

2. Related work
2.1. EEG-based emotion recognition with transfer learning methods
前人方法中的缺陷:为了解决情绪识别中的个体差异问题,研究者常采用迁移学习方法来最小化不同个体所提取特征分布之间的差异,从而提升基于 EEG 的情绪识别模型的稳定性与泛化能力。尽管上述方法取得了进展,但仍存在一个关键局限:现有迁移学习方法主要关注全局层面或情绪类别层面的对齐,往往忽略了同一个体在不同时间受到情绪刺激时 EEG 信号中存在的细微个体内差异。这些细粒度的子域差异可能会显著影响模型性能,但在以往研究中很少被处理。相比之下,论文的方法显式地建模并对齐这些个体内子域,捕捉此前被忽略的分布变化,从而实现更精确的跨被试泛化。
不是做情绪分类吗,为什么要对齐,怎么理解这个对齐?
对齐(alignment)是迁移学习/域适配(domain adaptation)里非常核心的概念,它回答的是:不同被试(源域 vs 目标域)的 EEG 分布不一样,直接用源域训练的分类器在目标域上会失效;所以要先让两边在“特征空间”里变得更像(对齐),再做分类才准。
虽然最终目标确实是“情绪识别分类”,但在跨被试场景里通常需要多做一步:先减少分布差异,再分类。
1) 为什么需要“对齐”?
跨被试时,EEG 的差异很大(电极阻抗、头型、个体神经反应、状态变化等)。这导致:源域训练出来的特征/决策边界,在目标域样本不再适用。可以简单理解为:同一种情绪在不同人身上对应的 EEG 特征“位置”不一样。所以对齐就是要让模型学到一种表示,使得:同一情绪在不同被试的特征分布尽量接近。不同情绪仍然能分开
2) “对齐”到底对齐的是什么?
不是对齐原始 EEG 波形,而是对齐模型提取后的特征分布。
3) 论文里提到的几种“对齐”分别什么意思?
(1) 全局对齐(global alignment)
让“整个源域”和“整个目标域”的特征分布接近(不管类别)
比如匹配总体均值/整体距离、对抗训练(DANN)等。
问题:EEG 情绪分类是多类,光全局像了不代表分类正确,可能把不同情绪混到一起。
(2) 类别/条件对齐(emotion-level / conditional alignment)
让“同一情绪类别”的源域特征和目标域特征接近:
源域“positive”的特征要靠近目标域“positive”的特征
源域“neutral”靠近目标域“neutral” 这比全局更贴近分类目标。
难点:目标域没标签,怎么知道哪个是 positive/neutral?所以需要伪标签、原型、图传播等机制。
(3) 子域对齐(subdomain alignment,本文强调的)
作者说传统方法忽略了“同一个人内部还有多个子域”。他们想对齐的是更细粒度的结构,例如:源域某个“子状态簇”的原型 ↔ 目标域对应“子状态簇”的原型,这样能避免“粗粒度对齐”把不该对齐的东西硬对齐,提升稳定性
4) 对齐和分类是什么关系?
对齐:让源/目标在特征空间“说同一种语言”(减少 domain shift)
分类:在这个共同语言空间里,用源域标签学一个能泛化到目标域的分类器
很多方法训练时就是同时做两件事:
- 分类损失(用源域真标签)
- 对齐损失(让源/目标分布接近,可能用伪标签/原型/对抗等)
5) 用一个直观比喻
你要训练一个“看脸判断情绪”的分类器:源域是欧美人表情数据,目标域是亚洲人表情数据,最终任务还是“分类情绪”,但因为两群人的“特征分布”不同,你需要先把特征表示学成“对两群人都一致”的表示(对齐),分类器才不会偏。
“子状态簇(subdomain cluster)”是什么
同一个被试(同一个域)内部的 EEG 样本,在特征空间里自然聚成的一个小团块/簇;这个簇代表该被试在某种隐含状态下产生的一类分布(子域)。因为即便是同一个人、同一种实验任务,EEG 也会随时间/状态变化而变,导致特征分布分裂成多团。跟情绪类别不太一样,一个子状态簇里可能以某个情绪为主(比如 70% positive),但也可能混有别的情绪;同一种情绪也可能分布在多个子状态簇中(比如 positive 分成两团)。
用一句话来类比:把“一个被试的数据”想成同一个城市一天的天气记录:虽然都在同一个城市,但可能自然分成“晴天簇、阴天簇、雨天簇”。这些“天气簇”就是子状态簇;它们不是你要预测的“季节标签”,但会影响你建模和泛化。
