强化学习理论-第2课-贝尔曼公式
1. return和贝尔曼

上图说明从不同状态出发得到的return,依赖于从其他状态出发的return

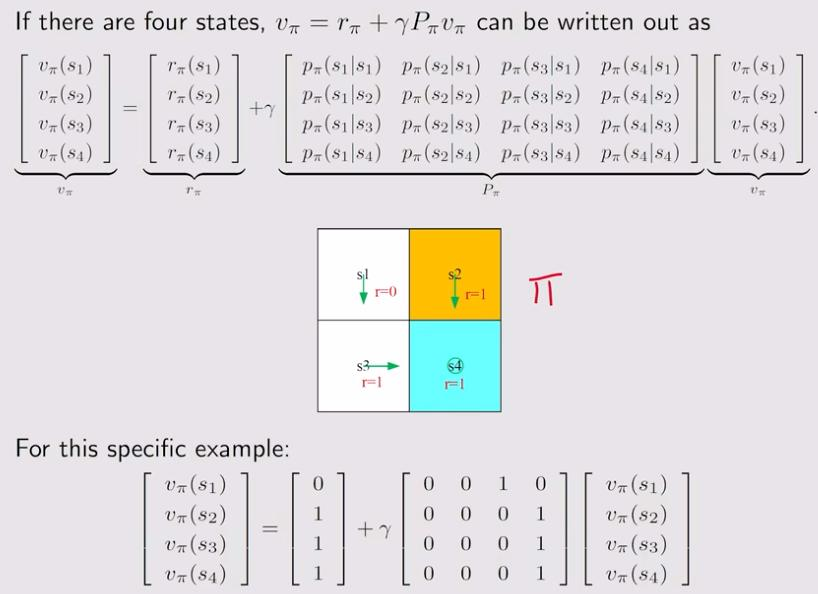
v是return,将第一张图写成矩阵的形式,r代表immediate reward,是已知的,矩阵P是策略加上state transition,也是已知的,求解v
这个公式实际上就是贝尔曼公式

- 在\(S_t\)采用什么样的动作\(A_t\),是有策略决定的,\(\pi\)
- 在\(S_t\)采用了\(A_t\)的动作,reward是有reward probability决定,p
- 在\(S_t\)采用了\(A_t\)的动作,会产生什么状态,是有state transition probability决定的
![]()

2. State value

- return和state value的区别:
return:对单条轨迹的返回值
state value:对多条轨迹的返回值,从一个状态出发,有可能会有多条轨迹
3. Bellman equation
贝尔曼公式描述了不同状态的state value之间的关系。

把state value分成了2个expectation,一个是immediate reward,一个是future reward。
3.1 mean of immediate reward:
在当前状态\(S_t\),得到的reward是\(R_{t+1}\),那么它的mean是多少:
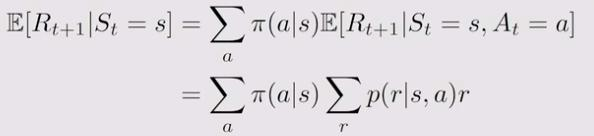
\(\pi (a|s)\):在状态s,采取action_a的概率是\(\pi\),累加起来所有的action概率
\(p(r|s,a)r\):在状态s,采取action_a,获取reward为r的概率为p,再乘上reward本身的值,累加起来所有reward的概率
3.2 mean of future reward:
我从状态s出发,到一下时刻的return的mean。

第一行公式:
E:当前状态s,跳到下一状态\(s^{'}\)所得return的mean
\(p(s^{'} | s)\):当前状态s,跳到下一个状态\(s^{'}\)的概率
对所有的下一步状态进行累加
第三行公式:
\(v_{\pi} (s^{'})\):当前状态是\(s^{'}\),所得return的mean,这个就是\(s^{'}\)的state value。
第四行公式:
\(p(s^{'} | s, a)\pi(a|s)\):当前状态是s,采取action_a,会跳到状态\(s^{'}\)的概率p * 从s出发采取不同的action的概率\(\pi\),对所有可能的action概率累加
3.3 Bellman equation


注意一点,这个贝尔曼公式在使用中是一组公式,\(v_{\pi}(s)\)和\(v_{\pi}(s^{'})\)都需要计算,然而前者依赖后者,看似不能计算,但是对于一个trajectory,有很多组公式,结合一起就可以计算了。
model是未知的话,就是model free reinforcement learning算法,这里还是有model的
3.4 列子:


3.5 贝尔曼公式变形为矩阵形式

4. Solve state values

最终,\(v_k\)会收敛到\(v_{\pi}\)
证明:

5. action values
与state values的区别:
state values:从一个状态到下一个状态的平均返回值
action values:从一个状态采取一个action到下一个状态的平均返回值
策略跟action value相关
5.1 定义:

这个\(q_{\pi}(s, a)\)就是action value。
从当前状态s出发,选择action_a,所得到的return的mean值。
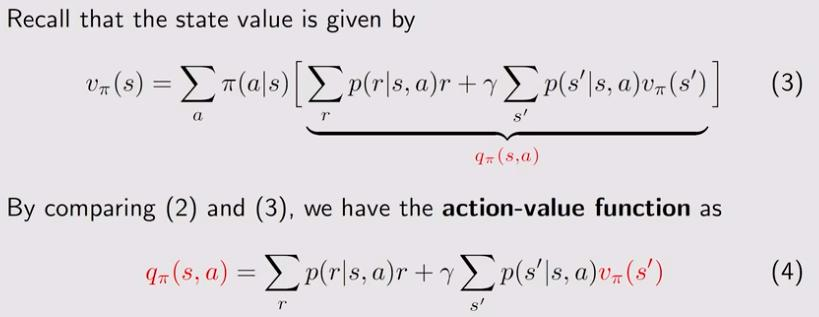
6. 总结:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号