Q函数和值函数
Q函数:奖励和
总奖励是在状态st采取行为at的奖励的期望和
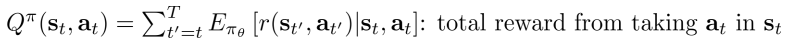
值函数:奖励和
总奖励是在状态st下获得的奖励的期望和
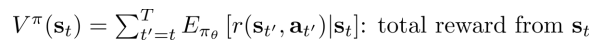
下面是值函数另外的定义,在at行为下采取策略 的Q函数的期望
的Q函数的期望
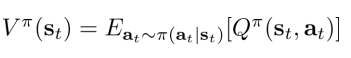
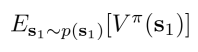 是RL的目标函数,我理解为在s1状态下转移到其他状态的概率p(s1)的值函数
是RL的目标函数,我理解为在s1状态下转移到其他状态的概率p(s1)的值函数![]() 的期望
的期望
使用
方法1:如果知道策略 和
和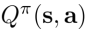 ,那么就可以改进策略:
,那么就可以改进策略:
如果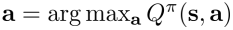 ,则设置策略
,则设置策略
该策略至少和之前的策略 一样好,甚至更好
一样好,甚至更好
方法2:计算策略去提升好的行为a的概率:
如果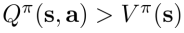 ,则a比平均值更好。然后就改进策略
,则a比平均值更好。然后就改进策略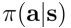 提高行为a的概率
提高行为a的概率

 浙公网安备 33010602011771号
浙公网安备 33010602011771号