2.2. EEG-based emotion recognition with prototype learning methods
原型学习(prototype learning)通过在特征空间中构建一组代表性样本(称为原型,prototypes)来表示不同的数据类别。这些原型能够概括数据的整体分布,使得在样本数量有限的情况下也能进行高效的分类与决策,并且在处理噪声和类内变化方面表现出很强的鲁棒性 [30,31]。近年来,研究者开始探索将原型学习融入基于 EEG 的情绪识别,以提升模型性能与适应性。
然而,现有基于原型的方法主要在全局粒度或情绪类别粒度上工作,不能充分捕捉个体内部的细粒度分布。相比之下,论文的方法在每个个体内部引入基于密度的子域原型,从而能够在源域与目标域的子域之间实现精确的伪标签传播。这种细粒度机制提升了模型对噪声与个体内部变化的鲁棒性,是区别于以往原型方法的核心点。
3. Intra-individual distribution
已有研究表明,在执行相同任务时,心理和生理因素(如压力、焦虑以及注意力需求等)可能会显著影响个体的行为和神经生理反应,从而导致 EEG 信号发生变化 [18–20]。如图 1 所示,即使是同一个被试,在相同情绪状态下,其 EEG 信号也常常呈现出不同的聚类模式。这样的个体内部变异性(intra-individual variability)增加了情绪识别的复杂性。
然而,目前大多数研究主要关注个体之间的差异(inter-individual differences),而忽略了对个体内部数据分布的捕捉与利用。这些局部的分布(local distributions)可能包含重要的情绪信息,值得进一步研究。因此,一个自然的问题是:如何捕捉这种个体内部的分布差异?

图片展示的是在正向情绪(positive)条件下的特征t-SNE可视化,(a) 来自 SEED 的 Subject 1;(b) 来自 SEED-IV 的 Subject 5。每种颜色代表一个不同的 trial(一次刺激/片段)。
t-SNE 是一种把高维特征投影到 2D 的可视化方法:点与点越近,代表它们在原始特征空间越相似(大致趋势),不同颜色代表不同 trial。这张图要表达的是虽然这些点都属于同一种情绪:positive,而且都来自同一个被试,不同 trial 的点云在 2D 空间里呈现为彼此分离的多团/多条结构,即:同一被试、同一情绪,并不是一个“单一分布”,而是多个“子分布/子簇”。因此这就是作者强调的 intra-individual subdomains(个体内部子域),同一个人内部还存在细粒度的分布差异,而且这种差异在不同 trial 之间很明显。
图1是在为DBPM的动机做证据:传统方法如果只按情绪类别建一个 positive 原型,可能会把这些彼此差异很大的 trial 混在一起,原型会变得很粗糙。因此DBPM是想把这些 trial 形成的不同“团块/子域”分开(密度聚类),每个团块各自形成一个“子域原型”,再跨被试做子域原型匹配与伪标签传播。其中密度聚类的目的就是把这些 trial 在特征空间里形成的“团块/子域”自动分出来。
由图1还可以知道,如果如果每个 trial 都对应一种固定的分布/状态,那么 Trial 21 的数据应该只和 Trial 21 的数据聚在一起,Trial 23 也应该只和 Trial 23 聚在一起。但是在SEED‑IV 里 Trial 21 和 Trial 23 的数据在特征空间里非常相似,所以聚类算法把它们分到同一个簇。因此说明了聚类反映的是特征相似性/真实分布结构,而不是试次编号;子域(subdomain)更像是隐藏的生理/心理状态模式,可能跨越多个 trial 出现;所以仅靠 trial 标签来划分子域不够准确,需要用聚类去自动发现。两个不同 trial 可能处在同一种隐含状态,所以会被聚成同一簇。

图2的作用是对比不同聚类算法在 EEG 特征空间中“恢复子域结构(subdomain structure)”的能力。作者用 t‑SNE 把特征投到 2D 上可视化,并用 NMI(Normalized Mutual Information) 来量化“聚类结果”和“参考的 Trial 划分”有多一致
