SFTDataset:Verl 单轮Dataset vs Verl 多轮Dataset vs Parallel-R1 Dataset
使用verl进行sft的命令大致为:
- 单机多卡:
#!/bin/bash
set -x
nproc_per_node=4
save_path="./checkpoints"
torchrun --standalone --nnodes=1 --nproc_per_node=$nproc_per_node \
-m verl.trainer.fsdp_sft_trainer \
data.train_files=$HOME/data/gsm8k/train.parquet \
data.val_files=$HOME/data/gsm8k/test.parquet \
data.prompt_key=question \
data.response_key=answer \
optim.lr=1e-4 \
data.micro_batch_size_per_gpu=4 \
model.partial_pretrain=Qwen/Qwen2.5-0.5B-Instruct \
trainer.default_local_dir=$save_path \
trainer.project_name=gsm8k-sft \
trainer.experiment_name=gsm8k-sft-qwen-2.5-0.5b-instruct \
trainer.logger=console \
trainer.total_epochs=3
- Lora微调
torchrun -m verl.trainer.fsdp_sft_trainer \
data.train_files=$HOME/data/gsm8k/train.parquet \
data.val_files=$HOME/data/gsm8k/test.parquet \
model.partial_pretrain=Qwen/Qwen2.5-0.5B-Instruct \
model.lora_rank=32 \
model.lora_alpha=16 \
model.target_modules=all-linear \
trainer.total_epochs=2
可以看出,主要运行了fsdp_sft_trainer这个模块。在这个模块中,定义了FSDPSFTTrainer,用于sft的训练。
大概的结构如下:
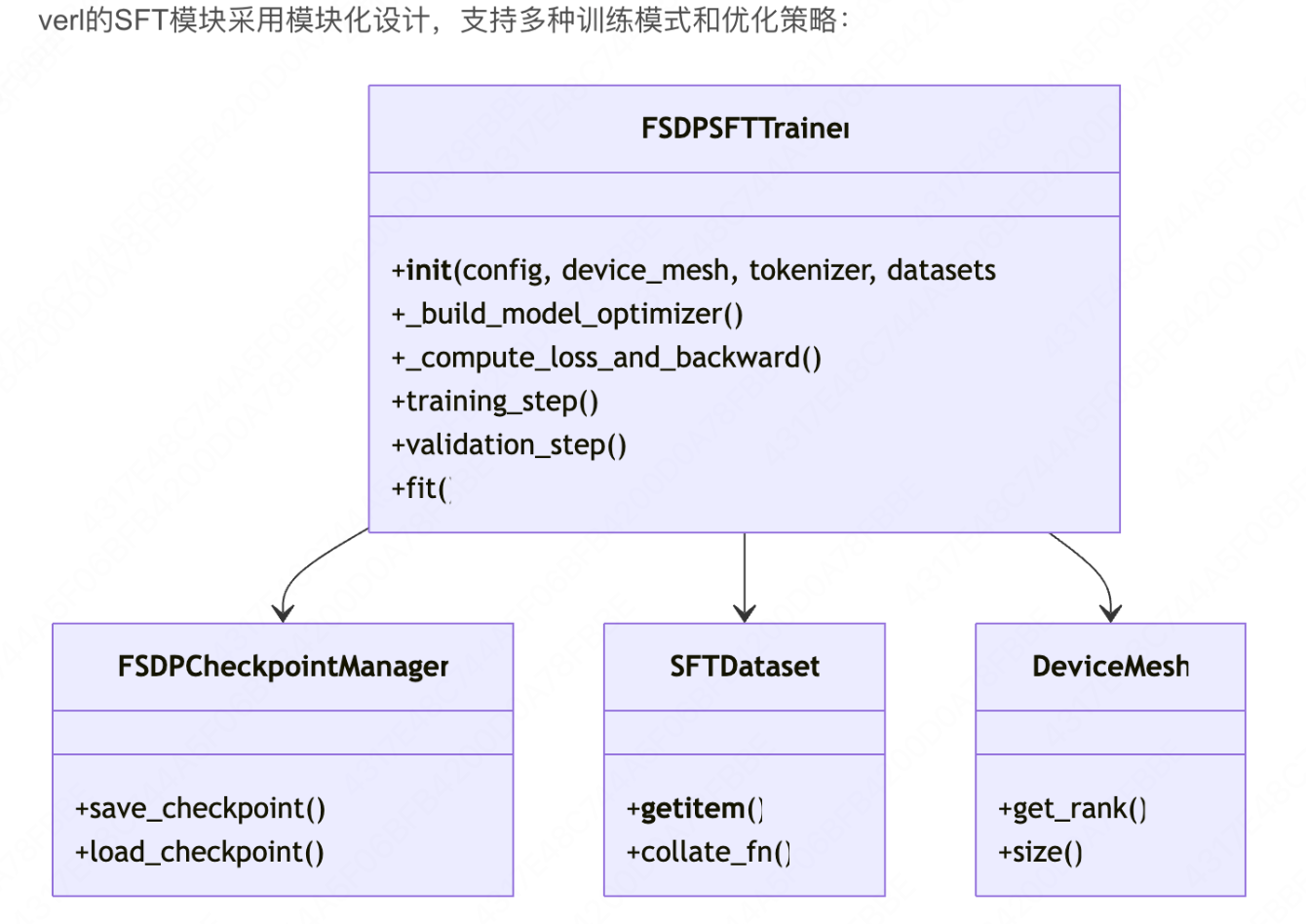
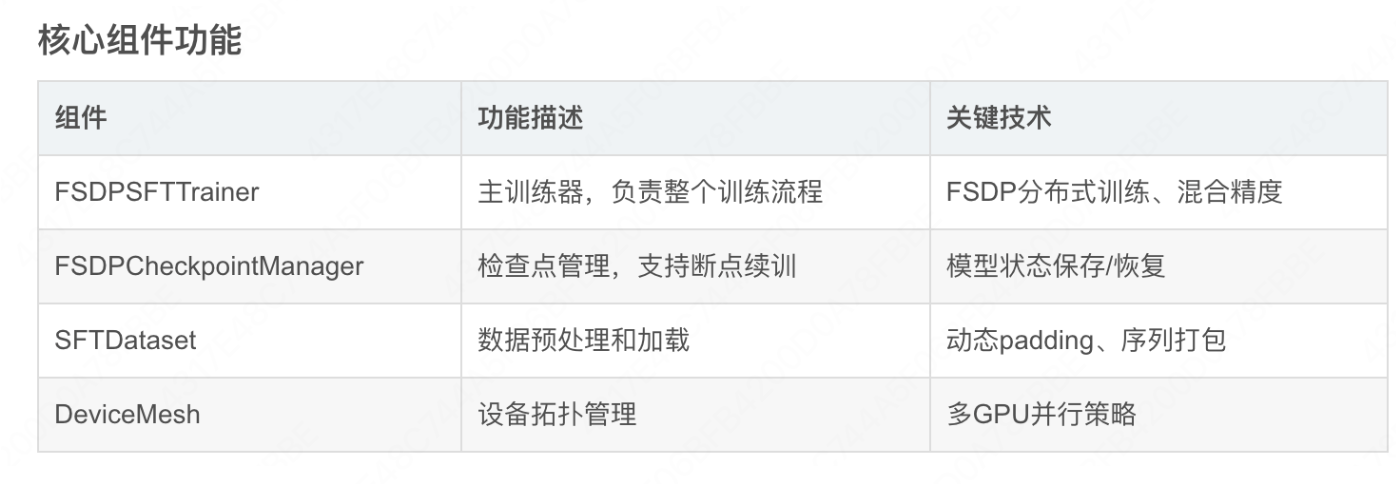
各个组件的功能为:
SFTDataset讲解
在Parallel-R1中,在verl/utils/dataset中,一共定义了三种Dataset,分别是单轮,多轮和Parallel-Dataset。这个Dataset是Verl SFT中唯一值得修改的部分,所以需要好好的讲一讲。
从verl/trainer/fsdp_parallel_sft_trainer.py的create_sft_dataset可以看出,会根据不同的配置来创建不同的Dataset。
def create_sft_dataset(data_paths, data_config, tokenizer):
"""Create a dataset."""
