折腾笔记[27]-使用OCR检测和识别字母
摘要
使用docker容器离线部署OCR, 使用OCR在自然场景检测(定位文字)和识别字母.
关键词
ocr;detection;recognition;scene;docker;podman;
原理简介
OCR检测及识别文字综述
[https://developer.aliyun.com/article/1054626]
自然场景、复杂场景(如字符变形、重叠)
- 检测detect : 检测文本位置(定位)
- 识别reg : 在文本位置识别文本
- OCR 1.0
- 读光OCR
- GOT_OCR_v2
- PaddleOCR_v4
#OCR,#深度学习,#场景识别,#CTC,
1. OCR技术概述
OCR(Optical Character Recognition,光学字符识别)技术是计算机视觉的一个重要分支,其核心任务是从图像中检测并识别出文字内容,并将其转换为结构化数据。这项技术在文档处理、票据识别、车牌识别、路标识别等众多领域有着广泛的应用。随着深度学习技术的发展,OCR技术在复杂场景下的表现越来越出色,逐渐成为主流的文字识别方式。
2. 传统OCR技术
传统OCR技术主要依赖于图像处理技术和统计机器学习方法。其流程通常包括图像预处理(如灰度化、二值化、矫正等)、字符定位切分、特征提取(如HOG、SVM等)以及字符识别。传统方法在处理背景单一、分辨率高的简单文档图像时效果较好,但在复杂场景下(如光照变化、字符变形、重叠等)识别精度会显著下降。
3. 基于深度学习的OCR技术
深度学习技术的引入极大地推动了OCR技术的发展。基于深度学习的OCR方法无需手动提取特征,能够自动学习图像中的复杂模式,从而在复杂场景下实现更准确的文字识别。
-
基于CTC的算法
CTC(Connectionist Temporal Classification)是一种常用于序列识别的算法,能够解决时序类文本的对齐问题。例如,CRNN(Convolutional Recurrent Neural Network)模型结合了卷积神经网络(CNN)和循环神经网络(RNN),并通过CTC损失函数实现端到端的序列识别,在场景文字识别中表现出色。此外,Rosetta等改进算法在规则文本识别上也有很好的效果。 -
基于Attention的算法
Attention机制能够使模型在解码过程中集中注意力于图像的关键区域,从而提高识别精度。例如,R2AM(Recurrent Attention Model)和ASTER等模型通过引入Attention机制,能够有效处理不规则文本识别问题。这些方法在处理弯曲、变形、遮挡等复杂场景下的文本时具有显著优势。 -
基于Transformer的算法
Transformer结构在处理长依赖关系和全局信息方面表现出色。例如,SRN(Semantic Reasoning Network)和NRTR(No Recurrent Transformer)等模型利用Transformer的编码器和解码器结构,能够更好地融合视觉信息和语义信息,进一步提升识别效果。 -
端到端识别方法
端到端的OCR方法将文本检测和识别集成到一个网络中,能够联合优化检测和识别任务,提高整体效率。例如,FOTS(Fast Oriented Text Spotter)和ABCNet等模型通过端到端的方式,实现了快速且准确的文本检测与识别。
4. 复杂场景下的OCR技术
在自然场景和复杂场景下,OCR技术面临着诸多挑战,如字符变形、重叠、光照变化等。近年来,研究人员提出了一系列创新方法来解决这些问题:
-
复杂场景文字检测
例如,GOT_OCR_v2和PaddleOCR_v4等模型通过改进检测算法,能够更准确地定位复杂场景中的文本区域。这些模型通常结合了先进的特征提取技术和优化的检测网络结构,能够有效处理弯曲、倾斜、重叠等复杂情况。 -
复杂场景文字识别
除了检测,复杂场景下的文字识别也需要特别的处理。例如,通过引入注意力机制和Transformer结构,模型能够更好地理解和识别变形、模糊的文本。此外,一些方法还结合了数据增强和预训练模型,进一步提升了模型的鲁棒性和泛化能力。
5. 未来发展趋势
-
复杂场景的进一步优化
