
A High Compression Efficiency Hardware Encoder for Intra and Inter Coding With 4K@30fps Throughput
目录
0 概述
复旦范老师团队的论文,主要介绍了一种新的硬件编码器,该编码器支持HEVC标准,能够实现高效的视频编码,具体包括对内编码和外编码的支持。文中提出了一系列硬件导向算法,以减少编码器模块之间和内部的数据依赖性,降低计算复杂度,同时保持可接受的压缩效率。通过采用统一的4×4引擎、二维数据重用以及时间调度等设计,最终实现了在GF 28nm工艺下以3154K门数和1.02MB内存占用,达到4K@30fps的编码速度。
1 基于硬件的算法优化
1.1 Intra Mode Decision
HM 15.0中,PU的帧内模式决策过程由两个部分组成:模式列表的选择和模式的决策。RMD选择一定数量的模式,这些模式与最有可能的模式(MPM)一起用于形成亮度模式列表。然后,RDO从亮度模式列表中决定最佳亮度模式,并基于最佳亮度模式创建一个色度模式列表(派生色度模式)。最后,RDO评估色度模式列表以做出色度模式的决策。上述过程存在许多依赖关系,数据流不规则。
A、模式列表的选择
为了降低复杂度并保持数据流一致,编码器在进入RDO(率失真优化)之前,会为每个预测单元(PU)统一建立一个亮度模式列表,其中包含固定的DC和平面模式及通过RMD(粗略模式决策)筛选出的角度模式。为减少计算量,RMD不再依赖RDO的速率估计,而是仅用原始像素和SATD失真作为判断依据,并通过4×4块的累积代价代替大块计算,从而降低硬件资源需求。最终,这些优化在保持视频质量基本不变的前提下,实现了复杂度与性能的平衡。
B、基于扩展色度候选的RDO模式决策
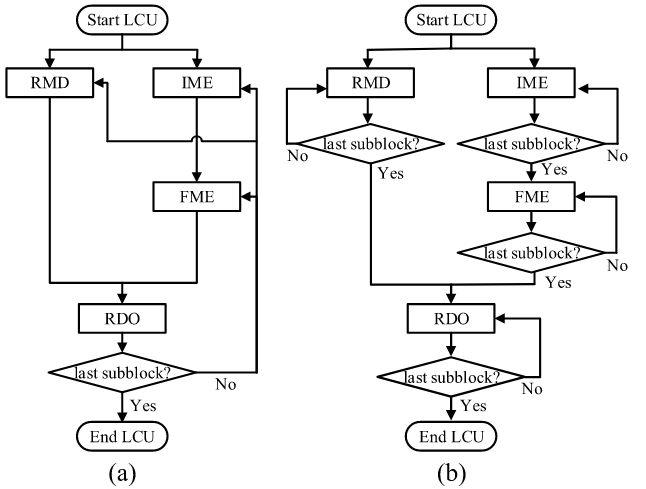
重点在于消除亮度(Luma)和色度(Chroma)模式决策之间的数据依赖,从而提升并行性与效率。传统的RDO过程包括预测、变换、量化、反量化、反变换等步骤,最终根据率失真代价(RD Cost)来选择最优模式。然而,在传统流程中,色度模式的推导依赖于亮度模式的最终决策,因此必须等待亮度模式选定后才能启动色度部分的RDO。这种依赖关系导致了数据等待和额外的处理延迟,限制了编码的并行性和吞吐量,如虚线箭头所示,这导致了数据依赖性和RDO决策中的额外延迟。。
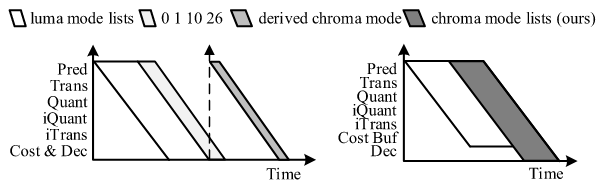
为了解决RDO中的数据依赖问题,提出了一种模式决策算法。核心思想是:提前构建色度模式列表,而非在亮度模式确定后再生成。具体而言,由于色度模式通常是亮度模式集合的一个子集,算法基于亮度模式列表预先形成色度模式列表,使其不仅包含常规的四种色度模式,还包括来自亮度模式列表的所有候选模式。这样,色度预测不再依赖于亮度模式的最终选择,从而实现了并行处理。
