deepseek-r1-grpo
1. DeepSeek-r1-zero(推理能力提升)
1.1 数据
-
prompt模版

-
数据详情:文章中没有提到
1.2 奖励建模
采用基于规则的奖励系统,主要包括两类奖励:
- 准确率奖励:准确率奖励模型评估响应是否正确。
- 例如,在具有确定性结果的数学问题中, 要求模型以指定格式(如方框内)提供最终答案,从而实现基于规则的可信正确性验证。
- 类似地,对于 LeetCode 问题,可使用编译器基于预定义测试用例生成反馈。
- 格式奖励:除了准确率奖励模型外,我们还使用了一个格式奖励模型,以强制模型将其思考过程放在
<think>和</think>标签之间。 - 在开发 DeepSeek-R1-Zero 时,我们并未采用结果或过程神经奖励模型,因为发现神经奖励模型在大规模强化学习过程中可能遭遇奖励破解问题,且重新训练奖励模型需要额外训练资源,这会使整个训练流水线复杂化。(在后来的工作里面,其实大量使用到了神经奖励/过程奖励的方法来构造奖励函数)
1.3 自我进化/顿悟现象
-
表现1:思考时间变长
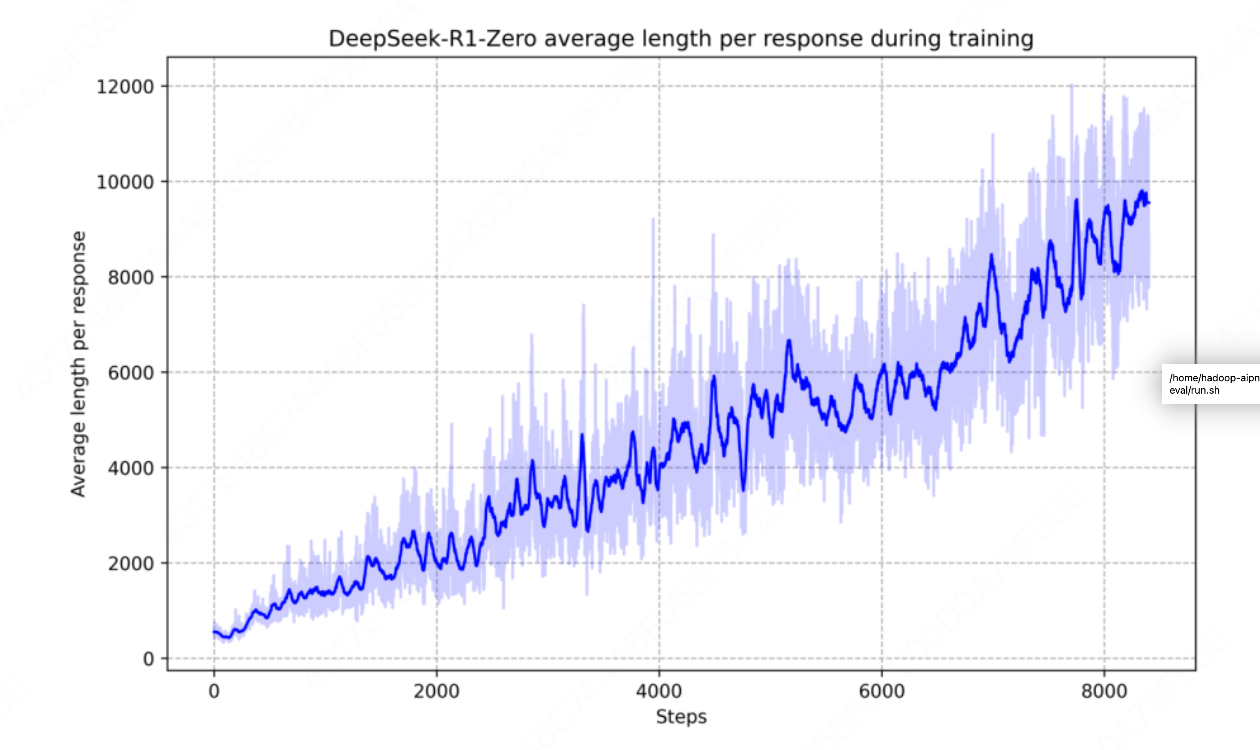
-
表现2:学会了反思

1.4不足之处
deepseek-r1-zero出现了:
- 可读性差
- 多语言混合的问题
2. DeepSeek-R1
受 DeepSeek-R1-Zero 优异表现的启发,我们自然产生两个疑问
- 通过引入少量高质量数据作为冷启动,能否进一步提升推理性能或加速收敛?
