cdq分治

P3810
经典三维偏序 · 陌上花开。
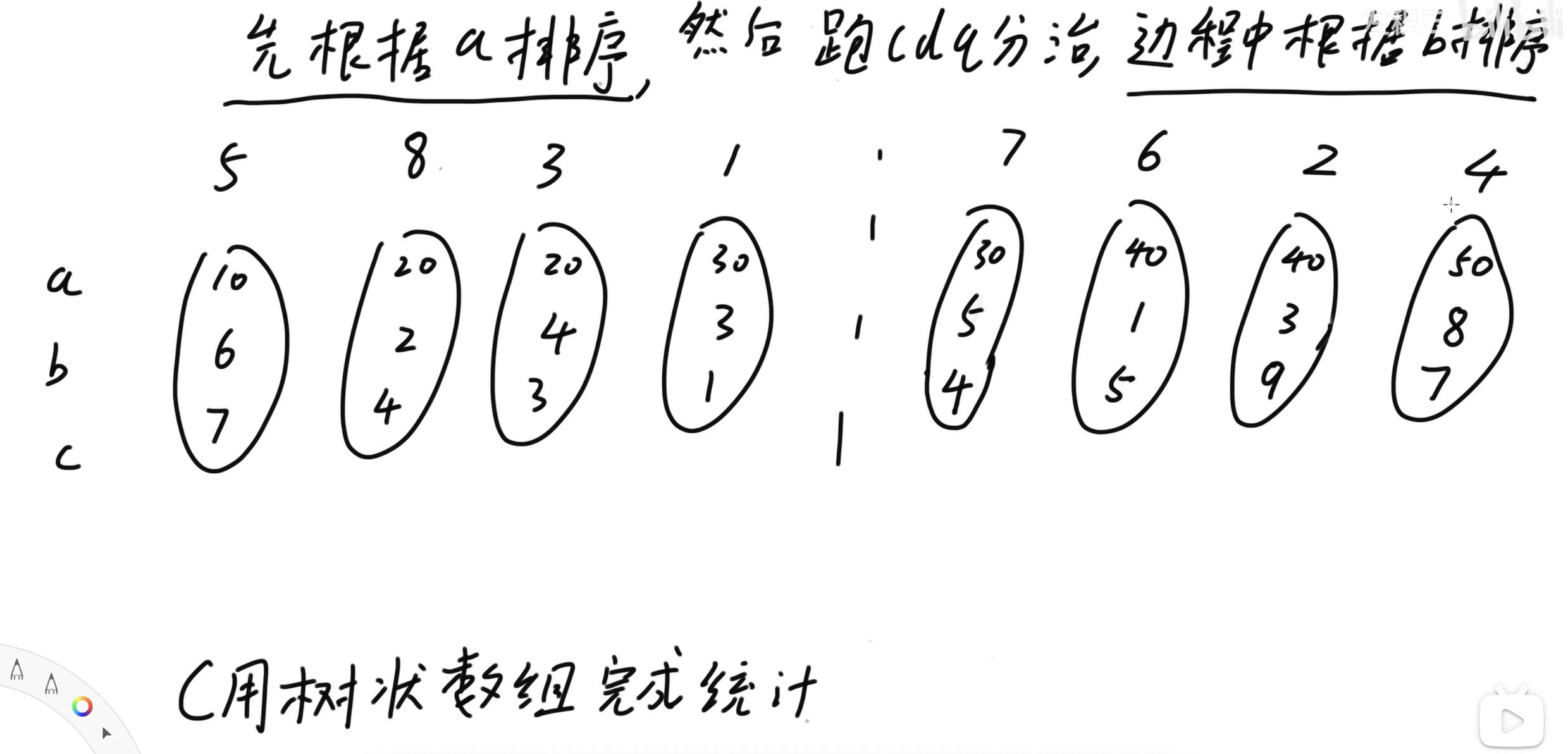
左、右两组根据 \(b\) 升序排序后:
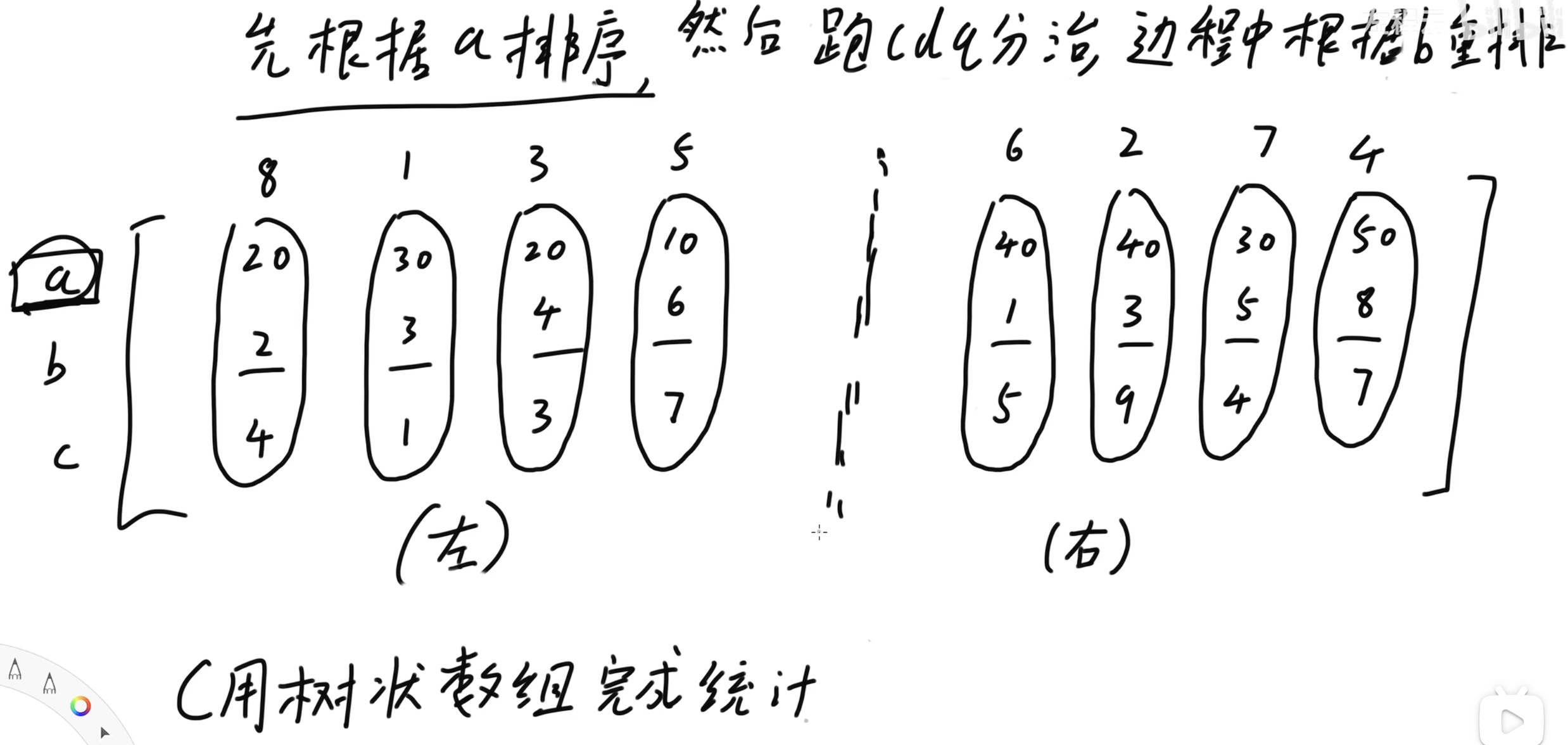
每次统计跨子区间答案时,左右两个子区间均如上述形式。
考虑如何计算跨子区间的答案。
我们发现:左子区间 \(a\) 的最大值一定 \(\leq\) 右子区间 \(a\) 的最小值,因此在按照 \(b\) 做归并排序的双指针过程时,就无需再考虑 \(a\) 的影响。
经典归并排序统计贡献时,由于没有 \(c\) 的约束,每次正确归位两侧指针后直接加的是左子区间的指针偏移;而当存在 \(c\) 的约束时,我们还需要考虑到 \(c_{右i} \geq c_{左1\backsim j}\)。我们可以考虑开一个值域树状数组,维护每次指针归位后的 \(c_{左1\backsim j}\),然后只计入 \(\leq c_{右i}\) 的数的个数,相当于树状数组查询前缀和,单次复杂度 \(O(\log n)\)。
复杂度分析:经典归并排序过程相当于对于长度为 \(n\) 的线段树的遍历,而我们知道在线段树中,每个位置只会在 \(\log n\) 个线段树结点上出现,因此线段树所有结点的总长度是 \(O(n\log n)\) 的;归并排序就是相当于将每个线段树结点表示的线段扫一遍,但在 cdq 过程中,每次移动一步指针后还需要一次 \(O(\log n)\) 的树状数组查询,因此总复杂度是 \(O(n\log^{2} n)\)。
对于本题,还需要额外考虑一件事情:对于 \(a,b,c\) 三个值均相等的不同元素,它们之间的偏序关系是模糊不清的。因此在排序时,无法保证谁在谁前面,统计贡献也可能会导致错误,而 \((a, b, c)\) 不同的两个元素之间的偏序关系一定是清晰的,在排序时可以保证唯一正确的相对顺序,进而做到正确统计。因此,我们可以对每个元素 \((a_{i}, b_{i}, c_{i})\),提前加上 \(cnt_{(a_{i}, b_{i}, c_{i})} - 1\) 的贡献,然后将相同的 \((a, b, c)\) 三元组去重,再做 cdq 分治就可以了。
在每次归并排序处理左右子区间时,虽然两侧均已经按照 \(b_{i}\) 升序排好序了,可以直接利用 辅助空间+双指针 的经典归并排序方式对整个区间排序,但由于整体时间复杂度已经是 \(O(n\log^{2} n)\) 了,我们为了写法更简便一些,也可以牺牲一些常数时间,直接对两侧区间用 sort 快排达到同样的效果。这样做有两个优点:
- 省去了辅助空间,优化了空间复杂度
- 写法更简便(主要原因)
看似直接快排多了一个 \(\log\),但牺牲的也仅仅是常数时间,可以忽略不计。
struct Node{
int a, b, c, id;
bool operator == (const Node& y){
return a == y.a && b == y.b && c == y.c;
}
};
bool cmp1(Node x, Node y){
if(x.a == y.a && x.b == y.b) return x.c < y.c;
if(x.a == y.a) return x.b < y.b;
return x.a < y.a;
}
bool cmp2(Node x, Node y){
return x.b < y.b;
}