# build dataset
# First check if a custom dataset class is specified
if data_config.custom_cls.get("path", None)
from verl.utils.import_utils import load_extern_type
dataset_cls = load_extern_type(data_config.custom_cls.path, data_config.custom_cls.name)
# Then check if multi-turn dataset should be used
elif data_config.get("multiturn", {}).get("enable", False):
dataset_cls = MultiTurnSFTDataset
# Default to single-turn dataset
else:
dataset_cls = ParallelThinkingSFTDataset
# Create datasets based on the selected class
dataset = dataset_cls(parquet_files=data_paths, tokenizer=tokenizer, config=data_config)
return dataset
首先,我们来看接口,
所有Dataset都继承自torch中的Dataset类,最主要的方法为__getitem__(),返回值为
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"position_ids": position_ids,
"loss_mask": loss_mask,
}
可以看出,Dataset的主要任务就是计算上面这几个变量
单轮Dataset
首先先来看最简单的,单轮对话的Dataset。
主要的细节有两个:
- padding token不参数计算attention(将attention mask掉)
- 用户prompt不参与计算loss(通过loss-mask实现)
def __getitem__(self, item):
tokenizer = self.tokenizer
prompt = self.prompts[item]
response = self.responses[item]
# apply chat template
prompt_chat = [{"role": "user", "content": prompt}]
# string
prompt_chat_str = tokenizer.apply_chat_template(prompt_chat, add_generation_prompt=True, tokenize=False)
response_chat_str = response + tokenizer.eos_token
# tokenize
prompt_ids_output = tokenizer(prompt_chat_str, return_tensors="pt", add_special_tokens=False)
prompt_ids = prompt_ids_output["input_ids"][0]
prompt_attention_mask = prompt_ids_output["attention_mask"][0]
response_ids_output = tokenizer(response_chat_str, return_tensors="pt", add_special_tokens=False)
response_ids = response_ids_output["input_ids"][0]
response_attention_mask = response_ids_output["attention_mask"][0]
prompt_length = prompt_ids.shape[0]
response_length = response_ids.shape[0]
input_ids = torch.cat((prompt_ids, response_ids), dim=-1)
attention_mask = torch.cat((prompt_attention_mask, response_attention_mask), dim=-1)
# padding to max length
sequence_length = input_ids.shape[0]
# 如果序列长度小于最大长度,则进行padding
if sequence_length < self.max_length:
padded_input_ids = (
torch.ones(size=(self.max_length - sequence_length,), dtype=input_ids.dtype)
* self.tokenizer.pad_token_id
)
# !!!需要将padding的attention-mask设置为0(padding token不计算attention)!!!
padded_attention_mask = torch.zeros(size=(self.max_length - sequence_length,), dtype=attention_mask.dtype)
input_ids = torch.cat((input_ids, padded_input_ids))
attention_mask = torch.cat((attention_mask, padded_attention_mask))
# 如果序列长度大于最大长度,则进行截断
elif sequence_length > self.max_length:
if self.truncation == "left":
# actually, left truncation may not be reasonable
input_ids = input_ids[-self.max_length :]
attention_mask = attention_mask[-self.max_length :]
elif self.truncation == "right":
input_ids = input_ids[: self.max_length]
attention_mask = attention_mask[: self.max_length]
elif self.truncation == "error":
raise NotImplementedError(f"{sequence_length=} is larger than {self.max_length=}")
else:
raise NotImplementedError(f"Unknown truncation method {self.truncation}")
# 计算position_ids
position_ids = compute_position_id_with_mask(attention_mask)
# 计算loss_mask
loss_mask = attention_mask.clone()
if prompt_length > 1:
# !!!mask掉prompt!!!
loss_mask[: min(prompt_length, loss_mask.size(0)) - 1] = 0
# !!!mask掉response的最后一个token!!!
loss_mask[min(prompt_length + response_length, loss_mask.size(0)) - 1] = 0
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"position_ids": position_ids,
"loss_mask": loss_mask,
}
多轮Dataset
- 和单轮Dataset的主要区别在于,将所有轮次中,非assistant角色的loss-mask设置为0.
