


内容补充:在上一节的Multi-Head Attention模块中,完成了自注意力值的计算:
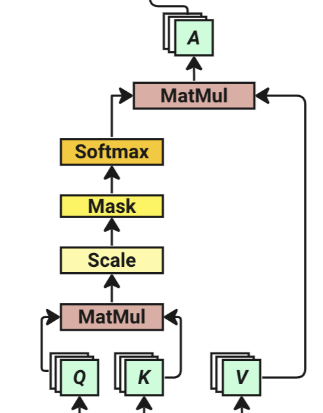
而该步骤总结为:
1.计算查询矩阵\(Q\)与键矩阵\(K\)的点积\(Q \cdot K^T\),求得相似值,称为分数;
2.将\(Q \cdot K^T\)除以键向量维度的平方根\(\sqrt{d_k}\);
3.用softmax函数对分数进行归一化处理,得到分数矩阵\(\text{softmax}\left(Q \cdot K^T / \sqrt{d_k}\right)\);
4.通过将分数矩阵与值矩阵\(V\)相乘,计算出注意力矩阵\(Z\),即图中的\(A\).
因此单个注意力矩阵\(Z_1\)可以表示为:
当计算第二个注意力矩阵\(Z_2\),需要创建另外一组矩阵:查询矩阵\(Q_2\)、键矩阵\(K_2\)和值矩阵\(V_2\),并引入了三个新的权重矩阵,即\(W_2^Q\)、\(W_2^K\)、\(W_2^V\)。用矩阵\(X\)分别乘以矩阵\(W_2^Q\)、\(W_2^K\)、\(W_2^V\)。就可以依次得出对应的查询矩阵、键矩阵和值矩阵。
注意力矩阵\(Z_2\)可按以下公式计算得出:
同理,可以计算出head个注意力矩阵,假设head=8,即\(Z_1\)到\(Z_8\),那么可以直接将所有的注意力头(注意力矩阵)串联起来,并将结果乘以一个新的权重矩阵\(W_0\),从而得出最终的注意力矩阵,公式如下:
基于上一节的内容,完成除Multi-Head Attention以外的transformer架构内容