int n, m;
Node A[100005], AA[100005];
int f[100005], ans[100005];
Fenwick<int> bit(200001);
int mp[100005];
int Cnt[100005];
void cdq(int l, int r){
if(l == r) return;
int mid = l + r >> 1;
cdq(l, mid); cdq(mid + 1, r);
// 此时 [l, mid] 与 [mid + 1, r] 按 b 升序排序
int j = l - 1;
for(int i = mid + 1; i <= r; i ++){
while(j + 1 <= mid && AA[j + 1].b <= AA[i].b){
j ++;
bit.add(AA[j].c, Cnt[AA[j].id]);
}
f[AA[i].id] += bit.querysum(AA[i].c);
}
for(int i = l; i <= j; i ++){
bit.add(AA[i].c, -Cnt[AA[i].id]);
}
sort(AA + l, AA + 1 + r, cmp2); // [l, r]
}
void solve()
{
cin >> n >> m;
for(int i = 1; i <= n; i ++){
cin >> A[i].a >> A[i].b >> A[i].c;
A[i].id = i;
}
sort(A + 1, A + 1 + n, cmp1);
int cnt = 0;
for(int i = 1; i <= n; i ++){
int j = i;
while(j <= n && A[i] == A[j]) j ++;
j --;
for(int k = i; k <= j; k ++){
mp[A[k].id] = A[i].id;
}
f[A[i].id] = j - i;
Cnt[A[i].id] = j - i + 1;
AA[++cnt] = A[i];
i = j;
}
cdq(1, cnt);
for(int i = 1; i <= n; i ++){
ans[f[mp[A[i].id]]] ++;
}
for(int i = 0; i < n; i ++){
cout << ans[i] << "\n";
}
}
P3157
Q:给点长度为 \(n\) 的排列,一共删除 \(m\) 个元素,每次删除某个指定元素,求每一次删除指定元素前,当前序列的逆序对数量。
将初始序列及每一步删除操作均看作是按时序依次发生的事件,如下图所示:
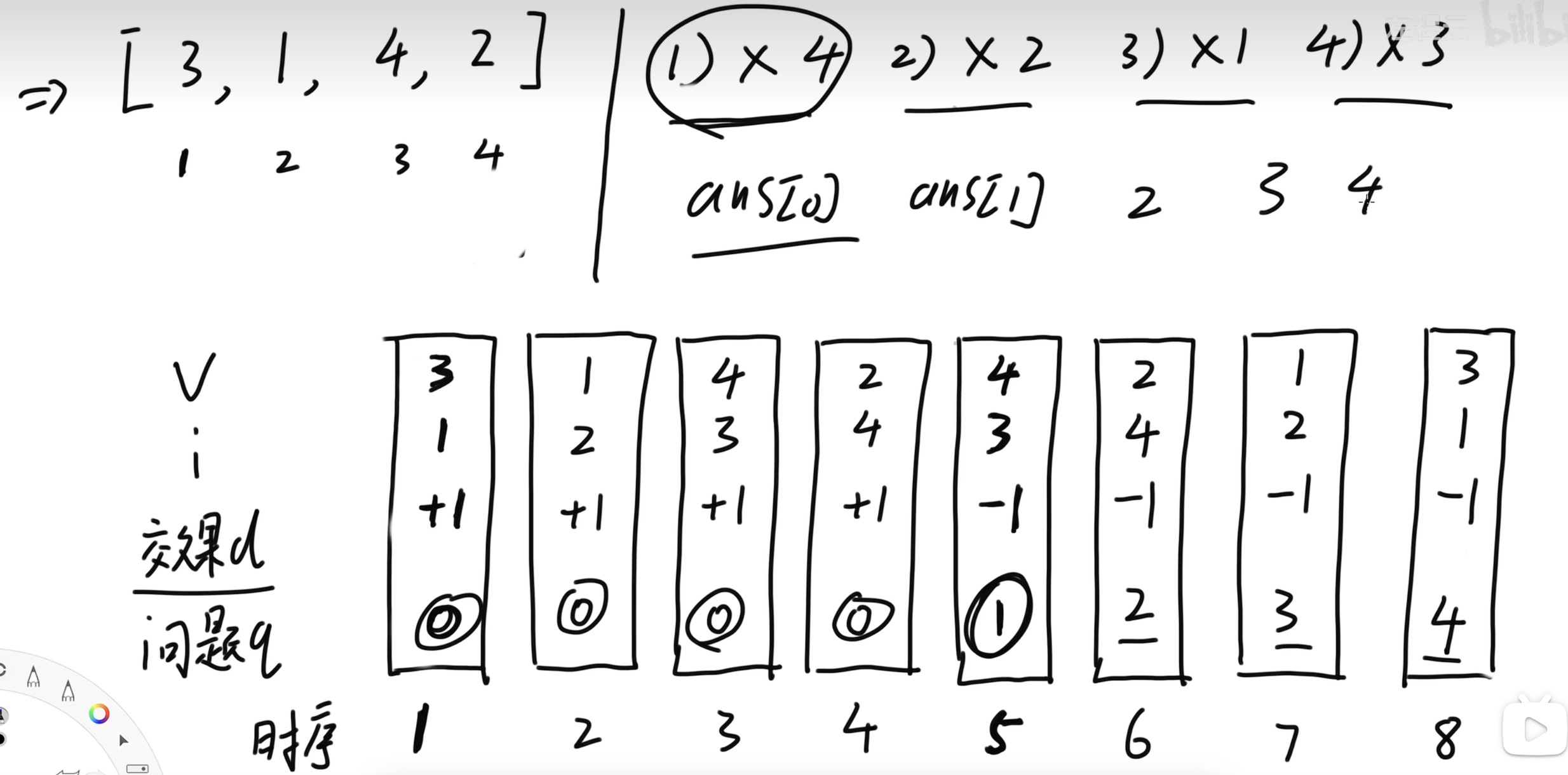
将每个事件按照上图形式组织,每个事件的表示:\(\{\) 时序,元素位置,元素值,添加/删除,事件编号 \(\}\),其中新增事件 \(0\),初始所有元素的添加均发生事件 \(0\)。
考虑对于每个事件,计算其发生所造成的逆序对变化量。那么每一步删除操作后的逆序对数量,就是事件按照时序构成的逆序对变化量的前缀和。
对于每个事件,其实就是在什么时刻,哪个位置上的哪个数添加/消失。而考虑这个事件发生带来的逆序对数量变化,只需要考虑这个事件发生之前,在该位置左侧、比它大、且存在的数/在该位置右侧、比它小、且存在的数 有哪些。
cdq 分治设计
