折腾笔记[29]-使用gradio的api进行深度估计
![折腾笔记[29]-使用gradio的api进行深度估计](https://img2024.cnblogs.com/blog/1048201/202504/1048201-20250422123314553-990022857.png) 使用dokcer/podman本地部署基于深度学习的深度估计(depth estimate)模块, 从单目图像中获取深度信息, 使用gradio_client调用api获取深度信息.
使用dokcer/podman本地部署基于深度学习的深度估计(depth estimate)模块, 从单目图像中获取深度信息, 使用gradio_client调用api获取深度信息.
摘要
使用dokcer/podman本地部署基于深度学习的深度估计(depth estimate)模块, 从单目图像中获取深度信息, 使用gradio_client调用api获取深度信息.
关键词
docker;depth anything;gradio;
原理简介
深度图估计简介
[https://zhuanlan.zhihu.com/p/439717254]
深度估计是指通过图像来预测场景中物体的距离信息。单目深度估计方法包括传统方法和基于机器学习的方法.
深度估计,就是获取图像中场景里的每个点到相机的距离信息,这种距离信息组成的图我们称之为深度图,英文叫Depth map。
两张图像中相同物体的像素坐标不同,较近的物体的像素坐标差异较大,较远的物体的差异较小。同一个世界坐标系下的点在不同图像中的像素坐标差异,就是视差。不同图像之间的视差,可以换算出物体和拍摄点之间的距离,也就是深度。
depth anything v2简介
[https://arxiv.org/abs/2406.09414]
论文介绍了Depth Anything V2版本。论文中并未追求复杂技术,而是通过关键发现为构建强大的单目深度估计模型铺平道路。值得注意的是,相比V1版本,该版本通过三项核心改进实现了更精细、更鲁棒的深度预测:1)用合成图像完全替代标注的真实图像;2)大幅提升教师模型容量;3)通过海量伪标注真实图像作为桥梁指导学生模型训练。相较于基于Stable Diffusion的最新模型,我们的模型效率显著更高(推理速度提升超10倍)且精度更优。我们提供不同规模的模型(参数量从2500万到13亿不等)以支持多样化场景。得益于强大的泛化能力,通过带尺度标注的深度数据微调后,这些模型可转化为 metric depth 模型。除模型外,针对现有测试集多样性不足和噪声较多的问题,我们还构建了标注精准、场景多元的综合性评估基准,以推动未来研究。
This work presents Depth Anything V2. Without pursuing fancy techniques, we aim to reveal crucial findings to pave the way towards building a powerful monocular depth estimation model. Notably, compared with V1, this version produces much finer and more robust depth predictions through three key practices: 1) replacing all labeled real images with synthetic images, 2) scaling up the capacity of our teacher model, and 3) teaching student models via the bridge of large-scale pseudo-labeled real images. Compared with the latest models built on Stable Diffusion, our models are significantly more efficient (more than 10x faster) and more accurate. We offer models of different scales (ranging from 25M to 1.3B params) to support extensive scenarios. Benefiting from their strong generalization