假设消息格式如下:
messages = [
{"role": "user", "content": "查询北京天气"},
{"role": "assistant", "content": "我将为您查询天气", "tool_calls": [{"name": "get_weather", "arguments": {"city": "北京"}}]},
{"role": "tool", "content": "北京今天晴天,20-25度"},
{"role": "assistant", "content": "北京今天晴天,温度20-25度"}
]
那么只会对两个个assistant轮次计算loss,对于user,和tool的轮次都不计算loss。
对于外部插入的生成提示符:Assistant,同样不计算loss。
进一步思考:为什么要这样做?
sft的基本目的,是训练模型的生成token id。因此,对于所有不是模型生成的token,都不应该参与sft损失的计算。而对于所有模型生成的token,都要参与损失计算
这个结论,就可以很好的归纳:单轮对话和多轮对话中loss-mask的区别;以及sft和预训练的区别(预训练中,所有的token都是模型自己生成的,因此不需要mask掉任何token)
如果把LLM看作一个Agent,那么可以理解为,从环境中获取到的信息(Prompt,工具调用结果,外部插入的标签等),都不参与计算loss;反之,自己生成的信息,都要参与loss
def _process_message_tokens(
self,
messages: list[dict[str, Any]],
start_idx: int,
end_idx: int,
is_assistant: bool = False,
enable_thinking: Optional[bool] = None,
tools: Optional[list[dict[str, Any]]] = None,
) -> tuple[list[int], list[int], list[int]]:
"""
处理单个消息或一组消息的token化
Args:
messages: 消息字典列表
start_idx: 消息列表的起始索引
end_idx: 消息列表的结束索引
is_assistant: 是否是助手消息
enable_thinking: 是否启用思考模式
tools: 工具定义列表
Returns:
元组:(tokens, loss_mask, attention_mask)
以
messages = [
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好!有什么可以帮助你的?"}
]
当前轮次为{"role": "assistant", "content": "你好!有什么可以帮助你的?"}进行讲解
"""
# 当前start_idx = 1
if start_idx > 0:
# 对上一轮消息 {"role": "user", "content": "你好"}进行编码
prev_applied_text = self.tokenizer.apply_chat_template(
messages[:start_idx],
tokenize=False,
add_generation_prompt=False,
enable_thinking=enable_thinking,
tools=tools,
)
# 当前的is_assistant=True
if is_assistant:
# 对 {"role": "user", "content": "你好"} +Assistant进行编码(加了生成提示符)
prev_applied_text_w_generation_prompt = self.tokenizer.apply_chat_template(
messages[:start_idx],
tokenize=False,
add_generation_prompt=True, # 添加生成提示符
enable_thinking=enable_thinking,
tools=tools,
)
else:
# 如果是第一条消息,前面没有文本
prev_applied_text = ""
# 对完整的message进行编码
cur_applied_text = self.tokenizer.apply_chat_template(
messages[:end_idx],
tokenize=False,
add_generation_prompt=False,
enable_thinking=enable_thinking,
tools=tools,
)
#
if is_assistant:
# 提取生成提示符Assistant
generation_prompt_text = prev_applied_text_w_generation_prompt[len(prev_applied_text) :]
# 对Assistant进行编码
generation_prompt_tokens = self.tokenizer.encode(
generation_prompt_text,
add_special_tokens=False, # 不添加特殊token
)
