强化学习真的能激发LLM的推理能力吗
arixv链接
日期:25.04
机构:LeapLab+清华
期刊:NiPS best paper
一篇实验文章,作者通过实验发现,强化学习(RLVR)方法虽然能够提高大语言模型在数学、编程等推理任务上的采样效率(即在少量尝试中获得正确答案的概率),但并没有真正激发出超越基础模型的全新推理能力。 (传统观点认为:RL方法可以增强LLM的推理能力)
实验过程
指标:pass@k
引入了pass@k来衡量模型的推理边界。
- pass@k:对于给定的问题,从模型采样k个输出,如果至少有一个输出通过验证,则该问题被认为可解。
实验1:pass@k分析
文章中分析了三个领域:数学推理,代码生成,视觉推理,这里以数学推理为例,讲解实验结果。
作者使用了其他论文训练好的模型(在GSM8K数据集上和MATH数据集上使用仅包含正确性奖励的GRPO进行Zero-RL训练)计算pass@k,对比base模型的pass@k。
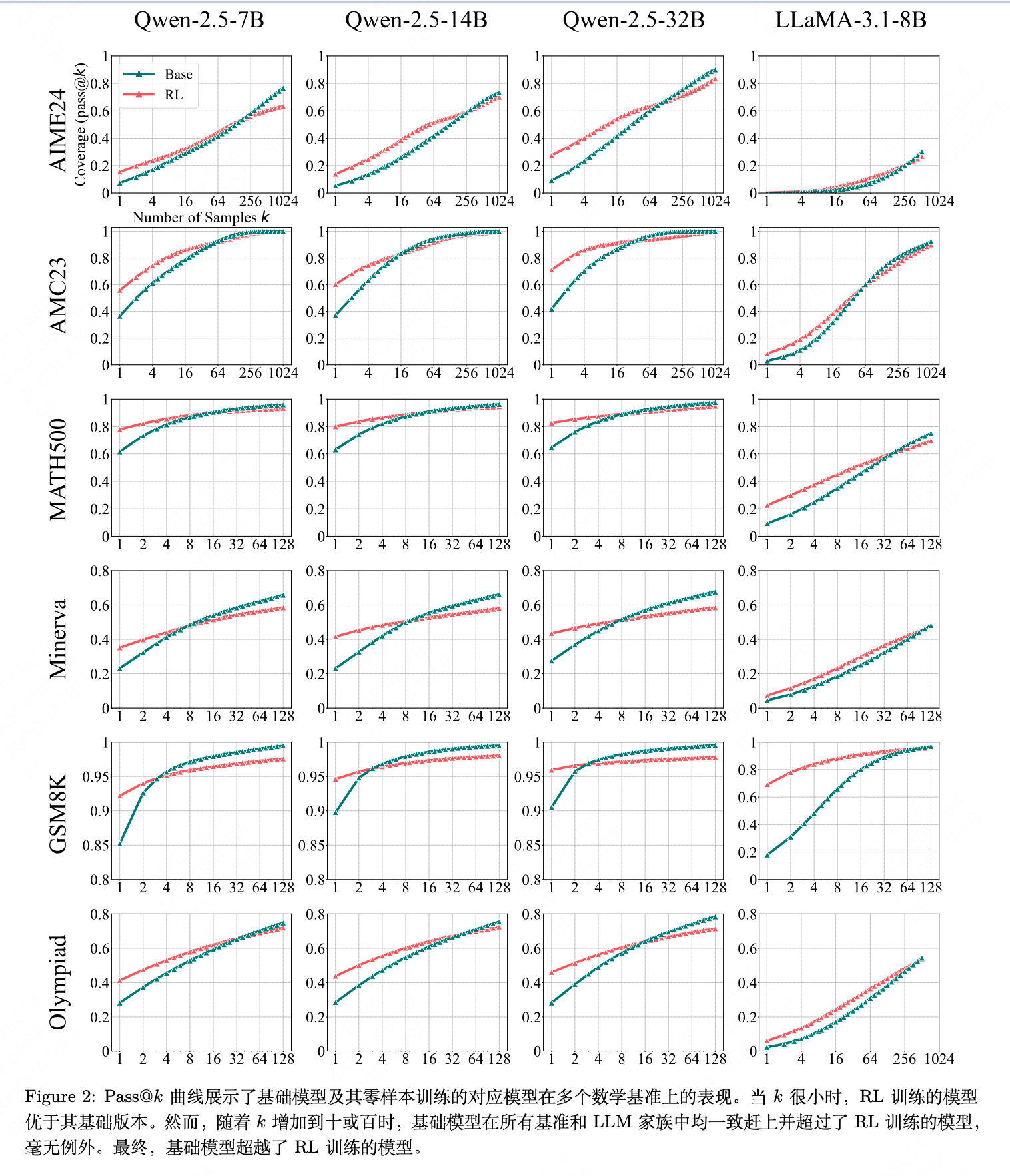
基本结果如上图,作者根据上面的图片做了几个分析:
- 结果分析:
- 如 Figure 2所示,我们一致观察到小规模和大规模 k 值之间呈现出相反的趋势。当 k 较小时(例如,k = 1,相当于平均准确率),RL 训练的模型优于其基础对应模型。这与常见的观察结果一致,即 RL 可以提高性能,表明 RLVR 使模型显著更有可能采样正确的响应。
