Python TIR 实践经验论文总结(未完待续)
https://zhuanlan.zhihu.com/p/1902381952998281700
ToRL
时间:25.03
目的:学习Agent RL的基本知识
机构:tongyi实验室
链接:https://arxiv.org/pdf/2503.23383

数据处理
我们从NuminaMATH (Li et al., 2024)、MATH (Hendrycks et al., 2021) 和DeepScaleR (Luoet al., 2025) 等奥林匹克级别数学竞赛题目中构建了数据集。初步筛选移除了基于证明的问题和验证标准不明确的题目,得到了75,149 道可验证的题目。随后,我们应用了LIMR (Li et al., 2025),一种强化学习数据蒸馏技术,提取出难度分布均衡的高质量样本。这一过程最终生成了包含28,740道题目的数据集,为所有后续实验奠定了基础。
Prompt

实现细节
- 基本推理模式:为了使模型能够自动输出带有代码块的推理,我们使用了图3中的提示。在模型的展开过程中,当检测到代码终止标识符(
output)时,系统会暂停文本生成,提取最新的代码块并执行,然后将结构化的执行结果以格式output\nOBSERVATION\n```\n 插入到上下文中,其中 OBSERVATION是执行结果。系统随后继续生成后续的自然语言推理,直到模型提供最终答案或生成新的代码块。 - 值得注意的是,当代码执行失败时,我们特意将错误信息返回给LLM,因为我们假设这些错误诊断能够增强模型在后续迭代中生成语法和语义正确代码的能力。我们实施了特定的错误处理优化,以提升训练效果。当Sandbox Fusion 遇到执行错误时,它会生成包含不相关文件路径信息的详细回溯。为了减少上下文长度并仅保留相关错误信息,我们仅提取错误信息的最后一行(例如,NameError: name 'a' is not defined)。
- 工具调用比例:为了将训练速度保持在合理值域内,我们引入了一个超参数C,即模型在单次响应生成过程中可调用的最大工具次数。一旦超过此阈值,系统将忽略进一步的代码执行请求,强制模型切换至纯文本推理模式。
