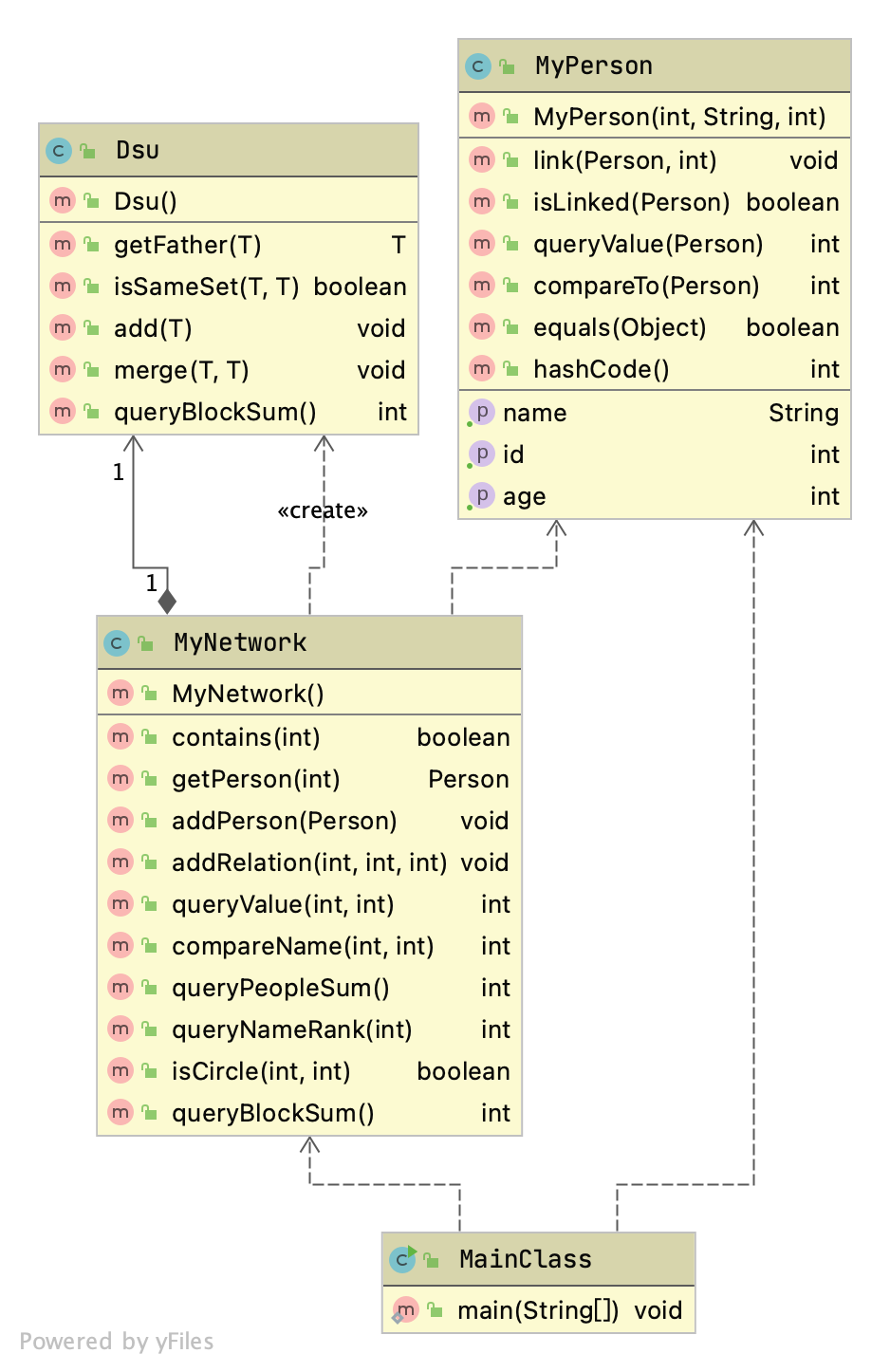
这次的架构比较简单,基本是按照规格来的。
比较特殊的就是我自己写的一个并查集类 Dsu<T>,不过也算是中规中矩,比较 Trivial。
但是这次我在 MyPerson 中定义了一个 link 方法,用来维护 acquaintance 容器。
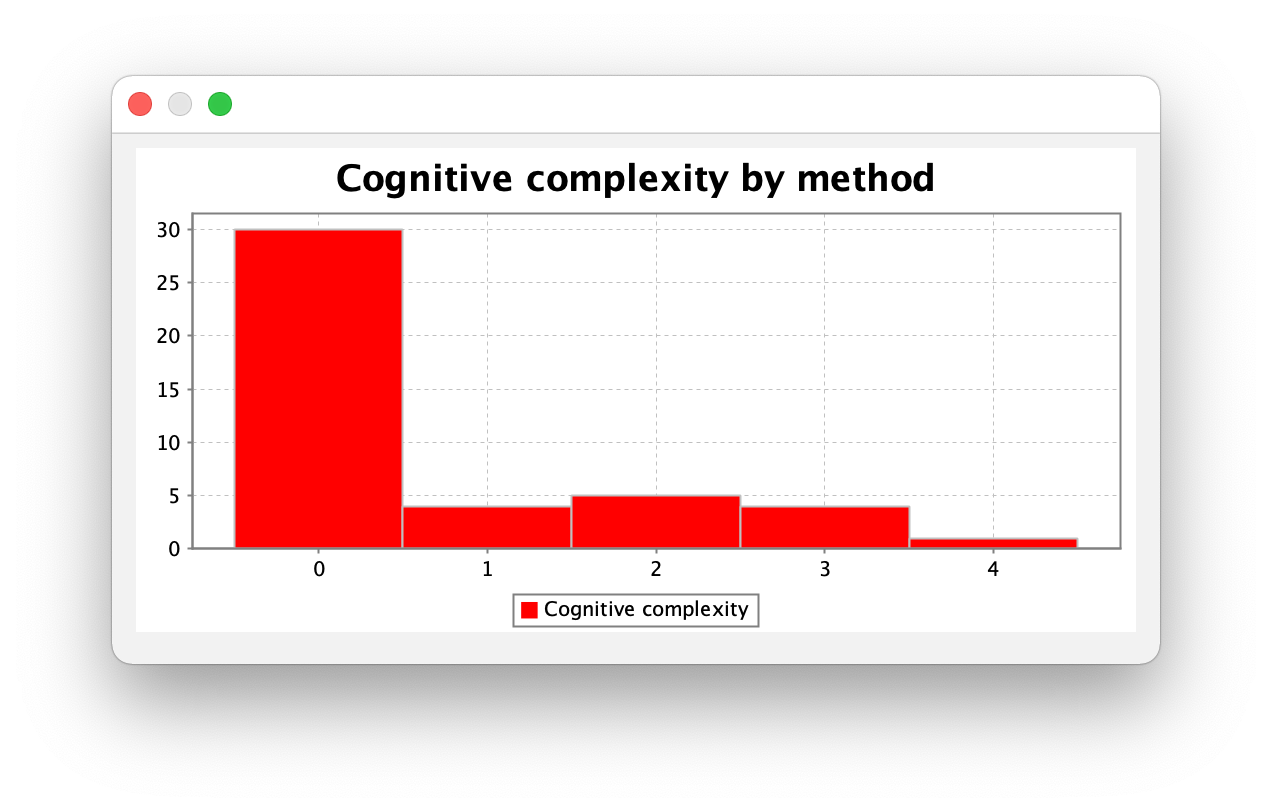
度量分析
得益于规格帮我们规划好了架构。度量分析基本没有问题,唯二有点超标的方法原因是异常判断用了多个 if 的 addRelation 方法和 queryValue 方法:
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| mycode.MyNetwork.addRelation(int,int,int) | 3.0 | 4.0 | 3.0 | 4.0 |
| mycode.MyNetwork.queryValue(int,int) | 3.0 | 4.0 | 3.0 | 4.0 |