# 计算实际回复的内容“你好!有什么可以帮助你的?”
_message_tokens = self.tokenizer.encode(
cur_applied_text[len(prev_applied_text_w_generation_prompt) :],
add_special_tokens=False,
)
# 合并生成提示符token和内容token
message_tokens = generation_prompt_tokens + _message_tokens
# 对Assistant进行loss-mask,对内容token不尽兴loss-mask
loss_mask = [0] * (len(generation_prompt_tokens)) + [1] * (
len(message_tokens) - len(generation_prompt_tokens)
)
else:
# 非助手消息:直接计算当前消息的token
message_tokens = self.tokenizer.encode(
cur_applied_text[len(prev_applied_text) :],
add_special_tokens=False,
)
# 非助手消息的损失掩码全为0
loss_mask = [0] * len(message_tokens)
# 注意力掩码:所有token都设置为1(有效)
attention_mask = [1] * len(message_tokens)
return message_tokens, loss_mask, attention_mask
def __getitem__(self, item):
# 获取分词器
tokenizer = self.tokenizer
# 获取当前样本的消息列表
messages = self.messages[item]
# 获取工具定义(如果存在)
tools = self.tools[item] if self.tools is not None else None
# 获取是否启用思考模式(如果存在)
enable_thinking = self.enable_thinking[item] if self.enable_thinking is not None else None
# 如果工具定义是字符串,解析为JSON对象
if self.tools is not None:
tools = json.loads(self.tools[item])
else:
tools = None
# 第一步:获取完整的对话tokens(用于验证)
try:
full_tokens = tokenizer.apply_chat_template(
messages,
tools=tools,
tokenize=True, # 进行token化
return_tensors="pt", # 返回PyTorch张量
add_generation_prompt=False, # 不添加生成提示符
enable_thinking=enable_thinking,
)
except Exception as e:
# 如果格式化失败,记录错误信息
logging.error(
f"Error applying chat template: {e}\nMessages: {messages}\nTools: {tools}\nEnable thinking: "
f"{enable_thinking}"
)
raise
# 用于验证的拼接tokens
concat_tokens = []
concat_loss_mask = []
concat_attention_mask = []
# 遍历所有消息,按角色类型分别处理
i = 0
while i < len(messages):
cur_messages = messages[i]
# 助手消息处理
if cur_messages["role"] == "assistant":
# 处理单个助手消息
tokens, loss_mask, attention_mask = self._process_message_tokens(
messages, i, i + 1, is_assistant=True, enable_thinking=enable_thinking, tools=tools
)
# 将结果拼接到列表中
concat_tokens.extend(tokens)
concat_loss_mask.extend(loss_mask)
concat_attention_mask.extend(attention_mask)
i += 1
elif cur_messages["role"] == "tool":
# 处理连续的工具消息
st = i
ed = i + 1
# 查找连续的工具消息
while ed < len(messages) and messages[ed]["role"] == "tool":
ed += 1
# 将连续的工具消息作为一个整体处理
tokens, loss_mask, attention_mask = self._process_message_tokens(
messages, st, ed, enable_thinking=enable_thinking, tools=tools
)
concat_tokens.extend(tokens)
concat_loss_mask.extend(loss_mask)
concat_attention_mask.extend(attention_mask)
i = ed
elif cur_messages["role"] in ["user", "system"]:
# 处理用户或系统消息
if cur_messages["role"] == "system" and i != 0:
# 系统消息必须是第一条消息
raise ValueError("System message should be the first message")
# 处理单个用户/系统消息
tokens, loss_mask, attention_mask = self._process_message_tokens(
messages, i, i + 1, enable_thinking=enable_thinking, tools=tools
)
concat_tokens.extend(tokens)
concat_loss_mask.extend(loss_mask)
concat_attention_mask.extend(attention_mask)
i += 1
else:
# 未知角色类型
raise ValueError(f"Unknown role: {cur_messages['role']}")
# 验证并转换tokens
input_ids, loss_mask, attention_mask = self._validate_and_convert_tokens(
full_tokens[0], concat_tokens, concat_loss_mask, concat_attention_mask
)
# 处理序列长度
sequence_length = input_ids.shape[0]
# 如果序列长度小于最大长度,那么填充
if sequence_length < self.max_length:
# 填充序列
pad_token_id = self.tokenizer.pad_token_id if self.tokenizer.pad_token_id is not None else 0
# 创建填充的输入ID(使用pad_token_id)
padded_input_ids = torch.full((self.max_length - sequence_length,), pad_token_id, dtype=input_ids.dtype)
# 创建填充的注意力掩码(全0)
padded_attention_mask = torch.zeros((self.max_length - sequence_length,), dtype=attention_mask.dtype)
# 创建填充的损失掩码(全0)
padded_loss_mask = torch.zeros((self.max_length - sequence_length,), dtype=loss_mask.dtype)
# 拼接原始序列和填充部分
input_ids = torch.cat((input_ids, padded_input_ids))
attention_mask = torch.cat((attention_mask, padded_attention_mask))
loss_mask = torch.cat((loss_mask, padded_loss_mask))
elif sequence_length > self.max_length:
# 序列过长,进行截断
if self.truncation == "left":
# 左截断:保留最后max_length个token
input_ids = input_ids[-self.max_length :]
attention_mask = attention_mask[-self.max_length :]
loss_mask = loss_mask[-self.max_length :]
elif self.truncation == "right":
# 右截断:保留最前max_length个token
input_ids = input_ids[: self.max_length]
attention_mask = attention_mask[: self.max_length]
loss_mask = loss_mask[: self.max_length]
elif self.truncation == "error":
# 抛出错误
raise ValueError(f"{sequence_length=} is larger than {self.max_length=}")
else:
raise ValueError(f"Unknown truncation method {self.truncation}")
# 创建位置ID
position_ids = torch.arange(len(input_ids), dtype=torch.long)
# 用注意力掩码调整位置ID:填充部分的位置ID置为0
position_ids = position_ids * attention_mask
# 返回样本字典
return {
"input_ids": input_ids, # 输入token IDs
"attention_mask": attention_mask, # 注意力掩码
"position_ids": position_ids, # 位置ID
"loss_mask": loss_mask, # 损失掩码
}
ParallelDataset
和普通的SFTDataset的主要区别在于:
- 不同Path之间生成注意力mask
- 校正位置编码
具体的函数如下
def generate_parallel_thinking_reasponse_mask(self, response_ids: torch.Tensor) -> torch.Tensor:
"""
生成注意力mask
"""
seq_len = response_ids.size(0)
mask = torch.tril(torch.ones((seq_len, seq_len), dtype=torch.bool))
path_ranges = []
in_parallel = False
i = 0
while i < seq_len:
tok = response_ids[i].item()
if tok == self.start_parallel_token:
in_parallel = True
path_ranges = []
elif in_parallel and tok == self.start_path_token:
# 找到这一条 <Path>... </Path> 的起止位置
path_start = i
...
path_end = i
path_ranges.append((path_start, path_end))
elif tok == self.end_parallel_token:
in_parallel = False
# 在一个 <Parallel> 块结束时,把不同 path 之间的注意力抹掉
for idx1, (s1, e1) in enumerate(path_ranges):
for idx2, (s2, e2) in enumerate(path_ranges):
if idx1 != idx2:
mask[s1:e1+1, s2:e2+1] = False
path_ranges = []
i += 1
def compute_structured_position_ids(self, response_ids: torch.Tensor) -> torch.Tensor:
"""
1. 当前path中的token position校正为<Parallel>开始的position+当前token相对于<Path>的相对长度
2. </Parallel> 后面的第一个 token position 设为 curr_pos + max_path_len + 1
"""
pad_token_id = self.tokenizer.pad_token_id
seq_len = response_ids.size(0)
pos_ids = torch.zeros(seq_len, dtype=torch.long)
nonpad_mask = (response_ids != pad_token_id)
curr_pos = 0
i = 0
while i < seq_len:
if not nonpad_mask[i]:
i += 1
continue
tok = response_ids[i].item()
if tok == self.start_parallel_token:
pos_ids[i] = curr_pos
i += 1
path_lengths = []
...
# 收集所有 path 的长度
while temp_i < seq_len:
...
if response_ids[temp_i].item() == self.start_path_token:
# 当前路径的(curr_pos表示<Parallel>开始的位置编码,1表示当前路径的相对长度)
local_pos=curr_pos+1
while temp_i < seq_len:
...