- 掩码处理:损失计算过程中,我们对沙盒环境中的 OBSERVATION 输出进行掩码处理,显著提高了训练稳定性,防止模型试图记忆特定的执行输出,而不是学习可推广的推理模式。
- 奖励函数:我们实现了一个基于规则的奖励函数,其中正确答案获得1 的奖励,错误答案获得-1 的奖励。此外,代码解释器自然提供了关于代码可执行性的反馈。基于成功代码执行与问题解决准确率之间的相关系数,我们引入了一个基于执行的惩罚:包含不可执行代码的响应将减少0.5 的奖励。(此外,默认实验中仅保留答案正确性奖励,未包含代码可执行性奖励)
3.1 分析结果
基本实验:模型的性能表现:
3.3.1 第一部分:代码在训练中的行为表现
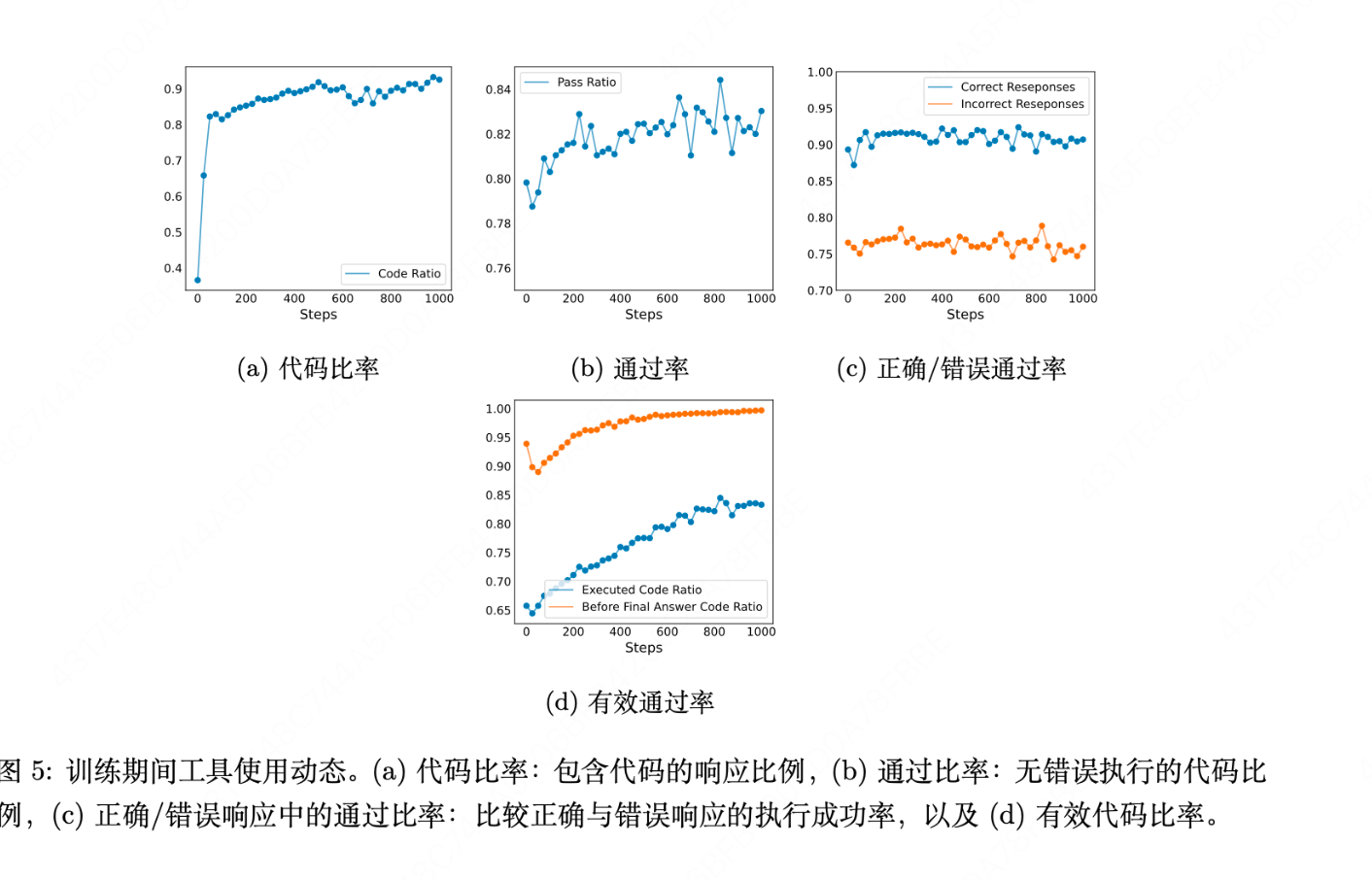
3.3.2 第二部分:关键情景的影响
首先,我们研究了增加C(即单次响应生成过程中可调用工具的最大数量)的影响。具体而言,我们探讨了将C 设置为1 和2 对模型性能的影响。如图 6a 和 6b 所示,将C 设置为2 显著提升了性能,平均准确率提高了约2%。然而,如表 4 所示,增加C 会大幅降低训练速度,因此需要在性能与效率之间进行权衡。
此外,我们分析了将代码可执行性奖励纳入奖励塑造的影响。图6c和图6d表明,这种奖励设计并未提升模型性能。我们推测,引入执行错误的惩罚可能会激励模型生成过于简单的代码以最小化错误,这反过来可能会阻碍其正确解决问题的能力。
3.3.3 模型的反思行为
我们揭示了在模型训练后期出现的一些有趣现象,这些现象有助于我们更细致地理解模型在利用工具解决问题时的认知行为。
表5 展示了模型根据代码解释器的执行反馈调整其推理的一个示例。模型首先编写了代码,但由于对results 的处理不当导致了索引错误。在收到反馈TypeError: 'int' object is notsubscriptable 后,它迅速进行了调整并生成了可执行的代码,最终推断出了正确答案。
表6展示了模型的反思认知行为。
该模型最初通过自然语言推理解决了问题,随后通过工具进行验证但发现了不一致之处。因此,模型进一步进行了修正,最终生成了正确答案。


有几个问题:
【1】模型如何学会代码产生的格式?似乎Math模型自己原来就会!