exception_behavior 处理
在处理异常时,我通常使用以下的代码结构:
public void method() {
if (xxx) {
throw new exception1;
} else if (yyy) {
throw new exception2;
} else if (zzz) {
throw new exception3;
}
do_normal_behavior;
}
这样虽然有可能增大代码复杂度,但是好处是 exception_behavior 和 normal_behavior 的界限更清晰,规格和架构可以一一对应。
这也类似于一种“逻辑分流”的概念——即异常和逻辑执行解耦。
架构分析
基本是按照规格实现的。
不过这里我将 Person 类规格中的下面两个数组 acquaintance 和 value 合并成了一个 HashMap<Person, Integer> 来减小时间复杂度。
Bug 分析
没有被发现 Bug。
测出了别人的两个 Bug,问题出在没有把控好时间复杂度,即没有使用并查集。
第十次作业
UML 图
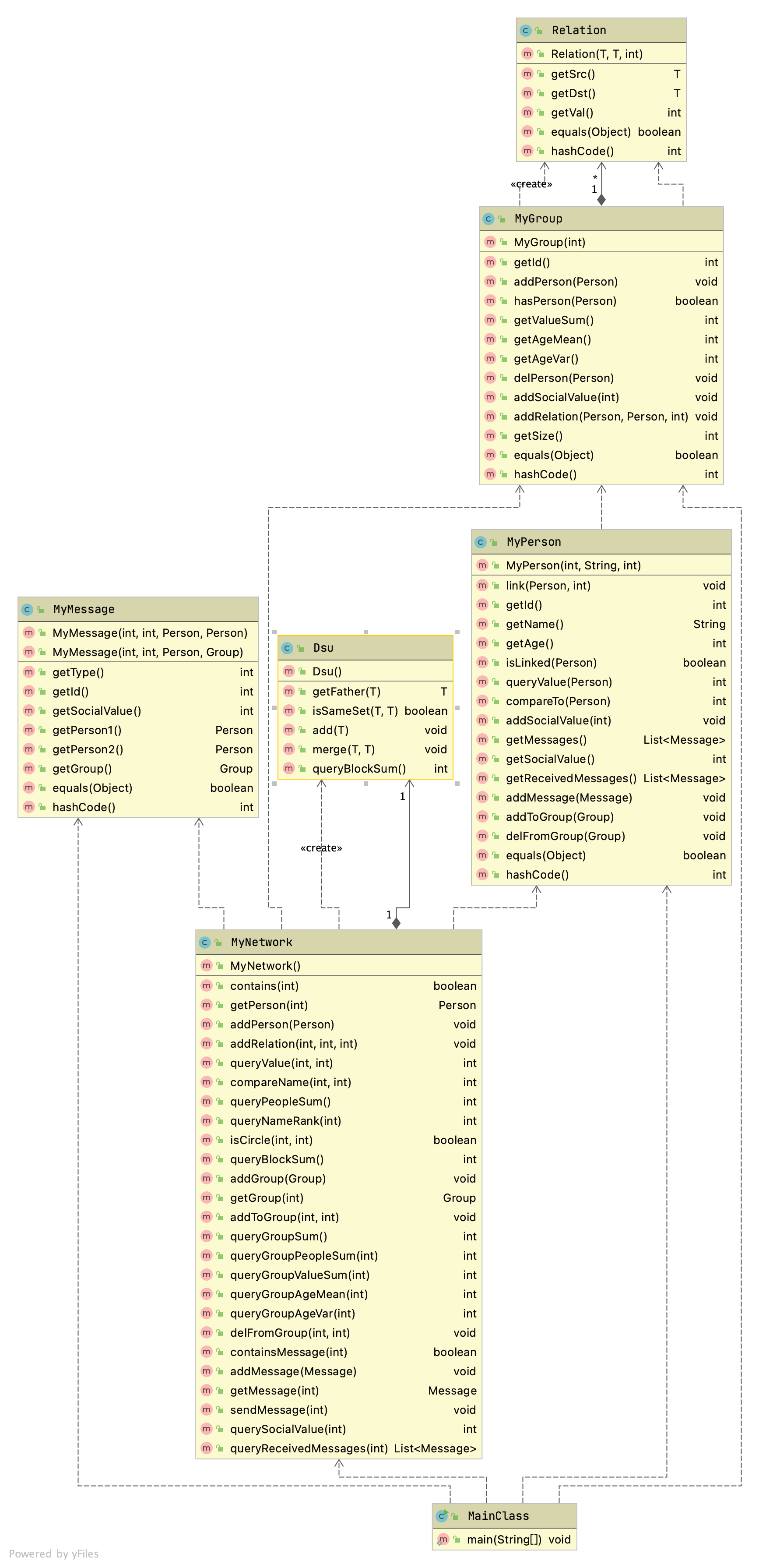
本次作业我的代码中新增了一个自己用的 Relation<T> 类,方便用来存储关系。
值得注意的是,除了规格中规定的方法以外,我还自己新增了其他自定义的方法:
MyGroup.javaaddSocialValue:在MyNetwork的sendMessage中使用,其实是规格中隐含的要求(虽然没独立写出来,但是规格描述暗含了这个方法)addRelation:维护relations容器,可以优化getValueSum方法的时间复杂度
MyPersonaddMessage:同addSocialValueaddToGroup:在MyNetwork的addToGroup使用,用来维护MyGroup中的relations容器delFromGroup:同addToGroup
度量分析
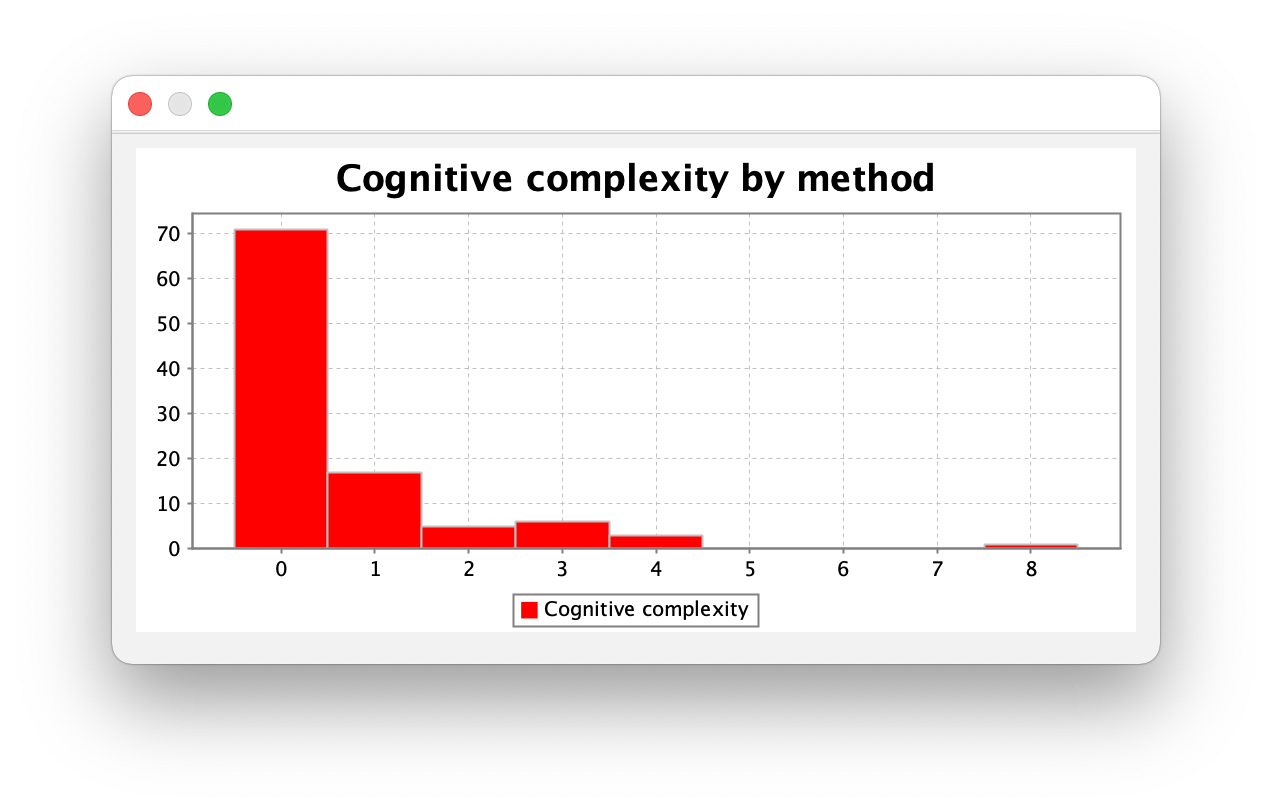
