【论文精读】Multi-modal Knowledge Graphs for Recommender Systems
【论文精读】Multi-modal Knowledge Graphs for Recommender Systems
论文链接:Multi-modal knowledge graphs for recommender systems
年份:2020
引用数:270+
影响:首次将知识图谱用于多模态推荐
1. 什么是知识图谱
-
知识图谱(Knowledge Graph,KG)
一个知识图谱, \(G=(V, E)\) ,是一个有向图,其中 \(V\) 表示节点集, E 表示边集。每条边以(头节点,关系,尾节点)的形式表示(记为 \((h, r, t)\) ,其中 \(h, t \in V, r \in R\),\(R\)是所有关系的集合) ,表明从头节点 \(h\) 到尾节点\(t\) 的关系 \(r\) 。
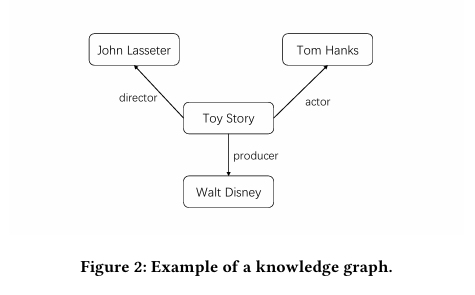
例如,电影Toy Story(玩具总动员)的导演,演员,制片人分别是John Lasseter,Tom Hanks,Walt Disney。如果把Toy Story,John Lasseter,Tom Hanks,Walt Disney看作四个节点,那么这四个节点就可以构成一个知识图谱,如下图。
其中,连接Toy Story和John Lasseter的边可以记作\(\text { (Toy Story, DirectorOf, John Lasseter) }\),表示这条边的头节点是Toy Story,尾节点是John Lasseter,头节点和尾节点之间的关系是DirectorOf,即:Toy Story的导演是John Lasseter。其他边的表示也是同理。
-
多模态知识图谱(Multi-modal Knowledge Graph,MKG)
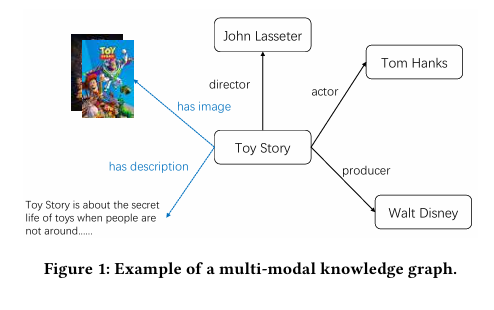
多模态知识图谱 也是一种知识图谱。和普通的知识图谱不同,MKG额外引入了多模态信息(文字描述,图像等)。
以图 1 为例,我们可以用\(\text { (Toy Story, hasImage, a picture of film promotion) }\)来表示Toy Story有一张图像,用\(\text { (Toy Story, hasDescription, description) }\)来表示Toy Story有相应的文字描述。
-
协同知识图谱(Collabarative Knowledge Graph,CKG)
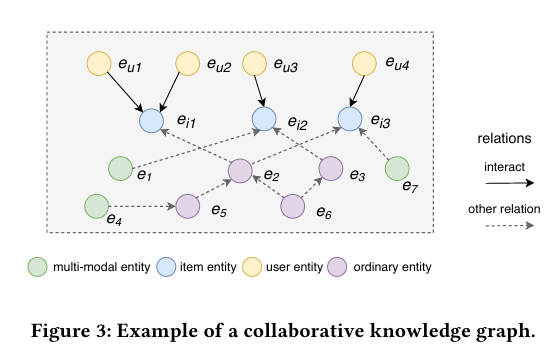