将所有事件先按照时序排序(cdq 分治中的 \(a\));在 cdq 分治过程中将所有事件按照元素下标升序排序(cdq 分治中的 \(b\));树状数组维护 比当前事件中的元素值大/小的元素数量(cdq 分治中的 \(c\))。
对于每个事件发生,需要同时考虑这个事件表示位置的左右两侧引起的变化,因此在 cdq 过程中需要正着、倒着各跑一遍。
经过上述 cdq 分治过程,我们最终就可以得到每个事件发生所带来的逆序对数量变化。具体实现见 code。
P2163
cdq 分治解决二维空间计数问题。
Q:有 \(n\) 个点,第 \(i\) 个点在空间直角坐标系中的位置为 \((x_{i}, y_{i})\)。处理 \(q\) 条查询:
- \(a\space b\space c\space d\):左上角 \((a, b)\),右下角 \((c, d)\) 的区域中点的数量。
\(n, q \leq 5e5\),\(x, y \leq 1e7\)。
根据二维前缀和,显然每个子矩形可以转化成 \(4\) 个同类型的二维前缀查询。于是问题转化为查询右下角为 \((x, y)\)(左上角固定为 \((1, 1)\))的子矩形内点的数量。某个点 \((x', y')\) 满足,当且仅当 \(x' \le x 且 y' \le y\),这是一个二维偏序问题。于是,将点的添加与前缀查询两种操作序列混合在一起,进行 cdq 分治即可(点的添加指的是累计初始点,而前缀查询用于统计答案;维护当前批次贡献时只有添加操作能产生贡献,cdq 分治过程完成后,最终会得到对于每条前缀查询 \((x, y),\) 满足 \(x' \le x 且 y' \le y\) 的、来自添加操作的 \((x', y')\) 的数量)。
需要注意的是,每一条原查询均会拆分成 \(4\) 条前缀查询,加上添加操作,总查询数量实际上是 \(5q\),最大可达 \(2.5 \times 10^{6}\);虽然 cdq 分治的常见复杂度是 \(O(n\log^{2} n)\),但本题实际上是一个二维偏序问题,并不需要在最后一维偏序中使用数据结构维护,因此只需要使用归并排序即可,总复杂度 \(O(n\log n)\)。同时为了保证这个复杂度,每次分治后的子区间排序不能再为了求方便用快排,而要借助额外空间辅助排序,即传统的归并排序。
P4390
上一题的动态版本(不再是先添加后查询,而是添加、查询操作均有时序)。
按照时序、\(x\)、\(y\) 做三维 cdq 分治即可。
P4169
也是按时序,\(x\),\(y\) 三维偏序的 cdq 分治模板题,但这里的 按四种象限进行坐标变换 分别跑 cdq 分治 这个思路挺清奇的,值得学习;同时本题需要用树状数组维护前缀最大值,而不是维护桶。
P5094
Q:给定序列 \(a_{1\backsim n}\),求:
会发现求 \(\max\) 这个东西很烦,考虑将原序列按 \((a_{i}, i)\) 升序排序,每个批次分别按照 \(i\) 升序、降序跑 \(2\) 次 cdq 分治(按 \(i\) 升序对应最大值在右侧的情况,按 \(i\) 降序对应最大值在左侧的情况),总复杂度 \(O(n\log n)\)。
CF1045G
Q:有 \(n\) 个机器人,每个机器人具有三种属性:坐标 \(x_{i}\)、视野 \(y_{i}\)、智商 \(q_{i}\)。第 \(i\) 个机器人能看到的坐标范围是 \([x_{i} - y_{i}, x_{i} + y_{i}]\),统计满足下述两种情况的机器人对数 \((i, j)\):
- 可以相互看到
