
6. Disscusion
6.1. Ablation study
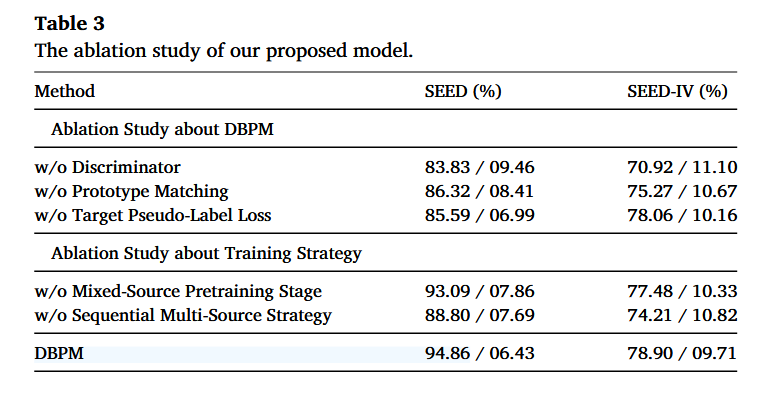
消融实验从两部分展开:1)关于 DBPM 组件的消融(Ablation Study about DBPM)2)关于训练策略的消融(Ablation Study about Training Strategy)
-
1)关于 DBPM 组件的消融(Ablation Study about DBPM)
①:w/o Discriminator(去掉域判别器/对抗对齐),没有域对齐后性能大幅下降,说明域判别器对缓解跨被试差异非常关键
②:w/o Prototype Matching(去掉原型匹配),原型匹配将源域的标签信息以伪标签形式迁移到目标域,如果改为直接使用模型输出作为伪标签,模型性能会下降。
③:w/o Target Pseudo-label Loss(去掉目标域伪标签损失),伪标签监督对 SEED 提升很明显;对 SEED-IV 提升较小(去掉后只小幅下降) -
2)关于训练策略的消融(Ablation Study about Training Strategy)
这部分研究“训练流程设计”带来的增益,
①w/o Mixed-Source Pretraining Stage(去掉混合源域预训练阶段),混合源域预训练能带来稳定增益,但不是最关键的那一个模块。

②w/o Sequential Multi-Source Strategy(去掉顺序多源策略),顺序多源训练对性能贡献很大,去掉后掉得明显

6.2. The effect of noisy labels噪声标签的影响
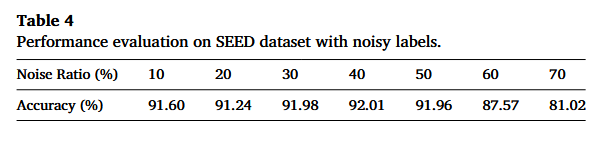
Table 4 内容:在 SEED 数据集上给源域标签加入噪声(Noise Ratio%),然后在干净目标域上评估 accuracy。当噪声比例从 10% 增加到 50% 时,模型在目标域上的准确率仍保持在 91% 以上,表现出很强的鲁棒性。即使在 60% 的标签噪声下,模型仍能达到 87.57% 的准确率;只有当噪声水平达到 70% 时,才观察到明显的性能下降。这些结果清楚地表明,即使存在较高比例的标签噪声,所提出模型仍能保持较强的跨域识别性能。
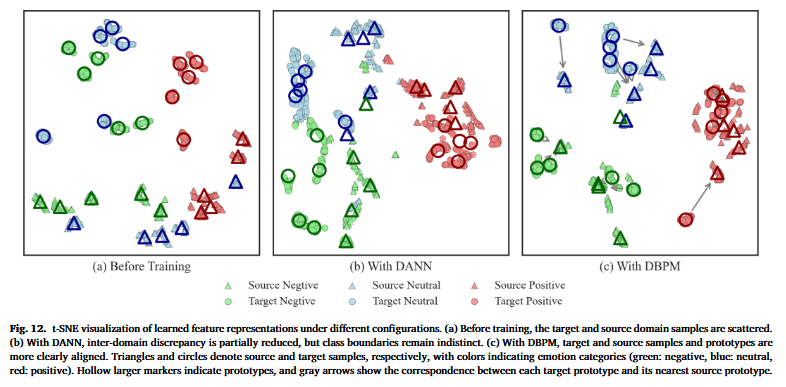
所提出模型的鲁棒性可以由其基于原型的伪标签策略来解释:该策略起到了“去噪”过程的作用。与其依赖单个带噪样本,标签信息通过能够表征子域分布中心趋势的簇级原型进行传播。这种聚合自然会抑制被错误标注的离群点(outliers)的影响,并稳定学习过程。因此,在向目标域迁移知识时,只会强调更可靠的结构信息,从而减轻噪声标签的影响。如图 12(c) 所示,即使源域中存在被标为离群类别的样本,目标域特征仍然保持清晰可分,从而进一步证明该模型在跨域迁移中的鲁棒性。