在RDO流程上,算法通过引入一个代价缓冲区(Cost Buffer)来协调亮度与色度模式的代价计算。当亮度模式被处理时,其率失真代价会被暂存到缓冲区中,而不是立即做出决策。随后,算法计算色度模式的代价,并将这些代价与缓冲区中对应亮度模式的代价相加,得到综合的总代价。最终,RDO根据这一整体代价同时决定最优的亮度和色度模式。通过这种机制,算法打破了传统RDO中的数据依赖关系,实现了更高效的模式决策。
1.2 Inter MV Pre-Selection
IME和FME依赖于从RDO决策中推断出的MVP。消除模块之间的这种依赖将显著影响编码器的压缩效率。一方面,在IME和FME中,运动向量差(MVD)是基于MVP计算的。MVD在帧间编码中的代价贡献相当大,有时甚至超过系数部分。另一方面,MVP还可以作为运动估计的搜索中心,从而改善搜索结果。为了解决这些挑战,我们提出了近似MVP算法和一种新的FME搜索算法。
A、基于FME生成的FMV和RDO生成的FMV的近似MVP
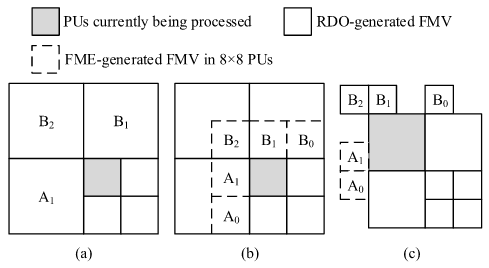
(a)当FME处理灰色PU时,MVP候选者已经通过周围PU的RDO过程确定。FME能够获取准确的MVP候选者。也就是说,MVP 的生成依赖于已知的相邻 PU 信息,因此可以获得准确的预测向量;但在实际硬件中,由于流水线分离(FME 和 RDO不同步),在FME阶段无法获得最终的PU分区和模式信息,从而导致 MVP 候选不准确,影响预测精度。
(b)当处理当前的8 × 8 PU时,周围的8 × 8 PUs已经完成了FME过程。因此,这些FME生成的FMVs可以用于生成当前8 × 8 PU的近似MVP候选。此外,当当前PU位于LCU的上边界时,上方的LCUs已经完成了RDO过程,它们生成的RDO FMVs可用于生成MVP候选。也就是说,在硬件实现中,由于FME阶段无法获得最终RDO结果,为了生成尽可能准确的MVP,采用了混合策略:
- 从同一LCU内已完成FME的相邻PU提取FMV → 得到近似MVP候选A;
- 从上一LCU已完成RDO的PU提取RDO FMV → 得到精确MVP候选B。
最终当前PU可以基于这两个方向的候选向量,形成其运动矢量预测集合。
(c)中展示了左上角的16 × 16 PU的一个样例。左侧的候选项标记为A,是基于FME生成的MV形成的,而上方的候选项标记为B,则可以通过RDO生成的MV形成。
B、FME中的两步搜索算法
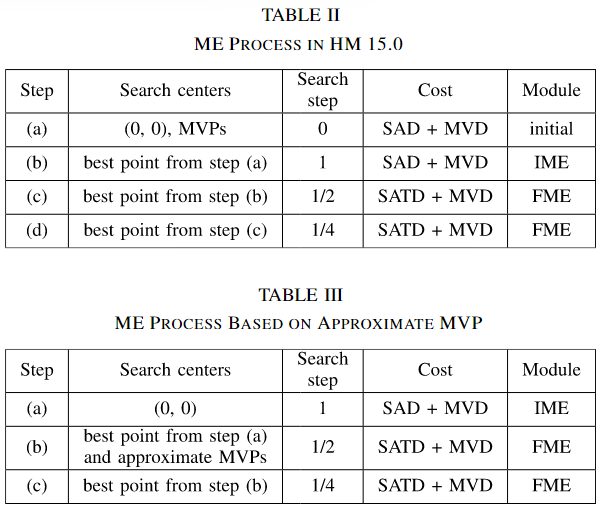
HM中,运动估计过程遵循表II中列出的步骤:
(a) 初始基于SAD的选择(Initial SAD-based Selection)
- 从三个候选搜索中心中选一个最佳:
- (0, 0)
- MVP_A(预测向量A)
- MVP_B(预测向量B)
- 目的是选择一个最优的起点,让后续搜索更高效。
(b) IME(Integer Motion Estimation,整数像素运动估计)
- 以步骤(a)选出的最佳点为中心,搜索整数像素级最优MV(IMV)。