- 智商差距不超过定值 \(k\)
\(n \le 10^{5},x,y,q \le 10^{9}\)
显然需要将所有机器人按照坐标升序排序并重新编号,并预处理每个机器人能看到的机器人编号区间。
机器人的坐标一定是其视野区间的中点,根据这一点可以发现一个重要性质:若视野小的机器人可以看到视野大的机器人,则视野大的机器人一定也能看到视野小的机器人。 于是将所有机器人按照视野降序排序后,判断两个机器人是否可以互相看到,只需要看右侧机器人能看到左侧机器人即可。
于是按照视野降序排序作为最外层排序,进行 cdq 分治,然后按照智商升序排序进行分治批处理。那么接下来枚举右子区间的机器人 \(j\),计算左子区间中机器人的贡献时,判断是否可贡献的条件:
- \(q_{i} \in [q_{j} - k, q_{j} + k]\)
- \(x_{i} \in [x_{j} - y_{j}, x_{j} + y_{j}]\)
会发现这与传统 cdq 分治类型题特别像,只不过满足前缀变成了满足区间,计数思路还是一样的:由于两侧子区间的智商均升序,故左子区间可用双指针维护满足智商条件的范围;而第二个条件可由上述的离散化处理,用树状数组维护关于编号的桶,在树状数组上查询。
cdq 分治优化 dp

P4093
Q:给定一个长度为 \(n\) 的正整数序列,和 \(m\) 条操作,每条操作的形式如下:
- \(x \space v\):将 \(a_{x}\) 改成 \(v\)
可以不操作,也可以执行至多一次某种操作,要求选出原序列的某个子序列,使得无论怎样选择,形成的序列都是不降的。求满足要求的子序列的最大长度。
先处理所有操作,得到每个位置的 \(lv_{i}\) 和 \(rv_{i}\):操作第 \(i\) 个位置可得到的最小值与最大值。
状态定义
\(dp_{i}\):考虑前 \(i\) 个位置以及对前 \(i\) 个位置的所有操作,且第 \(i\) 个位置必须选择,能满足条件的最长子序列长度。
状态转移
考虑 \(j < i\) 的每个位置 \(j\),看 \(dp_{j}\) 是否能转移到 \(dp_{i}\)。能转移当且仅当:
因此,状态转移可写作:
暴力转移是 \(O(n^{2})\) 的,考虑用 cdq 分治优化。
cdq 分治优化部分
定义 \(cdq(l, r)\):把 \(dp_{l \backsim r}\) 都更新正确。
\(cdq(l, r)\) 的组成结构:
- \(cdq(l, mid)\)
- \(merge(l, mid, r)\)
- \(cdq(mid + 1, r)\)
以上 \(3\) 个部分顺序执行,大致过程为:先将 \(dp_{l \backsim mid}\) 更新正确,然后利用计算完的 \(dp_{l \backsim mid}\) 部分更新 \(dp_{mid + 1 \backsim r}\),最后再将 \(dp_{mid + 1\backsim r}\) 更新正确。
其中核心部分在中间那一步,因为线性 \(dp\) 一定是从左推右,为了能让 \(cdq(mid + 1, r)\) 正确执行,必须要先利用 \(dp_{l \backsim mid}\) 部分更新好 \(dp_{mid + 1\backsim r}\)。
下面是 \(merge(l, mid, r)\) 的实现设计:
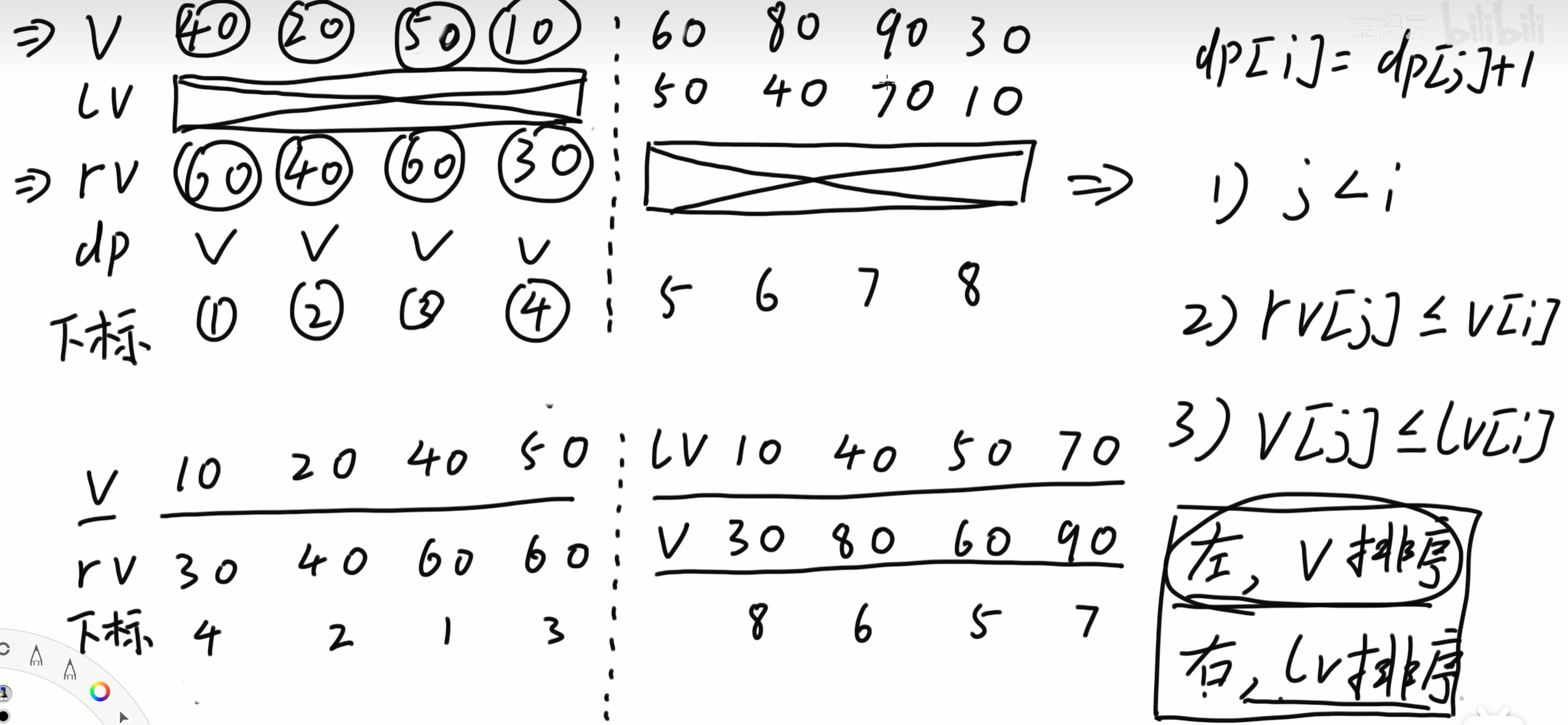