首先是Feed Forward块的实现,Feed Forward主要实现了前馈神经网络ffn层,由于在Transformer中的自注意力机制虽然实现了捕捉文本之间关系,但是在本质上还是一种线性的变换,即通过矩阵乘法计算注意力和加权求和。而前馈神经网络包含了激活函数ReLU,能够引入非线性变换,通过这种非线性变换,模型可以学习到更复杂的函数关系,增加数据的拟合能力。ffn将输入的特征向量从维度d_model变换到更高维度(通常是d_model*4),经过ReLU激活函数之后再变回d_model维度,ffn通过也会使用Dropout层,以一定的概率将一些神经元的输出设置为0,防止过拟合。
代码示例如下:
class FeedForwardNetwork(nn.Module):
def __init__(self):
super().__init__()
self.ffn = nn.Sequential(
nn.Linear(d_model, d_model * 4),
nn.ReLU(),
nn.Linear(d_model * 4, d_model),
nn.Dropout(dropout)
)
def forward(self, x):
return self.ffn(x)
因此在深度神经网络训练过程中,随着网络层数的增加,参数的更新可能会导致梯度消失或梯度爆炸问题,因此在Feed Forward和Masked Multi-Head Attention之间加入层归一化,将输入数据的分布调整到均值为0、方差为1的标准正态分布附近,使得各层的输入分布相对稳定。
在完成以上内容之后,则是transformer层的堆叠,在图中表示为左侧灰色区域的堆叠,由层归一化、多头注意力、前馈神经网络等组件构成,每一层的Transformer Block都会让输入进行一次完整的变换,包括特征提取、非线性变换等操作,通过多层堆叠,可以让模型学习到更复杂、高级的语义表示。
代码示例如下:
class TransformerBlock(nn.Module):
def __init__(self):
super().__init__()
self.ln1 = nn.LayerNorm(d_model)
self.ln2 = nn.LayerNorm(d_model)
# 实例化多头注意力(Multi-Head Attention)模块
self.mha = MultiHeadAttention()
# 实例化前馈神经网络(Feed Forward Network)模块
self.ffn = FeedForwardNetwork()
def forward(self, x):
# 第一个子层:层归一化后经过多头注意力,再与原始输入x进行残差连接
x = x + self.mha(self.ln1(x))
# 第二个子层:层归一化后经过前馈神经网络,再与上一步的结果进行残差连接
x = x + self.ffn(self.ln2(x))
# 返回经过Transformer块处理后的特征
return x
可以观察到TransformerBlock类forward函数中的归一化位置与前面的图片归一化位置并不相同,因为原始论文使用的是"后归一化",而代码中使用的是"预归一化"(这是后来被广泛采用的方案,训练更加稳定)。
最后是将前面定义的类都融合起来,形成最后的model类,完成从输入序列到生成序列的完整过程:
class Model(nn.Module):
def __init__(self, max_token_value=100080): # 默认词汇表大小为tiktoken的cl100k
# 调用父类初始化方法
super().__init__()
# 定义token嵌入表:将token索引映射为d_model维度的向量
self.token_embedding_lookup_table = nn.Embedding(max_token_value, d_model)
# 定义Transformer块序列:
# 1. 堆叠num_blocks个TransformerBlock
# 2. 最后添加一个层归一化层
self.transformer_blocks = nn.Sequential(*(
[TransformerBlock() for _ in range(num_blocks)] +
[nn.LayerNorm(d_model)]
))
# 定义输出线性层:将d_model维度映射回词汇表大小(用于预测下一个token)
self.model_out_linear_layer = nn.Linear(d_model, max_token_value)
# 定义前向传播过程(支持计算损失)
def forward(self, idx, targets=None):
# 获取输入token序列的形状:[批次大小B, 序列长度T]
B, T = idx.shape
# 生成位置编码(sin/cos位置编码):
# 1. 初始化位置编码表(context_length长度,d_model维度)
position_encoding_lookup_table = torch.zeros(context_length, d_model, device=device)
# 生成位置索引(0到context_length-1),并增加维度
position = torch.arange(0, context_length, dtype=torch.float).unsqueeze(1)
# 计算位置编码的分母项(指数衰减)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# 偶数维度用正弦函数
position_encoding_lookup_table[:, 0::2] = torch.sin(position * div_term)
# 奇数维度用余弦函数
position_encoding_lookup_table[:, 1::2] = torch.cos(position * div_term)
# 截取前T个位置的编码(适配当前输入序列长度)并转移到指定设备
position_embedding = position_encoding_lookup_table[:T, :].to(device)
# 计算输入嵌入:token嵌入 + 位置嵌入
x = self.token_embedding_lookup_table(idx) + position_embedding # [B, T, d_model]
# 将嵌入输入Transformer块序列
x = self.transformer_blocks(x)
# 通过输出线性层得到logits(未归一化的概率)
logits = self.model_out_linear_layer(x) # [B, T, max_token_value]
# 如果提供了目标标签,则计算损失
#target作用:训练时target计算损失,推理时target只生成结果
if targets is not None:
B, T, C = logits.shape
# 将logits和targets重塑为二维(适配cross_entropy的输入要求)
logits_reshaped = logits.view(B * T, C) # [B*T, C]
targets_reshaped = targets.view(B * T) # [B*T]
# 计算交叉熵损失
loss = F.cross_entropy(input=logits_reshaped, target=targets_reshaped)
else:
# 不提供目标时,损失为None
loss = None
return logits, loss
# 定义生成函数:根据输入序列生成新的token
def generate(self, idx, max_new_tokens=100):
# idx是当前上下文的token索引,形状为[B, T]
for _ in range(max_new_tokens):
# 将输入序列裁剪到context_length长度(防止超出位置编码范围)
idx_crop = idx[:, -context_length:]
# 前向传播获取预测结果(忽略损失)
logits, loss = self.forward(idx_crop)
# 取最后一个时间步的logits(预测下一个token)
logits_last_timestep = logits[:, -1, :] # [B, C]
# 应用softmax得到概率分布
probs = F.softmax(input=logits_last_timestep, dim=-1) # [B, C]
# 从概率分布中采样下一个token的索引
idx_next = torch.multinomial(input=probs, num_samples=1) # [B, 1]
# 将新采样的token索引拼接到原序列
idx = torch.cat((idx, idx_next), dim=1) # [B, T+1]
# 返回生成的完整序列
return idx

 浙公网安备 33010602011771号
浙公网安备 33010602011771号