幂法(指数迭代法)
幂法是通过迭代来计算矩阵的主特征值(按模最大的特征值)与其对应特征向量的方法,适合于用于大型稀疏矩阵。
基本定义
设$A = (a_{ij})\in R^{n\times n}$,其特征值为$\lambda_i$,对应特征向量$x_i(i=1,...,n)$,即$Ax_i = \lambda_i x_i(i=1,...,n)$,且$\{x_1,...,x_n\}$线性无关。任取一个非零向量$v_0\in R^{n}$,构造一个关于矩阵$A$的乘幂的向量序列:
$v_k = Av_{k-1}=A^2v_{k-2}=A^3v_{k-3}=...=A^kv_{0}$
称$v_k$为迭代向量。
设特征值$\lambda_i$的前$r$个为绝对值最大的特征值(ppt中分为$\lambda_1$强占优和非强占优,感觉没必要),即有:
$|\lambda_1|=|\lambda_2|=...=|\lambda_r|>|\lambda_{r+1}|\ge...\ge|\lambda_n|$
由于$\{x_1,...,x_n\}$ 线性无关,所以构成$R^n$的一个基,于是$v_0$能被表达为:
$v_0=\sum\limits_{i=1}^{n}\alpha_i x_i$(且设$\alpha_1...\alpha_r$非全零)
由$Ax_i = \lambda_i x_i$:
$v_k = Av_{k-1}=...=A^kv_{0}=\sum\limits_{i=1}^{n}A^k\alpha_i x_i=\sum\limits_{i=1}^{n}\lambda_i^k\alpha_i x_i=\lambda_1^k(\sum\limits_{i=1}^{r}\alpha_ix_i+\varepsilon_k)$
其中:
$\varepsilon_k = \sum\limits_{i=r+1}^{n}(\frac{\lambda_i}{\lambda_1})^k\alpha_ix_i$
因为$\lambda_1$最大,所以有$|\frac{\lambda_i}{\lambda_1}|<1 (i=r+1,...,n)$,从而有:
$\lim\limits_{k\to \infty}(\frac{\lambda_i}{\lambda_1})^k=0 (i=r+1,...,n)$
所以有:
$\lim\limits_{k\to \infty}\varepsilon_k = 0$
$\lim\limits_{k\to \infty}v_k = \lim\limits_{k\to \infty}\lambda_1^k(\sum\limits_{i=1}^{r}\alpha_ix_i+\varepsilon_k) = \lim\limits_{k\to \infty}\lambda_1^k(\sum\limits_{i=1}^{r}\alpha_ix_i)$
因为在上式中$(\sum\limits_{i=1}^{r}\alpha_ix_i)$是固定项,可以看出,迭代到后期,$v_{k+1}$和$v_k$的各个元素有固定比值$\lambda_1$,即:
$\lim\limits_{k\to \infty}\frac{(v_{k+1})_i}{(v_{k})_i} = \lambda_1$
这样,收敛到主特征值后,还可另外计算它对应的一个特征向量(其实就是构成$v_0$的前$r$项之和,而且只能算一个):
$\lim\limits_{k\to \infty}\frac{v_{k}}{\lambda_1^k} = \sum\limits_{i=1}^{r}\alpha_ix_i$
其中收敛速度由比值$|\frac{\lambda_{r+1}}{\lambda_1}|$决定,越小收敛越快。
幂法改进
以上定义中,随着不断的迭代,如果$|\lambda_1|>1$,$v_k$会无限大;如果$|\lambda_1|<1$,$v_k$则会趋于0。在计算机中就会导致溢出而出错。当然如果$|\frac{\lambda_{r+1}}{\lambda_1}|$很小,使得$\varepsilon_k$能快速收敛为0,并且$|\lambda_1|$不会太大或太小以至于在$\varepsilon_k$收敛前$v_k$就溢出了,那用上述方法就行了。
但是通常不会碰到那么好的运气,所以就在每次迭代的时候就要对$v_k$进行“规范化”,防止它溢出。规范化就是将向量除以一个标量,使向量的长度为1,而向量的长度有多种度量法,比如$||\cdot||_2、||\cdot||_\infty$等。一般使用$||\cdot||_\infty$,就是向量各个分量的绝对值的最大值(用别的也一样,但是这个复杂度最小,计算机最好算)。
为了便于理解,将一次迭代分为两步,一步乘矩阵$A$,一步除以向量长度进行规范化:
| 迭代序号 | 乘$A$($v_i$) | 规范化($u_i$) |
| 初始化 | 随机取$v_0=\sum\limits_{i=1}^{n}\alpha_ix_i$ | $u_0=\frac{v_0}{||v_0||}$ |
| 1 | $v_1=Au_0=\frac{Av_0}{\left\|v_0\right\|}$ | $u_1=\frac{v_1}{||v_1||}=\frac{\frac{Av_0}{\left\|v_0\right\|}}{\left\|\frac{Av_0}{\left\|v_0\right\|}\right\|}=\frac{Av_0}{\left\|Av_0\right\|}$ |