(c/d) FME(Fractional Motion Estimation,亚像素运动估计)
- 以IMV为中心,先做1/2像素插值搜索,再做1/4像素插值搜索,最终得到高精度MV。
在软件仿真中(如HM),所有宏块(LCU)是按顺序编码的,前一个块的MV已计算完毕,因此可以用作当前块的MVP。
但在硬件实现中(例如ASIC或FPGA),LCU通常采用流水线架构(pipeline)来提升吞吐率。这意味着:①不同LCU或CU可能并行处于不同处理阶段(预测、变换、熵编码等)。②当前LCU在进行运动估计时,相邻LCU的MV可能尚未计算完成;③因此,来自左侧(A)或上方(B)块的MVP信息在此时不可用。也就意味着由于LCU流水线的数据时序限制,MVP尚未产生,所以依赖MVP的步骤(a)无法执行从而导致(a)在硬件中“不可用”。
为应对MVP不可用的问题,提出了一种近似MVP策略,并对FME搜索流程进行了修改(表III):
- 在IME阶段,不再使用步骤(a)中的初始SAD选择,而是固定使用(0, 0)作为搜索中心。
- 在FME阶段,先用1/2像素插值评估IMV和两个近似MVP,再进行1/4像素精化。
- 同时采用SATD代价代替SAD,提高精度。
这样,算法就摆脱了对“真实MVP”的依赖,适应了硬件流水线时序。
1.3 基于系数复杂性的快速Rate Estimation
速率估计(Rate Estimation)是RDO中的“码率预测器”, 它在不真正熵编码的情况下,快速估算当前编码模式将产生的比特数,让编码器能在众多候选方案中高效找到最优的“率失真折中点”。
速率估计涉及两个方面:头部和系数估计。最复杂的部分是系数的估计。从定性上看,TU(Transform Unit)中系数的复杂性可以通过两个因素来表征:
- 系数幅度:由于CABAC对幅度较大的系数编码更多的语法元素,并且在系数足够大的情况下通常会采用Golomb编码,因此更大的幅度通常会导致更高的比特率。
- 系数位置:由于离散余弦变换(DCT)的影响,非零系数的概率随着它们离原点(即直流点)距离的增大而减少。在CABAC中,概率较低的语法元素会导致更高的比特率。因此,非零系数离直流点越远,比特率越大。
基于上述分析,采用“绝对值加权和”作为表示系数复杂度的计算方法。其计算公式如下:
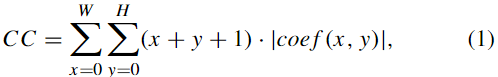
其中 CC 代表系数复杂度,W 和 H 分别代表 TU 的宽度和高度。变量 x 和 y 表示 TU 中当前系数的水平和垂直坐标。函数 coef (x, y) 表示位置 (x, y) 处的系数。
A、速率拟合模型
在确定系数复杂度 CC 后,用以下经验公式拟合速率:
$R=a⋅CC^b+c$
- R:拟合速率
- a, b, c:拟合参数
- 不同TU大小、通道和帧类型对应不同参数,因为它们影响CABAC上下文计算,从而影响速率。
B、硬件实现优化
直接使用公式$CC^{0.6}$在硬件上实现会面临查找表(LUT)深度过大的问题,这里的0.6是经验值,与实际比特率最匹配:
- 32×32TU系数复杂度通常需要 4 位整数 + 10 位小数的定点类型 → 查找表深度达 $2^{14}$,实际不可行。
为解决这一问题,将$CC^{0.6}$的计算分解如下:
- 二进制科学记数法表示$CC = t \cdot 2^n, \quad t \in [1, 2), n \in \mathbb{Z}$$CC^{0.6} = t^{0.6} \cdot 2^{0.6 n}$
- t部分查找表
- t在固定范围内,可接受一定误差;
- 实测8位查找表足够 → LUT深度仅需 256。
- n部分移位实现
- n为整数,$2^{0.6 n}$可通过移位和少量乘法实现(例如$2^{0.0}, 2^{0.2}, 2^{0.4}, 2^{0.6}, 2^{0.8}$移位组合)。
最终,将原本需要深度为$2^{14}$的查找表,替换为8位LUT + 定点乘法 + 移位操作,大幅降低硬件复杂度。
1.4 简化Merge Mode Estimation以减少硬件开销
HEVC中,为了减少AMVP(高级运动向量预测)带来的比特开销,引入了合并模式(Merge Mode)。MME(Merge Mode Estimation)用于从合并列表中估计运动向量(MV)。
- 在硬件实现上,有两种常用策略:
- 基于ME搜索点评估合并候选
- 优点:无需单独的MME引擎
- 缺点:BD-Rate增加约5.25%(HM 15.0实验结果)
- 设计独立MME引擎
- 优点:消除BD-Rate损失
- 缺点:增加硬件开销,引入RDO-合并列表依赖
- 基于ME搜索点评估合并候选
核心问题:独立MME引擎虽然精度高,但硬件复杂度大;而仅用ME搜索点评估虽然硬件简单,但编码效率下降。
A、提出的简化合并模式估计算法
目标:在两种方法之间取得平衡,兼顾硬件效率和编码性能。
- 大PU(等于LCU大小)的处理
- 合并候选的构建与当前LCU的模式决策之间无依赖
- 对所有合并候选进行RDO评估
- 优点:无需MME引擎,无流水线气泡
- 小PU(小于LCU大小)的处理
- 避免遍历所有合并候选,防止额外流水线气泡
- 例外:如果FME(最终运动估计)得到的FMV(最终运动向量)在合并候选中,则可视为合并模式
- 优点:仍保持较低硬件开销,同时保留关键合并模式
消除了RDO中对独立MME引擎的需求、避免了大量硬件复杂性、在保证流水线效率的同时,尽量保留编码性能。
2 提出的硬件架构设计
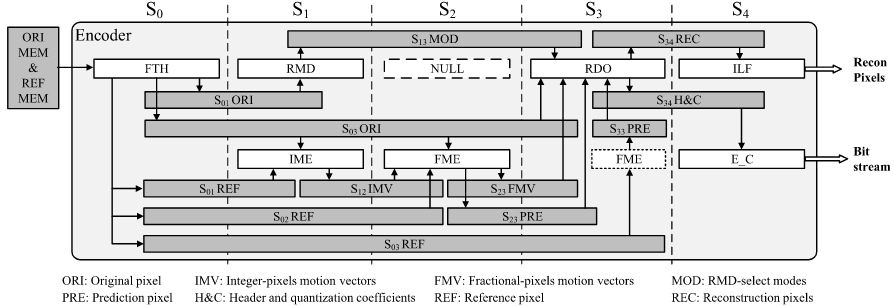
2.1 基于统一4×4引擎的RMD
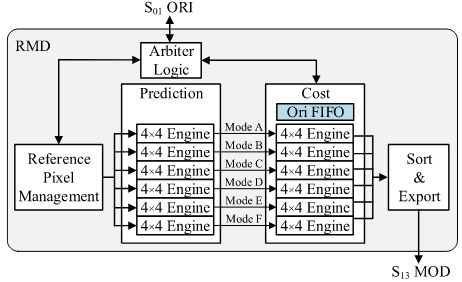
传统上,为不同大小的预测单元(PU, Prediction Unit)分别设计独立的预测与代价计算引擎,会显著增加硬件面积与功耗。为了解决这一问题,RMD 采用了统一的 4×4 引擎结构,即无论 PU 的尺寸大小如何,都以 4×4 块为最小处理单元进行预测与代价计算。较大的 PU(如 8×8 或 16×16)会被划分为若干个 4×4 子块,每个子块由独立的 4×4 预测引擎和 4×4 SATD 引擎处理,从而实现模块化、可复用的硬件设计,显著减少电路面积开销。