# 校正当前Path的Position-id
pos_ids[temp_i] = local_pos
...
local_pos+=1
temp_=+=1
# 小bug:当 <Path> 块缺少结束标签 </Path> 时,循环会执行到 temp_i == seq_len,
# 导致path_end = seq_len,导致越界错误
path_len = pos_ids[path_end] - curr_pos
path_lengths.append(path_len)
...
max_path_len = max(path_lengths) if path_lengths else 0
if i < seq_len and nonpad_mask[i]:
pos_ids[i] = curr_pos + max_path_len + 1
curr_pos += max_path_len + 1 + 1
else:
pos_ids[i] = curr_pos
curr_pos += 1
i += 1
主要的方法为
def __getitem__(self, item):
tokenizer = self.tokenizer
prompt = self.prompts[item]
response = self.responses[item]
# apply chat template
prompt_chat = [{"role": "user", "content": prompt}]
# print(prompt_chat)
# string
prompt_chat_str = tokenizer.apply_chat_template(prompt_chat, add_generation_prompt=True, tokenize=False)
response_chat_str = response + tokenizer.eos_token
# tokenize
prompt_ids_output = tokenizer(prompt_chat_str, return_tensors="pt", add_special_tokens=False)
prompt_ids = prompt_ids_output["input_ids"][0]
prompt_attention_mask = prompt_ids_output["attention_mask"][0]
response_ids_output = tokenizer(response_chat_str, return_tensors="pt", add_special_tokens=False)
response_ids = response_ids_output["input_ids"][0]
response_attention_mask = response_ids_output["attention_mask"][0]
attention_mask_1d = torch.cat((prompt_attention_mask, response_attention_mask), dim=-1)
# response_attention_mask = self.generate_parallel_thinking_reasponse_mask(response_ids)
# print(response_attention_mask.shape)
# print(prompt_attention_mask)
prompt_length = prompt_ids.shape[0]
response_length = response_ids.shape[0]
input_ids = torch.cat((prompt_ids, response_ids), dim=-1)
# padding to max length
sequence_length = input_ids.shape[0]
if sequence_length < self.max_length:
padded_input_ids = torch.ones(size=(self.max_length - sequence_length,), dtype=input_ids.dtype) * self.tokenizer.pad_token_id
padded_attention_mask_1d = torch.zeros(size=(self.max_length - sequence_length,), dtype=attention_mask_1d.dtype)
input_ids = torch.cat((input_ids, padded_input_ids))
attention_mask_1d = torch.cat((attention_mask_1d, padded_attention_mask_1d))
elif sequence_length > self.max_length:
if self.truncation == "left":
# actually, left truncation may not be reasonable
input_ids = input_ids[-self.max_length :]
attention_mask_1d = attention_mask_1d[-self.max_length :]
elif self.truncation == "right":
input_ids = input_ids[: self.max_length]
attention_mask_1d = attention_mask_1d[: self.max_length]
elif self.truncation == "error":
raise NotImplementedError(f"{sequence_length=} is larger than {self.max_length=}")
else:
raise NotImplementedError(f"Unknown truncation method {self.truncation}")
# !!!!! 生成不同路径之间的attantion amsk
attention_mask = self.generate_parallel_thinking_reasponse_mask(input_ids)
# print(attention_mask)
if sequence_length < self.max_length:
# 将padding部分的attention mask设置为False
attention_mask[:,-(self.max_length - sequence_length):] = False
attention_mask[-(self.max_length - sequence_length):,:] = False
# print(attention_mask)
attention_mask = attention_mask.unsqueeze(0)
# attention_mask = torch.cat((prompt_attention_mask, response_attention_mask), dim=-1)
float_attention_mask = torch.full_like(attention_mask, -torch.inf, dtype=torch.float)
float_attention_mask = float_attention_mask.masked_fill(attention_mask, 0.0)
## !!!!!!校正位置编码
position_ids = self.compute_structured_position_ids(input_ids)
loss_mask = attention_mask_1d.clone()
if prompt_length > 1:
# mask out prompt for SFT.
loss_mask[: min(prompt_length, loss_mask.size(0)) - 1] = 0
# mask out the last token in response
loss_mask[min(prompt_length + response_length, loss_mask.size(0)) - 1] = 0
# print(float_attention_mask.shape)
# print(loss_mask.shape)
# print(position_ids.shape)
return {
"input_ids": input_ids,
"attention_mask": float_attention_mask,
"bool_attention_mask": attention_mask,
"position_ids": position_ids,
"loss_mask": loss_mask,
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号