【2】基座模型选择是什么:Qwen2.5-Math-1.5B-Base
【3】使用的什么RL方法,是Zero-RL吗:Sandbox Fusion 作为代码解释器。我们采用GRPO (Shao et al., 2024) 算法,将rollout 批量大小设置为128,并为每个问题生成16 个样本。为了增强模型探索,所有实验均省略了KL 损失,并将温度设置为1。是Zero-RL
【4】评估:为了评估,我们在所有模型上使用贪心解码(温度= 0)
Zero-TIR-RL
https://zhuanlan.zhihu.com/p/1889286471078368477?spm=a2ty_o01.29997173.0.0.2b5bc921nei5E7
顾名思义,在base上跑tir的rl实验。相比sft阶段的tir,zero-tir不强制模型每道题都使用code解决,而是通过RL自行决定是否使用python-code解题。基本流程:
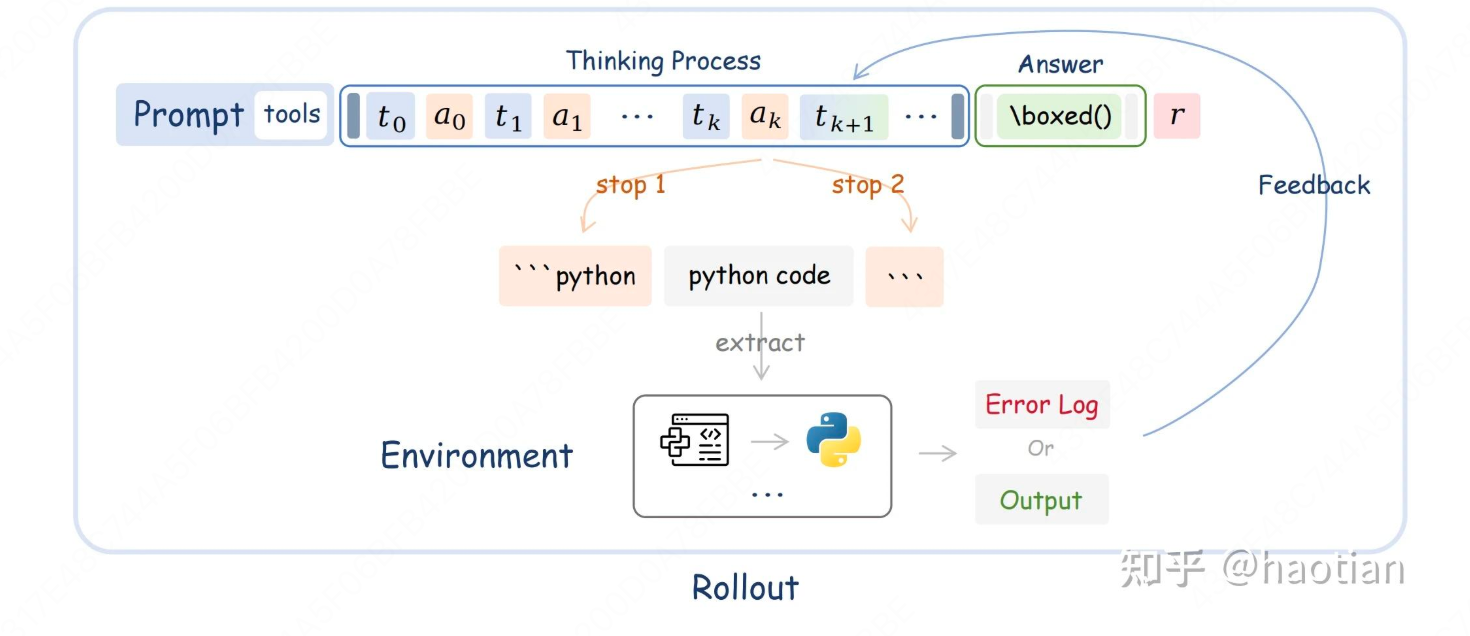
由于涉及工具/代码调用,这里涉及一个问题:直接生成后提取code,再认为拼上code执行的输出接着生成还是按照一定的schema做状态机跳转。这里,笔者选择后者:根据工具/code调用的关键字作为stop-token,这样,相对节省一些采样算力。只需要替换各个训练框架中的llm.generate即可。
#### .2 生成循环
函数通过一个 `while`循环处理多轮生成,每次循环处理尚未终止的提示。循环最多进行3轮(`iterative_num >= 3`时退出),以限制交互次数。
**关键机制**:通过动态修改 `stop`令牌来控制生成流程。
- 初始 `stop`令牌包括 `'```python'`,表示模型生成代码块的开始。
- 当模型生成 `'```python'`时,进入代码生成阶段,将 `stop`令牌改为 `'```'`,等待代码块结束。
- 当模型生成 `'```'`时,提取代码并执行,然后将执行结果作为文本追加到提示中,并将 `stop`令牌改回 `'```python'`,允许继续生成或结束。
#### 3.3 代码执行与结果处理
- 当检测到代码块(通过正则表达式匹配)时,提取代码并调用 `remote_compile`或本地 `run_code`执行。
- 执行结果(或错误信息)被格式化为 `\n```output\n{result}`并添加到生成文本中。
- **关键点**:代码执行输出的令牌会被标记为“非动作”(`action_mask`对应位置为0),这意味着这些令牌不会用于强化学习中的策略梯度计算(因为它们是环境反馈,不是模型动作)。