在实现层面上,RMD 的控制逻辑被划分为三个循环层次。第一级循环遍历不同的 PU 大小,第二级循环遍历每个 PU 内部的所有 4×4 块,这两个层次均采用串行方式执行;第三级循环则针对每个 4×4 块遍历其 33 种角度预测模式。为了满足吞吐率要求,RMD 在第三级循环中采用并行处理结构,利用 6 个并行的 4×4 引擎同时计算不同角度模式的预测代价。通过这种“外层串行、内层并行”的架构,系统既能保持较小的硬件面积,又能在高性能要求下实现足够的运算吞吐量。
2.2 原始像素访问冲突与重排序
在 RMD 过程中,RPM 模块使用原始像素生成“参考像素”(reference pixels),而代价计算模块使用相同的原始像素计算 SATD 代价。理论上,这两个模块都需要频繁访问原始像素。若同时运行,就需要两个独立的 S01 ORI 缓冲区(每个 S01 ORI 可存储两个 LCU 大小的原始像素)。然而,维护两个缓冲区会显著增加存储资源开销;若仅保留一个缓冲区,又会导致两个模块在访问原始像素时产生冲突。为此,设计中提出了一种基于三级循环层次的重排序策略,通过调整 PU、块和模式的遍历顺序,避免访问冲突,从而仅使用一个 S01 ORI 即可实现无冲突的并行访问。
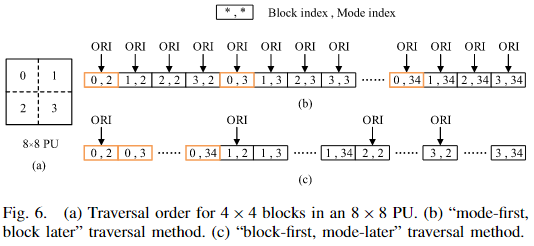
A、传统遍历方式与冲突问题
以 8×8 PU 为例,它由四个 4×4 块组成,通常按照锯齿形顺序遍历。每个 4×4 块都需要处理 33 种角度预测模式。
软件实现中通常采用“先模式、后块”的遍历方式:
- 先固定一个模式,对该 PU 的四个 4×4 块依次计算代价;
- 然后切换到下一个模式,重复以上过程。
在这种模式下:
- 当 RMD 模块切换块大小(PU 切换)时,RPM 需要访问原始像素;
- 当代价模块计算每个块的 SATD 时,它也会访问原始像素。
这导致两个模块会在不同循环层次同时访问同一原始像素缓冲区,从而产生访问冲突。
B、重排序方案:块优先策略
为解决冲突,本文提出了“块优先,峰值后处理(block-first, peak-postprocessing) ”的遍历策略。
具体做法是:
- 将同一个 4×4 块的所有模式计算聚集在一起,依次完成;
- 再切换到下一个 4×4 块。
通过这种方式:
- 每个 4×4 块的原始像素只需在第一次模式计算时读取一次;
- 后续模式的计算可直接复用缓存结果,无需重复访问原始像素;
- 从而彻底消除 RPM 与代价模块之间的原始像素访问冲突。
C、吞吐量分析与硬件优化
为验证重排序不会降低吞吐量,分析了 PU 访问像素与处理周期的关系。 RMD 每个周期可访问一个 4×4 块的像素,即 16 个像素。 对于一个 N×N PU:访问“参考像素”需 N+1 个周期;访问原始像素需 N²/16 个周期。