| 2 | $v_2=Au_1=\frac{A^2v_0}{\left\|Av_0\right\|}$ | $u_2=\frac{v_2}{||v_2||}=\frac{\frac{A^2v_0}{\left\|Av_0\right\|}}{\left\|\frac{A^2v_0}{\left\|Av_0\right\|}\right\|}=\frac{A^2v_0}{\left\|A^2v_0\right\|}$ |
| ... | ... | ... |
| k | $v_k=Au_{k-1}=\frac{A^kv_0}{\left\|A^{k-1}v_0\right\|}$ | $u_k=\frac{v_k}{||v_k||}=\frac{\frac{A^kv_0}{\left\|A^{k-1}v_0\right\|}}{\left\|\frac{A^kv_0}{\left\|A^{k-1}v_0\right\|}\right\|}=\frac{A^kv_0}{\left\|A^kv_0\right\|}$ |
| ... | ... | ... |
主特征值
对于向量序列${v_k}$:
$v_k=\frac{A^kv_0}{\left\|A^{k-1}v_0\right\|}=\frac{\lambda_1^k(\sum\limits_{i=1}^{r}\alpha_ix_i+\varepsilon_k)}{\left\|\lambda_1^{k-1}(\sum\limits_{i=1}^{r}\alpha_ix_i+\varepsilon_{k-1})\right\|}$
对$v_k$取范数:
$||v_k||=\frac{\left\|\lambda_1^k(\sum\limits_{i=1}^{r}\alpha_ix_i+\varepsilon_k)\right\|}{\left\|\lambda_1^{k-1}(\sum\limits_{i=1}^{r}\alpha_ix_i+\varepsilon_{k-1})\right\|}=|\lambda_1|\frac{\left\|\sum\limits_{i=1}^{r}\alpha_ix_i+\varepsilon_k\right\|}{\left\|\sum\limits_{i=1}^{r}\alpha_ix_i+\varepsilon_{k-1}\right\|}\to\left|\lambda_1\right|, (k\to\infty)$
注意!在计算机中并不是直接通过这个极限$k\to\infty$来计算,而是通过上面表格的迭代来实现$k\to\infty$,由于每一步的“规范化”,才能使得计算成为可能。而且如果直接用这个极限算的话就和前面的没区别了,“规范化”的优势没有用起来。
另外,因为算范数的时候是先取向量分量的绝对值再算的,所以改进后的方法计算出来的主特征值不可避免带有绝对值,因此特征值的符号还要再判断一下(下面判断)。而改进之前的是不带的(因为没有计算范数进行规范化),如果符合条件,改进之前的也可一试。
主特征值对应的一个特征向量
观察向量$u_k$:
$u_k=\frac{A^kv_0}{\left\|A^kv_0\right\|}=\frac{\lambda_1^k(\sum\limits_{i=1}^{r}\alpha_ix_i+\varepsilon_k)}{\left\|\lambda_1^{k}(\sum\limits_{i=1}^{r}\alpha_ix_i+\varepsilon_{k})\right\|}\to{\rm sign}(\lambda_1^k)\frac{\sum\limits_{i=1}^{r}\alpha_ix_i}{\left\|\sum\limits_{i=1}^{r}\alpha_ix_i\right\|},(k\to\infty)$
如上,通过$u_k$可获得一个单位化的主特征值特征向量。因为还乘上了$\lambda_1^k$的符号,所以向量各个分量的符号和迭代的次数$k$有关。当$k$足够大(使迭代收敛),连续两次迭代,$u_k$的分量的符号不变时,则可以判断主特征值符号为正,否则为负,从而解决了上面主特征值符号未知的问题。
另外,求出的单位特征向量(如果用L2范数)是主特征值的所有不相关特征向量的线性组合,与设置的$v_0$有关。当然如果主特征值的没有重根,且$\alpha_1$不为零(为零的话就迭代出第二大的特征值),那规范化后得出的都是同一个特征向量而和$v_0$无关(如果特征值为负,符号可能随迭代次数改变)。
Python代码
