
【深度学习】word2vec 中的数学原理详解
https://www.cnblogs.com/peghoty/p/3857839.html
推荐度max,word2vec 中的数学原理详解。
https://cloud.tencent.com/developer/article/1010918
Tensorflow实现word2vec
https://www.cnblogs.com/pinard/p/7278324.html
gensim 有个word2vec API,你可以直接用人家的word2vec。(pip install jieba & gensim. 已经实战过了gensim_word2vector)
word2vec是2013年Google开源的一个word embedding工具。word2vec工具主要包含两个模型:跳字模型(skip-gram)和连续词袋模型(continuous bag of words,简称CBOW),以及两种高效训练的方法:负采样(negative sampling)和层序softmax(hierarchical softmax)。
CBOW输出层对应的一棵二叉树。Huffman树。叶子节点N个,对应词典的N个词语,非叶子节点N-1个
Hierarchical softmax 是提高性能的一项关键技术。要了解一下huffman树编码,根据词频,高频的一般会短。上文中例子,“足球”编码是1001。(图11)
从根节点出发到叶子节点,经历4次二分类。约定左边是负类,右边是正类。
即然是一个二分类问题,通过逻辑回归,

然后你就可以推似然函数(4.4)
如何优化,如何最大化这个函数,用随机梯度上升法。
后来又提出了个negative sampling。不用huffman树啦,能大幅提高性能。随机负采样是NCE的一个简化版本。
看看Hierarchical Softmax的的缺点。的确,使用霍夫曼树来代替传统的神经网络,可以提高模型训练的效率。但是如果我们的训练样本里的中心词𝑤是一个很生僻的词,那么就得在霍夫曼树中辛苦的向下走很久了。能不能不用搞这么复杂的一颗霍夫曼树,将模型变的更加简单呢?
通过负采样,我们得到了neg个负例(𝑐𝑜𝑛𝑡𝑒𝑥𝑡(𝑤),𝑤𝑖)𝑖=1,2,..𝑛𝑒𝑔。为了统一描述,我们将正例定义为𝑤0。

和Hierarchical Softmax类似,我们采用随机梯度上升法,仅仅每次只用一个样本更新梯度,来进行迭代更新得到我们需要的𝑥𝑤𝑖,𝜃𝑤𝑖,𝑖=0,1,..𝑛𝑒𝑔
负样本那么多,怎么选择呢?用词频加权,高频词选为负样本的概率就比较大。
word2vector对高频词和低频词都做了一定的处理,
低频词:不会把语料小于min_count的词收录到词典里。
高频词:“的”“是”,这些词对应的词向量训练不会发生显著改变。用subsampling技巧,高频词按照一定概率被舍弃。公式(6.2)。
模型训练按照行的,语料文件每行存一个句子。太长(超过MAX SENTENCE LENGTH 默认100)会被截断。
源码里采用了自适应学习率。默认初始0.025,每处理完10000个词,会变小。小于10-4,就不会继续小了。
参数初始化问题,逻辑回归对应0初始化,词向量采用随机初始化。
word2vec的代码实现和文章有一些出入。
每个单词有两个向量:
1.一个表示这个词作为中心词 (Focus Word)时的向量。syn0数组,负责某个词作为中心词时的向量。是随机初始化的。所以word2vec其实并没有用one-hot编码。
2.一个表示它作为另一个中心词的上下文(Context Word)时的向量。syn1neg数组,负责这个词作为上下文时的向量。是零初始化的。
网上一些简化版的直观理解:
首先Wordvec的目标是:将一个词表示成一个向量
假设语料库有10个词: 【今天,我,你,他,小明,玩,北京,去,和,好】
今天 我 和 小明 去 北京 玩
对于小明而言,选择他的前三个词和后三个词作为这个词的上下文。 将这6个向量作为输入,即
X = [1, 1, 0, 0, 0, 1, 1, 1, 1, 0]
输出层期望的数据实际就是小明这个词构成的向量(可以认为是训练数据的标签) 即
小明 :[0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
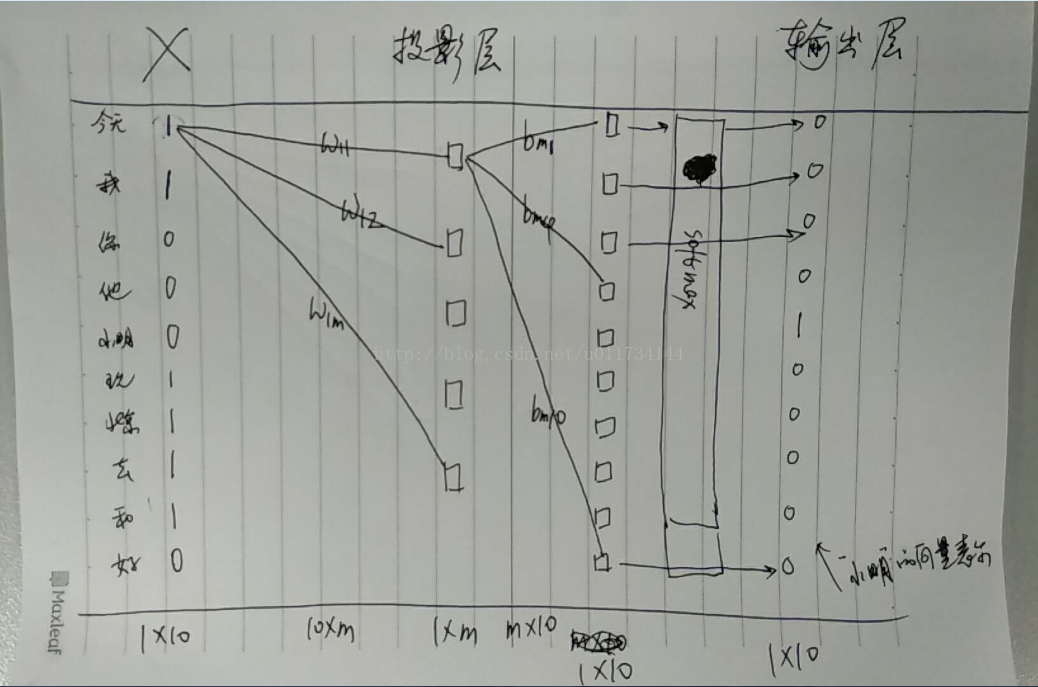
这样最终的输出层的维度1*10 = (1*10) * (10*m) * (m*10)
为了加快训练速度,可以一个批次一起训练,将多个句子的损失函数求和来训练
最终训练结束后,就要将一个词表示成一个向量,那么怎么表示呢?
输入X中第一个元素的值为1, 这表示的其实就是“今天” 这个词,那么“今天”就用它对应的连线上的权重参数来表示
今天 = [w11, w12... w1m]
我 = [w21, w22... w2m]
其实理解了CBOW模型后,要理解Skip-gram模型就非常简单了,CBOW模型是用词的前后几个词来预测这个词,而Skip-gram模型则是用一个词来预测他周围的词。
Skip-gram模型最终的结果是将小明表示成一个向量,而CBOW模型是将“小明”前后三个词表示成向量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号