随着深度学习技术的不断发展,OCR技术在复杂场景下的表现将不断提升。例如,通过改进网络结构、引入新的算法(如多模态学习)以及优化训练策略,模型将能够更好地处理字符变形、重叠、多语种混合等复杂情况。 -
零样本和少样本学习
在一些特殊领域(如古籍识别、少数民族语言识别等),样本数据往往有限。因此,零样本学习和少样本学习成为未来OCR技术的重要发展方向。通过结合上下文语义信息和辅助数据,模型能够在有限的样本条件下实现更准确的识别。 -
大规模数据集和标注
数据是深度学习模型性能提升的关键。未来需要开源更多大规模、高质量的文字数据集,并通过数据增强和生成对抗网络(GAN)等技术扩充数据集,从而进一步提升模型的性能和泛化能力。 -
轻量级模型的开发
为了满足实际应用中对速度和效率的要求,开发轻量级的OCR模型成为一个重要趋势。通过模型压缩、优化网络结构等方法,可以在保证一定精度的前提下,显著提升模型的运行速度,使其更适合在移动设备和边缘计算场景中部署。
OCR评价指标
[https://developer.aliyun.com/article/1054626]
文字识别目前用的最多的评价准则有词准确度 ( Accuracy ) 、字符准确度、编辑距离、归一化编辑距离、语境相关的评测方式等。
编辑距离是针对二个字符串(例如英文字)的差异程度的量化量测,量测方式是看至少需要多少次的处理才能将一个字符串变成另一个字符串。在莱文斯坦距离中,可以删除、加入、替换字符串中的任何一个字元,也是较常用的编辑距离定义,常常提到编辑距离时,指的就是莱文斯坦距离。
其他说明:
- 平均识别率:
- 平均编辑距离:编辑距离的平均值,用来评估整体的检测和识别模型;
- 平均替换错误:编辑距离计算时的替换操作,用于评估识别模型对相似字符的区分能力;
- 平均多字错误:编辑距离计算时的删除操作,用来评估检测模型的误检和识别模型的多字错误;
- 平均漏字错误:编辑距离计算时的插入操作,用来评估检测模型的漏检和识别模型的少字错误;
读光OCR简介
[https://duguang.aliyun.com/]
[https://duguang.aliyun.com/experience?type=universal&subtype=general#intro]
[https://duguang.aliyun.com/experience?type=universal&subtype=general_text#intro]
[https://zhuanlan.zhihu.com/p/685353998]
[https://www.modelscope.cn/models/iic/cv_LightweightEdge_ocr-recognitoin-general_damo/summary]
[https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/OCR/LiteWeightOCR]
阿里云文字识别OCR(读光OCR),是一款由阿里巴巴达摩院打造的OCR产品,用于识别图片、文档、卡证等文件所包含的文字信息。
本产品具备完善的图像检测、文字识别和文字理解的能力,服务的日均访问量高达上亿次,具有优秀的识别效果与处理性能。
通用文字识别适用于各行业场景下的非结构化文字识别,支持返回位置坐标信息。
| 读光OCR架构图 |
|---|
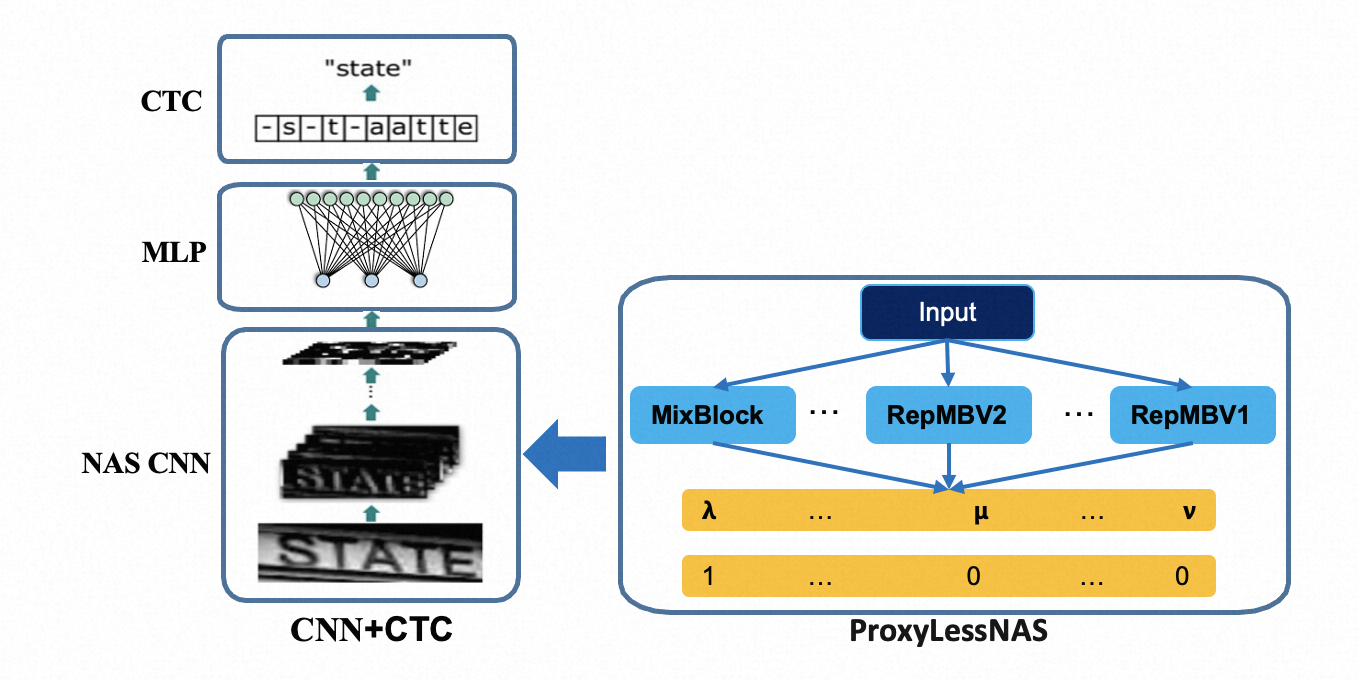 |
读光OCR系列模型中涉及的ConvNextViT模型,主要包括三个主要部分,Convolutional Backbone提取图像视觉特征,ConvTransformer Blocks用于对视觉特征进行上下文建模,最后连接CTC loss进行识别解码以及网络梯度优化。
- 各场景文本识别模型:
- ConvNextViT-通用场景
- ConvNextViT-手写场景
- ConvNextViT-自然场景
- ConvNextViT-车牌场景
- ConvNextViT-文档印刷场景
- CRNN-通用场景
- 各场景文本检测模型:
- SegLink++-通用场景行检测
- SegLink++-通用场景单词检测
- DBNet-通用场景行检测
- 整图OCR能力:
- 整图OCR-多场景
GOT OCR简介
[https://huggingface.co/stepfun-ai/GOT-OCR2_0]
[https://github.com/Ucas-HaoranWei/GOT-OCR2.0/tree/main]
- General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model
传统OCR系统(OCR-1.0)对人工光学字符智能化处理需求的日益增长已逐渐难以满足实际应用需求。本文将所有人造光学信号(如纯文本、数学/化学公式、表格、图表、乐谱乃至几何图形)统称为"字符",提出通用OCR理论并构建了卓越的GOT模型,以此推动OCR-2.0时代的到来。该模型参数量达5.8亿,采用高压缩编码器与长上下文解码器构成统一、优雅的端到端架构。作为OCR-2.0时代的代表,GOT能处理上述所有"字符"类型的识别任务:输入侧支持切片式与整页式的常见场景/文档图像;输出侧通过简单提示即可生成纯文本或结构化结果(支持markdown/tikz/smiles/kern等多种格式)。该模型还具备交互式OCR功能,可通过坐标或颜色引导实现区域级识别,并创新性地引入动态分辨率与多页面OCR技术以增强实用性。实验部分通过充分的数据验证了模型的优越性。
Traditional OCR systems (OCR-1.0) are increasingly unable to meet people’s usage due to the growing demand for intelligent processing of man-made optical characters. In this paper, we collectively refer to all artificial optical signals (e.g., plain texts, math/molecular formulas, tables, charts, sheet music, and even geometric shapes) as "characters" and propose the General OCR Theory along with an excellent model, namely GOT, to promote the arrival of OCR-2.0. The GOT, with 580M parameters, is a unified, elegant, and end-to-end model, consisting of a high-compression encoder and a long-contexts decoder. As an OCR-2.0 model, GOT can handle all the above "characters" under various OCR tasks. On the input side, the model supports commonly used scene- and document-style images in slice and whole-page styles. On the output side, GOT can generate plain or formatted results (markdown/tikz/smiles/kern) via an easy prompt. Besides, the model enjoys interactive OCR features, i.e., region-level recognition guided by coordinates or colors. Furthermore, we also adapt dynamic resolution and multi- page OCR technologies to GOT for better practicality. In experiments, we provide sufficient results to prove the superiority of our model.