度量分析结果和上一次作业差不多。值得注意的是这次的 sendMessage 方法比较复杂,原因是我的实现用了大量 if 语句嵌套,这一点将在下一次作业中得到改善。
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| mycode.MyNetwork.sendMessage(int) | 8.0 | 6.0 | 4.0 | 6.0 |
架构分析
基本和规格相符。
但是值得注意的是,为了追求性能,我的实现相比于规格的“理想化”实现而言更加耦合了,这样虽然增强了性能,但是降低了可维护性。
例如我的 MyPerson 维护了一个 group 成员,方便用于统计和修改 group 相关的询问。
由此可见开发中要注意二者的折中,如果要追求一项,那么势必要舍弃另一项作为代价。
Bug 分析
被发现了一个超时 Bug。这是因为当天我的好几个隐藏 Bug 在提交前半小时才被发现,然后开始了紧张刺激的 debug 之旅。
最后成功在截止时间前解决了大部分 Bug,但是还有一个性能优化的 Bug 没解决,所以无奈交了暴力,最后互测被人 Hack 出来。
第十一次作业
UML 图
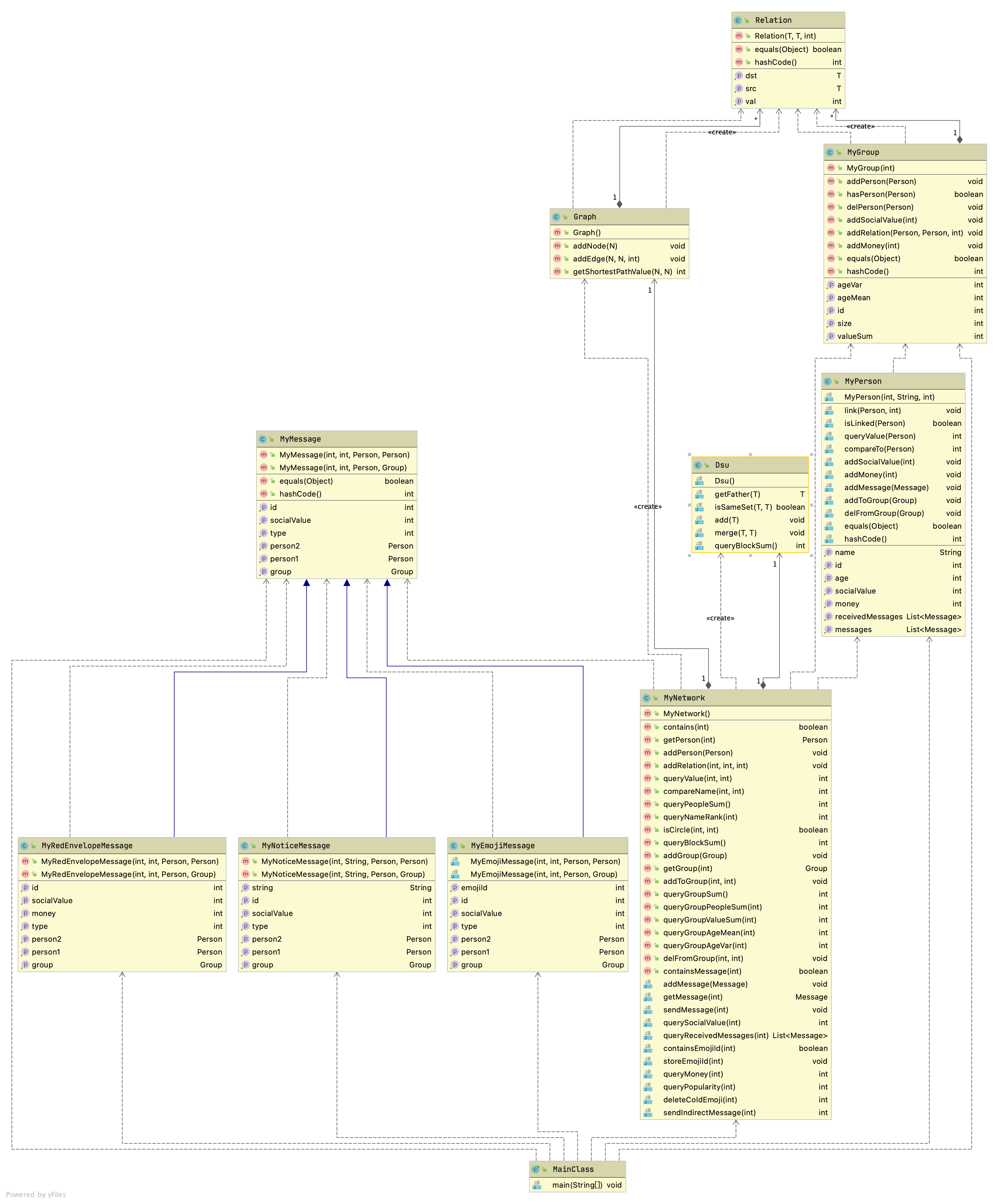
本次作业除了增加三种不同的 messages 以外,基本没有变化。但是多了一个求最短路的请求,因此除了规格的部分外,我自己写了一个 Graph 类,用来处理图相关的询问。
extends 和 implements
本单元新增了规格下的“继承”和“多态”。值得一提的是这次作业需要正确理解 extends 和 implements:
public class MyNoticeMessage extends MyMessage implements NoticeMessage;
按照我的理解:
extends表明了is-a的关系,有利于代码复用implements表明了can的关系,重点在于约束
度量分析
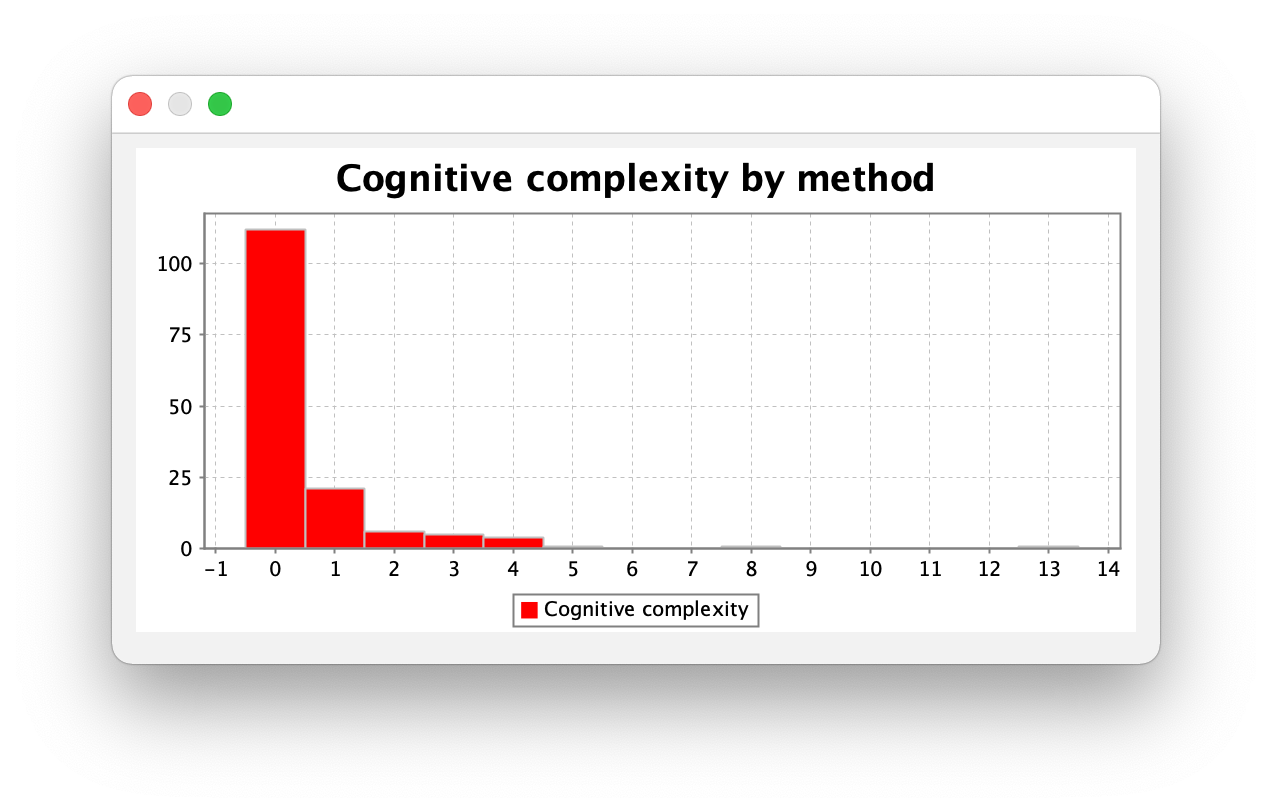
复杂度越来越高了,初步分析是规格中的多态增加了数据流的复杂程度。
不过虽然分析数据看起来更复杂了,但是实际上大部分是由于多态的选择性导致的,可以认为没有问题。
但是如果逻辑进一步复杂,需要考虑使用 visitor 模式等 design patterns 进行优化。
架构分析
基本符合规格。这次作业比前面两次更加直观,没有需要为了性能而 hack 规格进行的操作。
Bug 分析
已经非常努力 Hack 了(毕竟是最后一次)。
但是似乎没什么收获……
对课程的想法和建议
我觉得本单元的内容比较有趣,不仅仅是对规格的学习,还包括了形式化和一些高级数据结构算法的学习。
对比往年的题目,我觉得本单元的题目设置得也更加合理了。
但是我还是想提一个建议:我认为本单元的学习内容除了规格外,学习如何使用测试也是重要内容。建议未来可以在本单元加入一些测试相关的内容,包括回归测试、单元测试等。
因为目前用三次作业来学习规格,总的来说有点单调,而且后面两次的作业其实除了算法外就没有需要更新的知识点了。而加入了测试可以在提高同学正确性的情况下,教会大家养成写测试的习惯。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号