按原序列位置进行最外层排序,左右子区间分别按照 \(v_{i}\)、\(lv_{i}\) 升序排序。按照它们进行双指针,过程中维护好以 \(rv_{i}\) 为下标、值为 \(dp_{i}\) 的前缀最大值树状数组,以加速 \(dp\) 转移。
需要注意的是,在中序 cdq 分治之前,对应子区间可能不再是按最外层排序,必须恢复回来。
总复杂度 \(O(n\log^{2} n)\)。
template<typename T>
struct Fenwick
{
int n;
vector<T> tr;
explicit Fenwick(int x){
init(x);
}
void init(int x){
n = x;
tr.resize(x + 1, -inf);
}
int lowbit(int x){
return x & -x;
}
void update(int x, T k){
for(int i = x; i <= n; i += lowbit(i))
tr[i] = max(tr[i], k);
}
T querymax(int x){
T res = -inf;
for(int i = x; i; i -= lowbit(i))
res = max(res, tr[i]);
return res;
}
void _clear(int x){
for(int i = x; i <= n; i += lowbit(i)){
tr[i] = -inf;
}
}
};
Fenwick<int> bit(1);
int v[100005];
int lv[100005], rv[100005];
int dp[100005];
int p[100005];
bool cmp1(int x, int y){
return v[x] < v[y];
}
bool cmp2(int x, int y){
return lv[x] < lv[y];
}
void cdq(int l, int r){
if(l == r) return;
int mid = l + r >> 1;
sort(p + l, p + 1 + mid); // 注意每次进入函数前,需要将p恢复成按编号升序
cdq(l, mid); // 此时 dp[l~mid] 已经更新正确
// 尝试用 dp[l~mid] 更新 dp[mid+1~r]
sort(p + l, p + 1 + mid, cmp1); // 左子区间按v升排
sort(p + (mid + 1), p + 1 + r, cmp2); // 右子区间按lv升排
int j = l - 1;
for(int i = mid + 1; i <= r; i ++){
while(j + 1 <= mid && v[p[j + 1]] <= lv[p[i]]){
j ++;
bit.update(rv[p[j]], dp[p[j]]);
}
dp[p[i]] = max(dp[p[i]], bit.querymax(v[p[i]]) + 1);
}
for(int k = l; k <= j; k ++){
bit._clear(rv[p[k]]);
}
sort(p + (mid + 1), p + 1 + r); // 注意每次进入函数前,需要将p恢复成按编号升序
cdq(mid + 1, r); // 利用自身更新dp[mid+1~r]
}
void solve()
{
int n, m;
cin >> n >> m;
bit.init(n);