#### 3.4 终止条件
- 如果模型生成 `'```python'`或 `'```'`之外的停止原因(如达到最大长度、生成结束令牌等),则终止该提示的处理。
- 所有提示都终止后,循环结束。
训练Trick,Reward,Prompt
基础trick:dynamic-sampling/clip-higher/global-batch-token-level-loss
| model | algo | dataset |
|---|---|---|
| qwen25-base | reinforce_baseline/grpo/ppo | orz-57k |
reward使用orz[10]中的设定(不加入code/code执行反馈的reward)。限制环境交互次数<=2(为了提升训练效率)。
使用的prompt(在orz的prompt基础上,加入了In your reasoning-process, You can use python-code to solve your problem. )
我们首先评测了math-tir-generate在qwen25系列上的效果,保证与环境交互的tir-generate是正确的(与官方greedy结果相当)。
用什么算法?
我们在Open-Reasoner-Zero、OpenRLHF两个框架进行,评测了PPO、GRPO、Reinforce++三种算法,每个实验结果复现了3次,整体趋势近似。总的来看,收敛速率上 GRPO>Reinforce++>PPO,最终效果上近似,性能方面近似或高于Qwen2.5 math instruct TIR的表现。可以观察到的主要结论包括:
- 在Math任务中提供Code环境,对Qwen 7B Base模型直接进行RL,模型的Code Reward先降后升,原因可能源于RL前期模型调用Code大量报错,模型倾向于不使用Code,在RL后期,模型调用Code报错次数大量减少,于是Code出现回升。详细case在3.2中给出。
- 在Math任务中,Code In Correct与Code Reward基本保持一致(不是不使用Code Reward吗,使用Reward来描述现象而已),Code可能对提高准确率有所帮助,评测结果上,随着Code比例的提高,模型的准确率逐渐上升。 整体来看,Code在Math中被用于Verification的比例较高,收敛速率上 GRPO>Reinforce++>PPO,最终效果上近似。高于Qwen2.5 math instruct TIR的表现。
最终实验指标(aime24/25 amc23,我们均评测了greedy/pass@1/maj@32)