| GOT-OCR架构图 |
|---|
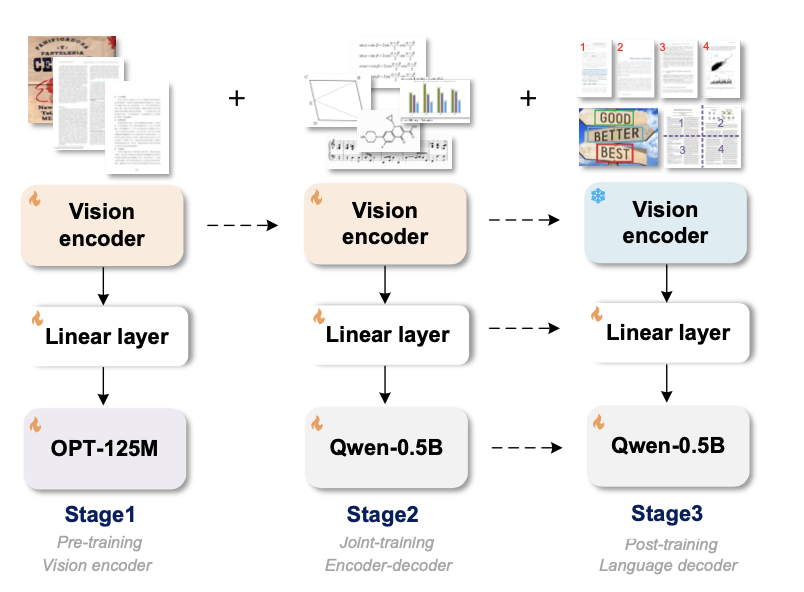 |
1. 编码器-解码器架构
GOT 的模型架构由三部分组成:
- 视觉编码器:将输入图像转换为高压缩的视觉特征。
- 线性投影层:调整视觉特征的维度以匹配解码器的输入。
- 解码器:生成OCR结果。
数学表示为:
其中,\(\mathbf{I}\) 是输入图像,\(\mathbf{h}_{\text{vis}}\) 是视觉特征,\(\mathbf{W}\) 是投影矩阵,\(\mathbf{y}\) 是输出OCR结果。
2. 高压缩率编码器
编码器采用VitDet结构,将高分辨率图像(如1024×1024)压缩为256×1024的视觉特征。其数学原理基于局部注意力机制:
局部注意力显著降低了计算成本,同时保留了密集文本的细节信息。
3. 长上下文解码器
解码器基于Qwen-0.5B语言模型,支持8K的最大上下文长度,确保对长文本和复杂格式(如数学公式、表格)的高效处理:
4. 多阶段训练策略
GOT 的训练分为三个阶段:
- 编码器预训练:使用纯文本识别任务优化编码器。\[\mathcal{L}_{\text{enc}} = \text{CrossEntropy}(\mathbf{y}_{\text{pred}}, \mathbf{y}_{\text{true}}) \]
- 联合训练:将预训练编码器与解码器结合,注入多样化OCR知识(如乐谱、分子式)。\[\mathcal{L}_{\text{joint}} = \mathcal{L}_{\text{enc}} + \lambda \mathcal{L}_{\text{format}} \]
- 解码器微调:针对交互式OCR、动态分辨率等任务优化解码器。\[\mathcal{L}_{\text{dec}} = \mathcal{L}_{\text{joint}} + \mathcal{L}_{\text{fine-grained}} \]
5. 动态分辨率与多页处理
- 动态分辨率:通过滑动窗口(1024×1024)处理超高分辨率图像,数学上表示为:\[\mathbf{y} = \text{Concat}\left(\text{GOT}(\mathbf{I}_1), \dots, \text{GOT}(\mathbf{I}_N)\right) \]其中,\(\mathbf{I}_i\) 是滑动窗口裁剪的子图像。
- 多页OCR:将多页PDF拼接为单张图像输入,避免分页问题:\[\mathbf{I}_{\text{multi-page}} = \text{ConcatPages}(\mathbf{I}_1, \dots, \mathbf{I}_M) \]
6. 数据引擎与合成数据
GOT 依赖大规模合成数据训练,包括:
- 自然场景文本:从公开数据集(如Laion-2B)生成伪标注。
- 格式化数据:使用Mathpix-markdown渲染数学公式和表格。
- 通用OCR数据:通过工具(如TikZ、Verovio)生成乐谱、几何图形等数据。
数学上,数据生成过程可表示为:
7. 性能优化指标
GOT 在多个OCR任务中采用以下评估指标:
- 编辑距离(Edit Distance):衡量预测与真实文本的差异。\[\text{ED} = \text{Levenshtein}(\mathbf{y}, \mathbf{y}_{\text{true}}) \]
- F1分数:综合精确率与召回率。\[F1 = 2 \cdot \frac{\text{Precision} \cdot \text{Recall}}{\text{Precision} + \text{Recall}} \]
总结
GOT-OCR 通过统一的端到端架构、高效压缩编码器和长上下文解码器,实现了对多样化“字符”(文本、公式、表格等)的高效识别。其数学原理的核心在于:
这一设计显著降低了训练与推理成本,同时提升了模型的通用性和实用性。
PaddleOCR_v4简介
[https://paddlepaddle.github.io/PaddleOCR/main/ppocr/blog/PP-OCRv4_introduction.html]
PP-OCRv4在PP-OCRv3的基础上进一步升级。整体的框架图保持了与PP-OCRv3相同的pipeline,针对检测模型和识别模型进行了数据、网络结构、训练策略等多个模块的优化。
| PPOCR_v4架构图 |
|---|
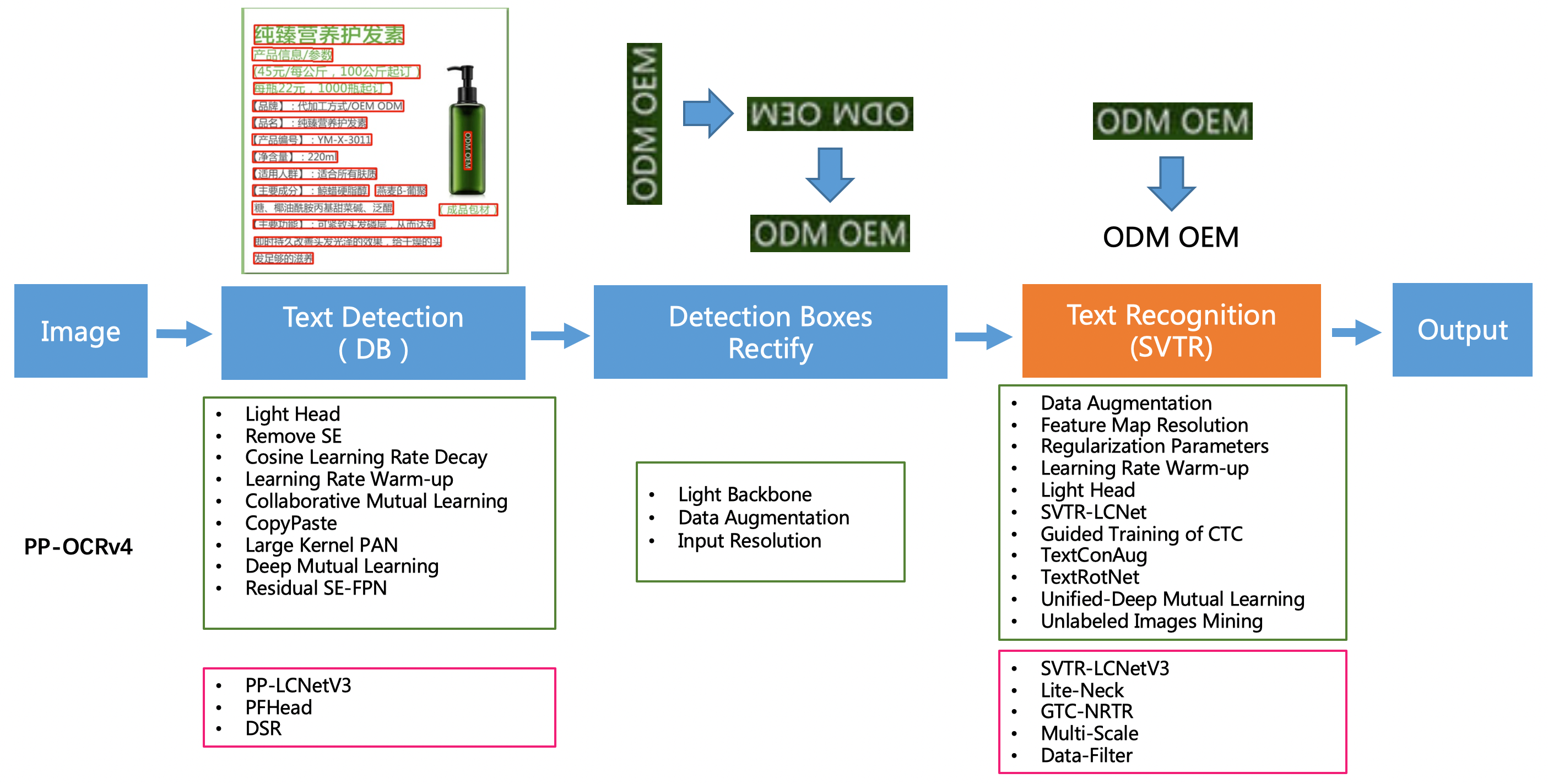 |
从算法改进思路上看,分别针对检测和识别模型,进行了共10个方面的改进:
- 检测模块:
- LCNetV3:精度更高的骨干网络
- PFHead:并行head分支融合结构
- DSR: 训练中动态增加shrink ratio
- CML:添加Student和Teacher网络输出的KL div loss
- 识别模块:
- SVTR_LCNetV3:精度更高的骨干网络
- Lite-Neck:精简的Neck结构
- GTC-NRTR:稳定的Attention指导分支
- Multi-Scale:多尺度训练策略
- DF: 数据挖掘方案
- DKD :DKD蒸馏策略
OpenOCR简介
[https://github.com/Topdu/OpenOCR/tree/main?tab=readme-ov-file#quick-start]
[https://github.com/Topdu/OpenOCR/blob/main/docs/openocr.md]
[https://arxiv.org/abs/2411.15858]
[https://modelscope.cn/studios/topdktu/OpenOCR-Demo]
- SVTRv2: CTC Beats Encoder-Decoder Models in Scene Text Recognition
基于连接时序分类(CTC)的场景文本识别(STR)方法(如SVTR)因其仅包含视觉模型和CTC对齐线性分类器的简洁架构,在OCR领域被广泛应用,并具备快速推理优势。然而,这类方法在复杂场景下的准确率通常低于基于编码器-解码器架构的方法(EDTRs)。本文提出SVTRv2——一个在准确率和推理速度上均超越主流EDTRs的CTC模型。通过创新性改进,SVTRv2能够有效应对文本不规则性和利用语言上下文,从而处理各类复杂文本实例。