CKG 首先定义一个用户 - 物品二部图,其形式为 \(\left.\left(e_u, y_{u i}, e_i\right) \mid e_u \in U, e_i \in I\right)\) ,其中 \(e_u\)是用户实体, \(y_{u i}\) 表示用户 \(u\) 和物品 \(i\) 之间的交互, \(e_i\) 表示物品实体, u 和 I 分别表示用户集和物品集。当 \(e_u\) 和 \(e_i\) 之间存在交互时, \(y_{u i}=1\) ;否则, \(y_{u i}=0\)。
然后,CKG 将用户 - 物品二部图融入知识图谱,其中每个用户的行为表示为一个三元组\(\left(e_u\right.\), Interact,\(\left.e_i\right)\)。 Interact \(=1\) 表示 \(e_u\) 和 \(e_i\) 之间存在交互关系。将用户-物品二部图与多模态知识图谱结合,可以形成一个新的知识图谱,如下图所示。其中黄色圆点表示用户,蓝色圆点表示物品,绿色圆点表示物品的各种多模态信息,紫色圆点表示物品的其他信息(例如,John Lasseter(Toy Story的导演)对应的节点就是紫色的)。
2. Method
本文提出了一种名为Multi-modal Knowledge Graph Attention Network (MKGAT)的模型。
模型的输入输出分别是:
- 输入:数据集的协同知识图谱。
- 输出:用户向量\(\mathbf{e}_u^*\)和物品向量\(\mathbf{e}_i^*\)。最终,模型预测的用户\(u\)对物品\(i\)的感兴趣程度\(\hat{y}(u, i)\)由公式\(\hat{y}(u, i)=\mathbf{e}_u^{* \mathrm{~T}} \mathbf{e}_i^*\)算出。
模型的大概结构如下图,
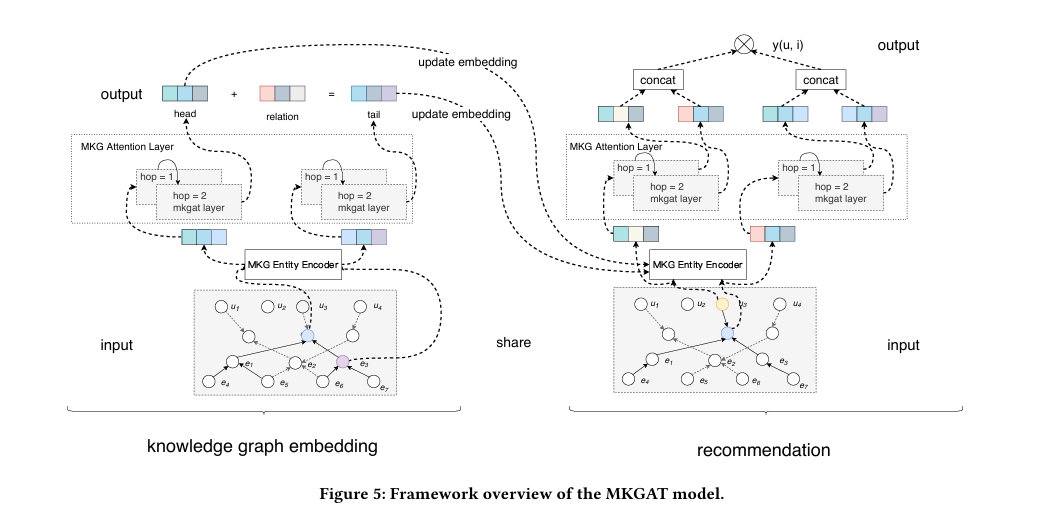
可以看出,主要包含两个子模块:
- knowledge graph embedding:主要是利用协同知识图谱的下半部分,也就是多模态知识图谱(MKG)来更新物品向量。
- recommendation:主要利用用户和物品的交互信息,来更新用户向量和物品向量,最后进行打分。
在讨论这些子模块之前,我们首先介绍两个关键组件:MKG Entity Encoder与MKG Attention Layer,这两个组件在两个子模块中都有用到。
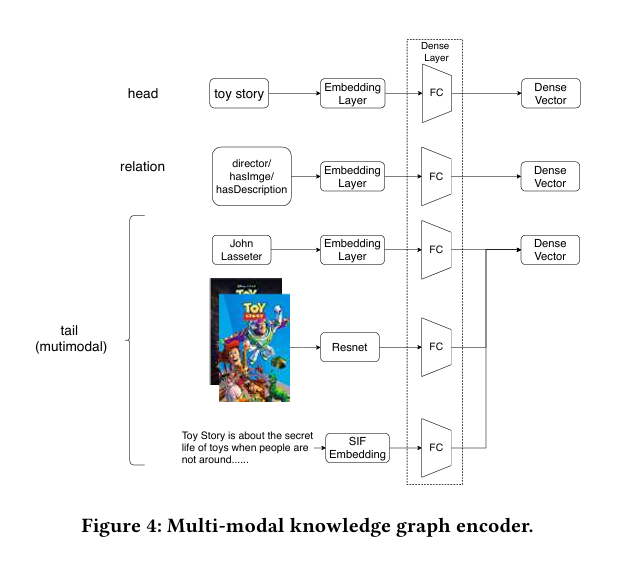
2.1 MKG Entity Encoder组件
- ID信息:使用Embedding Layer进行编码。
- 图像:使用ResNet进行编码。
- 文本:使用SIF Embedding进行编码。
整体过程如下图所示,对头节点,关系,和尾节点分别使用相应的技术进行编码,最后通过全连接层,形成三个维度相同的向量,分别表示头节点,关系,以及尾节点。
2.2 MKG Attention Layer组件
$ \mathbf{e}(h, r, t)$可通过如下公式得到, \(e_h\) 和 \(e_t\) 是实体嵌入, \(e_r\) 是关系嵌入。