从收敛效率上来看,grpo > reinforce_baseline > ppo(greedy-avg指标)。不同的算法在评测集上的code使用比例也不太相同,而code比例使用更高的ckpt,最终指标也相对更好。
使用TIR后,aime24的pass@1可以提升到28.5(进一步训练可以提升到29.4(reinforce-400-step)),而在同样的数据集上的zero-rl(不调用tool),aime24的pass@1只有17。其他数据集指标也均比text-cot的更高,且需要的训练steps数少一倍左右。
相比qwen-25-math-instruct+tora,general-base上的zero-tir-rl,仅需要200step即可达到更高的效果,而仅仅使用27k数据集(200step正好过了一半的数据)。而qwen-25-math-instruct经过了大量的math数据ct+大量的sft数据集,至少从数据量和pipline上来看,直接在qwen25-base上的zero-tir具备更高的数据效率。
是否mask掉环境反馈
环境反馈是一个observation,道理上不应该被计入loss(需要在kl/reward/return/advantage/advantage-normalization/loss等等环节加入env-mask,屏蔽掉环境反馈的token)。但对于具备ground-truth的环境如代码执行/物理引擎等等,预测环境输出也是make-sense的(相当于让模型模拟环境,某种意义上是个“dreamer”或者world-model)。
这里,我们在grpo/reinforce_baseline上都跑了env-mask的消融实验,从最终结果来看,没有特别显著的差异--->因为代码执行结果算一个groud-truth,让模型预测代码的执行结果是合理的事情(本身,code-llm也会加入编译/执行结果预测的pretrian/sft数据)。
[9]也提到了类似的问题,只是当成了多阶段训练:
- 模拟环境阶段:在这个阶段,模型使用之前学到的“内部世界模型”进行模拟训练。通过大量的模拟实验,模型可以快速探索各种行动策略,找到最优的解决方案。--->不加env-mask,预测环境输出
- 真实环境阶段:在这个阶段,模型开始与真实环境互动,获取真实的反馈。通过这种方式,模型可以适应真实世界的动态变化,确保在实际应用中的鲁棒性。--->加env-mask,不预测环境输出
Agent RL Scaling Law(ZeroTIR)
机构:fudan+小红书
链接:https://arxiv.org/pdf/2505.07773
算法:Reinforece++,PPO
Trick:
- 动态采样+经验值过滤:首先,我们引入了一种经验池过滤机制,以增强稳定性和集中学习。针对同一提示生成的多个响应被分组,并计算其最终答案的准确率(基于结果奖励)。我们过滤掉准确率高于高阈值 0.8 或低于低阈值 0.2 的组别,优先保留值域中间范围内的样本,此区间内学习梯度可能最为有利。
- 状态机转换:其次,我们实现了一种高效的交互机制,用于在 rollouts 过程中自发的代码执行,如图 3所示,并在算法 1中详细描述。该方法利用动态停止 token(例如 “‘python, “‘)来迭代管理推理、代码生成、与外部代码环境的交互以及执行反馈的集成。这种状态机方法比生成完整序列后再进行事后解析以提取代码要高效得多。该机制还通过计数完成的执行周期(ncalls)来管理工具交互频率。为了实验控制,特别是在初始运行中管理计算资源时,我们强制执行最大调用限制(Nmax)。当达到此限制时,在最终生成恢复之前,会在上下文中注入一条通知(“工具调用次数已耗尽。您不能再调用该工具。”),确保智能体此后依赖内部推理。
异步交互:工具执行和rollout解藕,从而实现异步调用
解耦的代码执行环境(第 3.3节)负责处理所有工具调用。在初始的缩放定律验证实验中,为提升效率,每条轨迹的最大工具调用次数受到限制(Nmax = 20)。评估指标包括贪婪解码(温度 =0)、绝对多数投票、pass@k,以及在不同 top‑p 采样情景(温度 =1)下测量的最终性能度量。
交互上限:
确认了交互上限 Nmax 与所有模型规模的准确率之间存在强烈的单调关系。将上限从零提升到四或二十,平均得分最多可提高十五个百分点,尽管超过四次调用后增益逐渐减少,
这突显了智能体强化学习的缩放规律,即额外的工具使用能带来更好的问题解决能力。
-
训练数据的选择至关重要
- DeepMath(使用以证明为重点的课程数据)在HMMT竞赛中取得了最高的Max得分(60%)。这说明深度、专精的训练能激发峰值推理能力,让模型有时能解决非常难的问题。
- Orz(使用异构的竞赛数据)在CMIMC竞赛中取得了更高的Maj得分(53% vs 33%)。这说明广泛、多样的训练数据能提升模型的稳健性和共识能力,使其表现更可靠。
-
解码阶段的“熵”控制是权衡的关键杠杆
- 实验通过调整
top-p(核采样参数)来控制生成多样性。 - 调高
top-p(增加随机性/熵):在HMMT上将Max得分提升了7分,但在多个数据集上降低了Maj和Avg得分。这直接证实了上述权衡:用稳定性换取了峰值表现。 - 降低熵:可以以很小的峰值得分损失为代价,显著增强共识(Maj)。这对于需要可靠输出的应用是更优策略。
- 实验通过调整
-
训练时与环境(代码解释器)的交互次数并非越多越好
