强化学习理论-第9课-策略梯度方法
1. Basic idea of policy gradient
之前的策略都是用表格表示的,现在改成函数的形式描述策略





2. Metric 1 - Average value




3. Metric 2 - Average reward








4. Gradients of the metrics





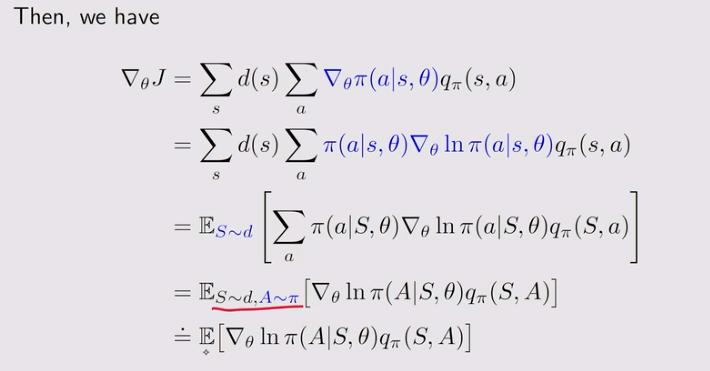


5. Gradient-ascent algorithm(REINFORCE)








def reinforce(self, learning_rate=0.001, epochs=20000, episode_length=100):
policy_net = PolicyNet()
optimizer = torch.optim.Adam(policy_net.parameters(),
lr=learning_rate)
for epoch in range(epochs):
# start_state = 0
# y, x = self.env.state2pos(start_state) / self.env.size
#将起始状态 (0, 0) 输入到策略网络中,得到动作概率分布 prb
#torch.tensor((0, 0)): 创建一个形状为 (2,) 的张量
#.reshape(-1, 2): 转换为形状 (1, 2),符合网络输入格式
#policy_net(...): 前向传播,输出每个动作的概率分布
#[0]: 取出第一个(也是唯一一个)batch 的结果
prb = policy_net(torch.tensor((0, 0)).reshape(-1, 2))[0]
#根据概率分布选择起始action
start_action = np.random.choice(np.arange(self.action_space_size),
p=prb.detach().numpy())
episode = self.obtain_episode_p(policy_net, 0, start_action)
if (len(episode) < 10):
g = -100
else:
g = 0
optimizer.zero_grad()
for step in reversed(range(len(episode))):
reward = episode[step]['reward']
state = episode[step]['state']
action = episode[step]['action']
if len(episode) > 1000:
print(g, reward)
g = self.gama * g + reward
self.qvalue[state, action] = g
y, x = self.env.state2pos(state) / self.env.size
prb = policy_net(torch.tensor((y, x)).reshape(-1, 2))[0]
log_prob = torch.log(prb[action])
loss = -log_prob * g
loss.backward() # 自动求导,反向传播计算梯度
self.writer.add_scalar('loss', float(loss.detach()), epoch)
self.writer.add_scalar('g', g, epoch)
self.writer.add_scalar('episode_length', len(episode), epoch)
print(epoch, len(episode), g)
optimizer.step()
for s in range(self.state_space_size):
y, x = self.env.state2pos(s) / self.env.size
prb = policy_net(torch.tensor((y, x)).reshape(-1, 2))[0].detach().numpy()
self.policy[s, :] = prb.copy()
self.writer.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号