当 N=4 且并行引擎数 N_parallel=6 时,读取参考像素需要 5 个周期,读取原始像素需要 1 个周期,整个 PU 过程约为 6 个周期。由此可见,像素读取不会阻碍整体处理吞吐量,无需增加额外的原始像素缓冲区。
此外,为进一步避免在同一周期内同时访问原始像素与参考像素,代价模块中引入了一个 FIFO 缓冲区。
该 FIFO 每个地址可存储 16 个像素,深度为 3,可完全覆盖并行访问期间可能产生的读冲突。
2.3 IME与二维数据重用
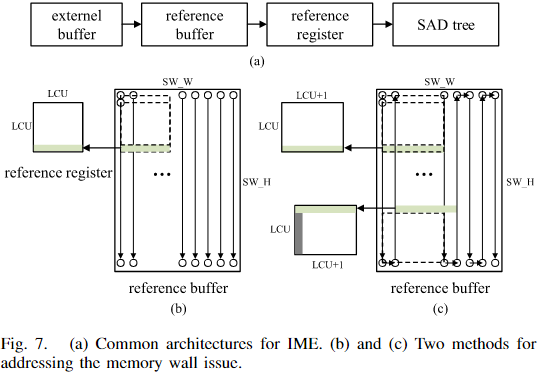
A、传统IME架构及存储墙问题
IME(整数运动估计)的典型硬件架构如图7(a)所示。系统从外部存储的重建帧中提取参考窗口像素,通过参考寄存器提供给SAD树进行代价计算。尽管SAD计算可以并行执行,但由于SRAM在单周期内只能访问同一地址,参考像素的寄存器加载仍需多周期完成,形成存储墙(Memory Wall) ,显著限制IME吞吐量。传统缓解方法包括参考帧压缩与Level D数据重用,但仍难以彻底消除存储墙。
B、典型优化方案
图7(b)和7(c)展示了两种缓解存储墙的方案:
- 光栅顺序SRAM(图7b)
- 搜索窗口像素按光栅顺序存储在SW_W × SW_H的SRAM中。
- 垂直移动(搜索点上下):相邻像素位于SRAM同一地址列,可在单周期内更新参考像素。
- 水平移动(搜索点左右):相邻像素位于不同地址行,寄存器阵列需重新加载整列像素,耗时多周期。
该差异源于SRAM地址连续性,寄存器初始化周期数取决于“需加载参考像素数量”和“SRAM单次访问效率”。
- 扩展寄存器阵列+蛇形搜索(图7c)
- 将寄存器阵列宽度扩展至 LCU+1,配合蛇形搜索模式,左右移动时无需额外初始化周期。
- 当搜索高度小于LCU尺寸时,仍会保留部分旧像素(灰色区域),向右移动搜索点时需重新初始化,效率受限。
C、提出的二维数据重用架构
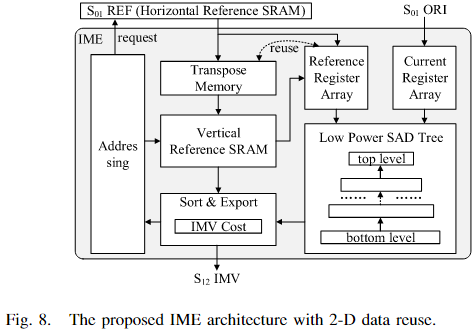
为彻底解决存储墙问题,提出了二维数据重用IME硬件架构(图8),特点如下:
- 参考SRAM模块
- 水平参考SRAM(HRS) :光栅顺序存储参考窗口像素。
- 垂直参考SRAM(VRS) :通过转置机制从HRS读取数据,实现垂直访问优化。
- 寄存器阵列模块
- 当前寄存器阵列(CRA) :存储原始像素。
- 参考寄存器阵列(RRA) :支持转置与刷新,确保任意方向移动时单周期获取参考像素。
- SAD计算与决策模块
- SAD树:单周期并行计算所有PU尺寸的SAD代价。
- 排序与导出单元:结合SAD代价和IMV代价选择最优IMV。
架构特点:
- HRS/VRS与CRA完成初始化后,RRA可在任意方向移动时单周期获取新参考像素。
- RRA的转置功能保证寄存器刷新仅需单周期。
- 寄存器阵列仅在搜索模式切换时需要重新初始化,从根本上消除了存储墙,显著提升IME吞吐量。
2.4 带有转置缓冲区和重排序的FME