- 然而,随着 k 增加到数十或数百时,在所有benchmark和 LLM 家族中,基础模型始终追上并超过了 RL 训练的模型,无一例外。值得注意的是,基础模型的 pass@k 曲线比其 RL 训练版本表现出更陡峭的上升趋势。最终,在足够大的 k 下,基础模型超越了 RL 训练模型,表明基础模型对可解问题的覆盖范围比增强版 RL 模型更广。例如,在 Minerva 基准测试中使用 32B 大小的模型时,在 k = 128 处,基础模型比 RL 训练模型高出约 9%,这意味着它在验证集中可以解决大约多 9%的问题。
- 有效性分析:
- 我们手动检查了在 GSM8k 数据集中最具有挑战性的可解问题的所有 CoTs——这些问题是那些平均准确率低于 5% 但高于 0% 的问题。基础模型回答了 25 个这样的问题,其中24 个包含至少一个正确的 CoT。同样,RL 训练的模型回答了 25 个问题,其中 23 个包含了至少一个正确的 CoT。
- 这些结果表明,即使在 GSM8k 中最难的问题上,解决问题主要依赖于采样有效的推理路径,而不是依赖幸运的猜测,这意味着在大 k 值下 pass@k 可以作为模型推理边界的一个相对准确的指标。
实验2:可解问题范围分析与困惑度分析
- RLVR模型的可解问题覆盖范围是Base模型覆盖范围的子集:
RLVR 模型的可解问题覆盖范围是基础模型覆盖范围的一个近似子集。在 Section 3 中的实验意外地表明,基础模型比 RLVR 训练的模型解决了更多的可解问题。为了进一步调查,我们在 AIME24 上比较了基础模型及其对应的 RL 训练版本的可解问题集合。我们发现,RL 训练的模型所解决的问题集合几乎是基础模型可解问题集合的一个子集,如 Table 4 所示。

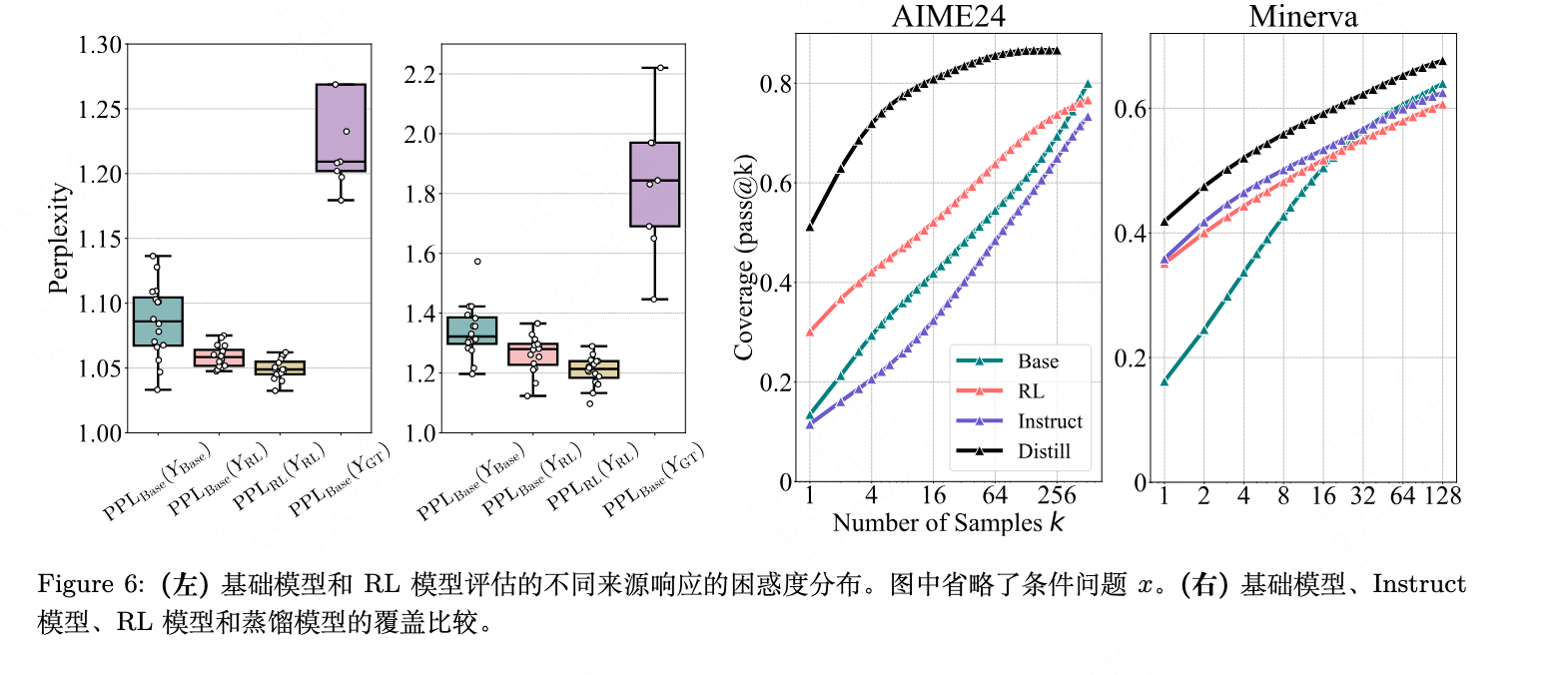