Fig12内容:
-
三个子图,(a) Before Training、(b) With DANN、(c) With DBPM;
-
形状含义:三角形 = 源域样本;圆形 = 目标域样本
-
颜色含义:绿=negative,蓝=neutral,红=positive
-
空心大标记:原型(prototype)
-
灰色箭头:目标原型与最近源原型的对应关系(prototype matching)
![image]()
-
(a) Before Training(训练前)
表现为源域和目标域点云分散、混杂,同一颜色(同一类)在不同位置出现,说明类内不紧凑,源/目标分布差异大,没做对齐/没学到判别特征的典型状态。 -
(b) With DANN(仅用对抗域适应)
可以看到某种程度上源/目标靠近了(域间差异部分减小),但仍存在明显问题:类别边界不清、不同颜色之间仍有交叠/拉扯;DANN 更偏对齐整体分布,但对“按类别分开”的结构帮助有限,尤其在有噪声标签时更容易出现类边界模糊。 -
(c) With DBPM(DBPM)
![image]()

6.3. The effect of hyperparameter settings文字内容翻译
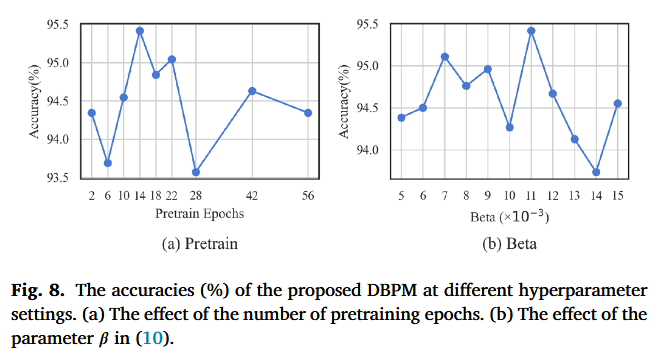
(a)我们还研究了所提出 DBPM 中超参数设置的影响。我们进行了实验来考察 Algorithm 1 中提到的 预训练轮数(pretraining epochs) 的影响。如图 8(a) 所示,当预训练轮数为 14 时能获得最佳性能。这是一个合理的结果,因为 SEED 数据集包含 14 个源域(14 个源被试),而 14 轮预训练能够保证所有源域数据都被充分遍历。该过程有助于实现源域与目标域边缘分布(marginal distribution)的初步对齐。
为进一步探索,我们又将预训练轮数扩展到 28、42、56 并做了额外实验设置。然而,相比 14 轮,准确率更低,这表明过多预训练可能导致过拟合,并在后续训练中削弱对目标域的原型匹配能力。
(b)β 是 DBPM 训练目标函数里的一个权重超参数,用来控制目标域伪标签损失在总损失中占多大比例
β 太小:目标域伪标签这条监督信号太弱,模型主要被源域标签驱动,目标域“按类别对齐/子域一致性”不够,迁移效果差。
β 太大:目标域伪标签损失占主导,→ 伪标签本身可能有噪声,会把模型带偏;同时会削弱源域真实标签的作用,导致标签传播不稳。
β 在 0.011(即 11×10^-3)附近最好(约 95.4%),β 太小(如 0.005~0.006)或太大(如 0.014)都会下降
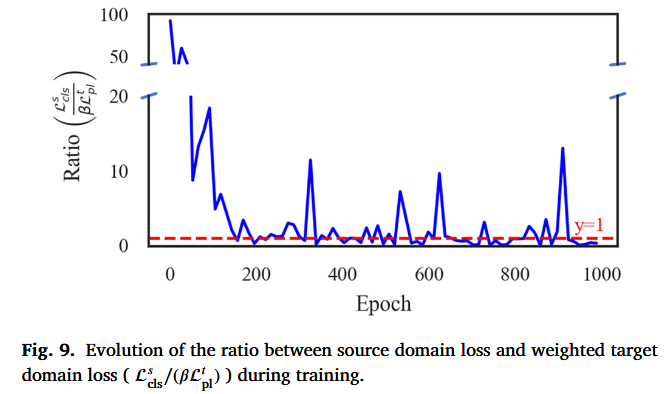
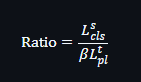