import numpy as np #矩阵A A = np.matrix( [[-5.6,2.,0.], [3.,-1.,1.], [0.,1.,3.]]) L0=2#范数类型 v = np.matrix([[-2.],[-7.],[1.]])#v0 u = v/(np.linalg.norm(v,L0))#u0 #迭代函数 def iterate_fun(A,u,final,L): i=0 while i<final: v = A*u u = v/(np.linalg.norm(v,L)) i=i+1 print("幂法特征值:") print(np.linalg.norm(v,L)) print("numpy特征值:") print(np.linalg.eig(A)[0]) print("幂法特征向量:") print(u) print("numpy特征向量:") print(np.linalg.eig(A)[1]) iterate_fun(A,u,1010,L0)
结果截图:

主特征值与numpy算出来绝对值一致。这里用的是L2范数,且主特征值无重根,所以计算出来的特征向量单位化后和numpy主特征值对应的向量除符号外相同。
迭代加速(原点平移法)
幂法迭代的速度由比值$\frac{\left|\lambda\right|_{second\,biggest}}{|\lambda_1|}$决定,当比值比较接近1时,迭代的速度就可能比较慢了。迭代加速的方法是给矩阵$A$减去一个数量阵$pI$:($I$为单位阵)
$B = A-pI$
假设$A$的特征值为:
$\lambda_1=\lambda_2=...=\lambda_r>...>\lambda_n$
则$B$的特征值就是:
$\lambda_1-p=\lambda_2-p=...=\lambda_r-p>...>\lambda_n-p$
而$A,B$的特征向量都是相同的。
注意!这里与上面假设不同,这里没有绝对值了。那么即使经过数量阵相加,特征值的大小关系还是不变的。用$B$迭代出特征值后再加回$p$即是$A$的特征值。
对于$B$,我们要:
1、保持$\lambda_1-p$的绝对值在$B$中依旧是最大,对$B$进行迭代才能算出最大特征值。
2、由于我们想要减小$B$的迭代比值:
$\frac{|\omega|}{|\lambda_1-p|},\omega=\max\limits_k(|\lambda_{k}-p|),(k=r+1,...,n)$
实际上,我们可以推断$\omega$只会取为$\lambda_{r+1}-p$或是$\lambda_{n}-p$(画个数轴就能判断),而当:
$p=\frac{\lambda_{second\,biggest}+\lambda_n}{2}=\frac{\lambda_{r+1}+\lambda_n}{2}$
数轴上$p$在$\lambda_{r+1}和\lambda_{n}$中间:(图中假设$r=1$)

有$\lambda_{r+1}-p = -(\lambda_{n}-p)$,此时$B$的迭代比值最小,为:
$\left|\frac{\lambda_{r+1}-\lambda_n}{2\lambda_{1}-\lambda_{r+1}-\lambda_{n}}\right|$
迭代速度达到最快,而$p$再小或再大都会使迭代速度减慢。
另外,当$p=\frac{\lambda_1+\lambda_{second\,smallest}}{2}$,还可以求$B$(或$A$)的最小特征值。实际上,通过平移,幂法可以求的就是在数轴两端的特征值。
在实际应用中,$A$的特征值并不知道,所以$p$是不能精确计算的,这个方法告诉我们,当发现收敛速度很慢时,我们可以适当地变动一下加速收敛。
加速python代码
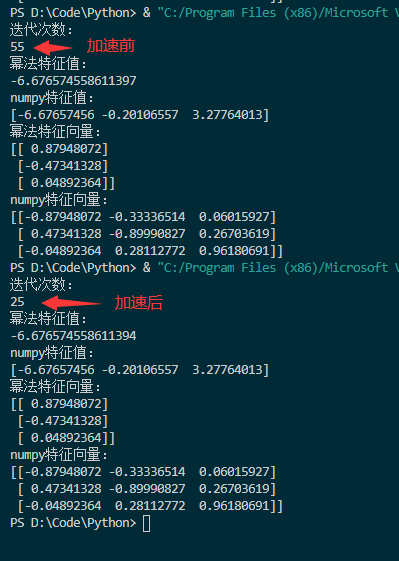
代码加速迭代计算最小特征值(负数,绝对值最大),加速前迭代55次,加速后迭代25次,速度提升约50%。
import numpy as np p = (-0.20106557+3.27764013)/2#p的大小 #矩阵A A = np.matrix( [[-5.6,2.,0.], [3.,-1.,1.], [0.,1.,3.]]) A = A-np.eye(3)*p #平移 L0=2#范数类型 v = np.matrix([[-2.],[-7.],[1.]])#v0 u = v/(np.linalg.norm(v,L0))#u0 #迭代函数 def iterate_fun(A,v,u,L): i=0 former_v = -1 after_v = -1 isPositive = 1 while True: i=i+1 former_v = np.linalg.norm(v,L) v = A*u after_v = np.linalg.norm(v,L) if former_v-after_v==0.: if u[0]*v[0] < 0: isPositive = -1 break u = v/(np.linalg.norm(v,L)) print("迭代次数:") print(i) print("幂法特征值:") print(isPositive*np.linalg.norm(v,L)+p) print("numpy特征值:") print(np.linalg.eig(A+np.eye(3)*p)[0]) print("幂法特征向量:") print(u) print("numpy特征向量:") print(np.linalg.eig(A+np.eye(3)*p)[1]) iterate_fun(A,v,u,L0)
结果截图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号