for(int i = 1; i <= n; i ++){
cin >> v[i];
lv[i] = v[i], rv[i] = v[i];
dp[i] = 1;
p[i] = i;
}
for(int i = 1; i <= m; i ++){
int x, y;
cin >> x >> y;
lv[x] = min(lv[x], y);
rv[x] = max(rv[x], y);
}
cdq(1, n);
int ans = 0;
for(int i = 1; i <= n; i ++){
ans = max(ans, dp[i]);
}
cout << ans << "\n";
}
P2487
与上一道题基本类似,但可以在本题中回顾一些易忘 trick:
- 对于一个序列 \(a\),求包含某个固定元素 \(a_{i}\) 的 LIS 方案数:
-
对原序列正着跑一遍 LIS,记录:
- \(len1_{i}\):考虑前 \(i\) 个元素,以 \(a_{i}\) 结尾的最长上升子序列长度
- \(cnt1_{i}\):考虑前 \(i\) 个元素,以 \(a_{i}\) 结尾的最长上升子序列方案数
-
再倒着跑一遍 LDS,记录:
- \(len2_{i}\):考虑后 \(i\) 个元素,以 \(a_{i}\) 开头的最长上升子序列长度
- \(cnt2_{i}\):考虑后 \(i\) 个元素,以 \(a_{i}\) 开头的最长上升子序列方案数
则答案分两种情况:
- \(len1_{i} + len2_{i} - 1 < |LIS|\) \(\rightarrow\) \(0\)
- \(len1_{i} + len2_{i} - 1 = |LIS|\) \(\rightarrow\) \(cnt1_{i} * cnt2_{i}\)
- 树状数组不仅可以维护前缀最大值,也可以维护前缀最大值的数量,只需要多设置一个 \(cnt\) 数组与 \(mx\) 数组联动就可以了。具体实现见 code。
cdq 套 cdq(四维偏序)
P5621
Q:给定大小为 \(n\) 的五元组集合 \((a_{i}, b_{i}, c_{i}, d_{i}, v_{i})\),找到一个最优子集,使得子集内所有元素关于 \(a,b,c,d\) 四个维度存在偏序关系,且 \(v\) 之和最大,求该最大值。
cdq 分治设计
定义两层 cdq 函数 cdq1、cdq2,其中 cdq2 嵌套在 cdq1 内。
cdq1(l, r):
- 大顺序按照 \(a\) 升排
- 记录按照 \(a\) 升排后,关于左右子区间的二分类标记(位于左子区间置 \(0\),位于右子区间置 \(1\))
- 将整个序列按照 \(b\) 升排(这里需要特别留意,\(b\) 值相等时要再按照排序前的位置升排,以保证排序稳定性,避免出错)
此时,整个序列的 \(b\) 是有序的,而刚才的标记是乱序的。我们可以发现只需要做 标记为 \(0 \rightarrow\) 标记为 \(1\) 的转移(保证 \(a\) 的偏序关系);进一步地,对于任何一个标记为 \(1\) 的对象,只需要考虑从其左侧标记为 \(0\) 的对象转移过来(保证 \(b\) 的偏序关系)。这与 cdq 分治解决三维偏序是类似的,唯一区别在于:
- 三维偏序中,需要将左子区间内的 所有 对象转移到右子区间的 所有 对象;
- 四维偏序中,需要将左子区间内 标记为0 的对象转移到右子区间 标记为1 的对象;
因此 cdq2(l, r) 的设计过程就不必再多说了。