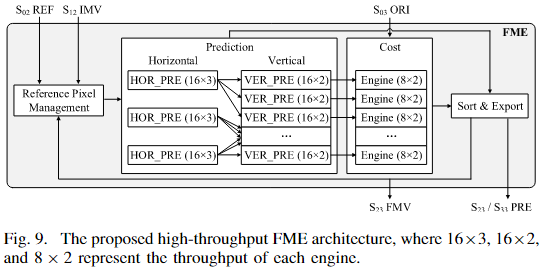
FME(Fractional Motion Estimation)硬件架构如图9所示,由四个主要模块组成:参考像素管理(RPM)、预测模块、代价模块和排序与导出模块。其核心处理流程如下:
- 参考像素获取:RPM根据搜索中心请求参考像素。FME以 8×8 块为单位处理,每个 8×8 块对应 RPM 输出 16×16 的参考像素供预测模块使用。
- 预测生成:预测模块执行插值,为每个 8×8 块生成九个邻域的预测像素。
- 代价计算:代价模块使用 SATD 计算代价,并为 MVD 提供速率估计。
- 排序与导出:排序与导出模块生成最佳 FMV,该 FMV 可输出至 RPM 进行 MVP 计算,或写入外部旋转缓冲区。
为了优化预测模块和减少内部空闲时间,FME引入了转置缓冲区(TSPS)和重排序策略。
A. 预测模块中的 TSPS
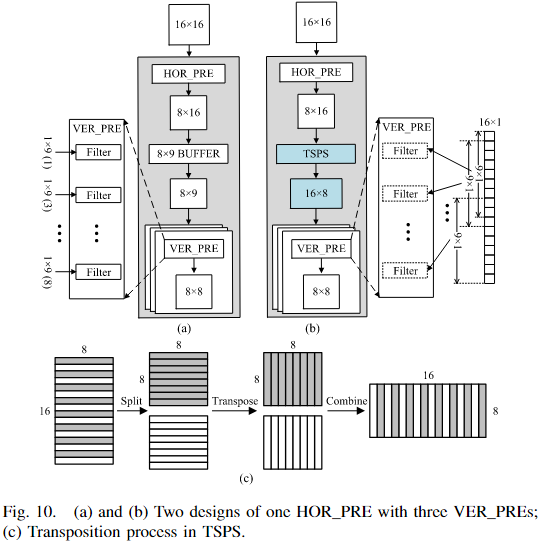
预测模块插值流程:
- 三个 HOR _PRE 水平方向插值搜索中心,输出 8×1 块。
- 输出通过三个 VER _PRE 垂直方向插值,生成九个邻域预测像素。
问题:HOR_PRE 输出需要至少 8×9 缓冲区才能开始垂直插值,但直接缓冲会导致 VER_PRE 访问不完整的参考列,从而减少可重用部分,是 FME 面积瓶颈。
解决方案:采用 TSPS 缓存 HOR_PRE 输出的 8×16 块,然后顺序转置为 16×8 块并输出,使 VER_PRE 能够访问重叠输入,实现滤波器重用。
- TSPS 转置流程(图10c):
- 将矩形块奇偶分成两个方阵
- 利用寄存器阵列对方阵进行转置
- 合并转置后的方阵输出
B. FME 中的重排序
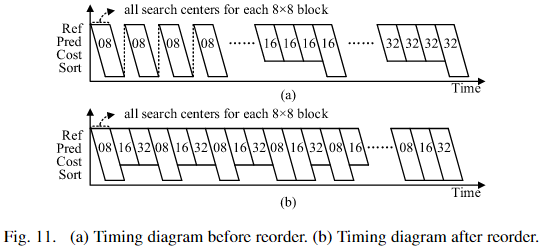
FME 的处理顺序涉及 PU 大小、8×8 块和搜索中心,如图11a 所示。由于近似 MVP 算法,8×8 PU 切换时存在数据依赖,产生大量空闲周期(气泡)。
解决方案:重排 8×8 块的处理顺序,将 16×16 和 32×32 PU 中的 8×8 块插入空闲周期,充分利用气泡(图11b)。
- 最终遍历顺序:
- 8×8 块
- PU 大小
- 搜索中心
- 为收集不同 PU 大小“打破”的代价,代价模块设置两个分离缓存。
- 每次插值周期缩短至 6 个周期。
2.5 RDO的高效时序调度策略
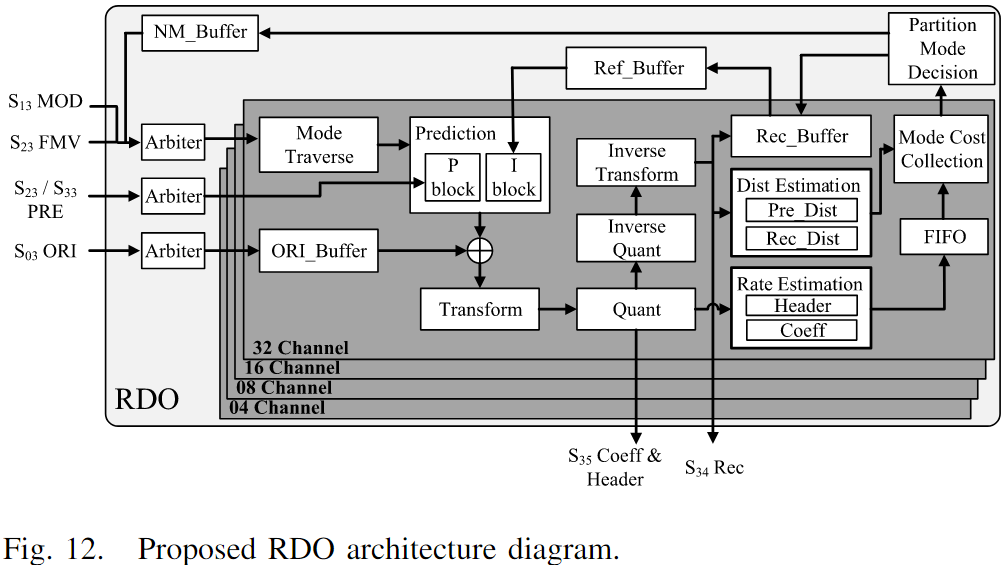
图12展示了用于 RDO 的完全并行硬件架构。由于不同 PU 大小之间的最小依赖性,设计采用四个通道(04/08/16/32)并行处理四种不同 PU 大小。
- 色度处理:编码器支持 YUV420 格式,对于 PU 大小超过 4 的块,其色度在较低维度通道处理。例如,8×8 PU 的亮度在 08 通道处理,降维后的色度在 04 通道处理。