- 如何训练出既能生成清晰连贯的思维链 (CoT),又具备强大通用能力的用户友好型模型?
2.1 冷启动
- 数据:
- 来源:
- few-shot prompt
- zero-shot prompt
- DeepSeek-R1-Zero可读格式的输出结果
- 人工标注员后期处理
- 大小:几千条
- 来源:
- base模型:
- deepseek-V3-Base(注意使用的是Base模型,而不是instruct模型)
- 冷启动的优势
- 可读性:DeepSeek-R1-Zero 的一个关键局限在于其内容往往不适合阅读。响应可能混合多 种语言,或缺少用于向用户突出答案的 Markdown 格式。相比之下,在为 DeepSeek-对读者不友好的响应。在此,我们将输出格式定义为 |special_token|< 推理过程 >|special_token|< 总结 >,其中推理过程是针对查询的思维链,总结则用于概括推理结果。
- 潜力:通过精心设计融合人类先验的冷启动数据模式,我们观察到相较于 DeepSeek-R1- Zero 模型实现了更优的性能。我们坚信迭代训练是提升推理模型能力的更有效途径。
思考:这篇文章中,对于冷启动的作用,概括为两点:1. 学习基本约束条件。(体现为单一语言+输出格式) 2. 提高RL的性能
2.2 推理RL
- 奖励函数:训练过程中,我们观察到思维链常出现语言混合现象, 尤其是在强化学习提示涉及多语言场景时。为缓解语言混合问题,我们引入了语言一致性奖励机制,该奖励通过计算思维链中目标语言词汇占比来实现。最终,我们通过直接相加的方式将推理任务准确率与语言一致性奖励相结合,构成最终奖励信号。
思考:如何设计奖励?从这篇文章中可以看到,奖励函数的设计有两种要素决定:1. 最终目标(文中体现为推理任务准确率奖励) 2. 次要目标,或者对badcase的修复(文中体现为语言一致性奖励)
2.3 通用SFT
- 数据:
- 推理数据(60w)
- 拒绝采样:从强化学习收敛后的检查点执行拒绝采样来生成推理轨迹
- 严格过滤掉混合语言、冗长段落及代码块的思维链,仅保留正确答案
- 评估机制:部分数据采用生成式奖励模型,将真实答案与模型预测输入DeepSeek-V3进行自动评判
- 非推理数据(20w)
- 智能适配:针对不同复杂度任务采用差异化处理
- 复杂任务:通过提示工程调用DeepSeek-V3生成潜在思维链
- 简单查询:直接提供答案而不包含推理过程
- 智能适配:针对不同复杂度任务采用差异化处理
- 推理数据(60w)
- 基座: DeepSeek-V3-Base
为什么对V3-Base进行微调,为什么不接着上一段RL的检查点进行微调?
2.4 通用RL
- 目标:提升有用性和无害性,同时精进推理能力
- 推理数据:
- 和R1一样,使用正确性奖励+格式奖励
- 通用数据(使用Reward Model):
- 对于有用性评估,我们聚焦最终回答的总结部分,确保评估重点落在回应用户需求的实用 性与相关性上,同时最大限度减少对潜在推理过程的干扰。
- 在无害性评估中,我们全面审视模型的完整输出(包括推理过程与总结),以识别并消除生成过程中可能出现的潜在风险、偏见或有害内容。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号