四维偏序的过程与三维偏序的区别:最外层偏序关系用一个二分类标记维护,内部的 \(3\) 层偏序关系用经典三维偏序 cdq 分治做,只不过在该过程中需要额外考虑代表最外层偏序关系的标记对转移的影响。
template<typename T>
struct Fenwick
{
int n;
vector<T> tr;
explicit Fenwick(int x){
init(x);
}
void init(int x){
n = x;
tr.resize(x + 1, -INF);
}
int lowbit(int x){
return x & -x;
}
void update(int x, T k){
for (int i = x; i <= n; i += lowbit(i))
tr[i] = max(tr[i], k);
}
T querymax(int x){
T res = -INF;
for (int i = x; i; i -= lowbit(i))
res = max(res, tr[i]);
return res;
}
void _clear(int x){
for(int i = x; i <= n; i += lowbit(i)){
tr[i] = -INF;
}
}
};
Fenwick<ll> bit(1);
int n;
ll dp[50005]; // dp[i]: 考虑前i个怪兽,以第i只怪兽结尾、在四维偏序情况下的最长上升子序列
struct Monster{
int a, b, c, d, id;
ll v;
bool st; // 是否属于原左组
}p[50005], tmp_p[50005], tmp2_p[50005];
bool cmp1(Monster x, Monster y){
if(x.a != y.a) return x.a < y.a;
if(x.b != y.b) return x.b < y.b;
if(x.c != y.c) return x.c < y.c;
if(x.d != y.d) return x.d < y.d;
return x.v > y.v;
}
bool cmp2(Monster x, Monster y){
if(x.b != y.b) return x.b < y.b;
return x.id < y.id; // 保证稳定排序
}
bool cmp3(Monster x, Monster y){
if(x.c != y.c) return x.c < y.c;
return x.id < y.id; // 保证稳定排序
}
void cdq2(int l, int r){ // 大顺序按b升排,分治按c升排,将左子区间标记为0的部分转移到右子区间标记为1的部分
if(l == r) return;
int mid = l + r >> 1;
cdq2(l, mid);
for(int i = l; i <= r; i ++){
tmp2_p[i] = tmp_p[i];
}
sort(tmp2_p + l, tmp2_p + mid + 1, cmp3);
sort(tmp2_p + mid + 1, tmp2_p + r + 1, cmp3);
int j = l - 1;
for(int i = mid + 1; i <= r; i ++){
while(j + 1 <= mid && tmp2_p[j + 1].c <= tmp2_p[i].c){