其中\(L_{\mathrm{cls}}\)是源域分类损失,用源域的真实标签算的监督损失(一般是交叉熵)。它反映模型在源域上“被真标签约束得多强”
\(\beta L^t_{pl}\)是目标域(target)伪标签损失,用 DBPM 生成的伪标签(通过聚类+原型匹配得到)对目标样本做的分类损失。它反映模型在目标域上“被伪标签约束得多强”。
\(\beta\)目标域伪标签损失的权重,因为\(L_{\mathrm{cls}}\)和\(\beta L^t_{pl}\)数值量级可能不同,直接比较不公平,所以把目标项乘上\(\beta\),来表示它在总损失里真正的“有效权重”。
当Ratio ≈ 1时,两者在同一量级,对梯度贡献相对平衡(注意这只是损失数值层面的平衡,不等于梯度完全相等,但通常是一个有用的近似信号)
6.4. Stability analysis稳定性分析的内容感觉不用再写了,PPT里面讲不完
6.5. Pseudo-labeling analysis伪标签分析
原文翻译:为了进一步分析所提出模型的有效性,我们评估了由“原型匹配(Prototype Matching)模块”生成的伪标签质量。具体来说,我们比较了第 3.2 节中介绍的三种具有代表性的伪标签策略:(1) 按情绪类别(Emotion-wise):直接把一个在源域训练好的模型预测结果当作伪标签;(2) 按样本(Sample-wise):在特征空间中,为每个目标样本分配与其最相似的源样本的标签;以及 (3) 按簇(Cluster-wise):我们提出的策略,通过聚类得到的原型表示来传播标签。评估在 SEED 数据集的第 1 个 session 上进行,因为该设置为伪标签质量分析提供了一个具有代表性且可控的基准。
表 6 同时报告了最终模型准确率以及伪标签准确率。正如预期的那样,emotion-wise 伪标签会得到相同的模型准确率与伪标签准确率,因为它直接复用了模型预测。相比之下,sample-wise 伪标签的伪标签准确率显著下降,主要原因是决策边界附近的不稳定性,这凸显了它对噪声的敏感性。相较而言,cluster-wise 策略的伪标签准确率达到 95.37%,表明原型匹配能够有效缓解标签噪声,并促进源域与目标域之间的条件分布(conditional distribution)对齐。这些高质量伪标签也直接带来了更优的最终模型准确率 95.42%,从而验证了我们的方法在提升跨被试泛化方面的有效性。
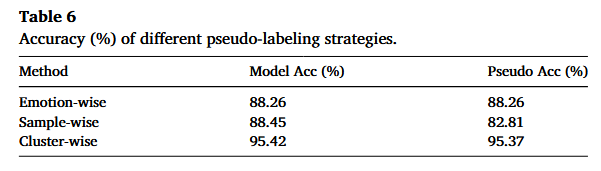
表 6 给了三种伪标签策略的两项指标:Model Acc (%):最终模型在目标域的准确率(或该实验设置下的准确率);Pseudo Acc (%):伪标签本身的准确率(用目标域真标签去“事后对比”计算)
为什么 Emotion-wise 的两个数完全一样?