注意力系数$\pi(h, r, t) $可通过下面的公式得到:首先经过线性变化与LeakyReLU激活函数,然后经过softmax进行归一化。
得到表示邻居的向量\(\mathbf{e}_{a g g}\)后,可以通过加法聚合或者拼接聚合将\(e_h\) 和 \(e_{a g g}\)拼接起来
当然,通过堆叠多个attention层,可以聚合到高阶邻居的特征。
2.3 knowledge graph embedding模块
-
流程:
首先是总图左侧的知识图谱嵌入模块,在这个模块中,先不管用户和物品的交互信息,仅仅利用物品的多模态知识图谱,来更新物品表示。
将多模态知识图谱作为输入,经过MKG Entity Encoder和\(L\)个MKG Attention Layer后,对于多模态知识图谱中的每个节点,会得到: \(e_h\), \(e_t\) 与 \(e_r\) ,其中 \(e_h\), \(e_t\) 表示头节点和尾节点经过Encoder层和Attention层后的输出,\(e_r\) 是关系向量经过Encoder层后的输出。
-
损失函数:
使用知识图谱中常用的translational scoring function作为损失函数。 尽可能让 \(e_h+e_r\)和\(e_t\)更接近,使用MSE来评估\(e_t\)与\(e_h+e_r\)的距离。
\[\operatorname{score}(h, r, t)=\left\|e_h+e_r-e_t\right\|_2^2 \]让正样本的距离尽可能小,负样本的距离尽可能大:
\[\mathcal{L}_{K G}=\sum_{\left(h, r, t, t^{\prime}\right) \in \mathcal{T}}-\ln \sigma\left(\operatorname{score}\left(h, r, t^{\prime}\right)-\operatorname{score}(h, r, t)\right) \]其中\(\mathcal{T}=\left\{\left(h, r, t, t^{\prime}\right) \mid(h, r, t) \in G,\left(h, r, t^{\prime}\right) \notin G\right\}\) ,并且 \(\left(h, r, t^{\prime}\right)\) 是通过随机替换有效三元组中的一个实体而构建的无效三元组。 \(\sigma(\cdot)\) 是 sigmoid 函数。
2.4 Recommendation模块
- 流程:
接下来是总图右侧的推荐模块。推荐模块其实和刚才讲的模块类似,只不过刚才得到的是物品的嵌入向量,推荐模块需要利用用户和物品的交互信息,将刚才得到的物品向量和初始化但未训练的用户向量信息输入到MKG Entity Encoder,再进入MKG Attention层,用户向量和物品向量生成一个表示,最后进行打分。