- 这是一个反直觉的发现:将训练时的交互调用上限从4次减少到2次,不仅很少损害性能,有时甚至在4次调用的测试中提高了准确率。
- 在AIME竞赛上,Max得分从50%大幅提升至66%。这表明:
- 大模型学习效率高:它能快速内化有效的代码模式和解题启发式方法。
- 过多探索可能导致“过拟合”:在训练早期进行过多的交互调用,可能让模型“记住”了低效或错误的探索路径,而不是学到通用的解题原理,从而损害了其泛化能力。
目标决定策略:如果你想冲击最高分(如参加竞赛),需要深度、专注的训练数据和解码时允许一定的创造性。如果你需要稳定可靠的助手,则需要多样化的训练数据和解码时较低的随机性。
质量重于数量:在训练中,限制模型与环境(代码解释器)的无效、冗余交互次数,迫使它学习更高效、更通用的思维模式,效果反而更好。这类似于“精打细算的思考”比“盲目试错”更有效。
存在固有权衡:Max(单次最佳)和Maj(共识稳定)是一对需要精心平衡的矛盾目标,可以通过训练数据配比和解码参数进行微调,以适应不同应用场景。
测量代码调用率+代码正确性:图 4 展示了关键的训练动态,为学习过程及智能体 RL 缩放定律在不同实验情景下的表现提供了深刻见解。代码相关指标的演变尤为显著。代码比例,即自发使用代码的频率,在启用 TIR 的模型中始终呈现先降后升的趋势,表明智能体在克服初始生成挑战后,逐渐学会了工具的效用。与此同时,涉及代码的正确回答指标——代码正确率,与原始奖励平均值同
步急剧上升,实证了学成工具的有效使用与任务成功之间的直接关联。
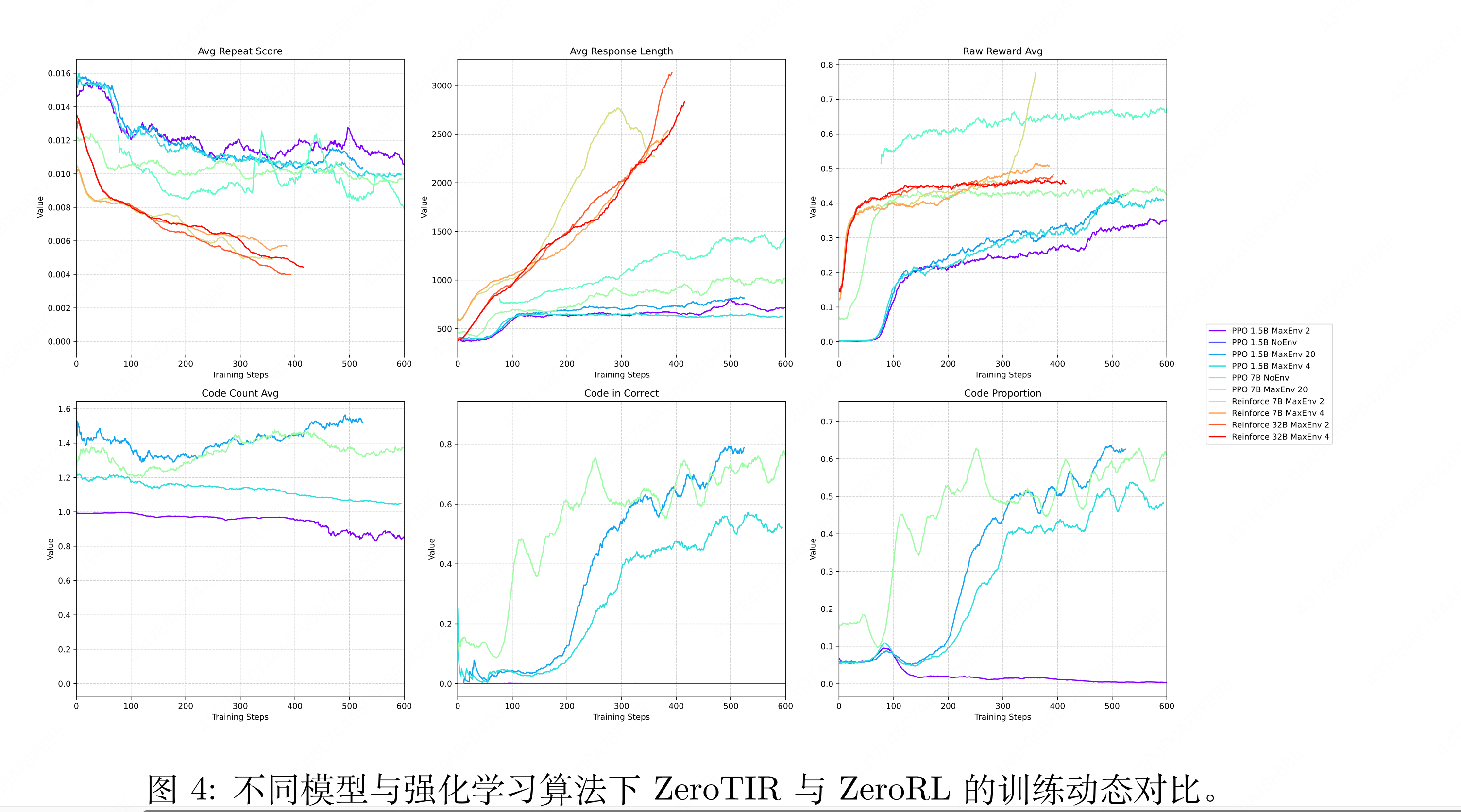
响应长度的消融:响应长度通常随着训练而增加,尤其是对于更大的模型,这与代码和输出的包含相关,尽管这一趋势并不完全反映所有情景下的奖励改进。奖励曲线明确证实,启用工具交互相比非工具基准带来了更优的性能,并进一步展示了随着最大允许交互次数 Nmax 和模型参数数量的增加而呈现的正向缩放效应。
代码次数的消融:有趣的是,虽然消融实验表明较高的 Nmax 值能带来性能提升,但在不同情景中,每次响应的代码调用次数平均值通常稳定在 1 到 2 次之间。这表明,尽管更大的交互预算是可用且有益的,但智能体主要学习的是涉及较少交互的策略。结合这些观察结果,我们得出结论:对于通过 ZeroTIR 学习的基础模型,早期尝试多次交互可能会由于代码质量较低而导致奖励不佳,从而促使智能体收敛到高效的单次调用策略。事实上,我们的分析表明,涉及代码的正确响应中,超过 90% 仅使用单次代码执行,而即使允许的情况下,少于 10% 的响应会使用两次或更多次调用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号