首先,我们提出多尺度自适应缩放策略(MSR),通过动态调整文本尺寸保持其可读性;同时引入特征重排模块(FRM)确保视觉特征完美适配CTC对齐需求,从而缓解对齐难题。其次,我们设计语义引导模块(SGM),将语言上下文信息融入视觉模型以提升准确率。值得注意的是,SGM在推理阶段可被移除,不会增加计算开销。
我们在标准测试集和新兴挑战性数据集上对SVTRv2进行全面评估,与24种主流STR模型进行多场景公平对比,涵盖不规则文本、多语言和长文本等场景。实验结果表明,SVTRv2在所有测试场景中均以显著优势超越EDTRs模型,同时保持更快的推理速度。代码已开源: https://github.com/Topdu/OpenOCR 。
Connectionist temporal classification (CTC)-based scene text recognition (STR) methods, e.g., SVTR, are widely employed in OCR applications, mainly due to their simple architecture, which only contains a visual model and a CTC-aligned linear classifier, and therefore fast in- ference. However, they generally have worse accuracy than encoder-decoder-based methods (EDTRs), particularly in challenging scenarios. In this paper, we propose SVTRv2, a CTC model that beats leading EDTRs in both accuracy and inference speed. SVTRv2 introduces novel upgrades to handle text irregularity and utilize linguistic context, which endows it with the capability to deal with challenging and diverse text instances. First, a multi-size resizing (MSR) strategy is proposed to adaptively resize the text and maintain its readability. Meanwhile, we introduce a feature rearrangement module (FRM) to ensure that visual features accommodate the alignment requirement of CTC well, thus alleviating the alignment puzzle. Second, we propose a semantic guidance module (SGM). It integrates linguistic context into the visual model, allowing it to leverage language