capability, we fine-tune them with metric depth labels to obtain our metric depth models. In addition to our models, considering the limited diversity and frequent noise in current test sets, we construct a versatile evaluation benchmark with precise annotations and diverse scenes to facilitate future research.
| 架构图 |
|---|
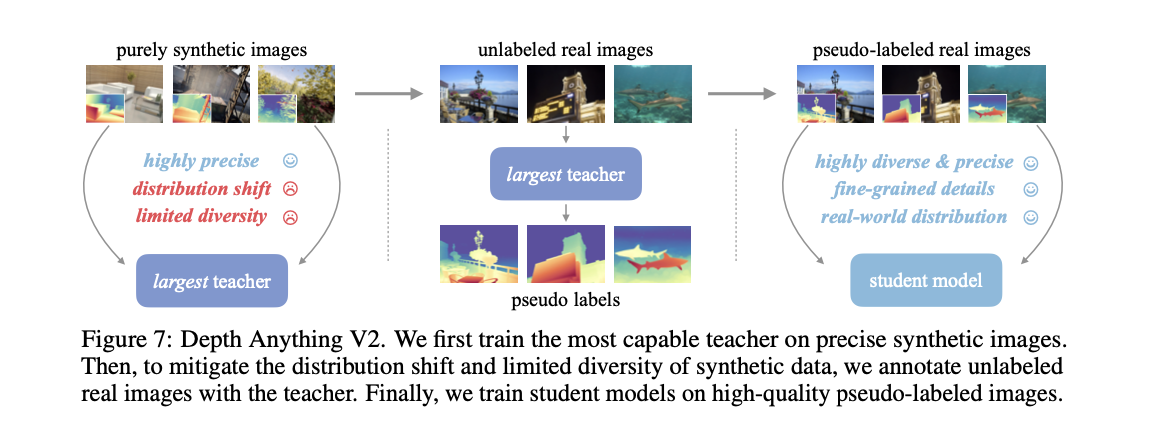 |
1. 核心思想
Depth Anything V2 是一种强大的单目深度估计基础模型,通过以下三个关键实践显著提升了深度预测的精度和鲁棒性:
- 使用合成图像替代所有标记的真实图像
- 扩大教师模型的容量
- 通过大规模伪标记真实图像指导学生模型
2. 损失函数
模型使用两种损失函数进行优化:
尺度和平移不变损失 (Scale-and Shift-Invariant Loss)
其中:
- \(d_i\) 是预测深度
- \(\hat{d}_i\) 是真实深度
- \(\alpha\) 是尺度和平移参数,通过最小化损失计算得到
梯度匹配损失 (Gradient Matching Loss)
该损失函数显著提高了使用合成图像时的深度锐度。
3. 训练流程
3.1 教师模型训练
- 在高质量合成图像上训练基于DINOv2-G的教师模型
- 使用以下联合损失:
其中\(\lambda\)是梯度匹配损失的权重(默认设置为2.0)
3.2 伪标签生成
教师模型在大规模无标签真实图像上生成伪深度标签:
3.3 学生模型训练
在伪标记的真实图像上训练最终的学生模型,使用以下损失:
其中\(\mathcal{L}_{fa}\)是特征对齐损失,用于保留预训练DINOv2编码器的信息语义。
4. 模型架构
- 编码器:基于DINOv2系列(ViT-S/B/L/G)
- 解码器:使用DPT(Dense Prediction Transformer)架构
- 输入分辨率:518×518(短边调整为518并保持宽高比)
5. 关键数学发现
-
合成图像优势:合成图像的深度标签精度远高于真实图像,特别是对于:
- 细粒度结构(边界、薄孔、小物体)
- 透明物体和反射表面
-
伪标签质量:教师模型生成的伪标签比人工标注更精确:
- 测试时分辨率缩放:模型支持测试时分辨率提升以获得更精细的深度图:
即使训练分辨率为518×518,在更高分辨率测试时仍能保持良好性能。
6. 性能指标
在提出的DA-2K评估基准上,不同规模模型的准确率:
| 模型规模 | 准确率(%) |
|---|---|
| ViT-S | 95.3 |
| ViT-B | 97.0 |
| ViT-L | 97.1 |
| ViT-G | 97.4 |
Depth Anything V2在保持高效率(比基于Stable Diffusion的模型快10倍以上)的同时,实现了更精确的深度估计。
获取gradio网页的api接口
[https://huggingface.co/posts/abidlabs/216848389441212]
例如: 打开[http://192.168.100.229:7863/?view=api]或者[https://huggingface.co/spaces/depth-anything/Depth-Anything-V2/?view=api]
| api接口展示 |
|---|
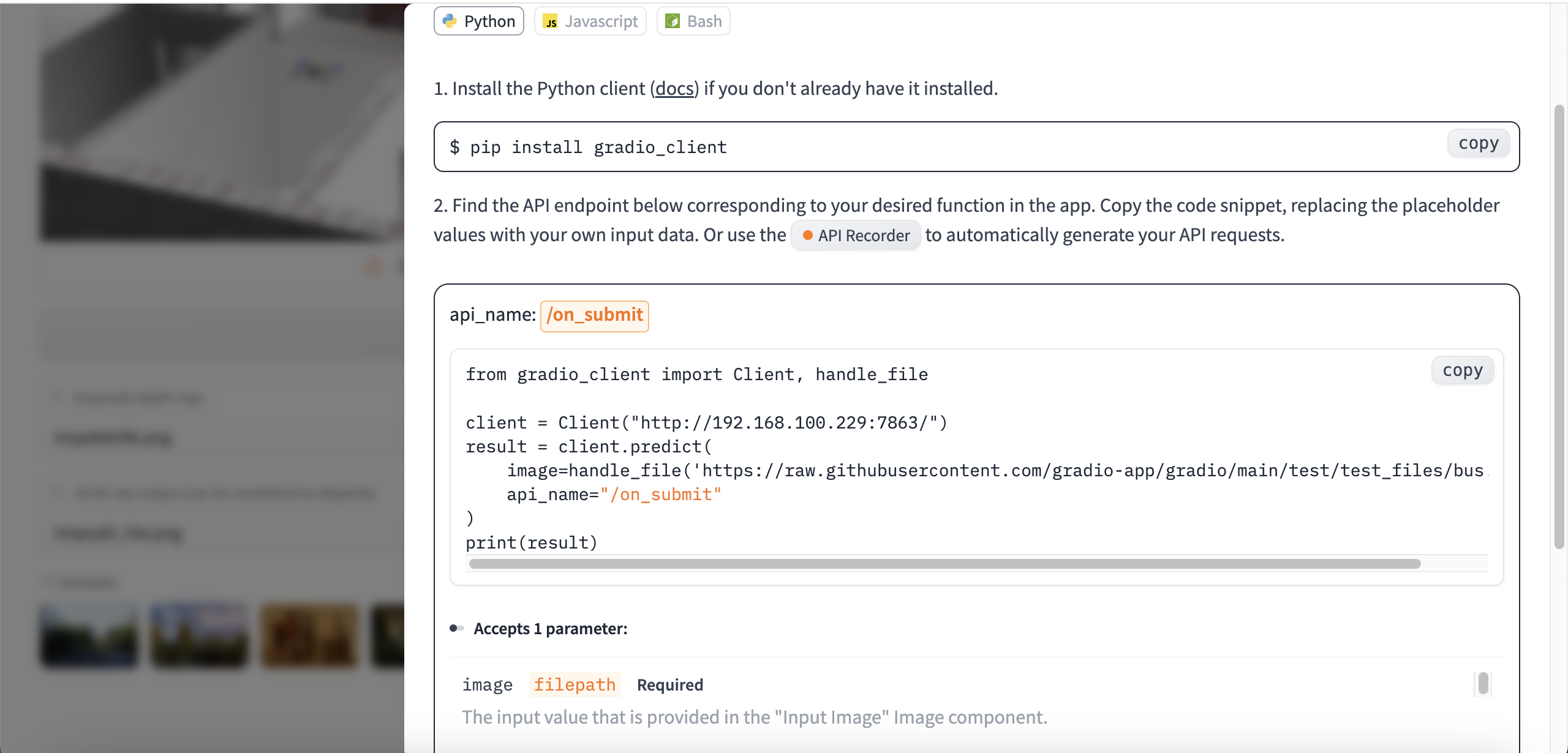 |
支持python, javascript和curl方式调用接口.
如果接口比较复杂, 还可以使用录制api方式.
介绍Gradio API录制器🪄
现在每个Gradio应用都配备了API录制功能,让您能够将交互过程转化为Python或JS客户端代码!我们的目标是让Gradio不仅成为构建ML界面的利器,更要成为创建ML API的最简单方式🔥
(翻译说明:1. 保留技术术语"API/JS"等专业名词不译 2. "🪄"魔法表情符号直译保留 3. 将"not just UIs"意译为"不仅成为...利器"符合中文对比句式 4. 结尾"🔥"表情符号保留 5. 使用"配备/转化/利器"等词汇体现技术文档的简洁专业感)