作者通过这种对比证明他们的核心假设是成立的,即同一被试内部确实存在“子域/簇结构”,而且这种结构是可以用无监督聚类从特征里挖出来的。同也为DBPM 后续流程选择一个合适的“子域发现工具”:
DBPM 需要先把数据划成若干子域簇,再构建子域原型、做原型匹配和伪标签传播。所以需要选一个在EEG特征上更能稳定恢复这些簇结构的聚类方法(实验显示 DBSCAN 更好)。
基于上述观察,作者将 DBSCAN 所识别出的子域结构称为基于密度的子域(density-based subdomains),因为它能够反映 EEG 信号在不同上下文条件下所呈现的内在局部聚类特征。这些子域为后续的建模与分析奠定了基础,并最终使模型能够更稳健地处理个体内部的变异性(intra-individual variability)。
3.1. Stability of intra-individual distributions个体内部分布的稳定性
DANN 和 DBSCAN的关系:先用 DANN 抽特征/做粗对齐,再用 DBSCAN 在特征空间里做子域聚类

为探究个体内部数据分布的特征,在SEED数据集上开展实验,论文中选取了单个被试的EEG信号进行分析,并使用DANN网络提取样本特征,训练DANN是为了学到一个特征空间,让源域/目标域在整体上更对齐,同时保留情绪可分性。
分析(a)t-SNE:训练DANN(抽取特征,粗对齐)后,个体内部的细粒度差异任然存在
图中
- 颜色:情绪类别(Negative / Neutral / Positive)
*形状:三角形=源域样本(source),圆形=目标域样本(target)
*每个点:一个 EEG 样本的特征(由 DANN 提取),t‑SNE 只是为了可视化
从图中可以知道:
- 按情绪类别的大分离是存在的:不同颜色大体分成了三片区域(绿色、黄色、红色),说明 DANN 训练后,模型确实学到了一定的可分类特征。
*同一情绪内部不是一团,而是许多条带/小团块:比如 Positive(红色)区域里不是一个圆团,而是由很多条弯曲的小段落/条带组成;Negative、Neutral 同理,这就是作者强调的intra‑individual subdomains(个体内部子域),即使情绪相同,特征分布仍存在局部结构差异。
*源域与目标域在同一情绪区域内仍有细微偏移:在同一颜色区域里,三角与圆并非完全重合,有些条带可能更偏向三角或更偏向圆。这说明:即便做了域对齐(DANN),仍会残留更细粒度的差异,因此作者后面要用子域级方法去进一步处理的就是这部分。
分析(b)轮廓系数 Silhouette:两种子域划分方式的变化
图中的两种子域分别为:
- Emotion‑wise:按情绪标签分子域(Negative/Neutral/Positive 三个组)
- Cluster‑wise:按无监督聚类分子域(对应 density‑based subdomains)
纵轴为Silhouette Score(轮廓系数),值越高,表示簇内更紧、簇间更分离,也就是聚类结构更清晰。
Before Train(训练前):Cluster‑wise 的轮廓系数明显更高,因为在训练前,数据的天然结构更像许多局部簇,而不是简单的三类情绪,而在训练之前,如果只按照情绪分组,会把很多内部结构混在一起,所以情绪分组的聚类质量较差。
After Train(训练后):Emotion‑wise 的轮廓系数显著上升,而Cluster‑wise 下降。这是因为训练过程主要用情绪标签监督(分类损失/情绪约束),所以模型会把特征学得更“按类别可分”,自然让 emotion‑wise 更像清晰的簇。但 cluster‑wise 下降并不意味着“子域消失”,而是说明:模型的训练目标没有在子域层面维持这些簇的可分性,导致局部簇之间边界变模糊一些(separability 下降)。
分析(c) 三种伪标签策略:准确率 vs(欧氏)相似度的对比
横轴:emotion‑wise、sample‑wise、cluster‑wise
两条曲线:蓝线:Pseudo Label Accuracy(伪标签准确率),值越高越好
红线:Euclidean Similarity(欧氏相似度),可以理解为源/目标在特征空间更接近/更相似的程度,数值越高代表越相似
伪标签:用模型预测的结果来模拟目标域中的真实情绪标签,给这些样本打上‘伪’标签。