information for improved accuracy. Moreover, SGM can be omitted at the inference stage and would not increase the inference cost. We evaluate SVTRv2 in both standard and recent challenging benchmarks, where SVTRv2 is fairly compared with 24 mainstream STR models across multiple scenarios, including different types of text irregularity, languages, and long text. The results indicate that SVTRv2 surpasses all the EDTRs across the scenarios in terms of accuracy and speed. Code is available at https://github.com/Topdu/OpenOCR.
| SVTRv2架构图 |
|---|
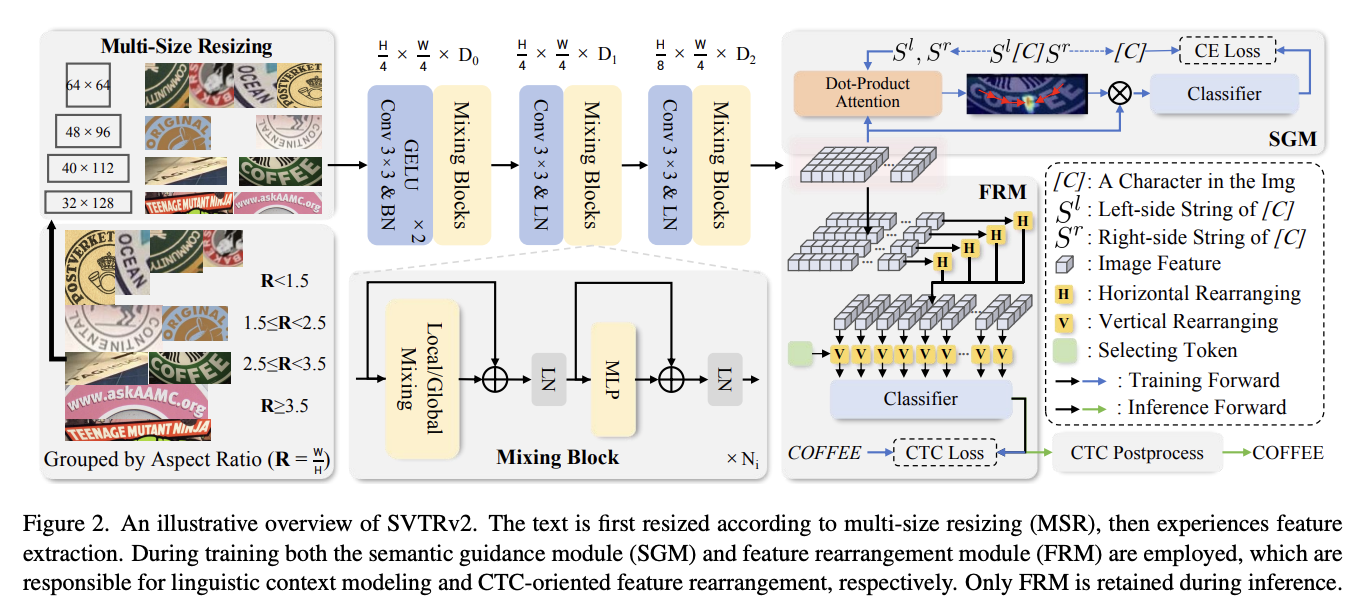 |
1. 多尺度调整策略 (MSR)
为了解决不规则文本在固定尺寸调整下的失真问题,SVTRv2提出基于长宽比的自适应调整策略:
定义4种调整尺寸:
- \([64, 64]\) 当 \(R < 1.5\) (R1)
- \([48, 96]\) 当 \(1.5 \leq R < 2.5\) (R2)
- \([40, 112]\) 当 \(2.5 \leq R < 3.5\) (R3)
- \([32, \lfloor R \rfloor \times 32]\) 当 \(R \geq 3.5\) (R4)
2. 特征重排模块 (FRM)
2.1 水平重排
对于特征图 \(F_i \in \mathbb{R}^{\frac{W}{4} \times D_2}\),计算水平重排矩阵:
重排后特征:
2.2 垂直重排
使用选择标记 \(T^s \in \mathbb{R}^{1 \times D_2}\) 计算垂直重排矩阵:
最终重排特征序列:
3. 语义引导模块 (SGM)
3.1 上下文编码
对于字符 \(c_i\) 的左右上下文 \(S_i^l\) 和 \(S_i^r\):
左上下文隐藏表示:
3.2 注意力计算
注意力图:
预测概率:
4. 损失函数
总损失由CTC损失和SGM损失组成:
其中:
- \(\mathcal{L}_{ctc} = \text{CTCLoss}(\tilde{Y}_{ctc}, Y)\)
- \(\mathcal{L}_{sgm} = \frac{1}{2L}\sum_{i=1}^L \left(\text{CE}(\tilde{Y}_i^l, c_i) + \text{CE}(\tilde{Y}_i^r, c_i)\right)\)
超参数设置为 \(\lambda_1=0.1\), \(\lambda_2=1\)。
5. 模型架构优势
SVTRv2通过以下数学设计克服了传统CTC模型的局限:
- MSR保持文本可读性:\(\min \|R_{resized} - R_{original}\|\)
- FRM实现特征空间校正:\(\tilde{F} = M \times F\)
- SGM注入语言上下文:\(\max P(c_i | F, S_i^l, S_i^r)\)
这些创新使SVTRv2在保持CTC高效性的同时,达到了超越Encoder-Decoder模型的准确率。
体验&本地部署
下载&运行docker镜像
打开[http://127.0.0.1:7865]和[http://127.0.0.1:7866].
- 百度网盘整合包(包含模型)
通过网盘分享的文件:OCR
链接: https://pan.baidu.com/s/1Q4DWvy4kFws-8vXBRlfwZg?pwd=g7bu 提取码: g7bu
运行:(默认使用cpu推理, 为了兼容性)
docker load biu_openocr-v1-amd64.tar
docker load biu_ppocr-v1-amd64.tar
docker run -p 7865:7860 -d biu_openocr:v1-amd64 python app.py
docker run -p 7866:7860 -d biu_ppocr:v1-amd64 python app.py
docker run -p 7867:7860 -d biu_paddleocr:v2-amd64 python app_box.py
- huggingface镜像(下载慢, 模型运行时才下载)
# OpenOCR
docker pull registry.hf.space/topdu-openocr-demo:cpu-1ceafe5
docker run -it -p 7860:7860 --platform=linux/amd64 \
registry.hf.space/topdu-openocr-demo:cpu-1ceafe5 python app.py
# docvqa + paddleocr
docker pull registry.hf.space/gaunernst-layoutlm-docvqa-paddleocr:cpu-90a9cee
docker run -it -p 7860:7860 --platform=linux/amd64 \
registry.hf.space/gaunernst-layoutlm-docvqa-paddleocr:cpu-90a9cee
# paddleocr_v4
docker pull registry.hf.space/paddlepaddle-paddleocr:cpu-49fcf58
docker run -it -p 7860:7860 --platform=linux/amd64 \
registry.hf.space/paddlepaddle-paddleocr:cpu-49fcf58 python app.py
效果
| 原图 | 识别图 | 识别结果 | 文字标注框 |
|---|---|---|---|
 |
 |
CAB |  |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号