刚才说的Attention层是以递归的形式计算的,推荐系统模块有一点不同,它会保存每一跳的计算信息,并且拼接到一起,即
其中\(\|\) 表示拼接,\(L\)表示Attention层的个数。
然后,把向量做内积作为模型的预测分数。
-
损失函数:
使用推荐系统常用的BPR损失。
\[\mathcal{L}_{\text {recsys }}=\sum_{(u, i, j) \in O}-\ln \sigma(\hat{y}(u, i)-\hat{y}(u, j))+\lambda\|\Theta\|_2^2 \]其中\(O=\left\{(u, i, j) \mid(u, i) \in R^{+},(u, j) \in R^{-}\right\}\)表示训练集, \(R^{+}\)表示用户 u 和项目 i 之间的观察到的交互, \(R^{-}\)是采样的未观察到的交互集, \(\sigma(\cdot)\) 是 sigmoid 函数, \(\Theta\) 是参数集, \(\lambda\) 是 L2 正则化的参数。
两个模块交替优化:先使用translational scoring function优化knowledge graph embedding模块,再使用BPR损失优化Recommendation模块,而后再优化knowledge graph embedding模块...如此交替,直到训练结束。
3. Experiments
-
和其他baseline相比,达到了sota。
-
使用多模态信息时,模型表现要比不使用多模态信息时好。(如果单模态的效果比多模态好,那么就会按单模态推荐投论文了)
-
这两个消融实验,一个是论证了Attention的层数取多少好,结论是:层数取2或者3时,会取得较好的效果。第二个是论证在Attention层中,加法聚合方式和拼接聚合哪个更好,作者做了实验发现,拼接聚合的效果更好。
-
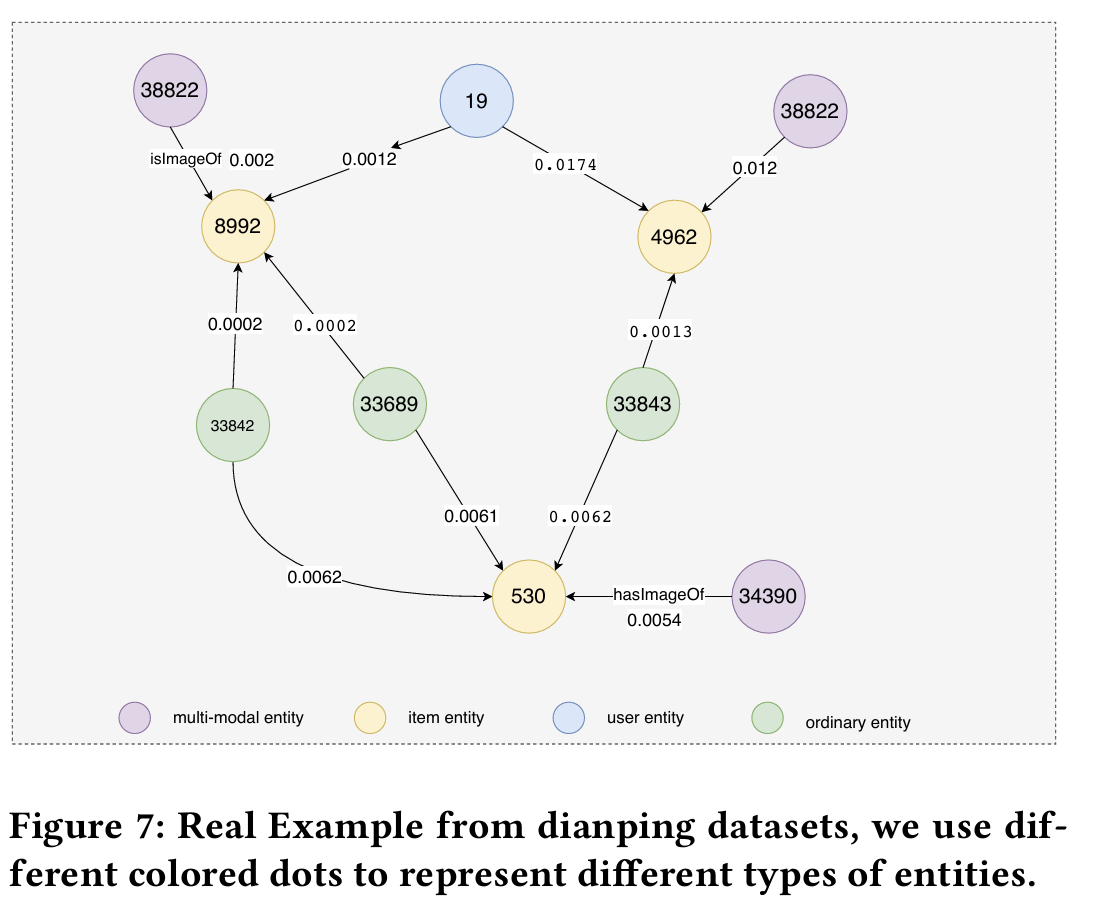
最后一个实验是找了一个案例。这些圆圈代表不同的实体,中间的数字是代表id,边是代表一个实体对另一个实体的重要性,可以看到这个紫色的多模态信息的0.002比绿色的传统信息多了十倍左右,说明多模态信息在推荐系统确实起到了较大的作用。(结论存疑,因为对于530号物品来说,多模态信息的权重并不大)。
4. 个人总结
总的来说,MKGAT的架构分为两个部分:第一个部分以知识图谱的形式提取物品的多模态信息,第二个部分关注于用户-物品二部图,用以更新用户和物品向量。
实际上,这和使用LightGCN来提取信息的模型没有本质上的区别,只不过一个是图,一个是知识图谱罢了。
但不管怎么说,本文首次把知识图谱用在了多模态推荐中,并且取得了不错的效果,算是开辟了多模态推荐中的一个新方向。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号