- 困惑度分析:
我们从 AIME24 中随机抽取两个问题,并使用 Qwen-7B-Base 和 SimpleRL-Qwen-7B-Base 为每个问题生成 16 个响应,分别记为 Ybase 和 YRL。我们还让 OpenAI-o1 (Jaech et al., 2024) 生成 8 个响应,记为 YGT 。如 Figure 6 左图所示,PPLBase(YRL|x) 的分布与 PPLBase(YBase|x) 分布的下部分紧密匹配,对应于基础模型倾向于生成的响应。这表明,通过强化学习训练的模型的响应有很大可能性是由基础模型生成的。
结论
根据上面的分析,作者得出以下结论:
1. RLVR 不会引发超出基础模型的新推理能力。在大值 k 下 pass@k 的趋势以及困惑度的分布表明,RL 模型的推理覆盖范围完全在其基础模型的范围内。RL 模型利用的所有推理路径已经存在于基础模型中。因此,RL 训练没有引入任何根本性的新推理能力,RL 模型的能力仍然受限于其基础模型。
2. RLVR 提升采样效率。尽管 RL 模型中的推理路径已经存在于基础模型中,但 RL 训练提升了pass@1 性能,如 Section 3所示。这表明通过将输出分布偏向高奖励的响应,RL 提高了对基础模型中已编码的正确推理路径进行采样的似然性。
3. RLVR 缩小了推理边界。RLVR 的效率提升是以降低覆盖率为代价的:与基础模型相比,随着 k 值的增大,pass@k 会减少。我们将此归因于 RL 倾向于降低输出熵,这限制了探索。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号