j ++;
if(tmp2_p[j].st == 0) bit.update(tmp2_p[j].d, dp[tmp2_p[j].id]);
}
if(tmp2_p[i].st == 1){
dp[tmp2_p[i].id] = max(dp[tmp2_p[i].id], bit.querymax(tmp2_p[i].d) + tmp2_p[i].v);
}
}
for(int k = l; k <= j; k ++){
if(tmp2_p[k].st == 0) bit._clear(tmp2_p[k].d);
}
cdq2(mid + 1, r);
}
void cdq1(int l, int r){
if(l == r) return;
int mid = l + r >> 1;
cdq1(l, mid);
for(int i = l; i <= r; i ++){
tmp_p[i] = p[i];
tmp_p[i].st = (i > mid); // 打标记
}
sort(tmp_p + l, tmp_p + r + 1, cmp2); // 改为按照b升排
cdq2(l, r);
cdq1(mid + 1, r);
}
void solve()
{
cin >> n;
vector<int> alls;
for(int i = 1; i <= n; i ++){
cin >> p[i].a >> p[i].b >> p[i].c >> p[i].d >> p[i].v;
alls.pb(p[i].d);
}
// 树状数组需要用到d作下标,因此需要将d离散化
sort(alls.begin(), alls.end());
alls.erase(unique(alls.begin(), alls.end()), alls.end());
bit.init((int)alls.size());
map<int,int> mp;
for(int i = 0; i < alls.size(); i ++){
mp[alls[i]] = i + 1;
}
for(int i = 1; i <= n; i ++){
p[i].d = mp[p[i].d];
}
sort(p + 1, p + 1 + n, cmp1);
// 将a,b,c,d四个属性均相同的对象合并
int m = 1;
for(int i = 2; i <= n; i ++){
if(p[m].a == p[i].a && p[m].b == p[i].b && p[m].c == p[i].c && p[m].d == p[i].d){
if(p[i].v > 0){
p[m].v += p[i].v;
}
}
else{
p[++m] = p[i];
}
}
n = m;
for(int i = 1; i <= n; i ++){
p[i].id = i; // 注意原顺序不重要,要按 a 升排的顺序重新编号
dp[i] = p[i].v;
}
cdq1(1, n);
ll ans = -INF;
for(int i = 1; i <= n; i ++){
ans = max(ans, dp[i]);
}
cout << ans << "\n";
}
P4849
比上一题需要多求出方案数
只需要在树状数组维护前缀最大值过程中额外维护前缀最大值的数量即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号