- 模式遍历:每个通道的模式遍历模块负责启动后续模块的模式计算,并输出最优预测模式(MPM)、最优运动向量(MVP)及合并列表。
- 预测与残差计算:预测模块执行帧内/帧间预测,残差通过 ORI 缓冲区计算,并经过变换、量化、逆量化及逆变换生成量化系数与重构像素。
- 速率与失真估计:速率估计模块使用量化系数和模式信息计算速率代价;失真估计模块包括预失真(Pre_Dist)和重构失真(Rec_Dist)两部分。
- 模式代价收集:收集分散的色度模式的 RD 代价,确保划分峰值决策模块可以做出最佳模式和 PU 划分决策。
重构环设计中,04 通道为时序瓶颈,吞吐量为每周期 16 个像素,其余通道为每周期 8 个像素。Ref_Buffer 和 NM_Buffer 存储下一个 PU 所需信息,消除了相邻 PU 之间的依赖。RDO 的主要时序瓶颈集中在决策过程中。
A. 调度优化帧内编码
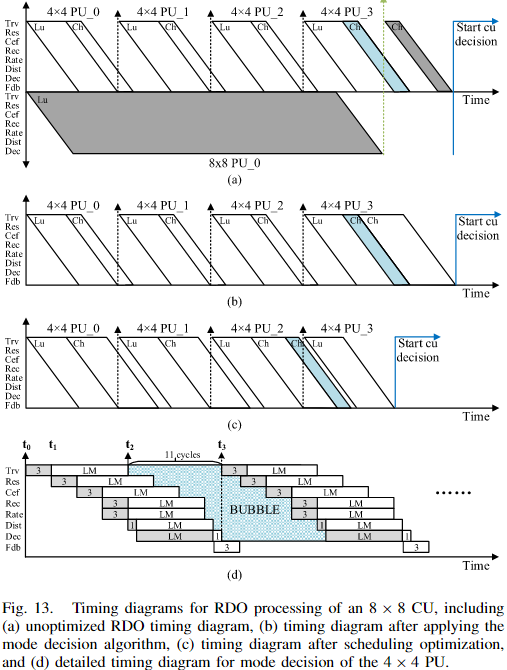
图13展示了 8×8 CU 的 RDO 时序:
- 流水线阶段包括模式遍历(Trv)、预测和残差计算(Res)、变换与量化(Cef)、逆量化与逆变换(Rec)、速率估计(Rate)、失真估计(Dist)、模式与划分决策(Dec)、以及缓冲区反馈(Fdb)。
- 问题:4×4 PU 的亮度决策之间存在气泡,同时色度模式依赖于最佳亮度模式,导致 8×8 PU 的色度模式延迟。
- 解决方案:
- 扩展亮度模式列表至色度模式列表,消除依赖。
- 调度策略将 4×4 和 8×8 PU 的色度模式安排在前三个气泡中(图13c),充分利用空闲周期。
- 效果:04 通道的代价评估周期从 1728 减少至 1280,总 RDO 过程在最坏情况下仅需 1940 个周期。
B. 预插值策略
- 问题:未优化时,运动矢量插值和残差获取涉及 Ref、Hor Pred、TSPS 和 Ver Pred,引入显著延迟,尤其在帧间编码中。
- 策略:在流水线 S2 阶段,FME 对最佳 FMV 再次插值生成亮度和色度预测像素,并写入 S23 PRE,以提前提供残差数据。
- 效果:显著缩短帧间编码 RDO 的处理时间。
C. 系统级流水线借用策略
- 问题:对于 LCU 级 PU,RDO 需遍历所有 MME 合并模式,需要插值引擎,引入面积和延迟开销。
- 策略:FME 与 RDO 共享流水线,借用 FME 处理合并列表:
- FME_a / FME_b:计算最佳 MV 并生成预测像素。
- RDO 读取 S33 PRE 获取预测像素,同时处理合并列表外的模式。
- 流程重复用于后续 LCU,消除对独立插值引擎的需求。
- 效果:32 通道的延迟消除,同时减少逻辑资源开销,无需额外插值引擎即可完成合并模式预测。
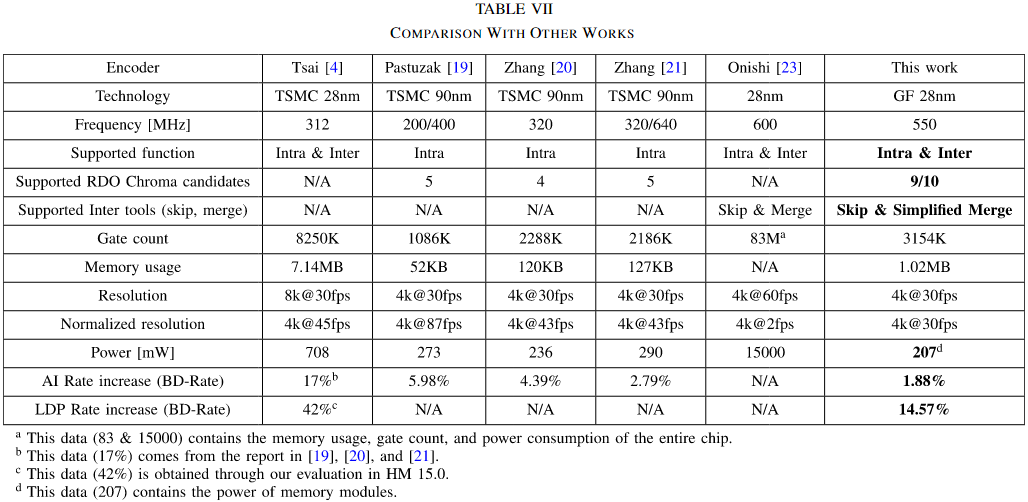
最终结果是支持Intra和Inter,能够满足4K@30fps

 浙公网安备 33010602011771号
浙公网安备 33010602011771号