为什么论文需要用伪标签:论文特别关心子域(subdomain)对情绪识别的影响,作者发现目标域样本在高维特征空间中,并不是简单地按情绪标签分布,而是存在复杂的局部子域。直接对每个样本逐个赋予伪标签会导致更高的噪声和误差,而基于子域的伪标签传播可以降低伪标签传播的错误率, DBPM(Density-Based Prototypical Matching)依赖密度聚类得到的子域作为原型,再通过伪标签传播优化目标域内的分类模型性能。
3.2. 个体内部分布的可迁移性(Transferability of intra-individual distribution)
问题:源域和目标域在边缘分布和条件分布上都存在差异
引出:UDA(Unsupervised Domain Adaptation,无监督领域自适应),用于在源域和目标域之间存在分布差异时,实现模型的迁移学习
解决边缘分布:为了解决边缘分布不一致的问题,已有研究大多通过对抗训练(例如领域判别方法)来减少源域和目标域在特征空间中的边缘分布差异,从而提高模型的跨域迁移能力。
解决条件分布:对于条件分布对齐,由于目标域没有标签,目前主流方法通常依赖于伪标签策略来近似目标域样本的条件分布 \(P_t(Y|X)\).目前的伪标签方法主要分为两大类:
-
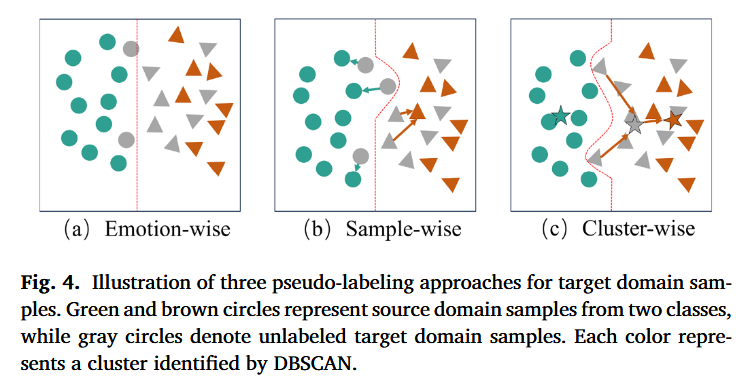
按情绪分类的伪标签(emotion-wise pseudo-labeling):这种方法使用在源域上预训练的模型的预测结果作为目标域样本的伪标签(如图 4(a) 所示)
-
逐样本伪标签(sample-wise pseudo-labeling):这种方法根据特征相似性,为每个目标域样本分配最相似的源域样本的标签作为其伪标签(如图 4(b) 所示)
传统方法的局限性:然而,由于 EEG 数据在跨被试学习中存在显著的个体差异和非平稳性,传统的伪标签方法对噪声高度敏感,从而限制了模型的泛化性能。一种更具前景的方法是将伪标签与基于子域的簇级结构(cluster-wise subdomain structure)相结合,其中通过原型表示(定义为每个簇的特征均值向量)进行标签传播(如图 4(c) 所示)
对图4的详细分析:
①Emotion-wise:灰色圆点为未标注的目标域样本,绿色圆形和棕色三角形为带标签的源域样本(两个情绪类别,分别是绿色和棕色),红色虚线为源域样本生成的情绪分类边界。
伪标签赋予的方法规则:直接让目标域未标注样本位于哪个情绪类别的区域,就打上哪个情绪类别的标签,比如落在红线左侧的灰色样本统一标记为 绿色圆圈类别,右侧样本统一标记为 棕色三角形类别
劣势:易错分靠近错误情绪区域边界的样本
②Sample-wise:
伪标签赋予的方法规则:逐样本伪标签策略,为每个目标域样本(灰色圆点)寻找特征上最相似的源域样本,通过计算目标域样本与源域样本之间的特征相似性(例如欧氏距离),将与目标域样本特征最接近的源域样本的标签赋予目标域样本。
劣势:容易受特定样本噪声的影响,比如由于特征上的轻微扰动,有的目标域样本可能偏离正确的最近邻源域样本,或类似图中跨情绪边界的灰点,可能因为最近邻计算出错而给出错误伪标签
③Cluster-wise:
伪标签赋予的方法规则:先通过 DBSCAN(基于密度的聚类算法)对目标域的未标注样本(灰色圆点)划分为多种簇(每个簇用不同颜色表示),得到图中灰色的五角星,然后使用每个簇的中心(即其聚类“原型”,通常是簇内样本特征的均值)作为簇的代表,通过其与源域数据的关系推断伪标签。这个伪标签随后应用于整个簇中的样本。(简单来说就是去判断灰色五角星跟哪个彩色的五角星距离最近,就判定为什么标签)
因此整体来说:结果表明,按情绪划分的标注(emotion-wise labeling)具有更高的准确率,但相似度较低。相较之下,逐样本标注(sample-wise labeling)具有更高的相似度,但准确率更低,因为它可能会将靠近决策边界的样本误分类。簇级标注(cluster-wise labeling)取得了整体最佳的准确率,因为它利用了目标域的个体内部数据分布,从而对齐源域与目标域之间的条件分布。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号