因为 emotion-wise 的定义就是“把模型预测当伪标签”,因此伪标签对目标域真值的准确率,本质就是“这个模型在目标域上的准确率”,两者必然相同。这一行更像是一个参照基线,告诉你“直接用当前模型输出当伪标签,质量就只有这么多”。
Sample-wise 为什么伪标签准确率更低(82.81)?
Sample-wise 是“给每个目标样本找最近的源样本,用它的标签,它的问题在于最近邻在边界附近非常不稳定,特征空间如果还没对齐好,最近邻关系会“错配”,一旦错配,伪标签会把错误继续传下去。
Cluster-wise(原型匹配)为什么会大幅提升?
Cluster-wise 的关键是“簇级传播”,先聚类形成子域/簇,用簇中心(prototype)代表结构,再做原型匹配把源域的“类信息”迁移给目标簇,这样等于是用“群体统计”抵消单个样本的噪声和偶然性
可能存在的一个问题:Pseudo Acc 是怎么计算的?在什么样的训练时刻计算?
常见有两种口径:在某个阶段生成一次伪标签,和真标签对比;或训练过程中不断更新伪标签,最后统计某一轮。论文这段没有展开细节。如果 pseudo acc 是“最后一轮的伪标签准确率”,那它可能已经受到模型训练的反馈影响;如果是“早期生成的伪标签准确率”,则更能说明原型匹配一开始就很可靠。
6.6. Analysis of prototype matching dependency on base performance
原型匹配对基线性能依赖性的分析
这一段也不打算在PPT讲
6.7. Generalization to new datasets跨数据集实验
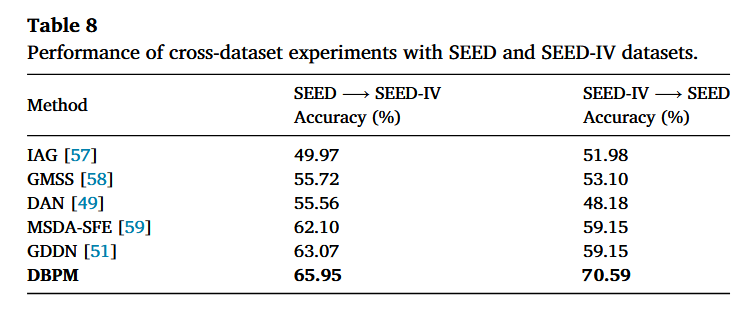
整体翻译:为了全面评估我们提出的 DBPM 方法的泛化能力,我们在 SEED 与 SEED‑IV 数据集之间进行了跨数据集(cross-dataset)的 EEG 情绪识别实验。按照以往工作的标准协议 [57,58],其中一个数据集用于训练,另一个用于测试。具体来说,我们在跨数据集之间对情绪类别进行了映射:对于 SEED,三类情绪为 positive / neutral / negative;对于 SEED‑IV,将 happy 映射为 positive,将 neutral 映射为 neutral,并将 fear 与 sad 合并映射为 negative,从而与 SEED 的三分类标签对应。
由于我们的方法采用“一对一原型匹配”,目标数据集中的每个被试都被视为一个独立的目标域。最终的跨数据集准确率计算为所有目标被试准确率的平均值。表 8 给出了这些实验结果。我们的 DBPM 方法取得了最高性能:在 SEED→SEED‑IV 上达到 65.95%,在 SEED‑IV→SEED 上达到 70.59%,显著优于 IAG [57]、GMSS [58]、DAN [49]、MSDA‑SFE [59] 以及 GDDN [51] 等现有方法。
有趣的是,SEED‑IV→SEED 的准确率高于 SEED→SEED‑IV。我们推测这主要是因为 SEED‑IV 包含更多样的电影刺激材料,使得 SEED‑IV 在进行原型匹配时能够受益于更丰富的分布。因此,模型可以从 SEED‑IV 构建出更可靠的原型,从而在预测 SEED 的情绪时获得更好的迁移性能。上述结果表明,DBPM 能够在情绪分布与刺激材料不同的数据集之间实现有效泛化,凸显了基于原型匹配在跨被试 EEG 情绪识别中的鲁棒性。
6.8. Feature representation特征表示 跟之前分析图12是一样的
7.Conclusion


 浙公网安备 33010602011771号
浙公网安备 33010602011771号