Introducing the Gradio API Recorder 🪄
Every Gradio app now includes an API recorder that lets you reconstruct your interaction in a Gradio app as code using the Python or JS clients! Our goal is to make Gradio the easiest way to build ML APIs, not just UIs 🔥
部署&使用
离线部署
- 百度网盘整合包(包含模型文件)
- 支持cpu/gpu模式
通过网盘分享的文件:depth
链接: https://pan.baidu.com/s/1E_fACUNZEz6Mieqlr691Bg?pwd=9fgt 提取码: 9fgt
使用:
# amd64
podman load -i depth-anything-v2.tar
podman run --name=depth -p 7863:7860 -d registry.hf.space/depth-anything-depth-anything-v2:zero-7f2e027 python app.py
- 方式2: huggingface的docker镜像(模型运行时下载)
[https://huggingface.co/spaces/depth-anything/Depth-Anything-V2]
docker run -it -p 7860:7860 --platform=linux/amd64 --gpus all \
registry.hf.space/depth-anything-depth-anything-v2:zero-7f2e027 python app.py
使用API调用
# 测试gradio的深度图api并保存结果文件
#############################################
# gradio接口
from gradio_client import Client, handle_file
# 图像处理
from PIL import Image
# 内置库
import shutil
import os
#############################################
# 初始化Gradio客户端
client = Client("http://192.168.100.229:7863/")
# 调用API获取处理结果
result = client.predict(
image=handle_file('../assets/scene1.png'),
api_name="/on_submit"
)
# 收集所有文件路径(处理嵌套的列表结构)
file_paths = []
for item in result:
if isinstance(item, list):
file_paths.extend(item) # 展开列表中的文件路径
else:
file_paths.append(item) # 添加字符串类型的文件路径
# 创建输出目录(如果不存在)
output_dir = '../result'
os.makedirs(output_dir, exist_ok=True)
# 遍历处理每个文件路径
for idx, file_path in enumerate(file_paths):
try:
# 读取图像文件并转换为PNG格式
img = Image.open(file_path)
# 生成标准化的输出文件名(强制使用PNG格式)
new_filename = f'gradio_api_depth_{idx}.png'
new_path = os.path.join(output_dir, new_filename)
# 保存转换后的文件
img.save(new_path, 'PNG')
print(f'文件已保存到:{new_path}')
except Exception as e:
print(f'处理文件 {file_path} 时出错:{str(e)}')
# 输出原始结果信息(调试用)
print("\n原始API返回路径:")
print(result)
效果
| 原图 | 深度图 |
|---|---|
 |
 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号